Spark成长之路-消息队列
Posted Q博士
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark成长之路-消息队列相关的知识,希望对你有一定的参考价值。
参考文章:Spark分布式消息发送流程
监听器模式
volatile
因为之前被这个消息队列坑过(stage夯住原因分析),所以现在研究源码,先从它下手,解答一下我这么久的疑惑。
继承关系
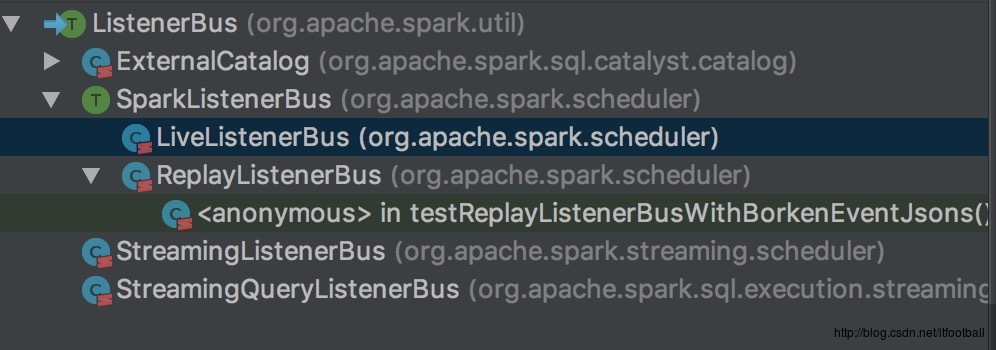
ListenerBus->SparkListenerBus->LiveListenerBus。原始基类为ListenerBus。运用的设计模式为监听器模式。
ListenerBus
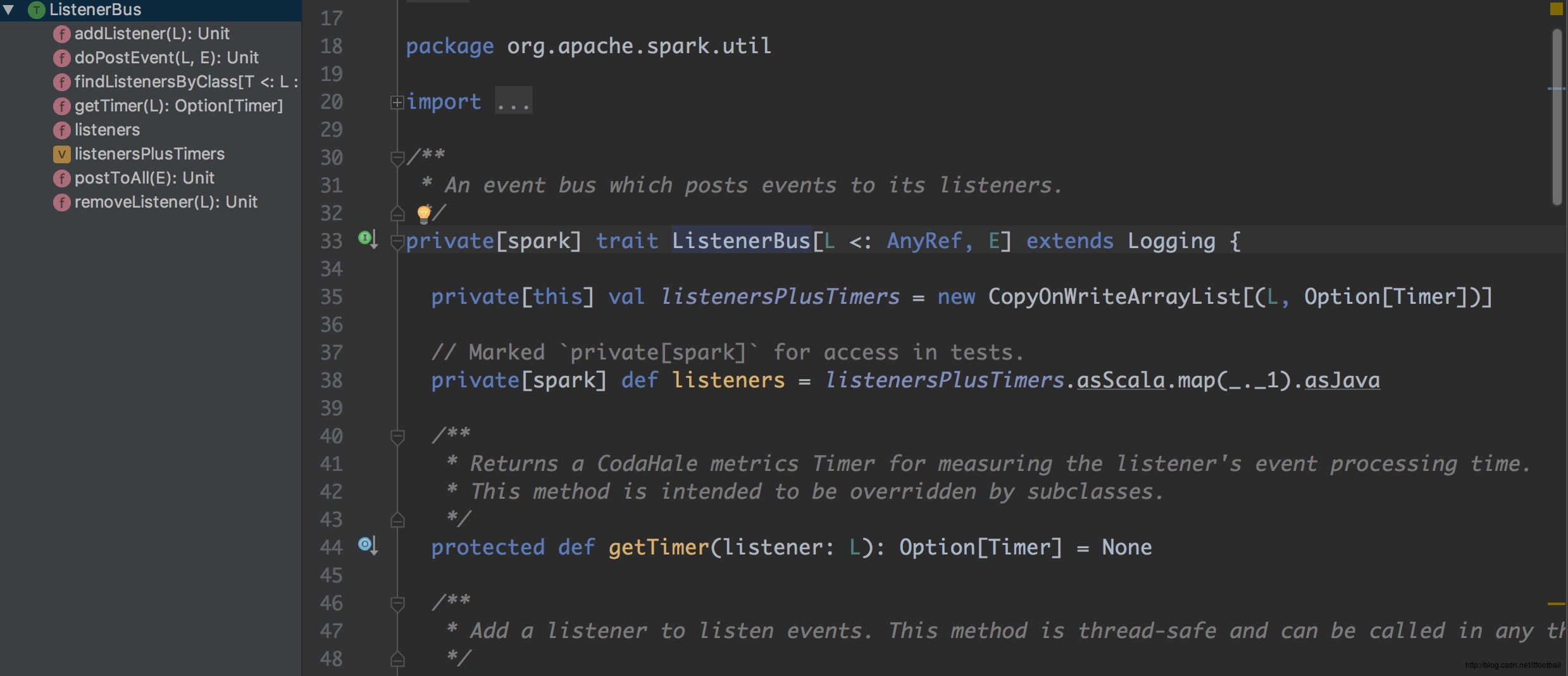
spark包中私有特质,继承自Logging(方便输出log),来熟悉一下它的成员变量
listenersPlusTimers 成员变量
类私有变量,CopyOnWriteArrayList为线程安全的列表,可以将其当做一个ArrayList(+线程安全)。存放的对象是一个二元组,二元组的第一个元素是一个引用型对象,第二个元素是一个Option对象,获取监听者的定时器,也可为None。
private[this] val listenersPlusTimers = new CopyOnWriteArrayList[(L, Option[Timer])]listeners 方法
将CopyOnWriteArrayList转换为Java的集合,这里应该是util.List。
private[spark] def listeners = listenersPlusTimers.asScala.map(_._1).asJavaaddListener 方法
该方法用final定义,表示不能被继承重写。该方法为添加观察者,监听器模式标配方法之一。
final def addListener(listener: L): Unit =
listenersPlusTimers.add((listener, getTimer(listener)))
removeListener 方法
监听器模式标配方法之二,移除监听者
final def removeListener(listener: L): Unit =
listenersPlusTimers.asScala.find(_._1 eq listener).foreach listenerAndTimer =>
listenersPlusTimers.remove(listenerAndTimer)
getTimer 方法
获取监听器中的定时器
protected def getTimer(listener: L): Option[Timer] = NonepostToAll 方法
向每一个监听器发送事件。
def postToAll(event: E): Unit =
// JavaConverters can create a JIterableWrapper if we use asScala.
// However, this method will be called frequently. To avoid the wrapper cost, here we use
// Java Iterator directly.
val iter = listenersPlusTimers.iterator
while (iter.hasNext)
val listenerAndMaybeTimer = iter.next()
val listener = listenerAndMaybeTimer._1
val maybeTimer = listenerAndMaybeTimer._2
val maybeTimerContext = if (maybeTimer.isDefined)
maybeTimer.get.time()
else
null
try
doPostEvent(listener, event)
catch
case NonFatal(e) =>
logError(s"Listener $Utils.getFormattedClassName(listener) threw an exception", e)
finally
if (maybeTimerContext != null)
maybeTimerContext.stop()
findListenersByClass 方法
根据类名反射出对应的监听器列表。
private[spark] def findListenersByClass[T <: L : ClassTag](): Seq[T] =
val c = implicitly[ClassTag[T]].runtimeClass
listeners.asScala.filter(_.getClass == c).map(_.asInstanceOf[T]).toSeq
doPostEvent 方法
向指定监听器发送事件,子类具体实现。
protected def doPostEvent(listener: L, event: E): UnitSparkListenerBus
之前说过doPostEvent这个方法,交由子类去实现。ok,来看看SparkListenerBus怎么实现的吧。
SparkListenerBus很没脸没皮的就只有这一个方法,其他啥都没有,该类已经把listener和event具体指向了SparkListenerInterface和SparkListenerEvent。该方法用模式匹配,来具体调用不同监听器的发送事件的方法。
protected override def doPostEvent(
listener: SparkListenerInterface,
event: SparkListenerEvent): Unit =
event match
case stageSubmitted: SparkListenerStageSubmitted =>
listener.onStageSubmitted(stageSubmitted)
case stageCompleted: SparkListenerStageCompleted =>
listener.onStageCompleted(stageCompleted)
case jobStart: SparkListenerJobStart =>
listener.onJobStart(jobStart)
case jobEnd: SparkListenerJobEnd =>
listener.onJobEnd(jobEnd)
case taskStart: SparkListenerTaskStart =>
listener.onTaskStart(taskStart)
case taskGettingResult: SparkListenerTaskGettingResult =>
listener.onTaskGettingResult(taskGettingResult)
case taskEnd: SparkListenerTaskEnd =>
listener.onTaskEnd(taskEnd)
case environmentUpdate: SparkListenerEnvironmentUpdate =>
listener.onEnvironmentUpdate(environmentUpdate)
case blockManagerAdded: SparkListenerBlockManagerAdded =>
listener.onBlockManagerAdded(blockManagerAdded)
case blockManagerRemoved: SparkListenerBlockManagerRemoved =>
listener.onBlockManagerRemoved(blockManagerRemoved)
case unpersistRDD: SparkListenerUnpersistRDD =>
listener.onUnpersistRDD(unpersistRDD)
case applicationStart: SparkListenerApplicationStart =>
listener.onApplicationStart(applicationStart)
case applicationEnd: SparkListenerApplicationEnd =>
listener.onApplicationEnd(applicationEnd)
case metricsUpdate: SparkListenerExecutorMetricsUpdate =>
listener.onExecutorMetricsUpdate(metricsUpdate)
case executorAdded: SparkListenerExecutorAdded =>
listener.onExecutorAdded(executorAdded)
case executorRemoved: SparkListenerExecutorRemoved =>
listener.onExecutorRemoved(executorRemoved)
case executorBlacklisted: SparkListenerExecutorBlacklisted =>
listener.onExecutorBlacklisted(executorBlacklisted)
case executorUnblacklisted: SparkListenerExecutorUnblacklisted =>
listener.onExecutorUnblacklisted(executorUnblacklisted)
case nodeBlacklisted: SparkListenerNodeBlacklisted =>
listener.onNodeBlacklisted(nodeBlacklisted)
case nodeUnblacklisted: SparkListenerNodeUnblacklisted =>
listener.onNodeUnblacklisted(nodeUnblacklisted)
case blockUpdated: SparkListenerBlockUpdated =>
listener.onBlockUpdated(blockUpdated)
case _ => listener.onOtherEvent(event)
有时间我把SparkListenerInterface, SparkListenerEvent这两个子系统的逻辑理一下。
LiveListenerBus
该类有一个伴生对象,还有一个附属对象LiveListenerBusMetrics。接下来一一来解释
eventQueue 成员变量
消息队列,我编写这个文章的核心,注释中解释了为什么要限制这个队列的大小,因为如果添加的速度大于消费的速度,那就有可能造成OOM。如果不设置spark.scheduler.listenerbus.eventqueue.size参数,默认为10000。
// Cap the capacity of the event queue so we get an explicit error (rather than
// an OOM exception) if it's perpetually being added to more quickly than it's being drained.
private val eventQueue =
new LinkedBlockingQueue[SparkListenerEvent](conf.get(LISTENER_BUS_EVENT_QUEUE_CAPACITY))metrics 成员变量
private[spark] val metrics = new LiveListenerBusMetrics(conf, eventQueue)存放各项配置的对象。
listenerThread成员变量
private val listenerThread = new Thread(name)
setDaemon(true)
override def run(): Unit = Utils.tryOrStopSparkContext(sparkContext)
LiveListenerBus.withinListenerThread.withValue(true)
val timer = metrics.eventProcessingTime
while (true)
eventLock.acquire()
self.synchronized
processingEvent = true
try
val event = eventQueue.poll
if (event == null)
// Get out of the while loop and shutdown the daemon thread
if (!stopped.get)
throw new IllegalStateException("Polling `null` from eventQueue means" +
" the listener bus has been stopped. So `stopped` must be true")
return
val timerContext = timer.time()
try
postToAll(event)
finally
timerContext.stop()
finally
self.synchronized
processingEvent = false
线程对象,首先设置为守护进程。然后将代码块传递给Utils.tryOrStopSparkContext方法中去执行,这个方法具有catch异常的作用,发现异常后停止SparkContext。然后使用LiveListenerBus.withinListenerThread.withValue(true)来讲变量设置为true后执行后续代码块,执行完毕后,设置回原始值。然后进入死循环,执行语句前后分别设置processingEvent为true,表示真正处理事件过程中,处理完后设置为false标识空闲状态。然后就是从消息队列中poll消息,发送消息。Timer的作用使计算耗时。
总体来说,这个方法是一个异步执行的线程方法,具有线程安全,锁机制。具体为了什么加这些东西,需要研究到调用方有哪些才清楚。
start 方法
入口方法,调用方为SparkContext:
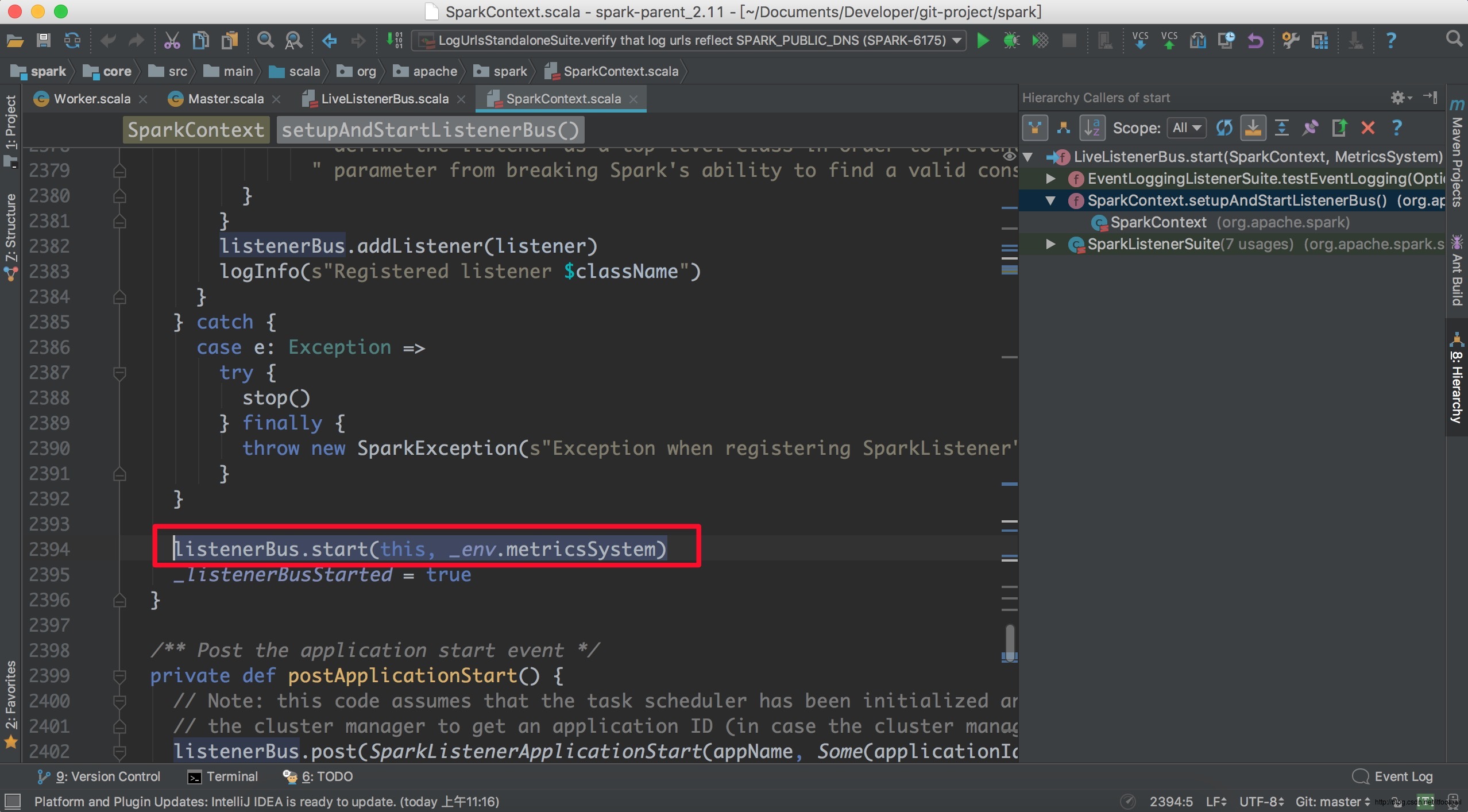
其实就是调用执行“listenerThread线程
def start(sc: SparkContext, metricsSystem: MetricsSystem): Unit =
if (started.compareAndSet(false, true))
sparkContext = sc
metricsSystem.registerSource(metrics)
listenerThread.start()
else
throw new IllegalStateException(s"$name already started!")
post 方法
向队列中添加事件。val eventAdded = eventQueue.offer(event)这行代码为向队列中添加元素,添加成功则返回true,队列已满则返回false。如果队列满了,所以这里如果超过了队列的长度,新消息就被抛弃了,好尴尬。
def post(event: SparkListenerEvent): Unit =
if (stopped.get)
// Drop further events to make `listenerThread` exit ASAP
logError(s"$name has already stopped! Dropping event $event")
return
metrics.numEventsPosted.inc()
val eventAdded = eventQueue.offer(event)
if (eventAdded)
eventLock.release()
else
onDropEvent(event)
val droppedEvents = droppedEventsCounter.get
if (droppedEvents > 0)
// Don't log too frequently
if (System.currentTimeMillis() - lastReportTimestamp >= 60 * 1000)
// There may be multiple threads trying to decrease droppedEventsCounter.
// Use "compareAndSet" to make sure only one thread can win.
// And if another thread is increasing droppedEventsCounter, "compareAndSet" will fail and
// then that thread will update it.
if (droppedEventsCounter.compareAndSet(droppedEvents, 0))
val prevLastReportTimestamp = lastReportTimestamp
lastReportTimestamp = System.currentTimeMillis()
logWarning(s"Dropped $droppedEvents SparkListenerEvents since " +
new java.util.Date(prevLastReportTimestamp))
如果添加失败后调用onDropEvent,就是把相关计数器加1,并输出log,只输出一次。
def onDropEvent(event: SparkListenerEvent): Unit =
metrics.numDroppedEvents.inc()
droppedEventsCounter.incrementAndGet()
if (logDroppedEvent.compareAndSet(false, true))
// Only log the following message once to avoid duplicated annoying logs.
logError("Dropping SparkListenerEvent because no remaining room in event queue. " +
"This likely means one of the SparkListeners is too slow and cannot keep up with " +
"the rate at which tasks are being started by the scheduler.")
因为消息队列满的日志消息在某个时刻只输出一遍,超过一分钟以后会重置:
val droppedEvents = droppedEventsCounter.get
if (droppedEvents > 0)
// Don't log too frequently
if (System.currentTimeMillis() - lastReportTimestamp >= 60 * 1000)
// There may be multiple threads trying to decrease droppedEventsCounter.
// Use "compareAndSet" to make sure only one thread can win.
// And if another thread is increasing droppedEventsCounter, "compareAndSet" will fail and
// then that thread will update it.
if (droppedEventsCounter.compareAndSet(droppedEvents, 0))
val prevLastReportTimestamp = lastReportTimestamp
lastReportTimestamp = System.currentTimeMillis()
logWarning(s"Dropped $droppedEvents SparkListenerEvents since " +
new java.util.Date(prevLastReportTimestamp))
我们来看看谁调用了这个post方法,向队列中添加事件的。
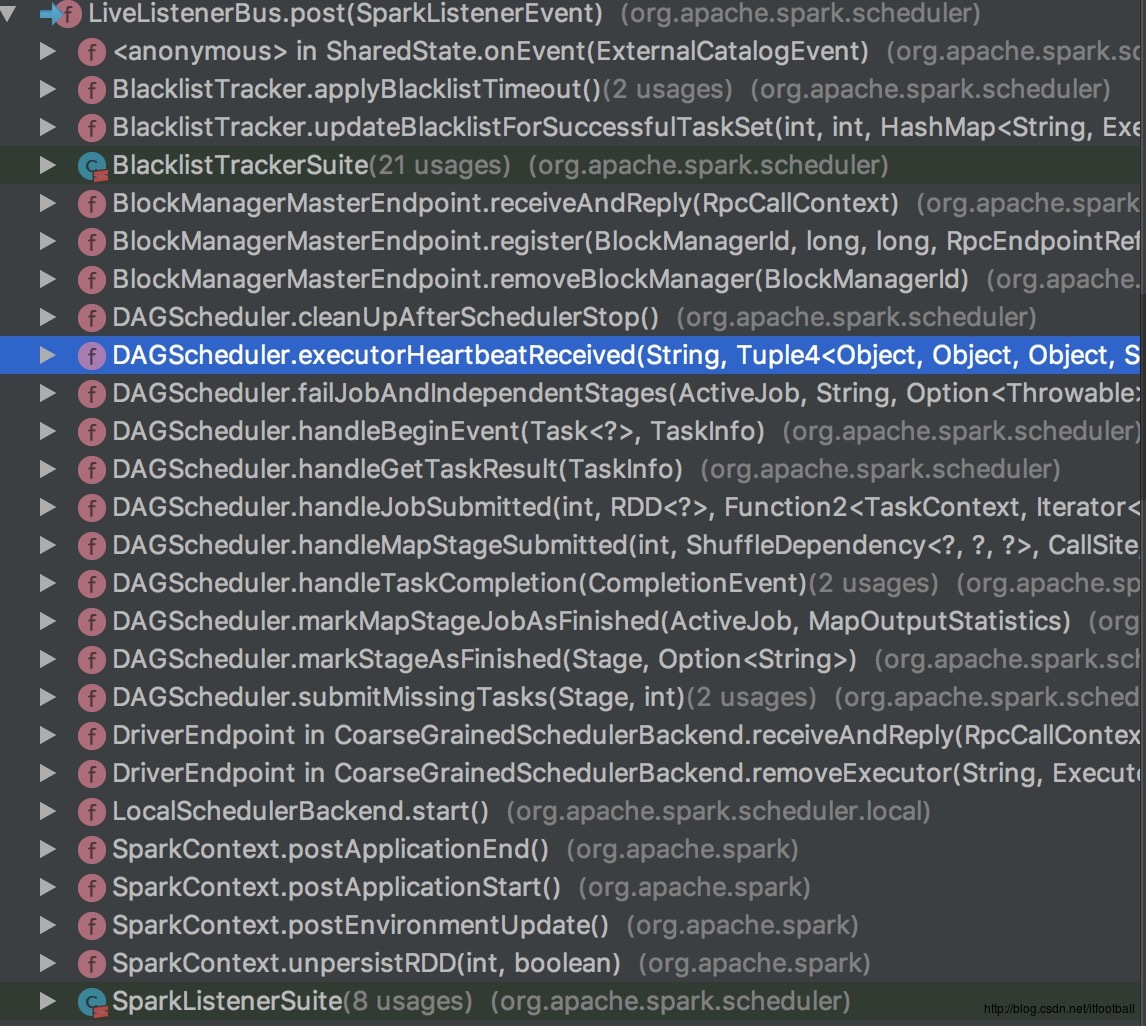
有DAGScheduler,SparkContext,我会在下一篇文章任务调用中详细说这个DAGScheduler。总体来说就是在这两个类中负责添加事件,但是我们是分布式的系统,其中有Master和Worker的概念在里面,上执行架构图:
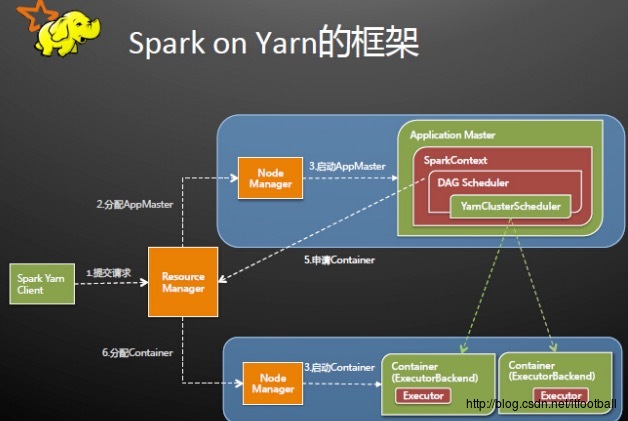
从图中可以看出来,DAGScheduler是存在于SparkContext,隶属于Master,那说明Worker和Master直接通过nio进行消息的传递,Master接受到信息并解析以后,委托DAGScheduler去提交响应的事件。
总结
消息队列的研究就告一段落了,发现还有很多东西要去学,现在只是在学spark-core的东西,我真正的做的spark-streaming还在等着我呢。时间不够用啊~
以上是关于Spark成长之路-消息队列的主要内容,如果未能解决你的问题,请参考以下文章