论文阅读之A Challenge Dataset and Effective Models for Aspect-Based Sentiment Analysis(2019)
Posted Icy Hunter
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文阅读之A Challenge Dataset and Effective Models for Aspect-Based Sentiment Analysis(2019)相关的知识,希望对你有一定的参考价值。
文章目录
前言
读这篇论文之前,我们得先大概了解一下方面级情感分析是什么。
Aspect-Category Sentiment Analysis(ACSA):给定Aspect类别(预定义),进行情感极性分类
Aspecct-Term Sentiment Analysis(ATSA):识别关于文章出现的目标实体的情感极性
例如一句话:
Average to good Thai food, but terrible delivery
ATSA: target: “Thai food” polarity: “Positive”
其中target表示句子中出现的方面词,预测方面词的情感倾向
ACSA:Category : “service” polarity: “Negative”
其中Category表示一类事物的范畴,不一定是在句子里出现的词,而是预先设定的范畴。
也就是说,方面级情感分析就是对一句话中的某个方面词或者提及的那类事务的情感分析。
论文阅读
接下来言归正传A Challenge Dataset and Effective Models for Aspect-Based Sentiment
Analysis这篇论文从标题来看,就知道方面级情感分析还是比较难搞的。
这篇文章的主要贡献如下:
(1)手动注释了一个大规模的多方面多情感数据集,防止 ABSA 退化为句子级情感分析。它的发布将推动ABSA的研究。
(2) 提出了一种新的基于胶囊网络(capsule network)的模型来学习方面和上下文之间的复杂关系。
(3) 实验结果表明,所提出的方法比最先进的基线方法取得了明显更好的结果。
这篇文章提出了MAMS(Multi-Aspect Multi-Sentiment)数据集,就是说他保证每句话都至少有两个不同的方面,也有两个不同的情感极性,因为如果只有一个方面或者情感极性都相同,那么就退化成了句子级情感分析了,这就把问题搞简单了(大概这个意思吧)。
所有如果你觉得你提出方面级情感分析模型效果好,一定要这个数据集跑一跑,不然论文审稿可能就还得来补实验。
数据集人家花时间标的,我们直接拿来用就行了,应该没什么难度,文章提出的使用了capsule的模型。还是有点意思的,因为capsule最先用于解决CNN位置信息问题的,接下来就好好读一读论文里的相关内容。
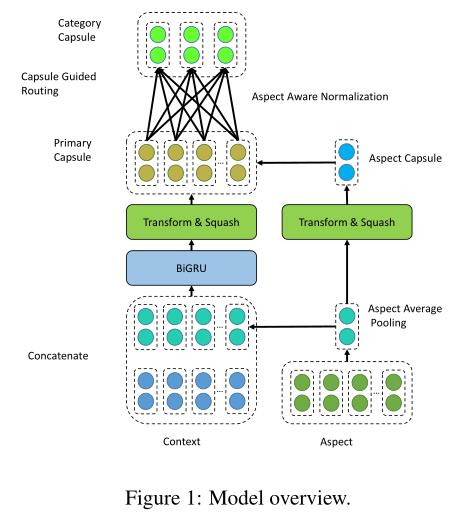
首先呈现一下模型结构图。
变量定义

D表示句子的集合。
S表示一个句子,长度用n表示
w表示的就是一个个词
At 表示方面词的集合,是在句子里出现过的词,长度用m表示
Ac表示范畴词的集合,是预先定义好的各类范畴,例如food、service等。
y就是表示方面词的情感标签了
Embedding Layer
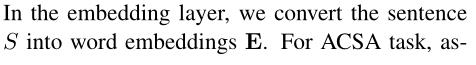

通过embedding层,将句子S中的每个词向量化得到E,值得注意的是,这里如果是方面词,因为在句子中出现,是明确包含具体语义的,那么就通过预训练模型中的词向量平均池化得到a,如果这里是预先定义的范畴即对Category进行识别,那么这个词的向量就随机初始化,因为这个其实相当于一个标签一样的东西,随机初始化自己学就行了。
得到句子和方面词的向量化后,就得到Eisa = [Ei:a],表示第i个句子和其中的待预测的方面词的向量表示,二者是拼接操作。
Encoding Layer

就是使用双向GRU+残差连接,将E转变为包含上下文语义的H
Primary Capsule Layer

初始胶囊层,pi由包含上下文词向量hi来生成
c则由方面词向量来生成
如果不懂capsule network可能看到这里有点懵,可以看看论文阅读之Dynamic Routing Between Capsules(2017)
Aspect Aware Normalization
由于句子长度可变,发送到上层胶囊的初级胶囊数量因句子而异,导致训练过程不稳定。极长的句子会使壁球激活饱和,并导致所有类别的置信度很高;而相反,非常短的句子会导致所有类别的置信度低下。为了缓解这个问题,提出了 aspect aware normalization,它利用 aspect capsule 来选择重要的 primary capsule,并通过以下方式对 primary capsule 权重 u 进行归一化:

这个主要是为了缓解因为句长有别导致预测置信度不平衡的问题。
Capsule Guided Routing
Capsule Guided Routing 原始动态路由机制 (Sabour et al, 2017) 由于路由的迭代过程而导致训练效率低下。并且没有用于指导路由过程的上层信息,这使动态路由像一个自我指导的过程一样工作。
文章设计了一种胶囊引导路由机制,而不是在路由过程中计算主胶囊和类别胶囊之间的耦合系数,该机制利用关于情感类别的先验知识来有效和高效地指导路由过程。具体来说,我们使用一组情感胶囊来存储关于情感类别的先验知识。
设 G ∈ RC×d为情感矩阵,用情感词的平均嵌入进行初始化。 C是情感类别的数量,d是情感嵌入的维度。我们可以通过在情感矩阵上应用挤压激活来获得情感胶囊 Z = [z1, …, zC] 并通过计算主胶囊和情感胶囊之间的相似性来计算路由权重 w:
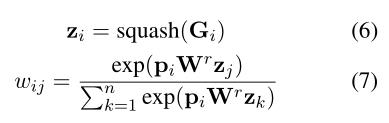
大概意思就是,原始的capsule net的动态路由调整是完全根据输入向量来调整的,当输入向量和得出的向量越相似时,输入的向量权重就会越大,这其实有点断章取义的味道,可能导致训练的效率低下,而文章采用使用一个已知的情感类别的先验知识矩阵来指导路由权重w的调整。
Category Capsule Layer

v就是类别胶囊了,也就是能够用于分类的结果了。
其中wij就是根据情感矩阵指导得出的路由权重。
ui则是防止词长区别对结果置信度不平衡情况的调节。
pi则是初始胶囊层的结果。
s时一组可学习的参数用来将连接权重缩放到合适的水平。
这里就相当于将句子+方面词聚合成了一个表示的向量,从而能够进行最终的分类了。
损失函数

CapsNet-BERT


使用Bert作为输入capsule的编码就直接句子+方面词得到Bert结果作为输入即可,embedding layer和encoding layer直接用bert来代替了,得出词向量进行后续计算。
实验结果
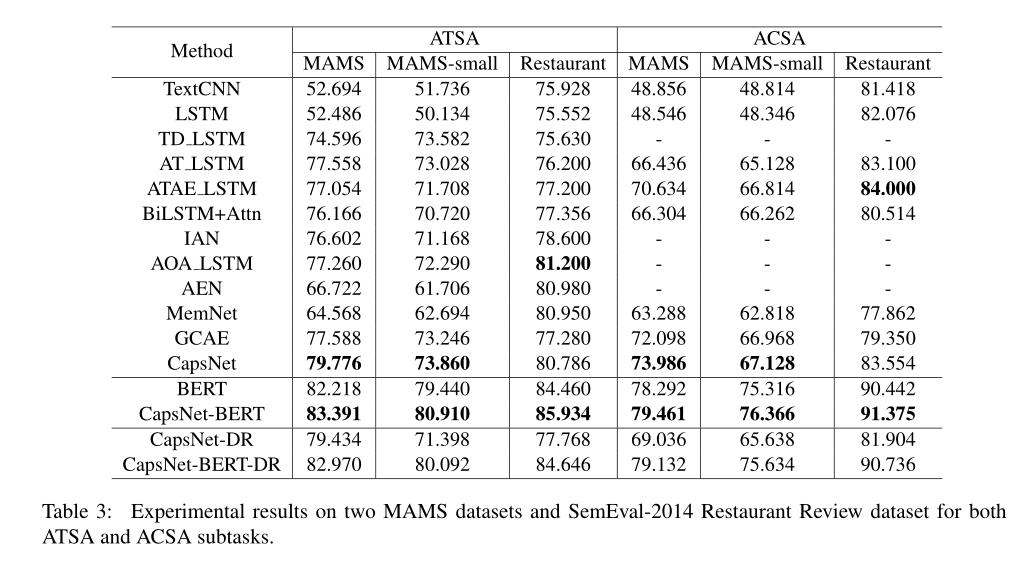
实验表明,模型效果很好,并且做了消融实验,当使用原来的动态路由时,性能是会有所下降的。所有使用类似情感词典来做路由引导,还是有一定效果的(但不多吧)
参考
A Challenge Dataset and Effective Models for Aspect-Based Sentiment
Analysis
[ACL 2018] GCAE : 在ABSA任务上用CNN
以上是关于论文阅读之A Challenge Dataset and Effective Models for Aspect-Based Sentiment Analysis(2019)的主要内容,如果未能解决你的问题,请参考以下文章