Tensorflow 源码分析- 从GPU OOM开始说Tensorflow的BFC内存管理
Posted raintungli
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Tensorflow 源码分析- 从GPU OOM开始说Tensorflow的BFC内存管理相关的知识,希望对你有一定的参考价值。
前言
在平台上跑GPU训练,结果CUDA OOM了,错误提示
E Internal: failed initializing StreamExecutor for CUDA device ordinal 0: Internal: failed call to cuDevicePrimary
CtxRetain: CUDA_ERROR_OUT_OF_MEMORY; total memory reported: 11711807488对会话没有进行任何GPU相关设置,tensorflow给出建议,可以用参数控制GPU的内存分配
# add gpu growth flags
tf_config.gpu_options.allow_growth = True
tf_config.gpu_options.per_process_gpu_memory_fraction = 0.1per_process_gpu_memory_fraction 参数
- per_process_gpu_memory_fraction 参数,这是一个控制GPU单个process的内存因子,这是一个筏值,通过筏值来决定获取GPU的内存比,从而控制留给系统的GPU的内存,如果不设置,在有效内存足够的情况下,tensorflow只预留给系统225M当有效内存小于2G的时候,而当有效内存大于2G的时候预留筏值0.05的有效内存且至少300M的内存,这是一种贪婪式的占有内存。设置因子可以有效控制你需要的内存量。
int64 allocated_memory;
double config_memory_fraction =
options.config.gpu_options().per_process_gpu_memory_fraction();
if (config_memory_fraction == 0)
allocated_memory = available_memory;
const int64 min_system_memory = MinSystemMemory(available_memory);
if (min_system_memory < allocated_memory)
allocated_memory -= min_system_memory;
else
allocated_memory = total_memory * config_memory_fraction;
- 如果你跑在一个已经内存使用比较多的平台里,每个GPU的剩余内存并不一定一样,设置因子是基于所有process内存的,单个因子无法控制每个process的内存分配,会导致由于单个process的内存不够而导致失败。
allow_growth 参数
看到这参数也许会很奇怪,allow_growth字面意思是允许增长,也就是允许后期继续分配内存?实际上在tensorflow启动的时候,并不会真实的去申请内存,初始参数的生成只是为了管控后期真实允许使用,申请内存的大小。
在tensorflow上有一层虚拟的内存管理BFC
BFC内存分配
这是一个虚拟的内存分配器,实现类似Doug Lea简单版本malloc(dlmalloc),通过合并进行内存碎片整理,实现'best-fit with coalescing'的算法,要求所有的分配内存都必须调用该接口。
1 Chunk结构体
1.1 结构体
这是tensorflow的最小内存单位,由数倍256bytes(kMinAllocationSize)的连续内存块组成,tensorflow的内存管理是基于chunk的管理。
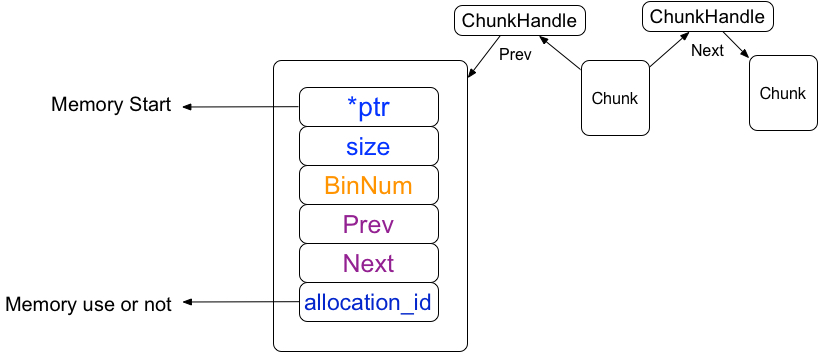
1.1.1 chunkhandle
chunkhandle是chunk数组向量的索引,在tensorflow保存着所有chunk的数组向量,而数组向量的下标就是chunkhandle
// If not kInvalidChunkHandle, the memory referred to by 'prev' is directly
// preceding the memory used by this chunk. E.g., It should start
// at 'ptr - prev->size'
ChunkHandle prev = kInvalidChunkHandle;
// If not kInvalidChunkHandle, the memory referred to by 'next' is directly
// following the memory used by this chunk. E.g., It should be at
// 'ptr + size'
ChunkHandle next = kInvalidChunkHandle;在Chunk结构体中有两个前后chunkhandle(所有chunk数组的索引),chunkhandle指向前后分别是相邻的连续内存块
1.1.2 ptr指针
ptr是一个内存指针,指向的是内存的启始位置,因为chunk指向的是连续内存,所以只记录它的大小
1.2 chunk的申请
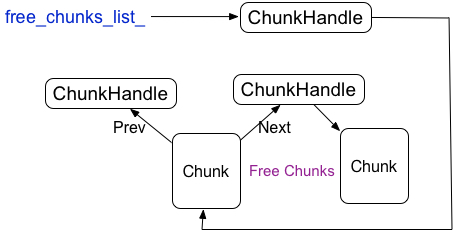
Tensorflow 会保存一个所有chunk的数组向量,为了避免频繁的申请和释放chunk,被释放的chunk会被重用,为了快速的查找已经释放的chunk,tensorflow又构建了已经释放的chunk的链表结构,free_chunks_list_指向链表的头
1.3 chunk的删除
chunk是重用的,chunk的删除需要抹去chunk里的特性,比如ptr,当然不是释放ptr指向的内存,而是将Region里所对应该地址的chunkhandle的指向设置无效,同时将该chunk添加到已经释放的chunk的链表中的头部,free_chunks_list_指向刚释放的chunk
2 Region
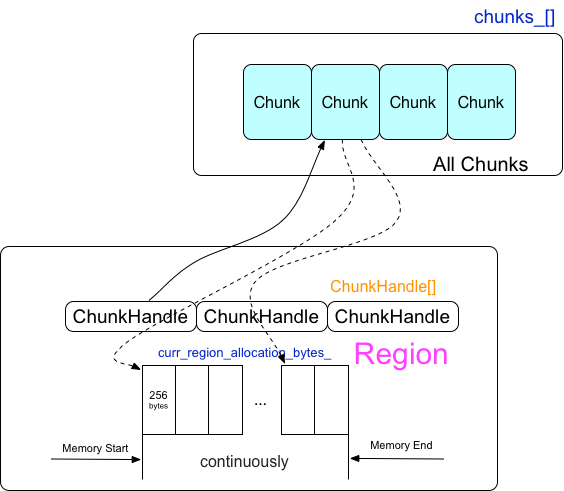
Region是一块已经分配的连续的内存块,一个region可以被拆分为多个chunk,一个chunk指向的是多个连续的256byte的内存块
2.1 Region 的申请
在真正需要使用内存的时候才申请Region
size_t bytes = std::min(curr_region_allocation_bytes_, available_bytes);
void* mem_addr = suballocator_->Alloc(32, bytes);在上面代码中我们可以看到每次申请Region的内存由下面几个参数控制:
curr_region_allocation_bytes参数
if (allow_growth)
// 1MiB smallest initial allocation, unless total memory available
// is less.
curr_region_allocation_bytes_ =
RoundedBytes(std::min(total_memory, size_t1048576));
else
curr_region_allocation_bytes_ = RoundedBytes(total_memory);
这里的allow_growth参数就是在前面的
tf_config.gpu_options.allow_growth = True当allow_growth关闭的时候,curr_region_allocation_bytes_就是默认的剩余内存大小,也就是只有一个Region
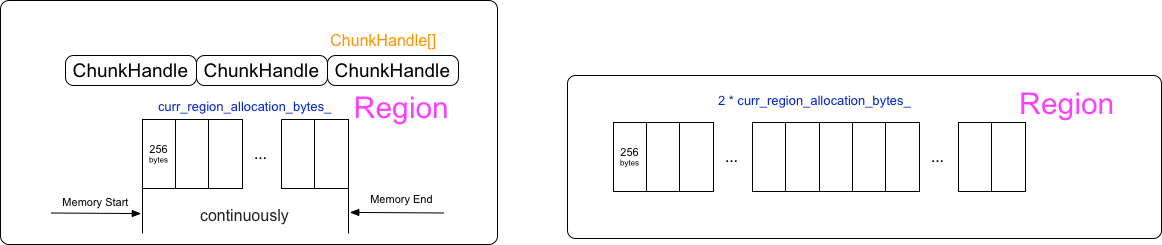
当allow_growth打开的时候,curr_region_allocation_bytes_的值是最小为1M的多个Region,curr_region_allocation_bytes_默认以2倍的速度增长,也就是每次申请Region的内存是连续最小以2倍速度增长的。
如果实际需要申请的内存大于curr_region_allocation_bytes_的时候,以2倍的curr_region_allocation_bytes_速度增长直到满足需要的内存。
bool increased_allocation = false;
while (rounded_bytes > curr_region_allocation_bytes_)
curr_region_allocation_bytes_ *= 2;
increased_allocation = true;
Available_bytes参数
available_bytes 指的是剩余的可被分配的内存,在初始化的时候Tensorflow会获取GPU的有效内存,每次申请的内存会从剩余内存中减去,也就是在整个运算过程中GPU的剩余内存只会在程序开始的时候获取一次,如果程序是在运行在GPU的平台上,剩余内存会不停的变化,有效的内存在程序开始运行的时候获取(并没有真的去申请),那么在计算过程中内存申请很有可能出现OOM。
2.2 Region的ChunkHandle
每个Region会被以256bytes大小分割成多个chunkhandle的数组,chunkhandle指向的就是前面章节中讨论的chunk向量数组的位置。
2.3 Region数组
每一次的申请连续的内存都会生成一个Region,多个Region组成了Region向量数组
private:
std::vector<AllocationRegion> regions_;如何定位chunk是属于哪个Region呢?每个Region会记录起始地址和结束地址,而chunk中会保存chunk的起始地址,只要比较chunk的起始地址和region的地址范围,就能确定所属于的Region
3. Bin
在前面章节中讨论了Region, Chunk,但当申请新的内存的时候,如何更快高效的查找匹配的空闲chunk,这是非常重要的。查找每个Region里的空闲chunk,显然是非常低效率的,tensorflow基于chunk上构建了一个全局的bin,每个bin里管理的是一定范围的内存大小的chunk(内存大小范围 (2^bin_num)*256 到 (2^(bin_num+1))*256-1的,bin_num代表的是bin的序列号)每个chunk是以256bytes数倍大小的内存块,bin管理的是空闲的chunk块。
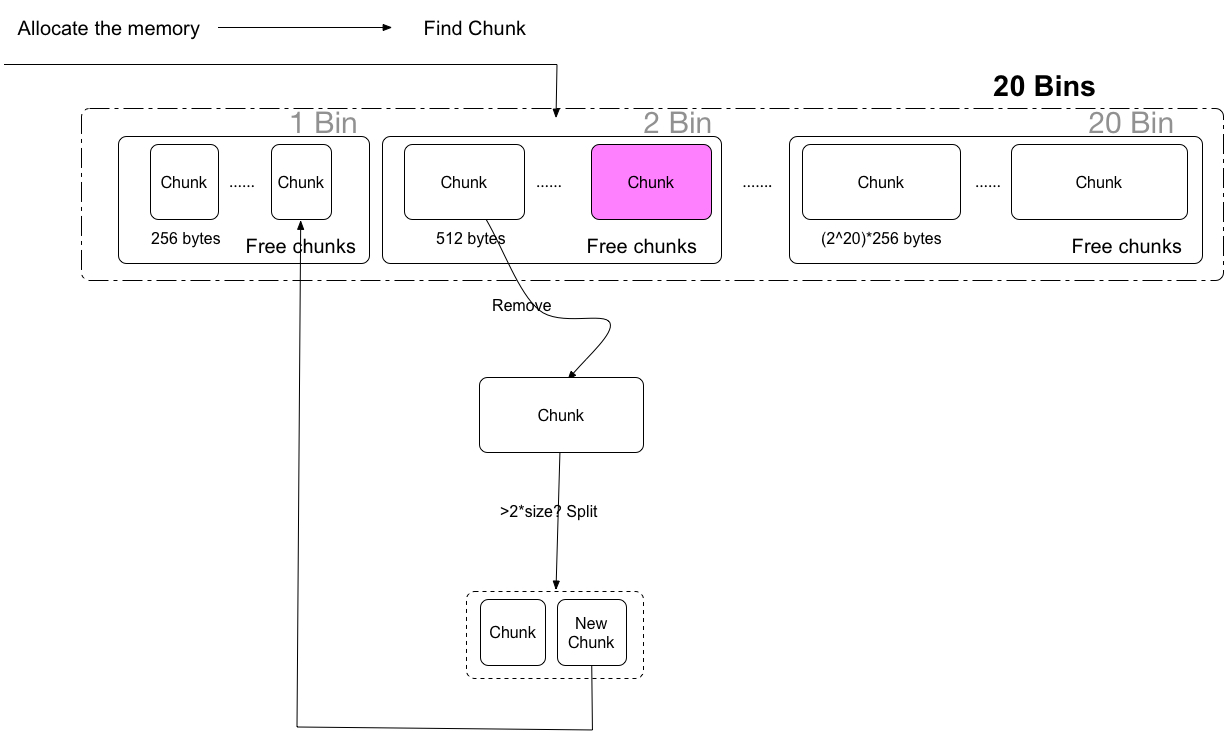
每个Bin里会保存着一个空闲的free的chunk的set
typedef std::set<ChunkHandle, ChunkComparator> FreeChunkSet;
// List of free chunks within the bin, sorted by chunk size.
// Chunk * not owned.
FreeChunkSet free_chunks;- 应用程序先申请内存
- 计算从而确定内存大小所属于的Bin
- 遍历Bin里面的空闲的Chunk Set,如果找不到继续查找更大的Bin,直到找到空闲的内存
- 如果依然找不到,那么就需要真实的向驱动申请内存,申请curr_region_allocation_bytes_大小的内存块为一个Region,同时也是一个大的chunk块,并将这个chunk块作为空闲块插入回所对应的bin中空闲chunk set,然后继续查找。
- 如果找到,那么需要判断一下空闲的chunk内存块是否2倍于所需要的内存
- 为了避免内存的浪费,大的空闲chunk块会倍拆分成2个chunk块,小的chunk块给程序使用,而剩余大的chunk块重新插入回所对应的Bin的空闲chunk set
4. Chunk 的合并和拆分
为了更有效的利用内存,对一个较大的chunk内存块进行chunk的拆分,该拆分策略前面章节里已经介绍过,而在chunk进行释放的时候,tensorflow会尝试对chunk进行合并,chunk合并的策略:地址相邻的内存块才可以合并
还记得chunk的Prev,Next么?
BFCAllocator::ChunkHandle h_neighbor = c->next;
new_chunk->prev = h;
new_chunk->next = h_neighbor;
c->next = h_new_chunk;在chunk拆分的时候,就是相邻的chunk块,在split一个大的Chunk成两个chunk块的时候, 新的chunk块prev会指向另一个chunk块, next指向原来大的chunk块的邻居,同时大chunk块的邻居prev指向新的chunk块。
在释放chunk的时候,会检查prev和next,如果prev,next指向的chunk没有被使用,那么就会尝试合并。
以上是关于Tensorflow 源码分析- 从GPU OOM开始说Tensorflow的BFC内存管理的主要内容,如果未能解决你的问题,请参考以下文章