胶囊网络(Capsule)学习笔记
Posted 梆子井欢喜坨
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了胶囊网络(Capsule)学习笔记相关的知识,希望对你有一定的参考价值。

1. 前言
最近学习了一下胶囊网络(Capsule Net),这里写一篇博客记录学习笔记。
胶囊网络于2017年,由深度学习先驱Hinton发布的开源论文《Dynamic Routing Between Capsules》提出。
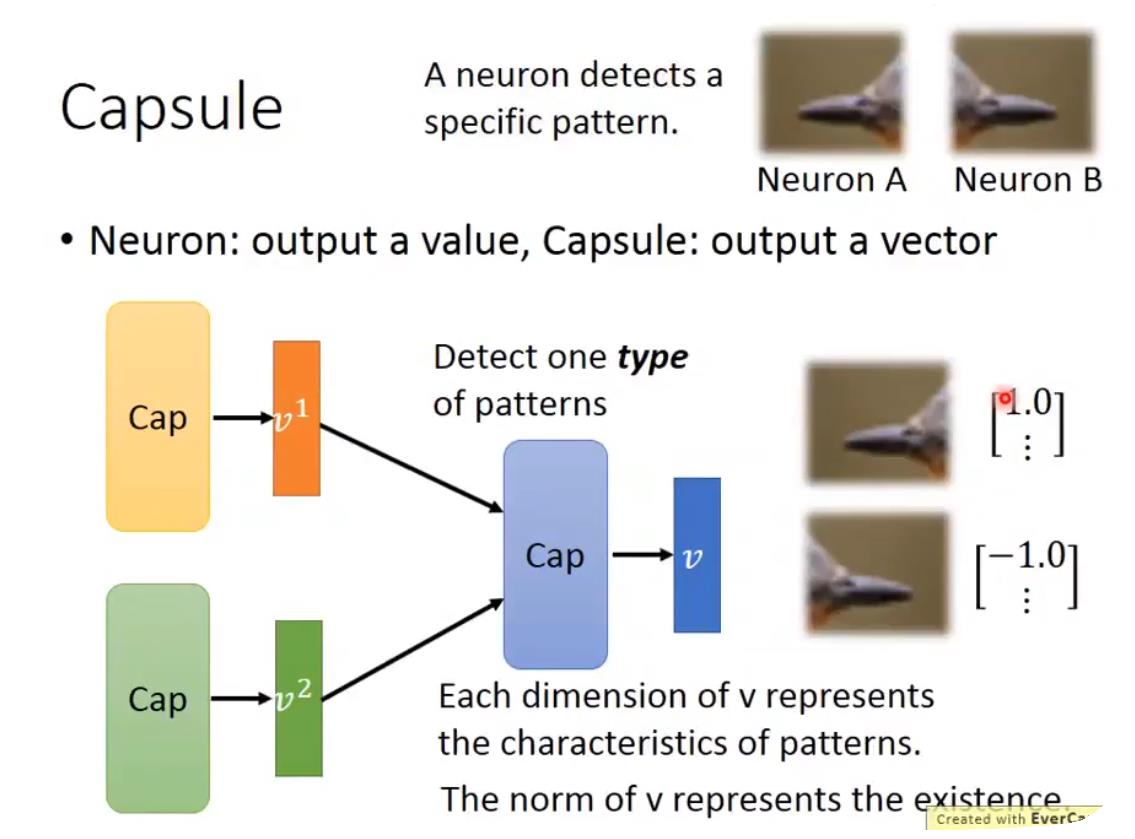
胶囊网络的特点是“vector in vector out”,取代了以往神经元的“scalar in scalar out”。
Q: 什么是“胶囊”呢?
A: 只要把一个向量当作一个整体来看,它就是一个“胶囊”。
每一个胶囊表示一个特征,Capsule输出的向量的模值大小表示有没有这个特征,而向量的每一维表示这个特征的特点。
以前只是用一个标量表示有没有这个特征(比如有没有鸟嘴),现在我们用一个向量来表示,不仅仅表示有没有,还表示“有什么样的”(比如鸟嘴的颜色、形状、方向等)。
如下图所示,以前可能要用两个不同的神经元来识别“朝左的鸟嘴”和“朝右的鸟嘴”。而这两个图像通过胶囊网络输出的向量可能都比较大,表明它们都是“鸟嘴”,而输出向量的某一维可能分别是1和-1,表明鸟嘴的朝向不同。
底层的胶囊和高层的胶囊构成一些连接关系,它们的关系会在下文中详细描述。
大致地了解了胶囊网络以后,直接进入正题,讲解胶囊网络的结构与算法。
2. 模型结构
2.1 高层特征是底层特征的某种聚类
Capsule的核心思想就是输出是输入的某种聚类结果。
假设有:
低层特征: u1, u2, u3, u4, u5
高层特征: v1, v2, v3, v4

Q: 如何融合这些特征,构成更高级的特征?
A: 用点积softmax做相似度的度量(类似于注意力机制),来决定高层特征中低层特征向量的占比。

(上图是一个较为直观的想法,来自参考资料[1],论文中的计算细节与此不同)
观察上面的公式,发现左右两边都有vj,这就变成了一个“鸡生蛋,蛋升鸡”的问题。很容易能想到EM算法,如k-means聚类算法就是EM算法的一个特例。为了得到各个vj,设置初始值,然后开始迭代就好。输出是输入的聚类结果,而聚类通常都需要迭代算法,这个迭代算法就称为“动态路由”。
v1,v2,v3,v4其实就是各个底层传入的特征的累加。
squash函数只是做一个标量上的压缩,不改变向量的方向。
在论文中, u i u_i ui并不是直接进行加权求和得到 s j s_j sj,而是与一个权重矩阵 W i j W_ij Wij相乘,得到一个预测向量 u j ∣ i ^ \\hatu_j|i uj∣i^,再进行求和。
W
i
j
W_ij
Wij是通过反向传播训练出来的,参数矩阵的个数等于输入输入胶囊数目乘以输出胶囊数目。

全连接版的capsule图示如下:

2.1 Squash
Hinton希望Capsule能有的一个性质是:胶囊的模长能够代表这个特征的概率,因此要做一个归一化操作。

当向量x的模长趋于正无穷时,squash(x)趋于1;当向量x的模长趋于0时,squash(x)趋于0。

如上图所示,在生成高层胶囊向量时,要做这样一个squash函数,squash函数只会压缩向量s的模值,不会改变s的方向。
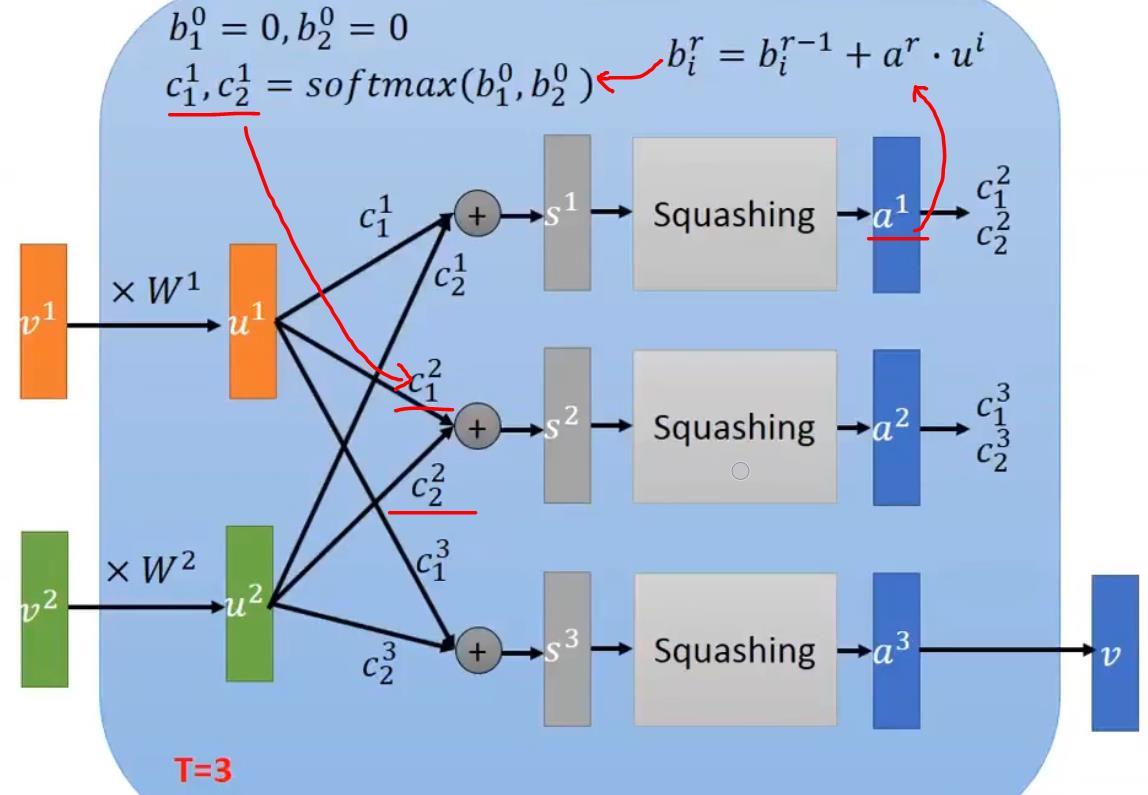
2.2 Dynamic Routing
动态路由主要是指,计算高层胶囊v时,u1和u2对应的系数c1和c2不是通过反向传播学到的,而是在testing的时候在线动态更新得到的。
如果某一个向量与其它的向量距离较远的话,它的weight就会越来越小。
如下图所示,假设灰色的向量(s)与绿色和橙色的向量长得很像的话,就会越来越靠近它们。
迭代的计算过程示例,整个过程有点类似于聚类。

b
i
j
b_ij
bij代表低层胶囊i和高层胶囊j匹配的概率,最初初始化均为0。
计算
v
j
v_j
vj的加权求和系数,是由
b
i
j
b_ij
bij经过softmax函数计算得到的。

下面来看看完整的动态路由算法:

大体思想与前述相同,需要注意的是
b
i
j
b_ij
bij的更新方式。
b
i
j
b_ij
bij不断地累加当前迭代中
v
j
v_j
vj与预测向量
u
j
∣
i
^
\\hatu_j|i
uj∣i^的相似度,然后进行softmax。
3. 在MNIST数据集上实验
论文中所用的模型

读原文没能完全理解论文中的卷积操作,参考知乎回答:如何看待Hinton的论文《Dynamic Routing Between Capsules》? - 云梦居客
首先要把灰度图像转化为Capsule可用的形式
MNIST中的图像数据为28x28
第一个卷积层使用256个9x9的卷积核(stride = 1)提取特征,得到256x20x20的数据
第二层PrimaryCaps有32个通道的卷积核,每个primary capsule有8个卷积单元,每个卷积单元尺寸为9x9(stride = 2)
The second layer (PrimaryCapsules) is a convolutional capsule layer with channels of convolutional 32 8D capsules (i.e. each primary capsule contains 8 convolutional units with a 9x9 kernel and a stride of 2).
Each primary capsule output sees the outputs of all 256 × 81 Conv1 units whose receptive fields overlap with the location of the center of the capsule.
这里需要注意一下,一般来说,卷积核有几个通道,就输出几个feature map,那这里得到的数据应当是6x6x32。
(通过原文知道,这里卷积核大小应该是9x9x256)
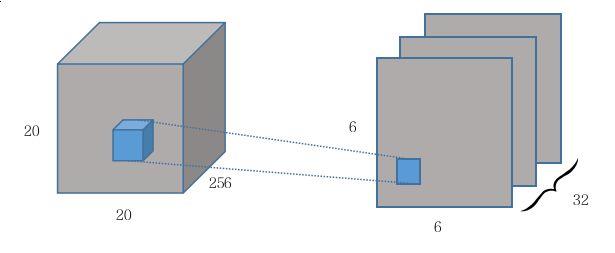
与原文的Figure 2对比可以看出,原本convolution每次的计算输出是一个scalar value,现在到了PrimaryCaps这里成了一个长度为8的vector,也就是从6x6x1x32到了6x6x8x32。
这篇知乎回答的推测是用8个不同的conv2d层做了共8次32 channel, 9x9 kernel size和strides 2的卷积(每个conv2d分别一次),每次都得到一个6x6x1x32的输出,共8个,再把这些输出在6x6x1x32的第三个纬度上concatenate, 就得到了第二层最终的输出:6x6x8x32大小的高维矩阵。另一个个人的猜想是做了一个Depthwise Convolution,然后在同一个位置上不求和。暂不知道正确与否,可能要读源代码才能搞清楚。
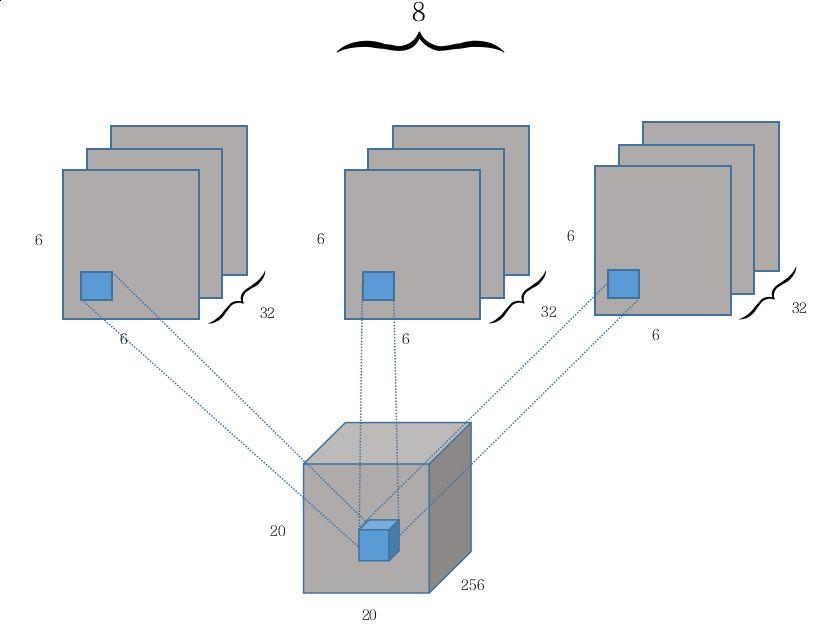
经此,PrimaryCaps具有[32×6×6]胶囊输出(每个输出是8D向量),并且[6 × 6]网格中的每个胶囊彼此共享它们的权重。
接下来对每个长度为8的vector做了文中的Eq. 1的向量单位化和缩放操作。
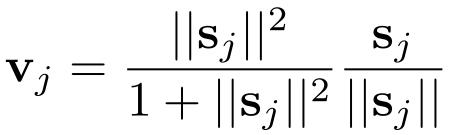
第三层(DigitCaps)在第二层的输出之上就开始使用动态路由算法。因为是手写数字的识别,所以最终输出的胶囊数量为10,每个胶囊的活动向量的长度表示每个类别的实例的存在,并用于计算分类损失。
现在我们有32×6×6个低层胶囊(8-D),要生成10个高层胶囊(16-D)
W
i
,
j
W_i,j
Wi,j是每个
u
i
,
i
∈
(
1
,
32
×
6
×
6
)
u_i, i \\in (1, 32 \\times 6 \\times 6)
ui,i∈(1,32×6×6)和每个
v
j
,
j
∈
(
1
,
10
)
v_j, j\\in (1, 10)
vj,j∈(1,10)之间的权重矩阵,尺寸为8x16。
另一部分是用解码器重构数字图像。
现在输入“1”的图片,希望第1个Cap输出的vector的模值越大,其他的Cap输出的vector的模值越小。
将CapsNet的输出输入一个NN试图重构数字的图像,比如输入“1”的图像,重构的时候就只用v1。

重构数字图像所用的网络结构,为一个全连接层

4. 实验结果分析
Baseline:CNN

调整v1中不同维度的值,就可以指导这个维度代表了什么特征,比如笔画的粗细,旋转等。

对重叠数字图像的识别

5. 胶囊与神经元对比
下面是来自参考3的一张图,很好地对比了胶囊与传统的神经元

例如识别数字“1”的图像和其翻转图像,在传统NN中输出应当是接近的,因为向量的每一维代表数字为几的概率。
而在CapsNet中,两张图像经过Cap 1 输出的向量v1的模值都会较大,表示这是1,但向量中每一维的值会是不同的。

相比采用Max Pooling的CNN,Capsule有看到输入之间的差别(输出的vector是不一样的),只不过在最后取norm的时候没有用这个差别。

6. 学习参考
[1] 揭开迷雾,来一顿美味的Capsule盛宴
[2] 李宏毅讲解胶囊网络
[3] naturomics/CapsNet-Tensorflow
以上是关于胶囊网络(Capsule)学习笔记的主要内容,如果未能解决你的问题,请参考以下文章