模型评估与选择
Posted ZJun310
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了模型评估与选择相关的知识,希望对你有一定的参考价值。
第二章 模型评估与选择
模型评估方法
1. 留出法(hold-out)
方法:直接将数据集D划分为两个互斥的集合,训练集合S和测试集合T,在S上训练模型,用T来评估其测试误差
注意:训练/测试集的划分要尽可能保持数据分布的一致性,避免因为数据划分过程引入额外的偏差而对最终结果产生影响
缺点与改进:单次使用留出法得到的估计往往不够稳定可靠,在使用留出法时,一般要采用若干次随机划分、重复进行实验评估后取平均值作为留出法的评估结果
实际运用:实际中一般将大约2/3~4/5的样本用于训练,剩余样本用于测试
2. 交叉验证法(cross validation)
方法:先将数据集D划分为k个大小相似的互斥子集.每个子集 Di 都尽可能保持数据分布的一致性,即从D中通过分层采样得到 .然后每次用k-1个子集的并集作为训练集,余下的那个子集作为测试集,这样就可以获得k组训练/测试集,从而可以进行k次训练和测试,最终返回的是这k个测试结果的均值
实际运用:一般而言k的取值为10,常用的还有5、20等
原理图:

3. 自助法(bootstrapping)
问题引出:我们希望评估的是用D训练出来的模型,但是留出法和交叉验证法中,由于保留了一部分样本用于测试,因此实际评估的模型所使用的训练集比D小,这必然会引入一些因训练样本规模不同而导致的估计偏差,为此提出自助法.
方法:它以自助采样(bootstrap sampling)为基础.给定包含m个样本的数据集D,我们对它进行采样产生数据集
D′
:每次随机从D中挑选出一个样本,将其拷贝放入
D′
, 然后再将该样本放回初始数据集D中,使得该样本在下次采样时仍有可能被采样到;这个过程重复执行m次后,我们就得到可包含m个样本数据的数据集
D′
,这就是自助采样的结果.样本在m次采样中始终不被采到到概率为
由此可知通过自助采样,初始数据集D中约有36.8%的样本未出现在采样数据集 D′ 中.于是我们可将 D′ 用作训练集, D∖D′ 用作测试集.
优缺点:自助法在数据集较小,难以有效划分训练/测试集时很有用,但是,自助法改变了初始数据集的分布,这会引入估计偏差,所以在数据量足够时,一般采用留出法和交叉验证法.
性能度量
1. 错误率(error rate)与精度(accuracy)
错误率定义:
精度定义:
acc(f;D)=1m∑i=1mI(f(xi)=yi)=1−E(f;D)
2. 准确率(precision)和召回率(recall)
问题引出:在现实生活,比如信息检索中,我们往往会关心”检索出的信息中有多少比例是用户感兴趣的“,”用户感兴趣的信息中有多少被检索出来了“,准确率和召回率则比较适用于此类需求的性能度量
绘制如下混淆矩阵(confusion matrix)来进一步定义相关概念
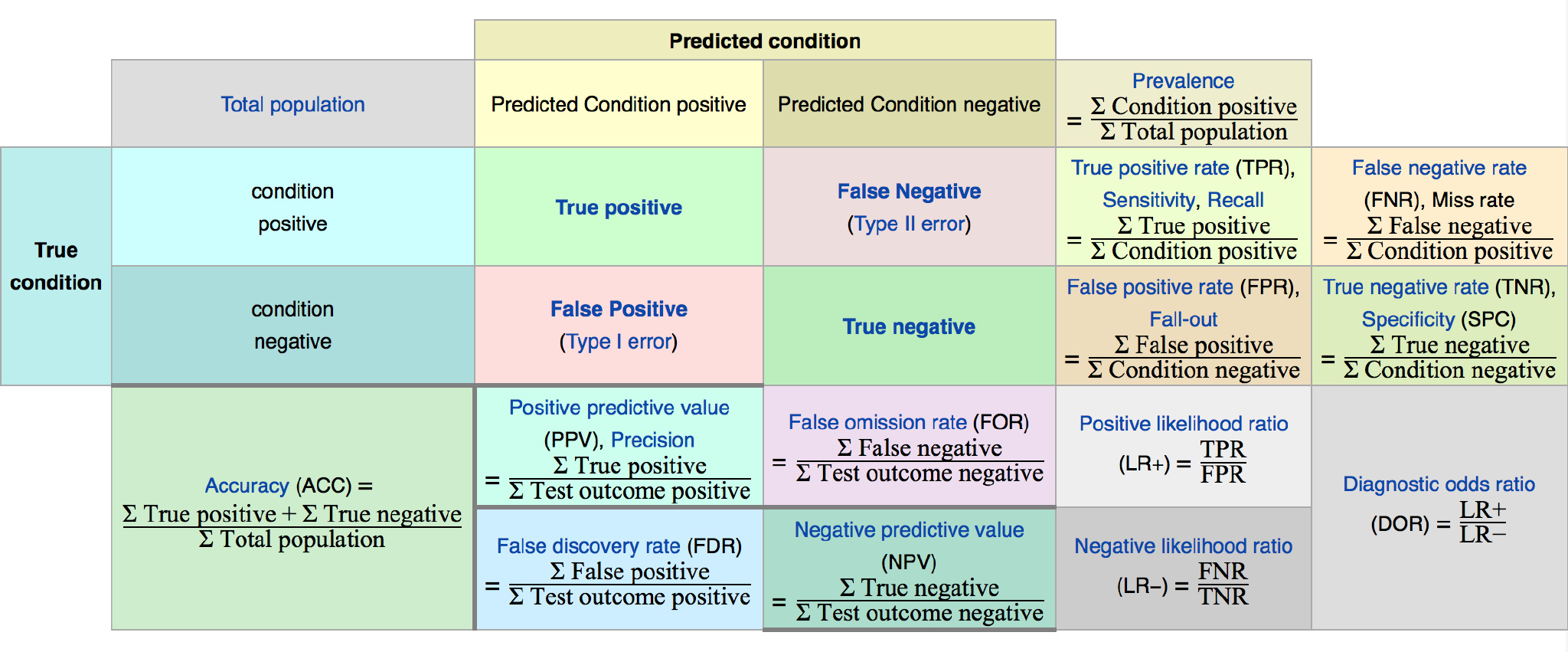
准确率定义:
召回率定义:
Recall=TPTP+FN
| 集合表示 | 形象化解释 |
|---|---|
 |  |
| 准确率与召回率之间的权衡可以使用PR曲线来衡量 |
|---|
 |
将准确率和召回率相结合可以得到一些更实用的度量方式
F1度量定义:
F1是基于准确率和召回率的 调和平均定义的
在一些应用中,对准确率和召回率的重视程度不同,例如在商品推销系统中,为了尽可能少打扰用户,更希望推荐内容是用户感兴趣的,此时准确率更重要.而在逃犯信息检索系统中,更希望尽可能少漏掉逃犯,此时召回率比较重要.
将F1一般化可得到
Fβ
的定义: