为啥用abbyy图片转为word全是乱码
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了为啥用abbyy图片转为word全是乱码相关的知识,希望对你有一定的参考价值。
ABBYY FineReader 是一款OCR图文识别软件,能够快速方便地将扫描纸质文档、PDF文件和数码相机的图像转换成可编辑、可搜索的文本,包括Word、Excel等格式。可按以下步骤将图片转为Word:
将图像文件转换成Word文档的过程如下:
步骤一:打开ABBYY FineReader 12,进入软件首页,在任务面板点击图像或PDF文件到Microsoft Word。
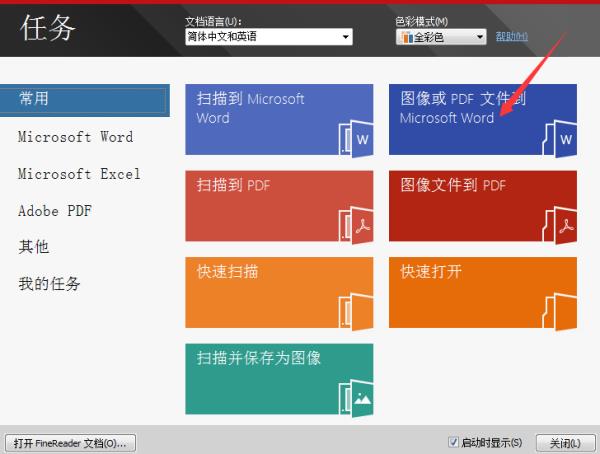
步骤二:在打开图像对话框中选择要转换为Word文档的图像文件,然后点击打开。
注意:请确保图像够清晰,ABBYY FineReader在识别文档时清晰度越高,识别率越高,否则转换后的文字可能存在很多识别错误。
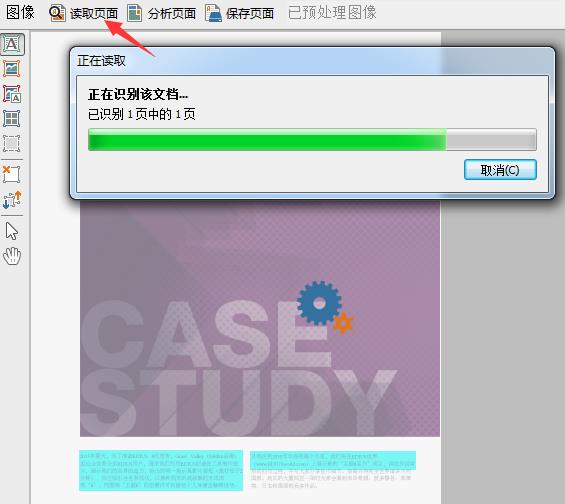
步骤三:打开图像文件之后,在工作区点击‘读取页面’按钮,等待ABBYY FineReader 12识别文档。
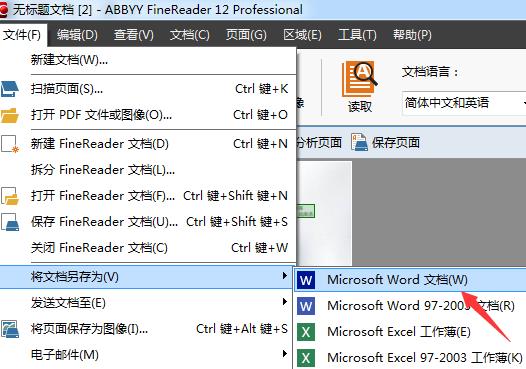
步骤四:完成识别文档之后,在‘文件’选项卡点击‘将文档另存为’,在出现的菜单中选择Word文档。或者点击工具栏上的‘保存’下拉按钮,选择另存为Microsoft Word文档,生成的新文本可编辑。
注意:由于没有设置校对工具以及受图像质量的影响,转换后的可编辑文本内容可能存在部分错误,建议对照原图像文件进行适当修改。
参考技术A 建议你是用acrobat 或者abbyy 这个 两款软件进行转换编辑Adobe公司推出的PDF格式是一种全新的电子文档格式。借助 Acrobat ,您几乎可以用便携式文档格
adobe-acrobat-x
式 (Portable Document Format,简称 PDF) 出版所有的文档。 PDF 格式的文档能如实保留原来的面貌和内容,以及字体和图像。这类文档可通过电子邮件发送,也可将它们存储在WWW 、企业内部网、文件系统或CD-ROM上,来供其他用户在 Microsoft Windows , Mac OS和 LINUX 等平台上进行查看。由于该格式使用Adobe公司开发的PostScript页面描述语言,使得页面中的文字和图形的质量得到质的飞跃。无论您是使用PDF文档进行网上阅读,还是打印、印刷出版,Adobe Acrobat都能给你最好效果。
ABBYY 是一家俄罗斯软件公司,在文档识别,数据捕获和语言技术的开发中居世界领先地位。其获奖产品 FineReader OCR 软件可以把静态纸文件和 PDF 文件转换成可管理的电子数据,可以大大节省您的时间和精力。
Word文件乱码XML
layout: default
title: Word文件乱码XML
category: [技术, 编码]
comments: true
---
文章介绍
一个朋友写的文档因为异常关机,导致全部文件变成了xml的乱码,正好帮他解决了,感觉这些或许有些帮助,就先记录下来了.
破损文件介绍
文件破坏之后,打开全是xml格式的文档,结构如下.

恢复过程
本来WSP有自动保存机智的,一般是在C:\Users\XX\AppData\Roaming\kingsoft\office6\backup这个目录下面.需要主意的是这里的XX一般是电脑的用户名.
当然,这个只能说是可能有,如果没有找到,估计只能找找你开启云同步没有,或者没有没有之前放在垃圾箱的老版本了.
好了,回归正题,找到了意外丢失的文档之后,打开是上图的效果,如果要还原的话,可以先用word打开,然后新建一个txt的文档,名字随便填写,然后把word里面打开的文件呈现的xml文档全部复制到txt里面去.在把txt的后缀名更改为xml.效果如下图:

因为没有格式化,所以只有一行数据,不知道格式化之后会不会影响原文件,没有测试.
之后,我们直接用word打开这个xml就行了,打开之后的效果如下图:

到了这一步,应该就不用我再多说了,直接另存为正常的word就行了.
说明
文档恢复只能说是幸运,碰巧看到word可以转换xml,然后先用自己的文档尝试了下,发现成功了,然后找朋友出错的文件实验,果然成功了,还好只是少量文件,如果文件太多,估计要写一个工具才行,不过一般应该不会出现大批量的错误吧,反正思路有了,谁弄个工具出来也轻松,欢迎留下工具,我就不弄了.
如有疑难,欢迎讨论.
参考文章
如何设置Word 2007生成的XML文件,编码为UTF-8?_Word联盟
版本记录
20180508 解决实际问题
20180509 确定博文主题及大纲
20180521 完成博客
以上是关于为啥用abbyy图片转为word全是乱码的主要内容,如果未能解决你的问题,请参考以下文章
php将图片转为二进制后,我想得到二进制的数据,但是直接在浏览上输出会乱码