python中用正则表达式re去除空格但不去除换行符?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python中用正则表达式re去除空格但不去除换行符?相关的知识,希望对你有一定的参考价值。
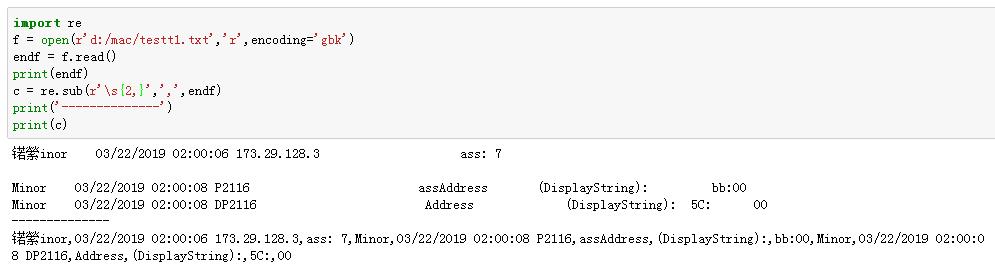
import ref = open(r'd:/mac/testt1.txt','r',encoding='gbk')endf = f.read()print(endf)c = re.sub(r'\s2,',',',endf)print('--------------')print(c)去除了空格,连带回车也去除了,希望不要去除换行求大神帮助
在 Python 中用逗号分隔并去除空格
【中文标题】在 Python 中用逗号分隔并去除空格【英文标题】:Split by comma and strip whitespace in Python 【发布时间】:2011-05-03 13:15:27 【问题描述】:我有一些用逗号分隔的 python 代码,但没有去掉空格:
>>> string = "blah, lots , of , spaces, here "
>>> mylist = string.split(',')
>>> print mylist
['blah', ' lots ', ' of ', ' spaces', ' here ']
我宁愿像这样删除空格:
['blah', 'lots', 'of', 'spaces', 'here']
我知道我可以遍历 list 并 strip() 每个项目,但由于这是 Python,我猜有一种更快、更简单、更优雅的方法。
【问题讨论】:
【参考方案1】:使用列表推导——更简单,就像for 循环一样容易阅读。
my_string = "blah, lots , of , spaces, here "
result = [x.strip() for x in my_string.split(',')]
# result is ["blah", "lots", "of", "spaces", "here"]
见:Python docs on List ComprehensionA good 2 second explanation of list comprehension.
【讨论】:
超级好!我添加了一项如下以摆脱空白列表条目。 > text = [x.strip() for x in text.split('.') if x != ''] @Sean: 无效/不完整的 python 代码是你的“帖子的初衷”吗?根据评论爱好者的说法是:***.com/review/suggested-edits/21504253。如果他们错了(再次),您能否通过更正来告诉他们? 原件是从 REPL 复制粘贴的(如果我没记错的话),目标是理解底层概念(使用列表理解来执行操作) - 但你是对的,它使如果您看到列表推导生成一个新列表,则更有意义。【参考方案2】:map(lambda s: s.strip(), mylist) 会比显式循环好一点。或者一次性全部:map(lambda s:s.strip(), string.split(','))
【讨论】:
提示:任何时候你发现自己在使用map,特别是如果你使用lambda,请仔细检查你是否应该使用列表解析。
你可以用map(str.strip, s.split(','))避免lambda。【参考方案3】:
在拆分之前,只需从字符串中删除空格即可。
mylist = my_string.replace(' ','').split(',')
【讨论】:
如果以逗号分隔的项目包含嵌入的空格,例如"you just, broke this".
天啊,这个是-1。你们好难啊它解决了他的问题,提供他的样本数据只是单个单词,并且没有指定数据是短语。但是w/e,我想你们就是这样在这里打滚的。
无论如何,谢谢,用户。公平地说,尽管我特别要求 split 然后 strip() 和 strip 删除前导和尾随空格,并且不会触及中间的任何内容。不过,稍作改动,您的答案就可以完美运行:mylist = mystring.strip().split(',') 虽然我不知道这是否特别有效。【参考方案4】:
我知道这已经被回答了,但是如果你经常这样做,正则表达式可能是一个更好的方法:
>>> import re
>>> re.sub(r'\s', '', string).split(',')
['blah', 'lots', 'of', 'spaces', 'here']
\s 匹配任何空白字符,我们只需将其替换为空字符串''。你可以在这里找到更多信息:http://docs.python.org/library/re.html#re.sub
【讨论】:
您的示例不适用于包含空格的字符串。 “for, example this, one”会变成“for”、“examplethis”、“one”。并不是说这是一个糟糕的解决方案(它在我的示例中完美运行)它只是取决于手头的任务! 是的,非常正确!您可能可以调整正则表达式,以便它可以处理带有空格的字符串,但如果列表理解有效,我会说坚持下去;)【参考方案5】:使用正则表达式拆分。请注意,我使用前导空格使情况更普遍。列表推导就是去掉前后的空字符串。
>>> import re
>>> string = " blah, lots , of , spaces, here "
>>> pattern = re.compile("^\s+|\s*,\s*|\s+$")
>>> print([x for x in pattern.split(string) if x])
['blah', 'lots', 'of', 'spaces', 'here']
即使^\s+ 不匹配,这仍然有效:
>>> string = "foo, bar "
>>> print([x for x in pattern.split(string) if x])
['foo', 'bar']
>>>
这就是您需要 ^\s+ 的原因:
>>> pattern = re.compile("\s*,\s*|\s+$")
>>> print([x for x in pattern.split(string) if x])
[' blah', 'lots', 'of', 'spaces', 'here']
看到 blah 中的前导空格了吗?
澄清:上面使用的是 Python 3 的解释器,但在 Python 2 中的结果是一样的。
【讨论】:
我相信[x.strip() for x in my_string.split(',')] 对于所提出的问题来说更符合pythonic。也许在某些情况下我的解决方案是必要的。如果我遇到一个,我会更新这个内容。
为什么需要^\s+?我已经在没有它的情况下测试了您的代码,但它不起作用,但我不知道为什么。
如果我使用re.compile("^\s*,\s*$"),结果是[' blah, lots , of , spaces, here ']。
@laike9m,我更新了我的答案以向您展示差异。 ^\s+ 使。如您所见,^\s*,\s*$ 也不会返回所需的结果。因此,如果您想使用正则表达式进行拆分,请使用^\s+|\s*,\s*|\s+$。
如果前导模式 (^\s+) 不匹配,则第一个匹配项为空,因此您会得到类似 [ '', 'foo', 'bar' ] 的字符串 "foo, bar "。【参考方案6】:
我来补充:
map(str.strip, string.split(','))
但看到 Jason Orendorff 在a comment 中已经提到过它。
阅读 Glenn Maynard 的 comment on the same answer 建议对地图进行列表推导后,我开始想知道为什么。我认为他的意思是出于性能原因,但当然他可能是出于风格原因或其他原因(格伦?)。
所以在我的盒子(Ubuntu 10.04 上的 Python 2.6.5)上进行的快速(可能有缺陷?)测试显示,在循环中应用这三种方法:
$ time ./list_comprehension.py # [word.strip() for word in string.split(',')]
real 0m22.876s
$ time ./map_with_lambda.py # map(lambda s: s.strip(), string.split(','))
real 0m25.736s
$ time ./map_with_str.strip.py # map(str.strip, string.split(','))
real 0m19.428s
让map(str.strip, string.split(',')) 成为赢家,尽管看起来他们都在同一个球场上。
当然,尽管出于性能原因不一定要排除 map(带或不带 lambda),但对我来说,它至少与列表理解一样清晰。
【讨论】:
【参考方案7】:s = 'bla, buu, jii'
sp = []
sp = s.split(',')
for st in sp:
print st
【讨论】:
【参考方案8】:re(如在正则表达式中)允许一次拆分多个字符:
$ string = "blah, lots , of , spaces, here "
$ re.split(', ',string)
['blah', 'lots ', ' of ', ' spaces', 'here ']
这不适用于您的示例字符串,但适用于逗号空格分隔的列表。对于您的示例字符串,您可以结合 re.split 功能在 regex 模式 上进行拆分,以获得“split-on-this-or-that”效果。
$ re.split('[, ]',string)
['blah',
'',
'lots',
'',
'',
'',
'',
'of',
'',
'',
'',
'spaces',
'',
'here',
'']
不幸的是,这很难看,但filter 可以解决问题:
$ filter(None, re.split('[, ]',string))
['blah', 'lots', 'of', 'spaces', 'here']
瞧!
【讨论】:
为什么不只是re.split(' *, *', string)?
@PaulTomblin 好主意。也可以这样做:re.split('[, ]*',string) 达到同样的效果。
Dannid 写完后我意识到它不会像@tbc0 的答案那样在开头和结尾去除空格。
@PaulTomblinheh,我的反驳 [, ]* 在列表末尾留下一个空字符串。我认为过滤器仍然是一个不错的选择,或者像最佳答案一样坚持列表理解。【参考方案9】:
import re
result=[x for x in re.split(',| ',your_string) if x!='']
这对我来说很好。
【讨论】:
【参考方案10】:import re
mylist = [x for x in re.compile('\s*[,|\s+]\s*').split(string)]
简单地说,逗号或至少一个空格,前面/后面有/没有空格。
请试一试!
【讨论】:
【参考方案11】:您可以先处理它然后再拆分它,而不是先拆分字符串然后担心空白
string.replace(" ", "").split(",")
【讨论】:
以上是关于python中用正则表达式re去除空格但不去除换行符?的主要内容,如果未能解决你的问题,请参考以下文章