pytorch案例代码-2
Posted weixin_43739821
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了pytorch案例代码-2相关的知识,希望对你有一定的参考价值。

循环神经网络——基础知识
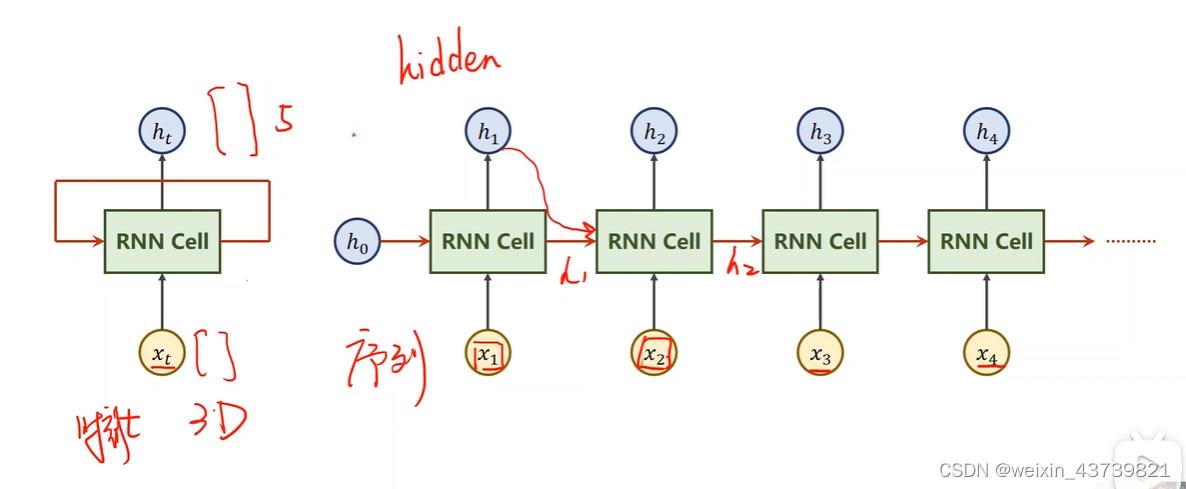
适合前后有联系的连续数据预测,比如天气预测、股市预测、自然语言等,而这些用DNN、CNN来做计算量就太大或者没法做,h0是先验,也可以前面接上CNN+FC后面连上RNN,就可以完成图像到文本的转换,没有先验时h0也可以设为和h1同维度的全0。
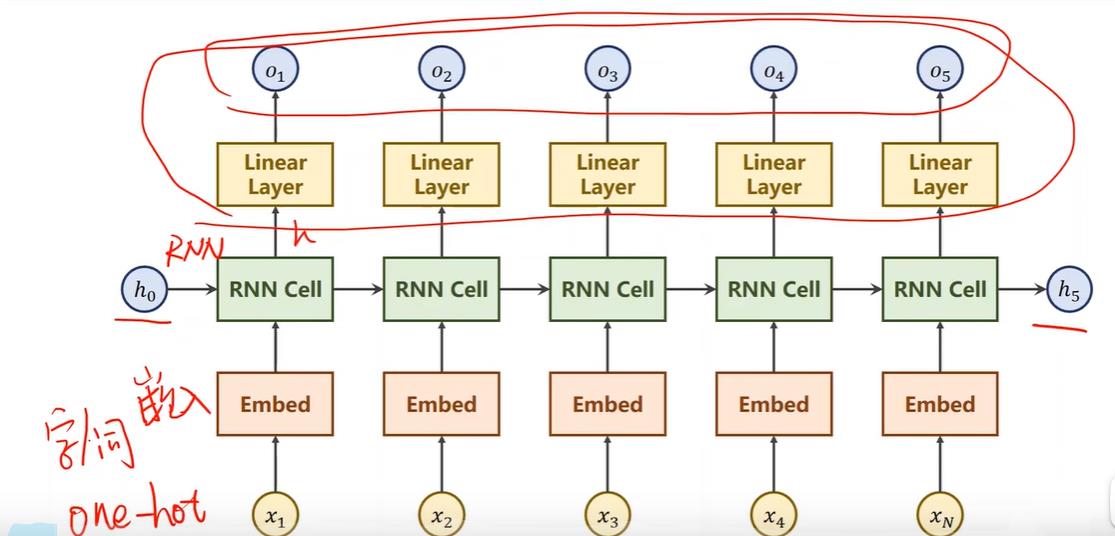
注意RNN Cell是共享的,所有的RNN Cell都是同一个Linear(线性层),将xi的n维映射到hi的m维度,循环使用这个Linear,所以叫循环神经网络。hi即作为时刻i的xi的输出结果,也作为xi+1时刻的输入。
Cell运算如下所示,输入xt的维度是input_size × 1,因为需要和ht-1相加所以把它转为hidden_size维度,所以Wih便是hidden_size × input_size大小的,然后Whh是hidden_size × hidden_size的,各自加上偏置,所得俩个向量直接(信息融合)相加传入tanh激活(在RNN中这个常用一些),得到ht。
实际中这俩个运算是一起的,因为W1 × h + W2 × x可转化为[W1 W2] × [h x]^T,实际中会把x和h拼起来得到(hidden_size+input_size)× 1的向量和一个hidden_size × (hidden_size+input_size)的权重矩阵运算。所以本质上还是一个线性层。

pytorch中可以自己定义RNN Cell。也可以用自带的,如下所示,注意input和hidden各自分别有俩个参数,第一个是batch,代表样本数,第二个才是维度。

如下所示,batch_size表示样本数,seqLen表示每个样本有多少个序列,比如这种情况每个样本包含x1 x2 x3三个四维的序列。

循环神经网络——使用循环神经网络
有了以上基础知识就可以用RNN了,RNN不用我们自己写循环,自动计算。注意RNN最关键和最基础的就是搞懂各个参数的size。
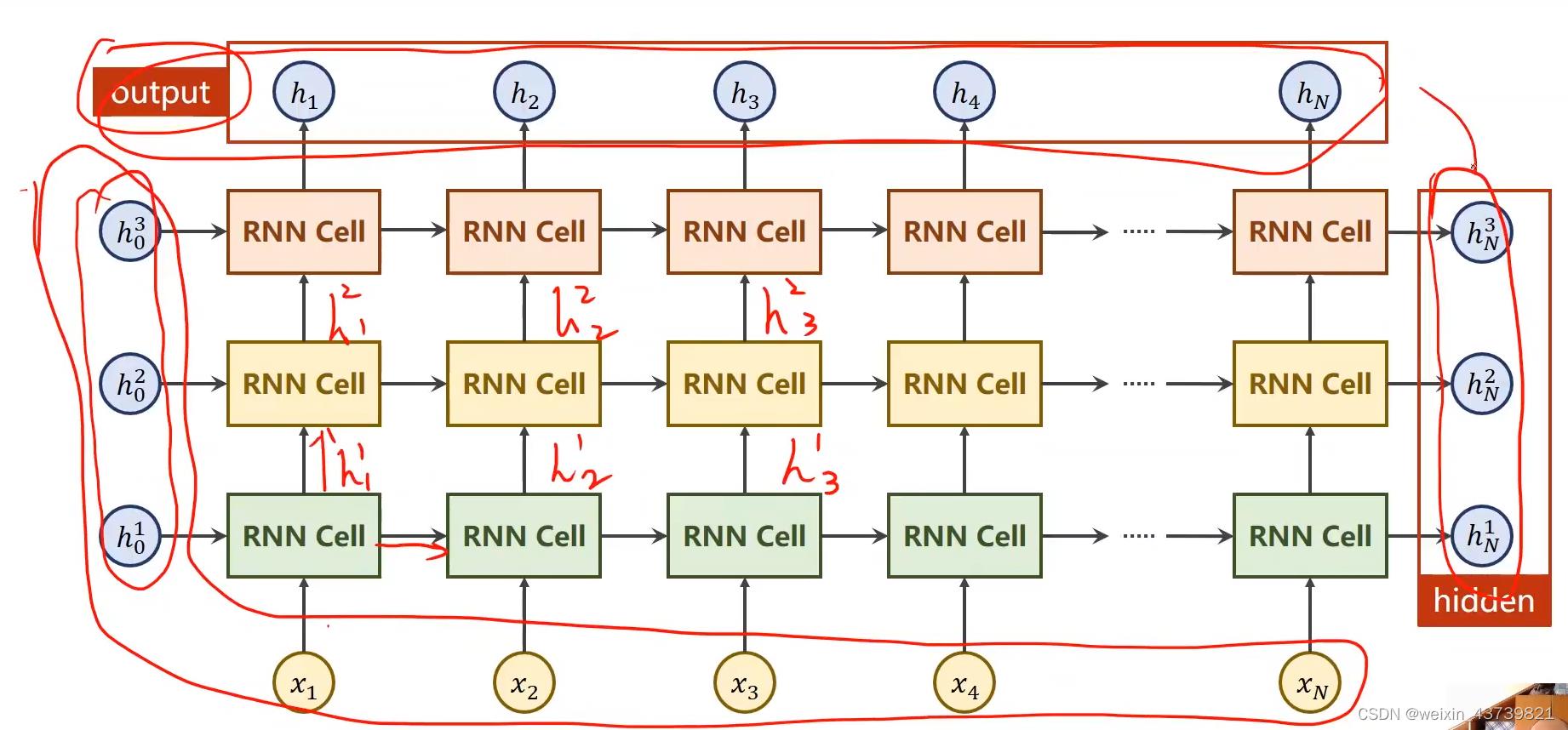
使用RNN,多一个num_layers参数,表示层数,如下面第二张图表示三层RNN(层数多了计算比较耗时),虽然看起来很复杂,其实也就只有三个线性层权重。
对于RNN的输入参数来说,inputs需要包含整个输入序列(x1-xn),hidden就是h0(如果有三层,就是三个左边的h0)。
输出的俩个张量参数中,第一个out表示h1-hn,第二个参数hidden表示hn(如果有三层,就是三个左边的hn)。
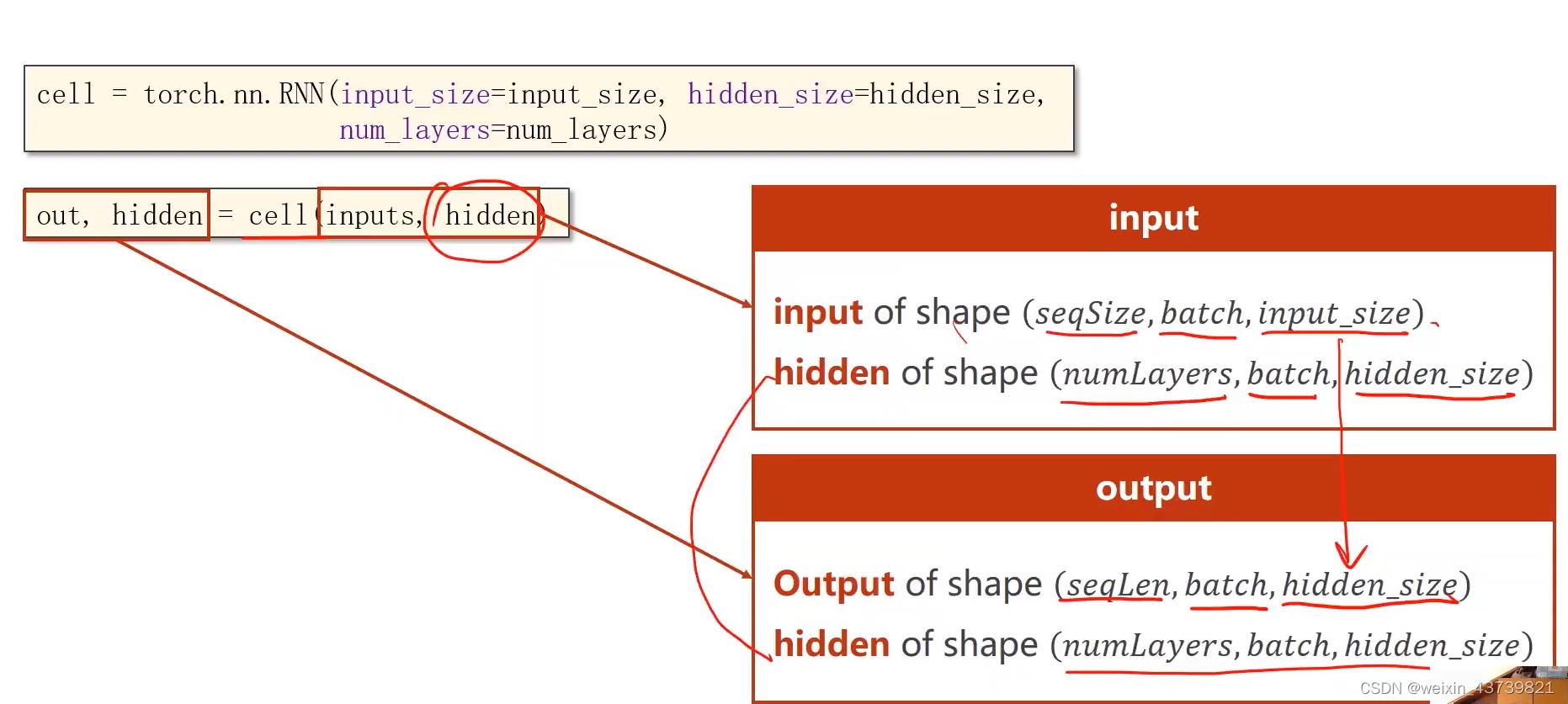
写代码时就要关注参数构建:
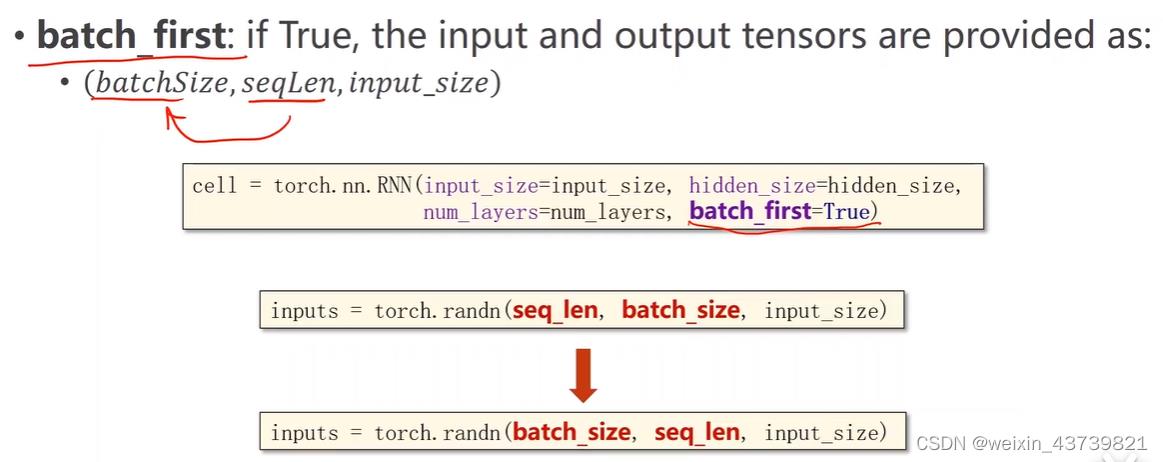
TIPS:为了方便构造数据集,RNN还提供了个参数batch_first,设置成True时,batch_size和seq_len参数位置互换。其他的不变
循环神经网络——例子使用RNNCell
一个简单的学习输入hello序列输出ohlo序列的例子。但是这些字符网络无法计算,所以一般在nlp中要将其向量化,一般方法是构造字符词典,如果是词级别的就是词的词典。如图2所示,这里给每个字符分配一个索引(可以随机分配,保持唯一就行),再由索引下标,生成独热向量,即只有索引下标为1其他为0,而向量的维度就是词典元素数量,这里是4,所以input_size是4。
因为我们想要输出告诉我们输出的是h e l o四个字符中的哪一个类别,所以输出的size即hidden_size也是4。
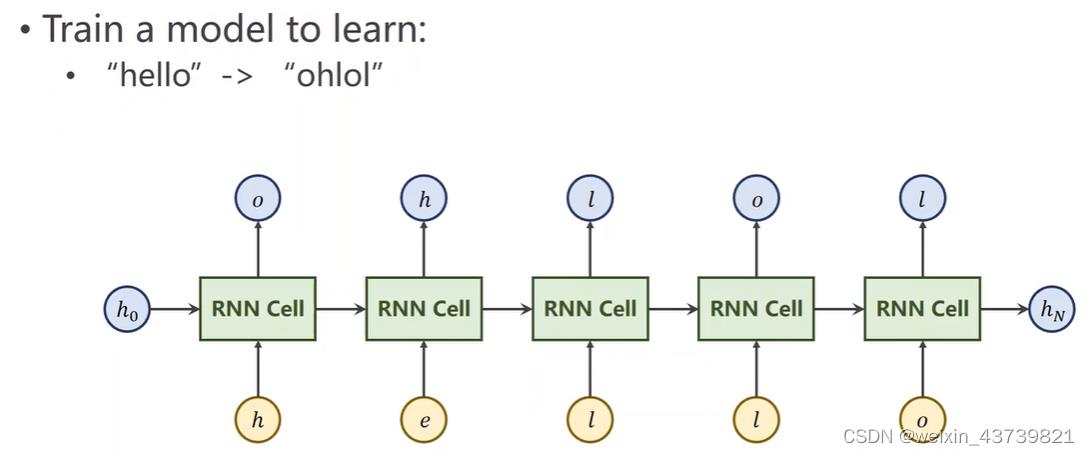
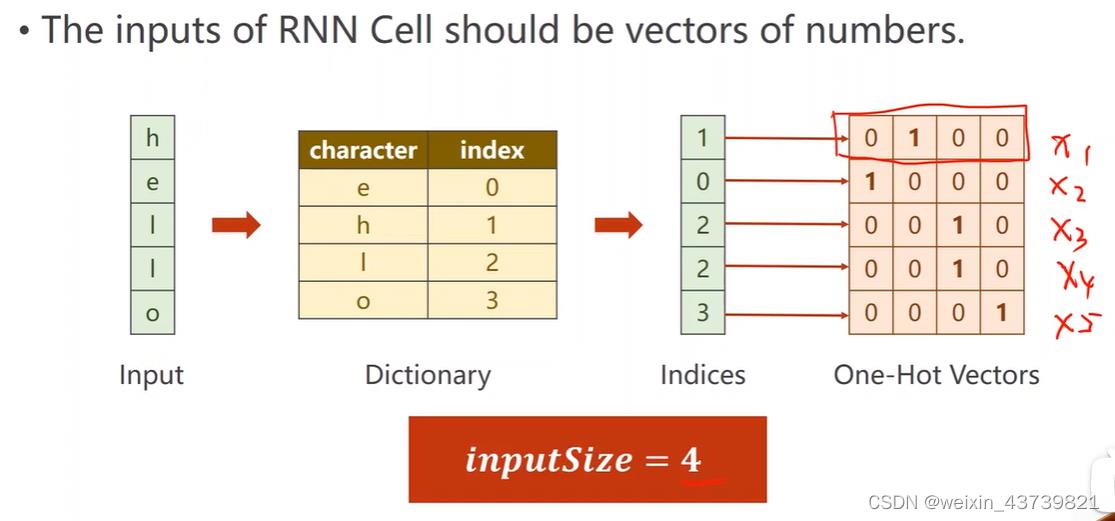
因为只有一个样本拿来训练,所以batch_size为1。然后首先创建字典即字符列表,方便根据索引拿字符,x_data对应h e l l o,y_data对应o h l o l。
然后用一个简单的查询语句构造了输入数据的独热向量,比如输入数据第二个字符索引对应0,就把第0行数据拿出来作为对应向量,所以输入数据独热向量的size是(seq_len, input_size),因为要求inputs中间还有个batch_size,所以view一下,最终保持成(seq_len,batch_size, input_size)的大小,同样把lables也reshape成(seq_len,1)的维度。
这里注意区分inputs与forward中的input,这里input的size是(batch_size, input_size),训练时一个个的input从inputs中取出,即一个个xt,这里forward做的是计算一个个ht = cell(xt, ht-1).
图三的第三个函数做的是生成初试的默认h0,这里生成全0。大小与ht、xt一样都是input的维度。可以看到只有在这里用到了传入的batch_size参数,实际上不传入这个参数,由input的shape也可以得到这个参数。


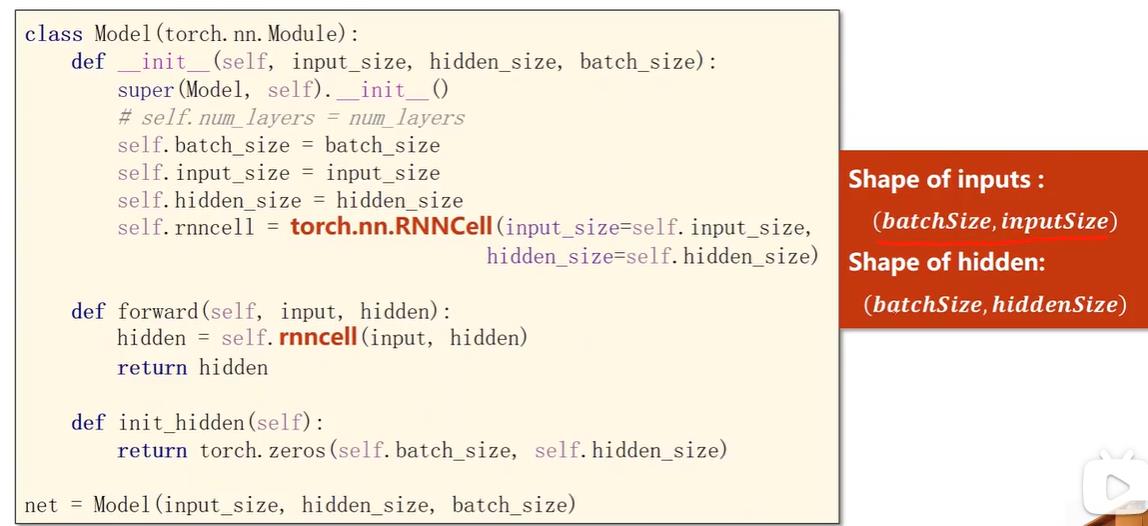
构造完模型就可以训练了,用这一个样本训练15轮,每轮训练记得要用init_hidden初始化h0,然后写循环遍历inputs拿出一个个input,也就是拿出一个个xt训练。关键还是弄明白一个个size,这里input的size是(batch_size, input_size),inputs是(seq_len,batch_size, input_size);lables是(seq_len,1),lable是(1).
注意这里loss要一个个累加,将整个序列的损失加起来构造计算图。
for循环最后俩行代码是为了输出预测,因为hidden是四维向量,分别代表每个字符的预测概率,因为其是(batch_size, input_size)维度,所以按dim1,即行来查找最大值下标来输出ht对应字符。
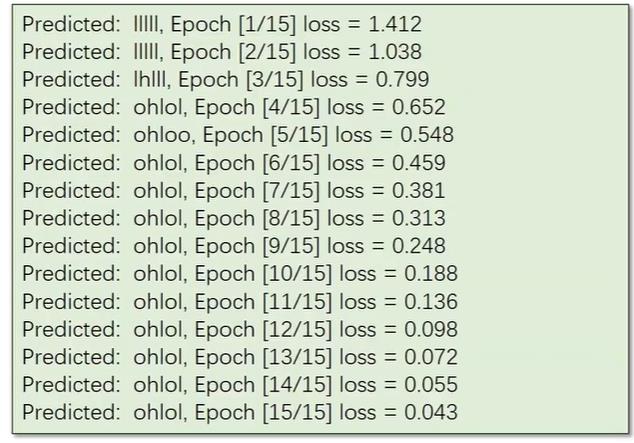
最后可以看到loss不断减少,最后结果也正确了。



循环神经网络——例子使用RNN
还是上面的例子,如果使用RNN就不用自己写循环计算。
这里隐层h0放在forward中构造,也可以放在外面构造传入forward。这里forward的input是整个inputs,所以是(seq_len,batch_size, input_size),这里hidden的维度是(num_layers, batch_size,hidden_size),因为最后的输出out是(seq_len,batch_size, hidden_size),所以将outview一下,好处是在计算交叉熵的时候需要将其变成一个二维矩阵,lables也是要从(seq_len,batch_size,1)变为(seq_len×batch_size,1)。
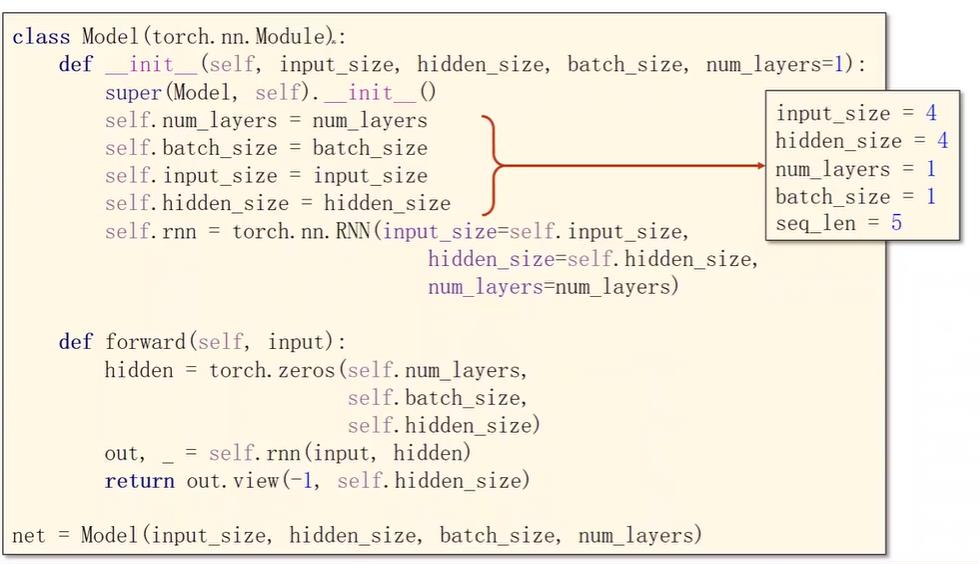

训练步骤就不用写循环,一次传入整个inputs,最下面的代码也是为了将预测输出。
这里有个小问题是,损失函数中传入的是outputs和lables,分别是view过后的((seq_len×batch_size, hidden_size))与(seq_len×batch_size,1)(其实经过pycharm测试,lables是torch.Size([5]),outputs是torch.Size([5, 4])),hidden_size和1怎么能对得上然后求损失函数呢?
其实torch.nn.CrossEntropyLoss(input, target)中的标签target使用的不是one-hot形式,而是类别的序号。形如 target = [1, 3, 2] 表示3个样本分别属于第1类、第3类、第2类。input:预测值,(batch,dim),这里dim就是要分类的总类别数,target:真实值,(batch),这里为啥是1维的?因为真实值并不是用one-hot形式表示,而是直接传类别id。


循环神经网络——独热向量—>EMBEDDING
缺陷:当词典存词,独热向量可能有上万的维度,且特别稀疏,且属于一种硬编码(不是学习出来的)。
针对以上有了嵌入层EMBEDDING


可以降维也可以升维,比如独热向量是四维,我们升到五维,创造下图所示矩阵,比如输入的是第二个字符,就把第二行拿出来。
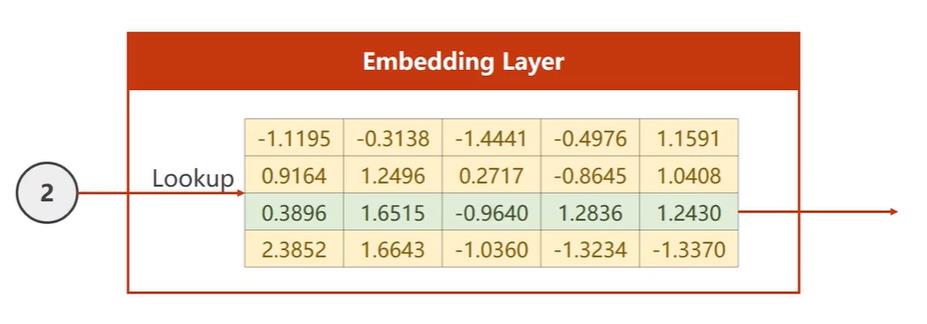
所以网络变成下面这样,首先嵌入层会把输入的独热向量转成稠密的形式,嵌入层要求输入是长整型的数据,最后还有一个线性层,因为要保证最后输出的hidden要和分类的类别数一致

嵌入层主要关注俩个参数,第一个是输入数据的维度num_emdeddings即独热向量的维度,第二个是输出维度embedding_dim,这俩就构成了上面矩阵的高度和宽度,嵌入层的input是长整型张量,output的size是(*, embedding_dim),表示input的shape,表示可以是任意维度。

然后是线性层:

然后是前面提到的交叉熵,target要比input小一维度,然后后面的数据可以是k维的。

循环神经网络——使用嵌入层网络
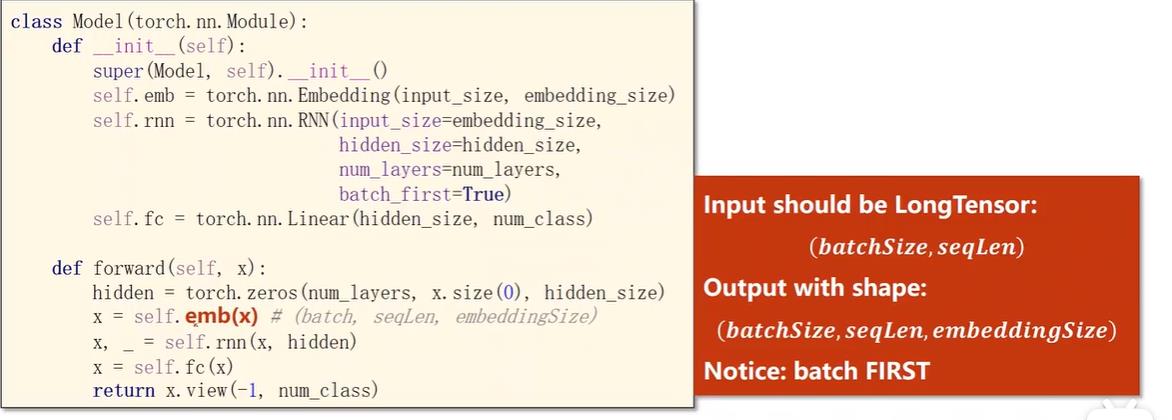
在上面基础之上,网络结构就是加了一个嵌入层和线性层,注意嵌入层的输入数据是长整型的,且size是(batch_size,seqlen),所以网络的输入数据的size得改成这样的,然后嵌入层的输出是(batch_size,seqlen,embedding_size),等于说它内部已经帮你处理好从标量到独热向量转换的过程了,你只需要提供input_size、embedding_size和索引序列x_data。
其次注意RNN构造时,batch_first设置为True了,将batch_size放到seq_len前面。
然后全连接层完成hidden_size到类别数的转换, 最后输出数据view成二维矩阵(batch_size×seqlen,num_class)以传入loss计算。
ouputs是(batch_size×seqlen,num_class),target或者说lables是(batch_size×seqlen)的。



循环神经网络——实现一个循环神经网络的分类器
解决对名字进行分类的问题,用几千个来自18个语言的人的名字进行训练,模型可以根据拼写来预测人名属于哪种语言。
因为我们只关心最后名字的分类所以模型可以变得更简单,由下面图1转为图2,我们只关心最终的隐层状态,然后在通过一个全连接分成18个类别。
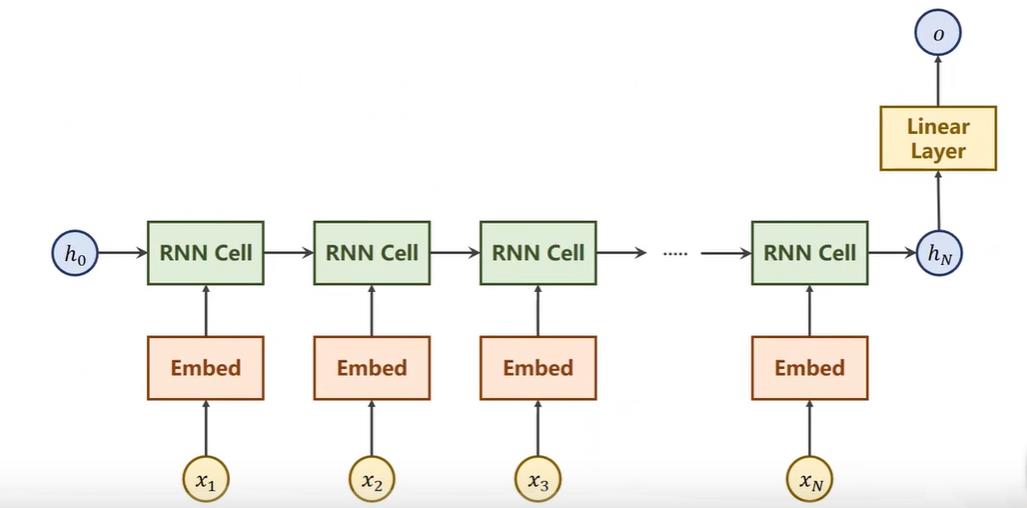
并且我们将定义的模型改成使用gru,这里x虽然看起来只有一个数据,但是实际上一个Maclean的名字,是由多个单词组成,即x1、x2、x3…组成一个单词,我们输入的是x1、x2、x3…这样的序列,因为名字长短不一,所以输入也不一,这是我们需要考虑的。
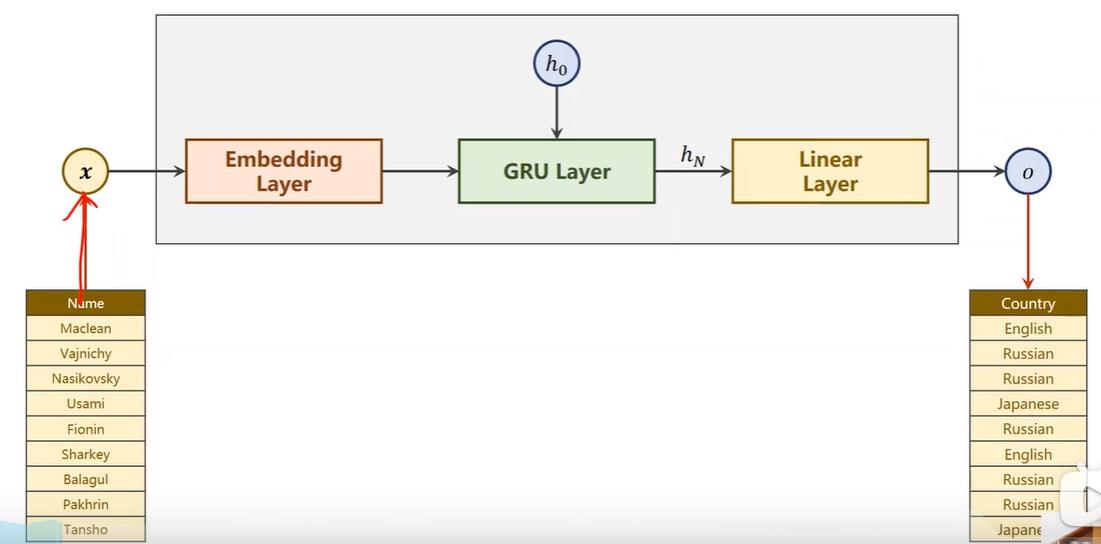
我们使用自己定义的分类器RNNClassfier,传入的参数分别是,传入的字符数量(名字有多少个字母),隐层数量 (gru输出结果大小),分类数量,用几层的gru。
下面代码会定义一个time变量就可传入定义的time_since函数用于打印距离开始训练时训练时间有多长。
在循环里面可以分别将训练和测试封装调用,然后把测试结果添加到列表这样就可以把记录下来的准确率用于绘图


数据准备方面,由于输入的是序列,所以要先把字符串转为一个个字符,由于字符正好可以在ascii上对应,也可以采用128维的ascii表,我们只需要告诉嵌入层每个字符对应的独热向量第几个维度是1,让嵌入层帮我们转成稠密的形式就行,所以我们只需要把其ascii码值传入就行。
由于数据长短不一,所以我们还需要做一个padding,因为训练的inputs是一个个数据组成的batch_size,这种数据长短不一的不能组成张量批量运算,padding的长度与最长的字符串对齐。
国家的名字也要做一个索引。
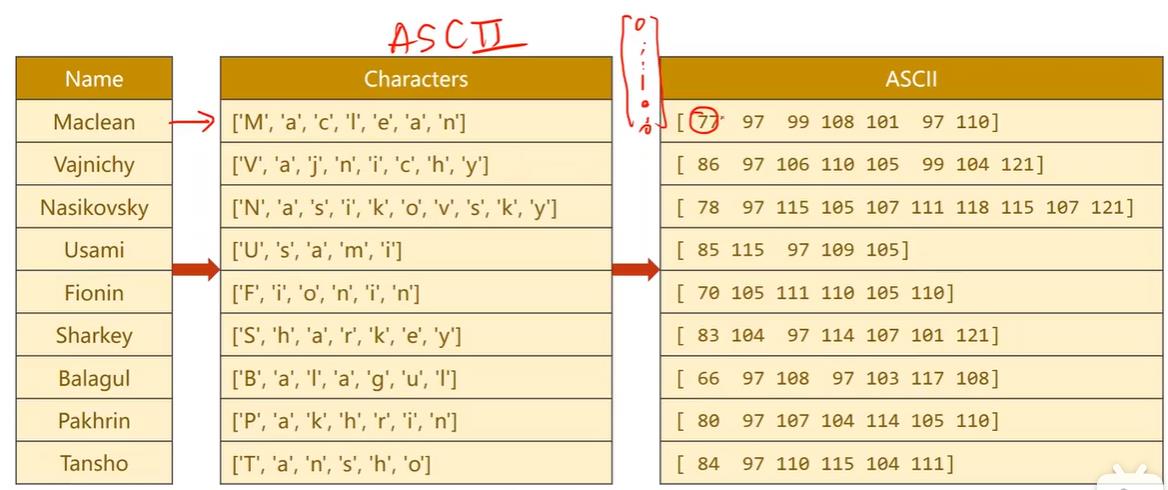
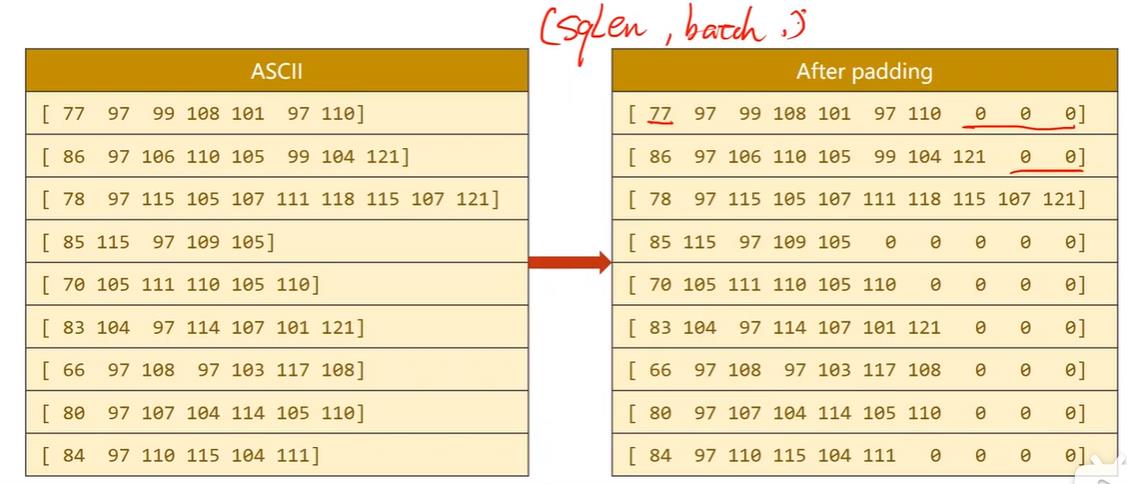

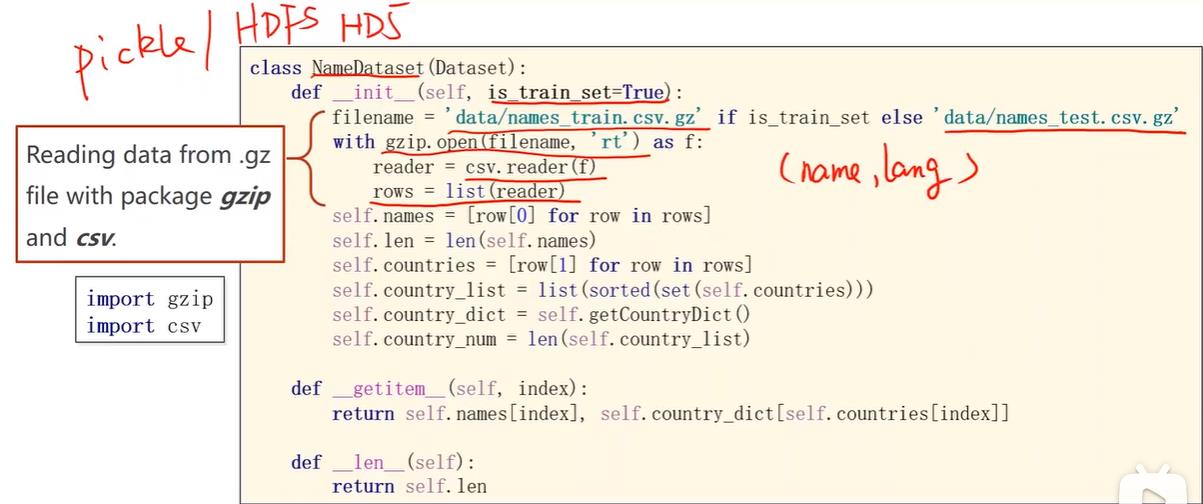
名字的数据读取方面,由于几千个名字占不了多少内存,所以可以一次性读入,当然如果一次全部转成张量数据量会比较大。传入is_train_set决定是读入训练集还是测试集,gz是linux中压缩文件格式,可以通过gzip读压缩包。
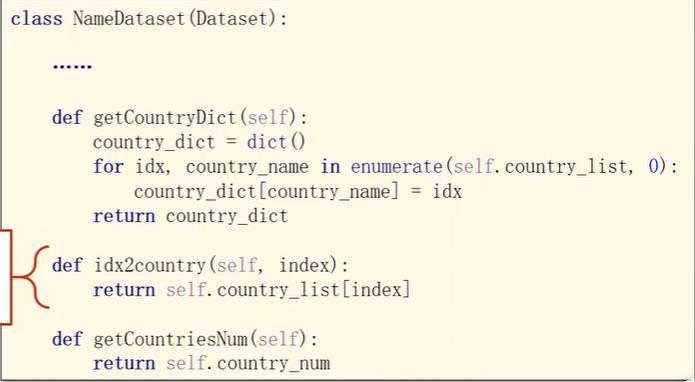
把csv的所有行读入到rows中,每一行是一个元组包含名字和国家,将名字和国家读出。其中国家因为要做索引,所以用set把列表变成集合去除重复元素,然后排序之后形成列表,然后调用getCountryDict将列表转变成上面一张图中的索引词典,便于在getitem中索引访问可以输出名字和国家对应的索引。

以上是关于pytorch案例代码-2的主要内容,如果未能解决你的问题,请参考以下文章
Pytorch RuntimeError:预期的标量类型 Float 但找到了字节
通过 DataLoader (PyTorch) 迭代:RuntimeError: 标量类型 unsigned char 的预期对象但序列元素 9 的标量类型浮点数