KSP - 元编程编译提速的小助手
Posted datian1234
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了KSP - 元编程编译提速的小助手相关的知识,希望对你有一定的参考价值。
前言
前边一系列的协程文章铺垫了很久,终于要分析Flow了。如果说协程是Kotlin的精华,那么Flow就是协程的精髓。
通过本篇文章,你将了解到:
- 什么是流?
- 为什么引进Flow?
- Fow常见的操作
- 为什么说Flow是冷流?
1. 什么是流

自然界的流水,从高到低,从上游到下游流动。
而对于计算机世界的流:
数据的传递过程构成了数据流,简称流
比如想要查找1~1000内的偶数,可以这么写:
var i = 0
var list = mutableListOf<Int>()
while (i < 1000)
if (i % 2 == 0)
list.add(i)
i++
此处对数据的处理即为找出其中的偶数。
若想要在偶数中找到>500的数,则继续筛选:
var i = 0
var list = mutableListOf<Int>()
while (i < 1000)
if (i > 500 && i % 2 == 0)
list.add(i)
i++
可以看出,原始数据是1~1000,我们对它进行了一些操作:过滤偶数、过滤>500的数。当然还可以进行其它操作,如映射、变换等。
提取上述过程三要素:
- 原始数据
- 对数据的一系列操作
- 最终的数据
把这一系列的过程当做流:

从流的方向来观察,我们称原始数据为上流,对数据进行一系列处理后,最终的数据为下流。
从流的属性来观察,我们认为生产者在上流生产数据,消费者在下流消费数据。
2. 为什么引进Flow?
由前面的文章我们知道,Java8提供了StreamAPI,专用来操作流,而Kotlin也提供了Sequence来处理流。
那为什么还要引进Flow呢?
在Kotlin的世界里当然不会想再依赖Java的StreamAPI了,主要来对比Kotlin里的各种方案选择。
先看应用场景的演变。
a、集合获取多个值
想要获取多个值,很显而易见的想到了集合。
fun testList()
//构造集合
fun list(): List<Int> = listOf(1, 2, 3)
list().forEach
//获取多个值
println("value = $it")
以上函数功能涉及两个对象:生产者和消费者。
生产者:负责将1、2、3构造为集合。
消费者:负责从集合里将1、2、3取出。
若此时想要控制生产者的速度,比如先将1放到集合里,过1秒后再讲2放进集合,在此种场景下该函数显得不那么灵活了。
b、Sequence控制生成速度
Sequence可以生产数据,先看看它是怎么控制生产速度的。
fun testSequence()
fun sequence():Sequence<Int> = sequence
for (i in 1..3)
Thread.sleep(1000)
yield(i)
sequence().forEach
println("value = $it")
通过阻塞线程控制了生产者的速度。
你可能会说:在协程体里为啥要用Thread.sleep()阻塞线程呢,用delay()不香吗?
看起来很香,我们来看看实际效果:

直接报编译错误了,提示是:受限制的挂起函数只能调用自己协程作用域内的成员和其它挂起函数。
而sequence的作用域是SequenceScope,查看其定义发现:

究其原因,SequenceScope 被RestrictsSuspension 修饰限制了。
c、集合配合协程使用
sequence 因为协程作用域的限制,不能异步生产数据,而使用集合却没此限制。
suspend fun testListDelay()
suspend fun list():List<Int>
delay(1000)
return listOf(1, 2, 3)
list().forEach
println("value = $it")
但也暴露了一个缺陷,只能一次性的返回集合元素。
综上所述:
不管是集合还是Sequence,都不能完全覆盖流的需求,此时Flow闪亮登场了
3. Fow常见的操作
最简单的Flow使用
suspend fun testFlow1()
//生产者
var flow = flow
//发射数据
emit(5)
//消费者
flow.collect
println("value=$it")
通过flow函数构造一个flow对象,然后通过调用flow.collect收集数据。
flow函数的闭包为生产者的生产逻辑,collect函数的闭包为消费者的消费逻辑。
当然,还有更简单的写法:
suspend fun testFlow2()
//生产者
flow
//发射数据
emit(5)
.collect
//消费者
println("value=$it")
执行流程:
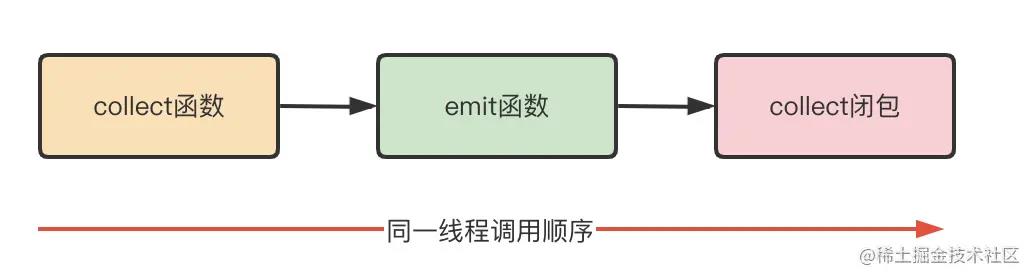
Flow操作符
上面只提到了flow数据的发送以及接收,并没有提及对flow数据的操作。
flow提供了许多操作符方便我们对数据进行处理(对流进行加工)。
我们以寻找1~1000内大于500的偶数为例:
suspend fun testFlow3()
//生产者
var flow = flow
for (i in 1..1000)
emit(i)
.filter it > 500 && it % 2 == 0
//消费者
flow.collect
println("value=$it")
filter函数的作用根据一定的规则过滤数据,一般称这种函数为flow的操作符。
当然还可以对flow进行映射、变换、异常处理等。
suspend fun testFlow3()
//生产者
var flow = flow
for (i in 1..1000)
emit(i)
.filter it > 500 && it % 2 == 0
.map it - 500
.catch
//异常处理
//消费者
flow.collect
println("value=$it")
中间操作符
前面说过流的三要素:原始数据、对数据的操作、最终数据,对应到Flow上也是一样的。
flow的闭包里我们看做是原始数据,而filter、map、catch等看做是对数据的操作,collect闭包里看做是最终的数据。
filter、map等操作符属于中间操作符,它们负责对数据进行处理。
中间操作符仅仅只是预先定义一些对流的操作方式,并不会主动触发动作执行
末端操作符
末端操作符也叫做终端操作符,调用末端操作符后,Flow将从上流发出数据,经过一些列中间操作符处理后,最后流到下流形成最终数据。
如上面的collect操作符就是其中一种末端操作符。
怎么区分中间操作符和末端操作符呢?
和Sequence操作符类似,可以通过返回值判断。
先看看中间操作符filter:
public inline fun <T> Flow<T>.filter(crossinline predicate: suspend (T) -> Boolean): Flow<T> = transform value ->
if (predicate(value)) return@transform emit(value)
internal inline fun <T, R> Flow<T>.unsafeTransform(
@BuilderInference crossinline transform: suspend FlowCollector<R>.(value: T) -> Unit
): Flow<R> = unsafeFlow // Note: unsafe flow is used here, because unsafeTransform is only for internal use
collect value ->
// kludge, without it Unit will be returned and TCE won't kick in, KT-28938
return@collect transform(value)
可以看出,filter操作符仅仅只是构造了Flow对象,并重写了collect函数。
再看末端操作符collect:
public suspend inline fun <T> Flow<T>.collect(crossinline action: suspend (value: T) -> Unit): Unit =
collect(object : FlowCollector<T>
override suspend fun emit(value: T) = action(value)
)
返回值为Unit,并且通过调用collect最终调用了emit,触发了流。
Flow相比Sequence、Collection的优势
Sequence对于协程的支持不够好,不能调用其作用域外的suspend函数,而Collection生产数据不够灵活,来看看Flow是如何解决这些问题的。
suspend fun testFlow4()
//生产者
var flow = flow
for (i in 1..1000)
delay(1000)
emit(i)
.flowOn(Dispatchers.IO)//切换到io线程执行
//消费者
flow.collect
delay(1000)
println("value=$it")
如上,flow的生产者、消费者闭包里都支持调用协程的suspend函数,同时也支持切换线程执行。
再者,flow可以将集合里的值一个个发出,可调整其流速。
当然,flow还提供了许多操作符帮助我们实现各种各样的功能,此处限于篇幅就不再深入。
万变不离其宗,知道了原理,一切迎刃而解。
4. 为什么说Flow是冷流?
flow 的流动
在sequence的分析里有提到过sequence是冷流,那么什么是冷流呢?
没有消费者,生产者不会生产数据
没有观察者,被观察者不会发送数据
suspend fun testFlow5()
//生产者
var flow = flow
println("111")
for (i in 1..1000)
emit(i)
.filter
println("222")
it > 500 && it % 2 == 0
.map
println("333")
it - 500
.catch
println("444")
//异常处理
如上代码,只要生产者没有消费者,该函数运行后不会有任何打印语句输出。
这个时候将消费者加上,就会触发流的流动。
还是以最简单的flow demo为例,看看其调用流程:

图上1~6步骤即为最简单的flow调用流程。
可以看出,只有调用了末端操作符(如collect)之后才会触发flow的流动,因此flow是冷流。
flow 的原理
suspend fun testFlow1()
//生产者
var flow = flow
//发射数据
emit(5)
//消费者
flow.collect
println("value=$it")
以上代码涉及到三个关键函数(flow、emit、collect),两个闭包(flow闭包、collect闭包。
从上面的调用图可知,以上五者的调用关系:
flow–>collect–>flow闭包–>emit–>collect闭包
接下来逐一分析在代码里的关系。
先看生产者动作(flow函数)
flow函数实现:
public fun <T> flow(@BuilderInference block: suspend FlowCollector<T>.() -> Unit): Flow<T> = SafeFlow(block)
传入的参数类型为:FlowCollector的扩展函数,而FlowCollector是接口,它有唯一的函数:emit(xx)。因此在flow函数的闭包里可以调用emit(xx)函数,flow闭包作为SafeFlow的成员变量block。
flow 函数返回SafeFlow,SafeFlow继承自AbstractFlow,并实现了collect函数:
#Flow.kt
public final override suspend fun collect(SafeCollector: FlowCollector<T>)
//构造SafeCollector
//collector 作为SafeCollector的成员变量
val safeCollector = SafeCollector(collector, coroutineContext)
try
//抽象函数,子类实现
collectSafely(safeCollector)
finally
safeCollector.releaseIntercepted()
collect的闭包作为SafeCollector的成员变量collector,后面会用到。
由此可见:flow函数仅仅只是构造了flow对象并返回。
再看消费者动作(collect)
当消费者调用flow.collect函数时:
public suspend inline fun <T> Flow<T>.collect(crossinline action: suspend (value: T) -> Unit): Unit =
collect(object : FlowCollector<T>
override suspend fun emit(value: T) = action(value)
)
此时调用的collect即为flow里定义的collect函数,并构造了匿名对象FlowCollector,实现了emit函数,而emit函数的真正实现为action,也就是外层传入的collect的闭包。
上面分析到的collect源码里调用了collectSafely:
private class SafeFlow<T>(private val block: suspend FlowCollector<T>.() -> Unit) : AbstractFlow<T>()
override suspend fun collectSafely(collector: FlowCollector<T>)
collector.block()
此处的block即为在构造flow对象时传入的闭包。
此时,消费者通过collect函数已经调用到生产者的闭包里
还剩下最后一个问题:生产者的闭包是如何流转到消费者的闭包里呢?
最后看发射动作(emit)
在生产者的闭包里调用了emit函数:
override suspend fun emit(value: T)
//挂起函数
return suspendCoroutineUninterceptedOrReturn sc@ uCont ->
try
//uCont为当前协程续体
emit(uCont, value)
catch (e: Throwable)
// Save the fact that exception from emit (or even check context) has been thrown
lastEmissionContext = DownstreamExceptionElement(e)
throw e
private fun emit(uCont: Continuation<Unit>, value: T): Any?
val currentContext = uCont.context
currentContext.ensureActive()
// This check is triggered once per flow on happy path.
val previousContext = lastEmissionContext
if (previousContext !== currentContext)
checkContext(currentContext, previousContext, value)
completion = uCont
//collector.emit 最终调用collect的闭包
return emitFun(collector as FlowCollector<Any?>, value, this as Continuation<Unit>)
如此一来,生产者的闭包里调用emit函数后,将会调用到collect的闭包里,此时数据从flow的上游流转到下游。
总结以上步骤,其实本质还是对象调用。
中间操作符的原理
以filter为例:
public inline fun <T> Flow<T>.filter(crossinline predicate: suspend (T) -> Boolean): Flow<T> = transform value ->
//判断过滤条件是否满足,若是则发送数据
if (predicate(value)) return@transform emit(value)
internal inline fun <T, R> Flow<T>.unsafeTransform(
@BuilderInference crossinline transform: suspend FlowCollector<R>.(value: T) -> Unit
): Flow<R> = unsafeFlow // Note: unsafe flow is used here, because unsafeTransform is only for internal use
//调用当前对象collect
collect value ->
// kludge, without it Unit will be returned and TCE won't kick in, KT-28938
return@collect transform(value)
internal inline fun <T> unsafeFlow(@BuilderInference crossinline block: suspend FlowCollector<T>.() -> Unit): Flow<T>
//构造flow,重写collect
return object : Flow<T>
override suspend fun collect(collector: FlowCollector<T>)
collector.block()
filter操作符构造了新的flow对象,该对象重写了collect函数。
当调用flow.collect时,先调用到filter对象的collect,进而调用到原始flow的collect,接着调用到原始flow对象的闭包,在闭包里调用的emit即为filter的闭包,若filter闭包里条件满足则调动emit函数,最后调用到collect的闭包。

理解中间操作符的要点:
- 中间操作符返回新的flow对象,重写了collect函数
- collect函数会调用当前flow(调用filter的flow对象)的collect
- collect函数做其它的处理
与sequence类似,使用了装饰者模式。
以上以filter为例阐述了原理,其它中间操作符的原理类似,此处就不再细说。
下篇将分析Flow的背压与线程切换,相信分析的逻辑会让大家耳目一新,敬请期待~
本文基于Kotlin 1.5.3,文中完整Demo请点击
您若喜欢,请点赞、关注、收藏,您的鼓励是我前进的动力
持续更新中,和我一起步步为营系统、深入学习android/Kotlin
1、Android各种Context的前世今生
2、Android DecorView 必知必会
3、Window/WindowManager 不可不知之事
4、View Measure/Layout/Draw 真明白了
5、Android事件分发全套服务
6、Android invalidate/postInvalidate/requestLayout 彻底厘清
7、Android Window 如何确定大小/onMeasure()多次执行原因
8、Android事件驱动Handler-Message-Looper解析
9、Android 键盘一招搞定
10、Android 各种坐标彻底明了
11、Android Activity/Window/View 的background
12、Android Activity创建到View的显示过
13、Android IPC 系列
14、Android 存储系列
15、Java 并发系列不再疑惑
16、Java 线程池系列
17、Android Jetpack 前置基础系列
18、Android Jetpack 易学易懂系列
19、Kotlin 轻松入门系列
20、Kotlin 协程系列全面解读
作者:小鱼人爱编程
链接:https://juejin.cn/post/7168511169781563428
最后
如果想要成为架构师或想突破20~30K薪资范畴,那就不要局限在编码,业务,要会选型、扩展,提升编程思维。此外,良好的职业规划也很重要,学习的习惯很重要,但是最重要的还是要能持之以恒,任何不能坚持落实的计划都是空谈。
如果你没有方向,这里给大家分享一套由阿里高级架构师编写的《Android八大模块进阶笔记》,帮大家将杂乱、零散、碎片化的知识进行体系化的整理,让大家系统而高效地掌握Android开发的各个知识点。

相对于我们平时看的碎片化内容,这份笔记的知识点更系统化,更容易理解和记忆,是严格按照知识体系编排的。
全套视频资料:
一、面试合集

二、源码解析合集
三、开源框架合集

欢迎大家一键三连支持,若需要文中资料,直接点击文末CSDN官方认证微信卡片免费领取↓↓↓
以上是关于KSP - 元编程编译提速的小助手的主要内容,如果未能解决你的问题,请参考以下文章