八爪鱼采集器可以看到预览数据采集后是零
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了八爪鱼采集器可以看到预览数据采集后是零相关的知识,希望对你有一定的参考价值。
参考技术A 安装打开八爪鱼首页后,可以看到界面简洁,从上到下有搜索框、采集模板以及教程。采集时可以直接在搜索框输入目标网址,或者在左侧选择【新建】创建采集任务。输入网址后进入采集界面,可以看到,初始页面分为①网页显示、②数据预览和③流程图三大区域。
其中点击版块①右上角的黄色图标,会打开【操作提示框】;
在版块②中可以对数据字段进行编辑、添加、删除等操作;
在版块③中,点击每个步骤框可以进入基础、高级选项设置页面,点击…按钮可对当前步骤进行删除等操作。此外,将鼠标移动到流程中的 ↓位置,会出现 + 按钮,点击可添加流程步骤。
那么什么是采集流程呢?它是指从特定网页上抓取数据的指令。由于每个网站的页面布局不同,因此采集流程不能通用,要根据具体需要自定义配置。
接下来我们以具体例子,了解如何采集列表数据、表格数据以及翻页采集详情页数据。
采集列表数据
步骤一:输入网址
在首页【输入框】中输入目标网址(以豆瓣读书为例),点击【开始采集】,八爪鱼会自动打开网页。
步骤二:建立采集流程-【循环提取数据】
观察可以发现,该网页上的图书信息以列表形式呈现,每个列表结构相同,都包含书名、出版信息、评分、评价数、图书简介等。那么如何让八爪鱼识别所有列表,并采集所需类型的数据呢?
在八爪鱼中,我们需要建立【循环提取数据】的流程:
第一,任意点击选中页面上的一个图书列表。选中后的列表会呈绿色框选状态,其中红色虚线框内的称为【子元素】。(需要注意的是,要确保待采集的所有内容都在绿色框内。)
第二,在弹出的黄色操作提示框中选择【选中子元素】。
此时当前列表数据的全部具体字段已被识别出来,并且八爪鱼还自动识别出了其他同类元素。
第三,在黄色操作提示框中,继续选择【选中全部】。
此时可以看到在下方的列表当中显示出了其他同类数据。
第四,在黄色操作提示框中,选择【采集数据】。此时,八爪鱼提取出列表中的字段。
步骤三:编辑字段
在下方的数据预览部分,对于列表中已提取出的所有字段,我们可以根据实际需求进行修改字段名称或删除等操作。
步骤四:启动采集
第一,以上设置完成后,依次点击右上方的【保存】和【采集】按钮,启动本地采集。
第二,采集完成后,选择合适的导出方式(Excel、CSV、html)导出数据。这里导出为Excel。
打开Excel文件,可以看到成功采集的数据~
采集表格数据
表格是一种很常见的网页样式,比如现在有一个新浪财经的网页 ,如何采集其中具体数据呢?
可以看到表格内每条股票信息各占一行,且一行股票中包含代码、名称、最新评级、评级机构、所属行业等多个字段信息。
那么如何将这些字段数据采集下来并以Excel形式保存呢?
接下来看具体操作:
步骤一:输入网址
在八爪鱼中采集数据的第一步基本都是输入目标网址,点击【开始采集】。
步骤二:建立采集流程
第一,选中页面上第一行第一个单元格,再点击操作提示框下方的TR,选中至一整行。
第二,在提示框中,选择【选中子元素】,这样第1个股票的具体字段会被选中。
同时可以看到,列表其他元素在红色线框内,说明八爪鱼还自动识别出了页面中其他股票列表中的同类【子元素】。
第三,在提示框中,选择【选中全部】。可以看到页面中所有股票列表中的子元素都呈绿框选中状态。
第四,在黄色操作提示框中,选择【采集数据】。
点击采集选项之后,可以看到数据预览区域显示出所有待采集字段的数据。
步骤三:编辑字段
接下来对列表中已提取出的所有字段,根据实际需求进行修改名称或删除等操作。
步骤4:启动采集
第一,以上设置完成后,依次点击右上方的【保存】和【采集】按钮,启动本地采集。
第二,采集完成后,选择以Excel格式导出,即可得到成功采集的数据。
采集详情页数据
在上面的操作中,我们采集的是主页面上的相关数据。但实际上,网页之间会有链接关系,如果我们对主页上某个条目感兴趣,会点击进入详情页进一步了解。那如何爬取多个同类详情页数据呢?
以百度学术对“知识交互作用”的检索页面为例,在八爪鱼首页输入目标网址后,开始建立采集流程。
建立采集流程—【循环-点击元素-提取数据】
第一,选中页面上第1个链接(会呈绿色实线框选状态)。
这时可以看到出现黄色操作提示框,提示我们发现了同类链接(红色虚线框选状态)。
第二,点击【选中全部】后,同类标题链接都被选中。
第三,在黄色操作提示框中,选择【循环点击每个链接】。(因为是按顺序依次采集每个详情页数据,所以需要循环点击链接。)
选择以后,会发现页面跳转到了第1个链接的详情页。
第四,按照需要提取数据。依次点击选中字段后,在黄色操作提示框选择【采集该元素文本】或其他。这里只提取文章标题、作者、摘要、关键词、被引量和年份。
八爪鱼采集列表和详情信息
前两天突然接到领导一个邮件,让我用八爪鱼采集互联网数据。下面是邮件的原话:

我是接触可视化工具较多,但是你这个应该不复杂就有点主观了吧,没办法,让我对应就对应吧。
首先登陆官网:http://www.bazhuayu.com/,下载客户端安装,傻瓜式安装下一步下一步就完成了。我不需要免费账号,公司买了一个。
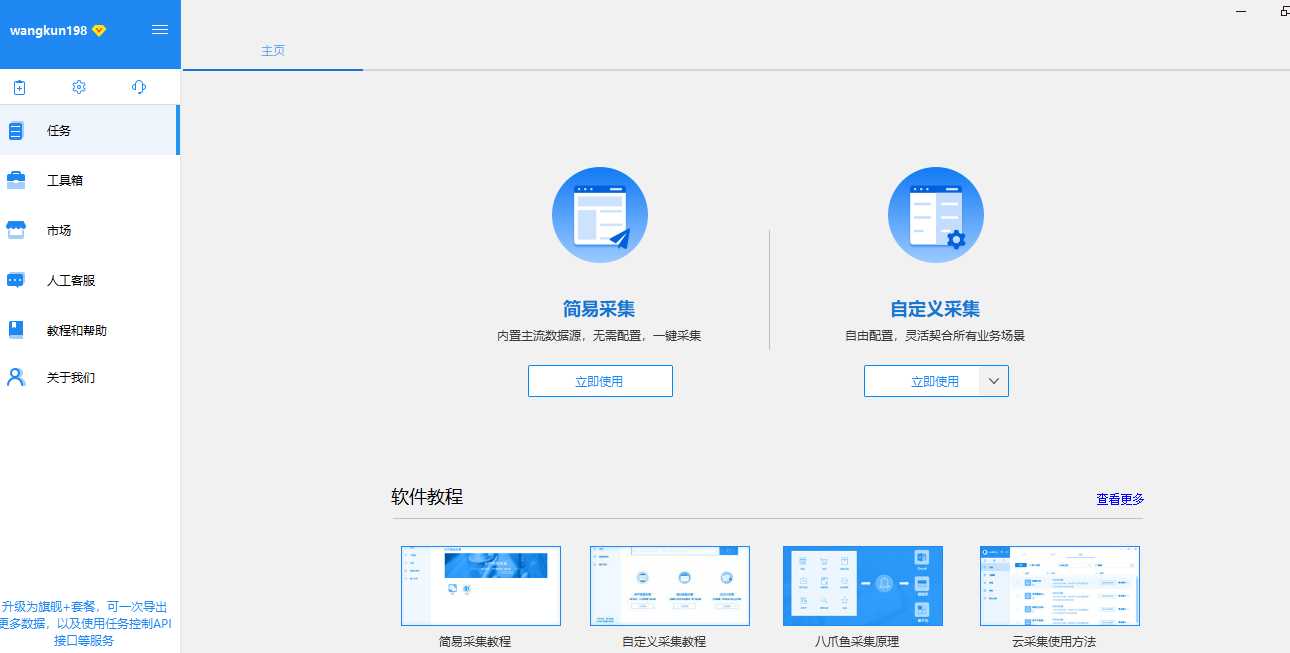
这是这个工具的界面,还是蛮简洁的,最主要的是任务栏和工具箱栏。任务栏首先可以建立任务组,在任务组下面建立具体的任务。下面我就具体的某一任务来一一说明。
我采集的是中国土地市场网的结果公示,网址为http://www.landchina.com/default.aspx?tabid=263&ComName=default,页面如图:
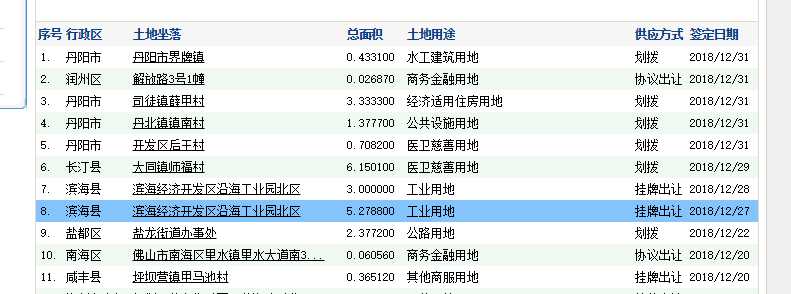
需要采集的信息是列表内容和点进去列表后的详情,当然我的例子是列表选一个,详情选一个。还有一点,这个列表需要翻页,一共200页,每页30条。
1,建立任务:点击新建,选择自定义采集,输入网址,点击保存。
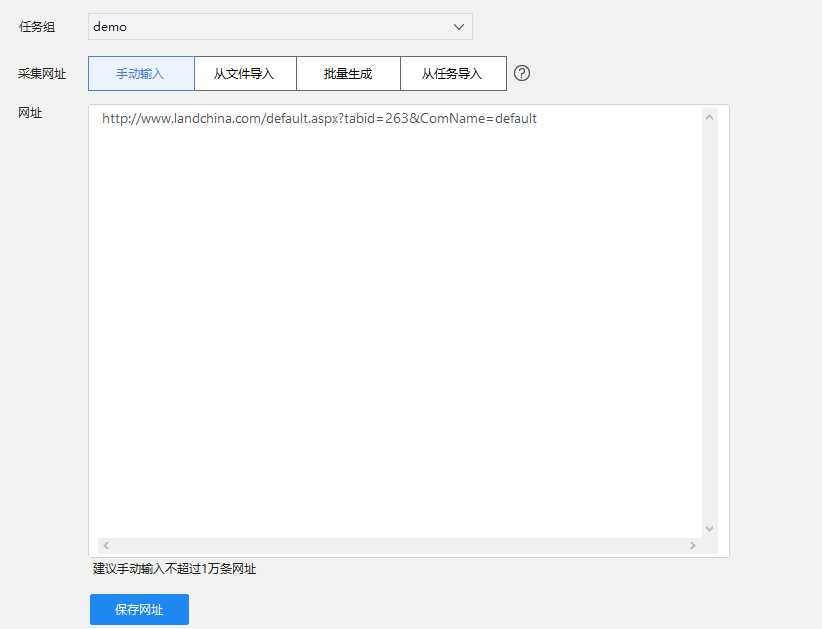
出来的页面是这样:
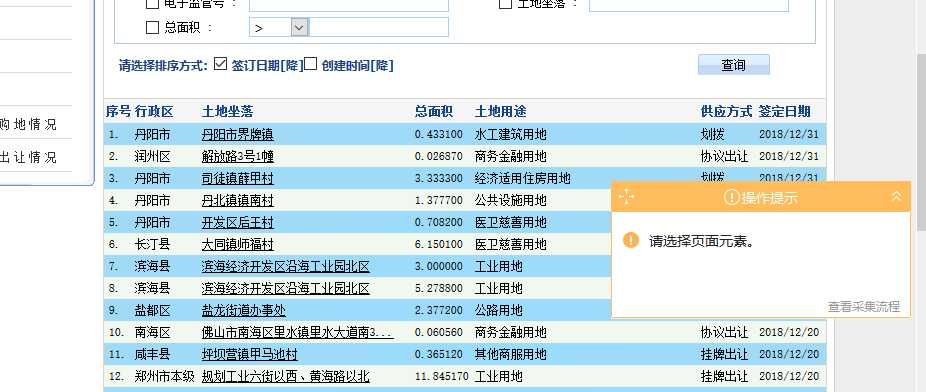
2,现在我要把序号这一列采集下来,鼠标点击1.,然后选择选中全部:
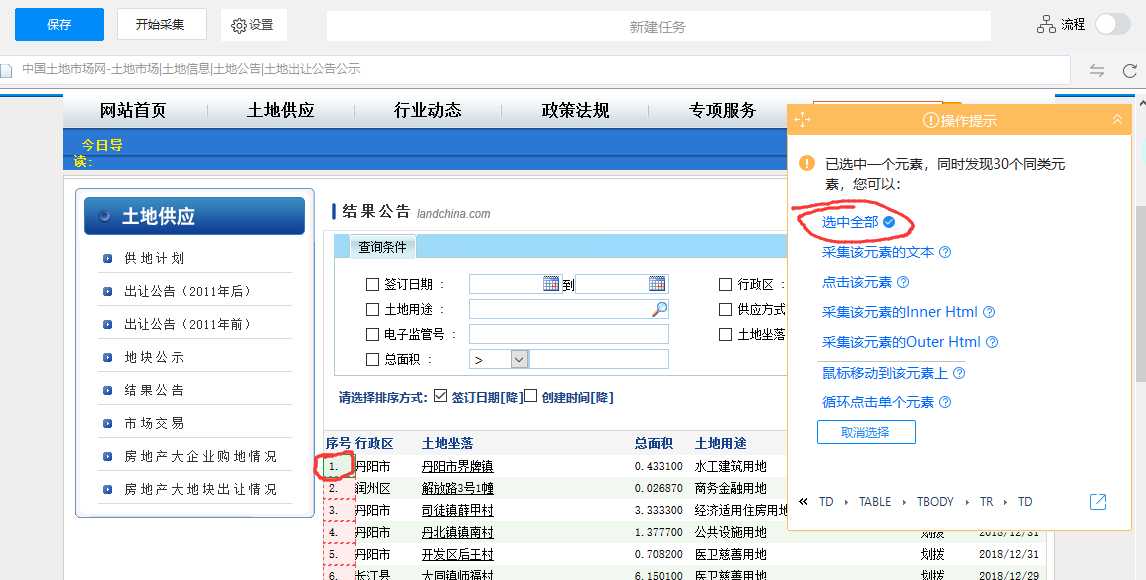
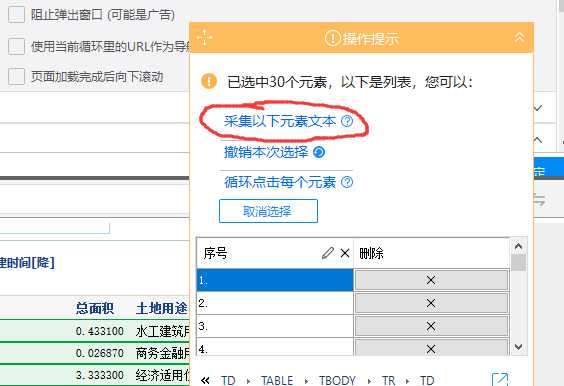
再选择采集以下元素文本。至此,列表的信息可以采集了。
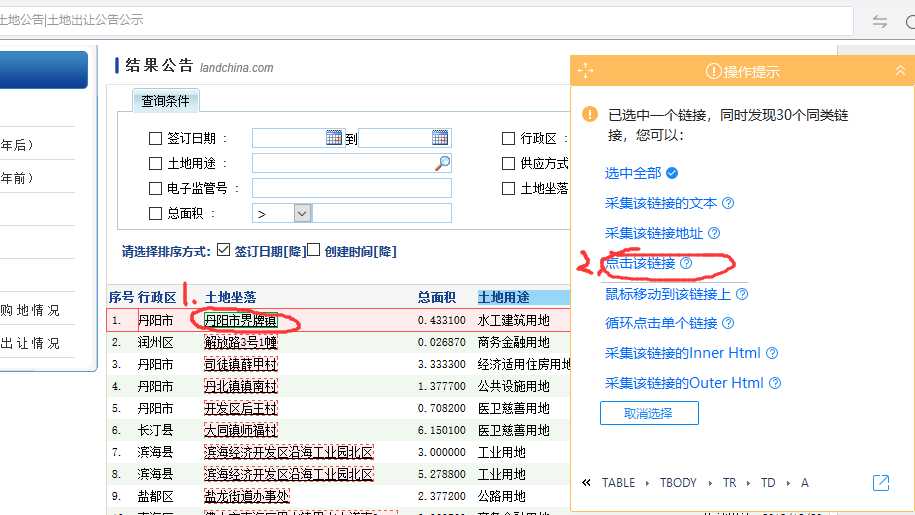
2,点击钻取到详情列的超链接,然后选择点击该链接:
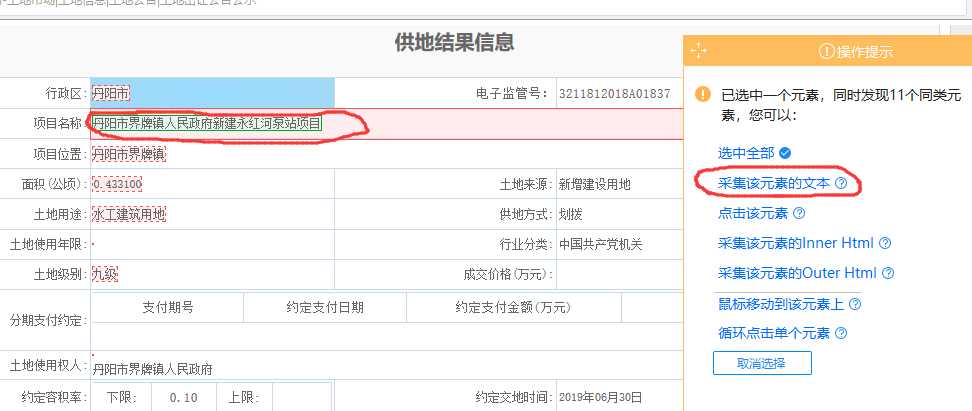
下面会跳转到详情页,我再采集项目名称,单击对应文本,选择采集该元素的文本,至此详情的信息可以采集了。
3,我们的采集工作完成了,但是我们还差翻页循环,点击返回上个页面:
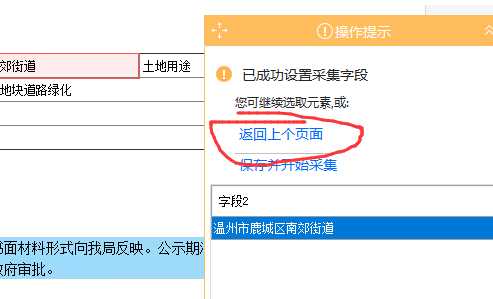 找到下页按钮,点击,然后选择循环单击单个链接:
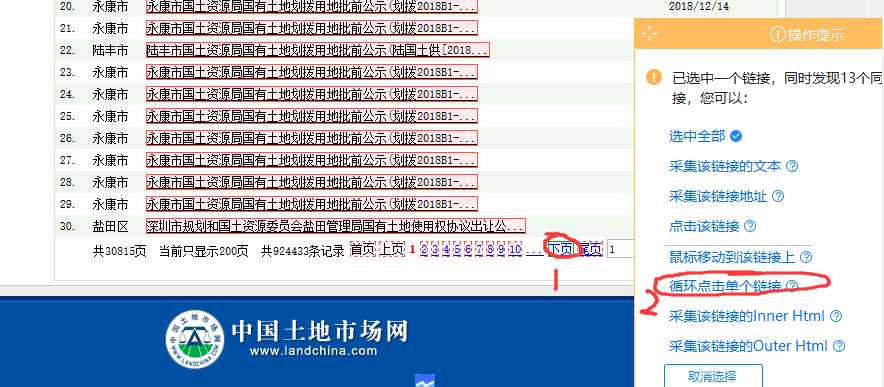
找到下页按钮,点击,然后选择循环单击单个链接:
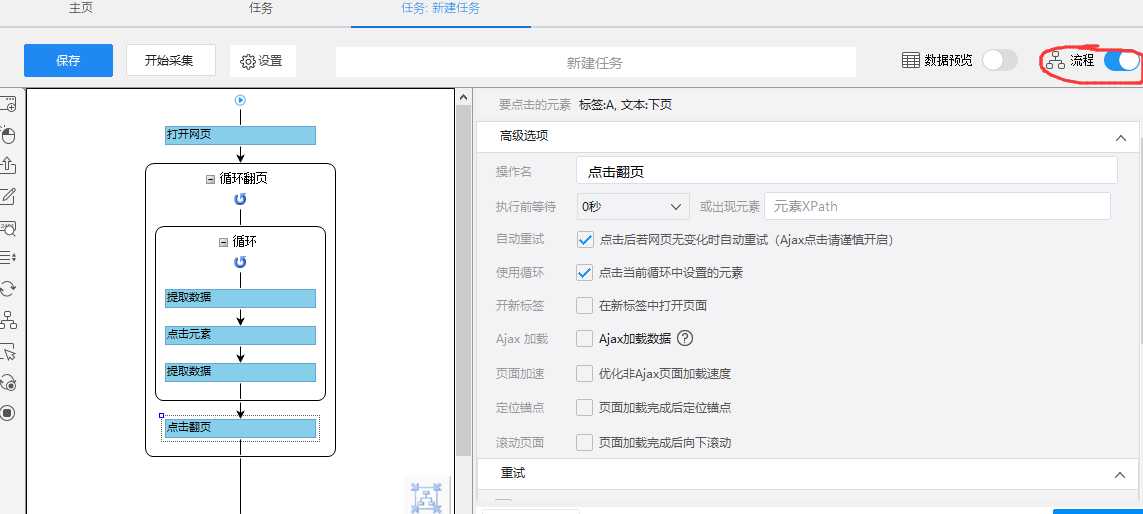
然后点击左上角保存,全部步骤完成,我们可以看一下流程图:
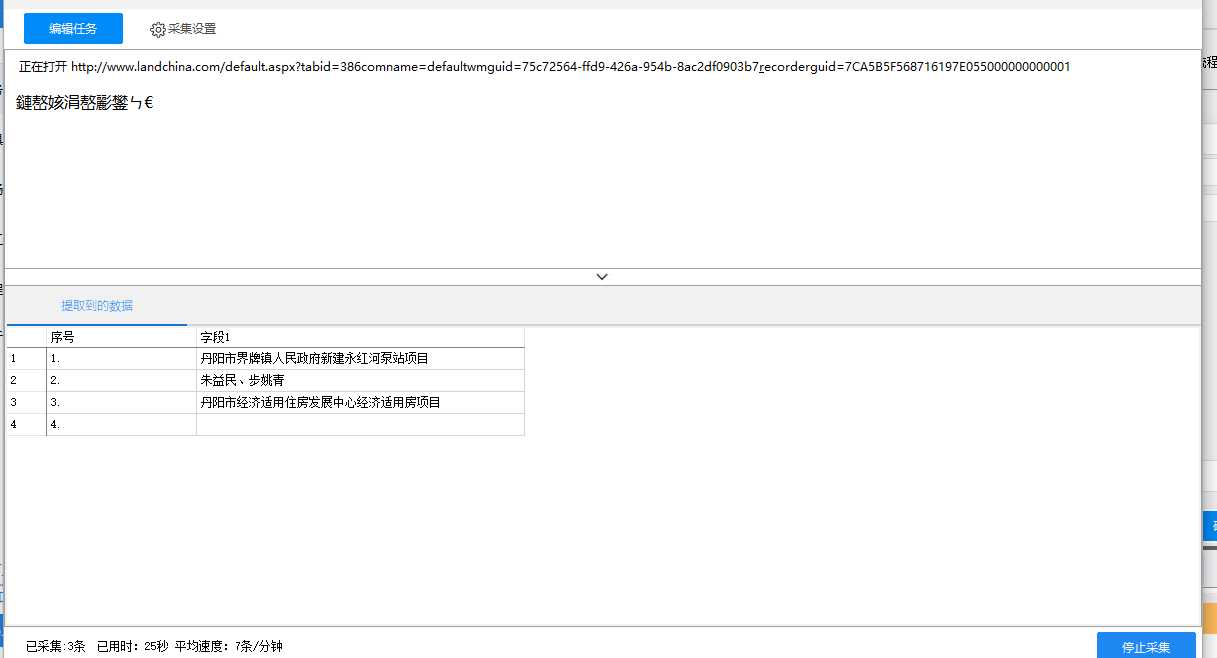
这样一个采集任务就完成了,接下来就可以点击开始采集按钮测试了。
以上是关于八爪鱼采集器可以看到预览数据采集后是零的主要内容,如果未能解决你的问题,请参考以下文章