PE结构-导出表
Posted 嘻嘻兮
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PE结构-导出表相关的知识,希望对你有一定的参考价值。
在上一篇博客中说了导入表,所谓的导入表,其实相当于记录程序所依赖的函数库信息,类似于你要调用外部函数,总得记录下这个函数在哪个库中,名字或者序号是什么。有了这些信息后,我们就可以LoadLibrary和GetProcAddress获取函数地址了
那么,操作系统是如何来获取函数地址呢,也就是GetProcAddress的实现,这里就涉及到了导出表。导出表,会记录这个库函数的地址是多少,所以简单来说GetProcAddress就是查导出表来获取地址,如何查就是下面的话题了。
导出意味着需要提供API给他人使用,一般来说会是一些DLL之类的,所以,我们先来写一个DLL,再来分析其PE格式
.386
.model flat, stdcall ;32 bit memory model
option casemap :none ;case sensitive
include windows.inc
include user32.inc
includelib user32.lib
public g_nTest
.data
g_nTest dd 87654321h
.code
ShowMsg proc szText:LPSTR,szTitle:LPSTR
invoke MessageBox,NULL,szText,szTitle,MB_OK
ret
ShowMsg endp
MySub proc x:UINT,y:UINT
mov eax,x
sub eax,y
MySub endp
MyAdd proc x:UINT,y:UINT
mov eax,x
add eax,y
MyAdd endp
DllMain proc hinstDLL:HINSTANCE,fdwReason:DWORD,lpvReserved:LPVOID
mov eax,TRUE
ret
DllMain endp
end DllMain
def文件描述
EXPORTS
ShowMsg @11
MySub @5 noname
MyAdd @7
g_nTest @8这里我们先用Depends来观察一下导出情况
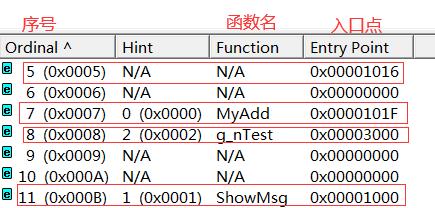
其中序号为5,7,8,9的就是我们自己导出的,那么剩余的是什么,下面就可以通过导入表来解释了
首先先来说一下如何定位到导入表,导入表位于数据目录的第一项
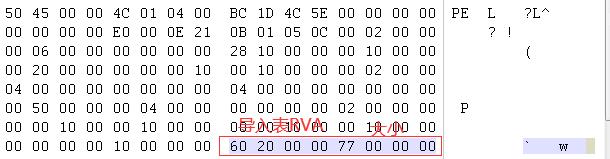
2060这里转FA的话就是660,所以文件地址从660开始,大小为77,这一整块是导入表信息的总大小,这里的总大小是包含所有信息的。
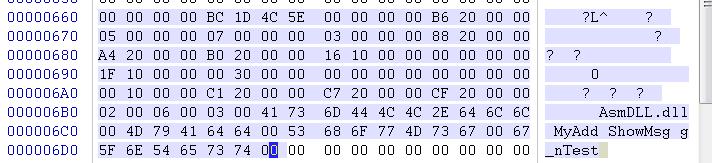
OK,下面先来看一下导入表结构,注意上面的0x77是全部信息的大小,而单纯的导入表结构只占40字节,也就是两行半
typedef struct _IMAGE_EXPORT_DIRECTORY
DWORD Characteristics;
DWORD TimeDateStamp;
WORD MajorVersion;
WORD MinorVersion;
DWORD Name; //动态库名 用于说明性信息
DWORD Base; //导出序号中的最小值
DWORD NumberOfFunctions; //多少项导出函数
DWORD NumberOfNames; //多少个根据名字导出的函数
DWORD AddressOfFunctions; // 指向导出函数地址数组,数组大小由NumberOfFunctions确定
DWORD AddressOfNames; // 指向名字导出数组,记录函数名,数组由NumberOfNames确定
DWORD AddressOfNameOrdinals; // 指向名称对应序号数组,大小由NumberOfNames确定
IMAGE_EXPORT_DIRECTORY, *PIMAGE_EXPORT_DIRECTORY;前四个字段我们略过,因为可以填写任意值,没有太大意义,开始讨论后面的字段意义
Name字段,说明性信息,一般情况下会默认源码文件名
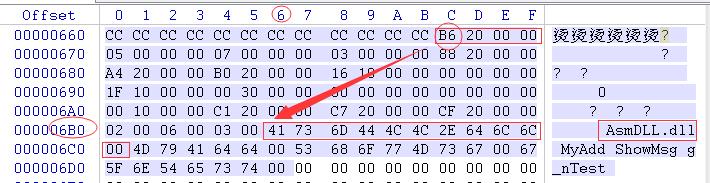
OK,下面几个字段相对会有那么点绕,总的来说,站在GetProcAddress的角度去思考就会清爽很多
Base 全部导出函数中序号的最小值,首先来思考一下这个字段的意义?
首先我们先来想一下根据序号来找到函数地址,那么此时肯定会有一张函数地址表(AddressOfFunctions),如何查找效率高?毫无疑问,直接将序号当成数组的下标来寻址,这样找到函数地址的效率是最高的,
那么问题来了,拿我们的导出例子来说,最小的序号为5,数组下标来寻址意味着需要使得0~4项都是空的,所以Base字段的意义就来了,下标平移,节省空间。也就是说序号减去Base就是数组下标的位置,那么序号5就会放在第0项,这样子省去了一部分空间。
不过像我们中间出现的断序的情况(序号5后面是序号7),这个就没有办法了,所以在上面Depends图中0x6,0x9,0xA这几项都是空的,只是用于占位置罢了,毕竟数组是需要连续的。
NumberOfFunctions用于记录总共有多少项导出函数地址
根据上图中该结果是0x7,懂了上面的Base设计原理后,应该能明白为什么只有四项导出函数,这里却显示7项。因为还有好几项只是用于数组中占位置的,空间换时间的想法。
NumberOfNames用于记录有多个是是根据名字导出的
好了,上面两个字段都是根据序号这一方面的考虑的,那么使用函数名导出该这么办呢,我们可以这样子来设计一下
typedef struct _IMAGE_EXPORT_BY_NAME
DWORD nameRva; //名字地址
WORD index; //对应的地址表中的下标
看一下上面的结构体,其中一个字段是名字地址,根据其可以找到函数名,匹配函数名成功后可那下面的index下标字段去函数地址表中找地址。
当然Windows并不是这样设计的,Windows把上面的两项分别拆成了两张表:名字导出表(AddressOfNames),名字对应下标表(AddressOfNameOrdinals),这两张表的同下标是相互关联的,也相当于上面的结构体。
所以这个字段就是用于描述这两项有多少个的。

下面我们具体在WinHex中来看一下数值,可对照着上表的数据看,上表是一个概括
首先看AddressOfFunctions,其数组的大小为NumberOfFunctions

VA2088对应FA为688,下面在688位置查找7项

再来看一下AddressOfNames,其数组大小为NumberOfNames,三项

这里因为是名字表,所以其对应是个名字的VA值,要找到名字字符串,我们还需要根据其值再找一次

再来看最后一张表了,这张表的大小也为NumberOfNames,主要用于辅助名称查地址,比如你知道了名称,那么这么知道这个名称在地址表的第几项呢,所以这张表的目的就是用于映射该名称在地址表中的下标值。需要注意的是因为序号最大2字节,所以该表的每项长度也是2字节的

好了,分析完后可以再对照着上面的表看看,下面再来总结操作系统如何实现GetProcAddress
1.序号
定位到数据目录->导入表
序号-Base = 下标(index)
越界检查,取函数总个数,检查下标有没有超过个数
取函数地址表,取index项 -> RVA值 + 参数一实例句柄 = 函数地址
2.名称
定位到数据目录->导入表
根据名称导出个数遍历函数名称数组查找 - 导出函数多
操作系统会折半查找,所以链接器会按照ascii码顺序排放
查找不到则返回NULL
查找到下标-index,找函数名称和序号对应关系表
同在该表中取index项,取到内容->index2
越界检查,取函数总个数,检查index2有没有超过个数
取函数地址表,取index2项 -> RVA值 + 参数一实例句柄 = 函数地址下面是具体的代码实现,当然这里的代码只是简易版的,操作系统做的事情还有挺多的,这里只是给了一个主体概要
void* MyGetProcAddress(HMODULE hModule, LPCSTR lpProcName)
if(hModule == NULL || lpProcName == NULL)
return NULL;
PIMAGE_DOS_HEADER pDosHeader = (PIMAGE_DOS_HEADER)hModule;
PIMAGE_NT_HEADERS pNtHeaders = (PIMAGE_NT_HEADERS)((DWORD)hModule + pDosHeader->e_lfanew);
if (pDosHeader == NULL || pDosHeader->e_magic != IMAGE_DOS_SIGNATURE)
return NULL;
if (pNtHeaders == NULL || pNtHeaders->Signature != IMAGE_NT_SIGNATURE)
return NULL;
PIMAGE_EXPORT_DIRECTORY pExport = (PIMAGE_EXPORT_DIRECTORY)((DWORD)hModule +
pNtHeaders->OptionalHeader.DataDirectory[IMAGE_DIRECTORY_ENTRY_EXPORT].VirtualAddress);
PDWORD funTable = (PDWORD)((DWORD)hModule + pExport->AddressOfFunctions);
if ((DWORD)lpProcName & 0xffff0000)
//Name
PDWORD pNameTable = (PDWORD)((DWORD)hModule + pExport->AddressOfNames);
PWORD pOrdinalTable = (PWORD)((DWORD)hModule + pExport->AddressOfNameOrdinals);
for (int i = 0; i < pExport->NumberOfNames; ++i)
char *funName = (char*)((DWORD)hModule + pNameTable[i]);
int funIndex=0,procIndex=0;
while (funName[funIndex] && lpProcName[procIndex])
//比较名字字符串
if(funName[funIndex] != lpProcName[procIndex])
break;
++funIndex;
++procIndex;
if(funName[funIndex] || lpProcName[procIndex])
continue;
WORD ordinal = pOrdinalTable[i];
lpProcName = (LPCSTR)ordinal;
break;
if (!((DWORD)lpProcName & 0xffff0000))
//Ordinal
WORD ordinal = (WORD)lpProcName;
if(ordinal < 0 || ordinal >= pExport->NumberOfFunctions)
return NULL;
return (void*)((DWORD)hModule+funTable[ordinal]);
return NULL;
以上是关于PE结构-导出表的主要内容,如果未能解决你的问题,请参考以下文章