Opencv2.4.9源码分析——Gradient Boosted Trees
Posted zhaocj
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Opencv2.4.9源码分析——Gradient Boosted Trees相关的知识,希望对你有一定的参考价值。
一、原理
梯度提升树(GBT,Gradient Boosted Trees,或称为梯度提升决策树)算法是由Friedman于1999年首次完整的提出,该算法可以实现回归、分类和排序。GBT的优点是特征属性无需进行归一化处理,预测速度快,可以应用不同的损失函数等。
从它的名字就可以看出,GBT包括三个机器学习的优化算法:决策树方法、提升方法和梯度下降法。前两种算法在我以前的文章中都有详细的介绍,在这里我只做简单描述。
决策树是一个由根节点、中间节点、叶节点和分支构成的树状模型,分支代表着数据的走向,中间节点包含着训练时产生的分叉决策准则,叶节点代表着最终的数据分类结果或回归值,在预测的过程中,数据从根节点出发,沿着分支在到达中间节点时,根据该节点的决策准则实现分叉,最终到达叶节点,完成分类或回归。
提升算法是由一系列“弱学习器”构成,这些弱学习器通过某种线性组合实现一个强学习器,虽然这些弱学习器的分类或回归效果可能仅仅比随机分类或回归要好一点,但最终的强学习器却可以得到一个很好的预测结果。
设一个数据集合(x1, y1),(x2,y2), …, (xN,yN),每一个数据项xi是一个表示事物特征属性的矢量,如果yi∈R则为回归问题,如果yi∈-1, 1则为分类问题。通过m-1次迭代得到了一个弱学习器集合k1,k2,…, km-1,则强学习器Cm-1为:
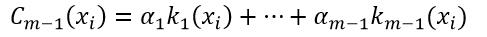 (1)
(1)
式中,α为k的权值,并且m > 1。再经过一次迭代,则强学习器Cm为:
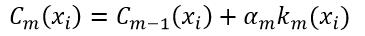 (2)
(2)
Cm的效果一定会强于Cm-1,因为在第m-1次迭代后,算法会对那些预测错误的样本加大权值,使得在第m次迭代时更加关注这些样本,从而达到了纠正上次迭代错误的目的。
在许多应用中,弱学习器往往就是一棵决策树,因此这两种算法结合在一起被称为提升树。
梯度下降法,一般也称为最速下降法(Steepest Descent),是一种一阶优化算法,用此方法可以得到函数的局部极小值。设F(x)是一个多变量的实函数,它在点a的邻域范围内有定义并可微,则F(x)从a点出发沿着负梯度(即梯度相反)的方向下降得最快,即F(x)的值减小得最多:
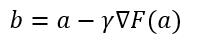 (3)
(3)
式中,γ是一个足够小的常数,它可以控制下降的速度,则F(a)≥F(b)。梯度就是一阶连续偏导,因此式3又可写为:
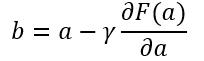 (4)
(4)
如果我们从x0点出发,要到达一个局部极小值点,则应用式4会得到一系列的点x1,x2,…,即
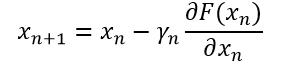 (5)
(5)
则F(x0)≥F(x1)≥F(x2) …,直至F(x)不再变化就达到了局部极小值的点。如果F(x)是一个凸函数,则局部极小值也是全局极小值,因此梯度下降法能够收敛于全局最优。
那么梯度下降法如何与提升树相结合,从而得到一种新的机器学习算法呢?
设F(x)实现了对样本(x, y)的拟合,即y=F(x)。但拟合的效果不是很好,并不能对样本集中的所有样本实现无误差的拟合,即对每个样本总是会有残差:
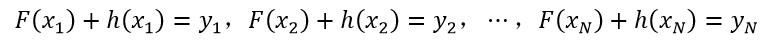 (6)
(6)
式中,h(x)被称为对样本x的残差,该式也可以等价为:
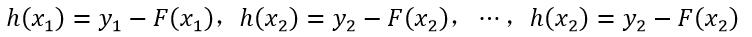 (7)
(7)
在不改变F(x)的前提下,只需要优化h(x)就可以实现提升拟合效果的作用。设F0(x)为初始的拟合函数,h1(x)为经过优化处理后得到的残差,则新的拟合函数F1(x)为
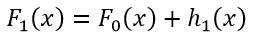 (8)
(8)
式中,
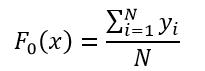 (9)
(9)
即所有样本的初始拟合函数为全体样本响应值的平均值。
F1(x)的拟合效果仍然不能到达预期,则需要继续优化针对F1(x)的残差h2(x),从而得到了F2(x):
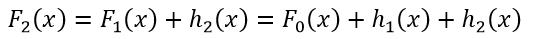 (10)
(10)
经过m次迭代优化,最终得到的拟合函数Fm(x)为:
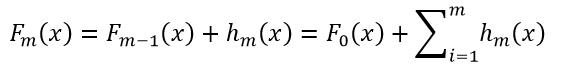 (11)
(11)
与式2相比可以看出,式11也是一种逐步提升性能的过程,但它是通过优化残差实现的。我们可以使用决策树的方法来优化残差,如我们已有了模型Fm(x)(即拟合函数),这时我们需要得到hm+1(x)来建立Fm+1(x)模型,则需要的数据集为
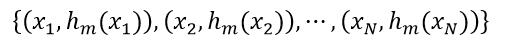 (12)
(12)
由式6,式12改写为
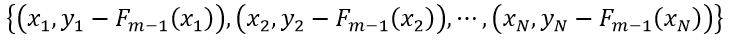 (13)
(13)
我们用式13的数据集合来构建决策树hm+1(x)。与传统的决策树相比,决策树hm+1(x)的数据中的x对应的响应值不是它真正的响应值y,而是残差hm(x),因此我们把hm(x)(或y-Fm-1(x))称为“伪响应值”。在决策树hm+1(x)构建好后,我们再用该决策树对样本数据进行预测,得到的伪响应值hm+1(x)即为Fm+1(x)模型所需要的残差。在提升的过程中残差是会逐渐减小的,因此每次迭代所使用的伪响应值是不同的,所以所使用的决策树也是不同的。
我们再来回顾一下上面的提升过程:真实的样本响应值与当前模型得到的响应值之间会有残差,残差就是用来弥补当前模型的不足。我们构建基于上次迭代时的残差的决策树,通过该决策树的预测就得到了当前模型所需要的新的残差,两者相加就得到了新的模型。但这个提升过程又与梯度下降法有什么联系呢?
我们定义样本x的响应值y与拟合函数F(x)的损失函数为平方损失函数,即:
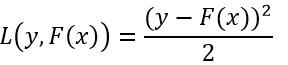 (14)
(14)
很明显,上面的提升过程就是通过改变每个样本的F(xi)使J最小化,其中J为:
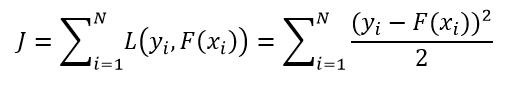 (15)
(15)
我们把F(xi)作为一个参数,并对J求偏导:
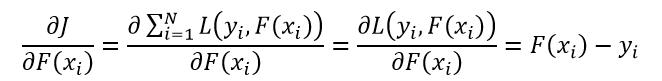 (16)
(16)
因此我们就可以解释残差就是负梯度:
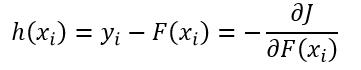 (17)
(17)
所以我们就有了下式:
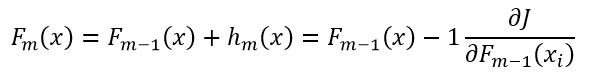 (18)
(18)
式中,F0(x)由式9得到。式18表明基于残差的优化模型F(x)其实就是基于负梯度的优化F(x)。并且式18与式5相比较,就会发现我们实际上就是在使用梯度下降法来优化我们的模型,其中γn为1。
事实证明使用梯度的概念要比使用残差更为通用,因为这样我们可以使用其他的函数来定义损失函数。平方损失函数虽然在引出梯度概念上数学意义更清晰,但它易受到那些离群的样本点的影响,因为它对误差的处理是平方。下面再给出两种损失函数,绝对值损失函数:
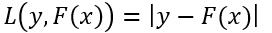 (19)
(19)
Huber损失函数:
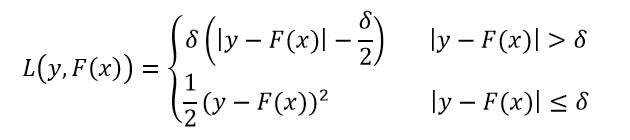 (20)
(20)
这两种损失函数对离群的样本点都具有很强的鲁棒性。对于绝对值损失函数,它的负梯度为:
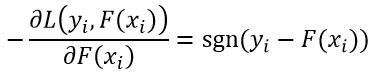 (21)
(21)
式中,sgn( )表示符号函数。对于Huber损失函数,它的负梯度为:
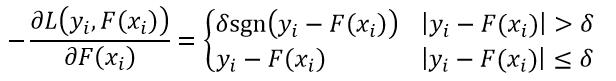 (22)
(22)
很显然,绝对值损失函数和Huber损失函数的负梯度不再是残差,但正因为我们用这些负梯度来替代残差才使得它们的损失函数具有更强的鲁棒性。我们把这些所谓的残差称为“伪残差”。而之所以GBT可以使用其他的损失函数,就是因为GBT引入了伪残差的概念。
对于绝对值损失函数,它的F0(x)可以按如下定义:
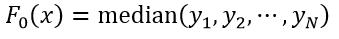 (23)
(23)
式中,函数median表示取中值,如果N是偶数,则中值为中间两个数的平均值。对于Huber损失函数,它的F0(x)可以按如下定义:
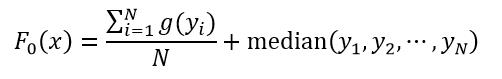 (24)
(24)
式中,
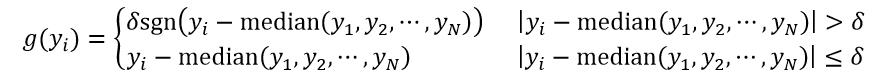 (25)
(25)
平方损失函数、绝对值损失函数和Huber损失函数只能应用于回归问题,而偏差(Deviance)或交叉熵(cross-entropy)损失函数可以用于分类问题。设样本数据集一共有K个分类,F(k)(x)表示第k个分类的拟合函数,即模型,则偏差损失函数为:
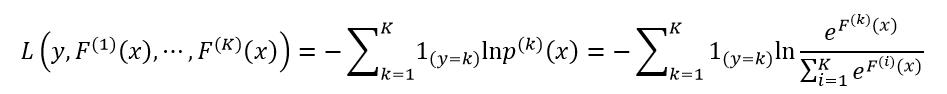 (26)
(26)
式中,1(y=k)表示只有当x属于第k个分类时为1,否则为0。它的负梯度为:
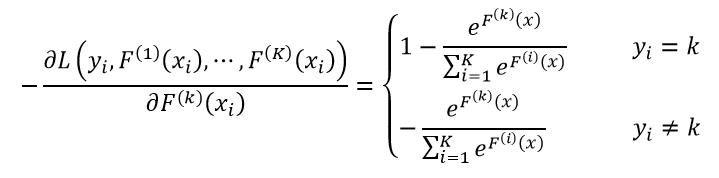 (27)
(27)
回归问题只需要一类模型F(x),而分类问题需要K类模型F(k)(x),每类模型都按式18计算,即
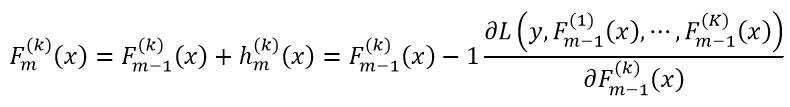 (28)
(28)
所以对于回归问题来说,每一个弱学习器只需要一个决策树,而对于分类问题来说,每个弱学习器需要K个决策树。
在GBT算法中,为了防止过拟合,还可以采取以下措施:
1、控制决策树的规模,主要方法是限定叶节点的数量或限定决策树的深度;
2、增加一个收缩因子(shrinkage)v,则式11改写为:
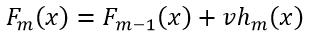 (29)
(29)
式中,v是一个不大于1的正数,一般来说v<0.1。v起到控制学习“步长”的作用,v过大,虽然能够加快学习进度,但一旦发生偏差,很难纠正;v小,虽然学习时间增加了,但不容易出现偏差,即使出现偏差也很容易纠正过来;
3、在用样本构建决策树hm(x)时,可以对叶节点的值(即残差hm(x),也就是最终的回归或分类结果)做进一步的优化。如有r个样本的预测结果是属于叶节点Lj(j表示第j个叶节点),则根据不同的损失函数,由这r个样本的值来调整Lj的值。设调整后的叶节点Lj的值为h(j)m(x),则把该值带入式29来计算这r个样本的模型Fm(x)。对于平方损失函数,h(j)m(x)为:
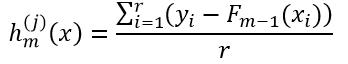 (30)
(30)
式30与式9相比较可以看出,式30使用的是伪响应值,而式9使用的是真正的响应值,两者的区别就在于此。对于绝对值损失函数,h(j)m(x)为:
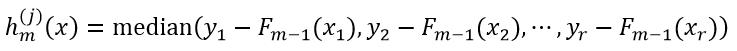 (31)
(31)
对于Huber损失函数,h(j)m(x)为:
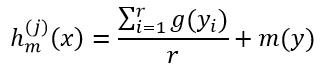 (32)
(32)
式中,
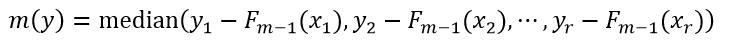 (33)
(33)
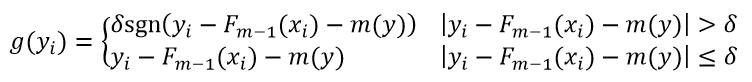 (34)
(34)
对于偏差损失函数,h(j)m(x)为:
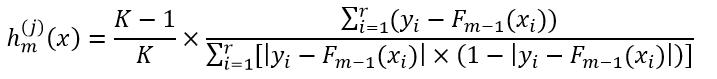 (35)
(35)
式中,K表示所有样本的分类数量。
4、把样本数据集分为训练样本和测试样本,用训练样本构建决策树hm(x),而用测试样本得到具体的hm(x)值。训练样本和测试样本是随机选取的。对于样本数据不是很庞大的情况,训练样本占整个样本集的0.5至0.8是比较合适;对于样本规模比较庞大的,应在0.5以下比较合适。
下面我们总结一下GBT算法的步骤:
1.初始化F0(x),对于分类问题,F0(x)设置为0,对于回归问题,如果是平方损失函数,F0(x)为式9,如果是绝对值损失函数,F0(x)为式23,如果是Huber损失函数,F0(x)为式24;
2.优化迭代过程m=1至M:
◇计算负梯度,即伪残差hm(x)(式17)
◇由该残差组成的数据集(式12)构建决策树hm+1(x)
◇由决策树hm+1(x)预测得到新的伪残差hm+1(x)
◇得到新的模型Fm+1(x)(式29)
3.输出FM(x)
在利用GBT模型对样本进行预测时,对于回归问题,样本x的预测结果y=FM(x):
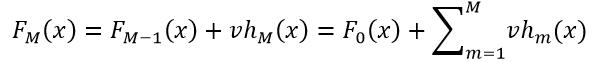 (36)
(36)
式中,F0(x)和v分别为构建GBT模型时使用的初始拟合函数和收缩因子,hm(x)为弱学习器。而分类问题,对于样本x,首先得到所有K个类别的每个分类类别的F(k)M(x):
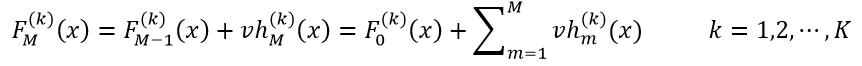 (37)
(37)
F(k)M(x)中的最大值所对应的分类即为样本x的预测结果。
二、源码分析
下面介绍Opencv的GBT源码。
首先给出GBT算法所需参数的结构体CvGBTreesParams:
CvGBTreesParams::CvGBTreesParams( int _loss_function_type, int _weak_count,
float _shrinkage, float _subsample_portion,
int _max_depth, bool _use_surrogates )
: CvDTreeParams( 3, 10, 0, false, 10, 0, false, false, 0 )
loss_function_type = _loss_function_type;
weak_count = _weak_count;
shrinkage = _shrinkage;
subsample_portion = _subsample_portion;
max_depth = _max_depth;
use_surrogates = _use_surrogates;
loss_function_type表示损失函数的类型,CvGBTrees::SQUARED_LOSS为平方损失函数,CvGBTrees::ABSOLUTE_LOSS为绝对值损失函数,CvGBTrees::HUBER_LOSS为Huber损失函数,CvGBTrees::DEVIANCE_LOSS为偏差损失函数,前三种用于回归问题,后一种用于分类问题
weak_count表示GBT的优化迭代次数,对于回归问题来说,weak_count也就是决策树的数量,对于分类问题来说,weak_count×K为决策树的数量,K表示类别数量
shrinkage表示收缩因子v
subsample_portion表示训练样本占全部样本的比例,为不大于1的正数
max_depth表示决策树的最大深度
use_surrogates表示是否使用替代分叉节点,为true,表示使用替代分叉节点
CvDTreeParams结构详见我的关于决策树的文章
CvGBTrees类的一个构造函数:
CvGBTrees::CvGBTrees( const cv::Mat& trainData, int tflag,
const cv::Mat& responses, const cv::Mat& varIdx,
const cv::Mat& sampleIdx, const cv::Mat& varType,
const cv::Mat& missingDataMask,
CvGBTreesParams _params )
data = 0; //表示样本数据集合
weak = 0; //表示一个弱学习器
default_model_name = "my_boost_tree";
// orig_response表示样本的响应值,sum_response表示拟合函数Fm(x),sum_response_tmp表示Fm+1(x)
orig_response = sum_response = sum_response_tmp = 0;
// subsample_train和subsample_test分别表示训练样本集和测试样本集
subsample_train = subsample_test = 0;
// missing表示缺失的特征属性,sample_idx表示真正用到的样本的索引
missing = sample_idx = 0;
class_labels = 0; //表示类别标签
class_count = 1; //表示类别的数量
delta = 0.0f; //表示Huber损失函数中的参数δ
clear(); //清除一些全局变量和已有的所有弱学习器
//GBT算法的学习
train(trainData, tflag, responses, varIdx, sampleIdx, varType, missingDataMask, _params, false);
bool
CvGBTrees::train( const CvMat* _train_data, int _tflag,
const CvMat* _responses, const CvMat* _var_idx,
const CvMat* _sample_idx, const CvMat* _var_type,
const CvMat* _missing_mask,
CvGBTreesParams _params, bool /*_update*/ ) //update is not supported
//_train_data表示样本数据集合
//_tflag表示样本矩阵的存储格式
//_responses表示样本的响应值
//_var_idx表示要用到的特征属性的索引
//_sample_idx表示要用到的样本的索引
//_var_type表示特征属性的类型,是连续值还是离散值
//_missing_mask表示缺失的特征属性的掩码
//_params表示构建GBT模型的一些必要参数
CvMemStorage* storage = 0; //开辟一块内存空间
params = _params; //构建GBT模型所需的参数
bool is_regression = problem_type(); //表示该GBT模型是否用于回归问题
clear(); //清空一些全局变量和已有的所有弱学习器
/*
n - count of samples
m - count of variables
*/
int n = _train_data->rows; //n表示训练样本的数量
int m = _train_data->cols; //m表示样本的特征属性的数量
//如果参数_tflag为CV_ROW_SAMPLE,则表示训练样本以行的形式储存的,即_train_data矩阵的每一行为一个样本,那么n和m无需交换;否则如果_tflag为CV_COL_SAMPLE,则表示样本是以列的形式储存的,那么n和m就需要交换。总之,在后面的程序中,n表示训练样本的数量,m表示样本的特征属性的数量
if (_tflag != CV_ROW_SAMPLE)
int tmp;
CV_SWAP(n,m,tmp);
// new_responses表示每个样本的伪响应值,因为构建GBT决策树使用的是伪响应值
CvMat* new_responses = cvCreateMat( n, 1, CV_32F);
cvZero(new_responses); //伪响应值初始为零
//实例化CvDTreeTrainData类,并通过该类内的set_data函数设置用于决策树的训练样本数据data
data = new CvDTreeTrainData( _train_data, _tflag, new_responses, _var_idx,
_sample_idx, _var_type, _missing_mask, _params, true, true );
if (_missing_mask) //如果给出了缺失特征属性的掩码
missing = cvCreateMat(_missing_mask->rows, _missing_mask->cols,
_missing_mask->type); //初始化missing
cvCopy( _missing_mask, missing); //赋值_missing_mask给missing
//初始化orig_response矩阵的大小,该变量表示样本的原始真实响应值
orig_response = cvCreateMat( 1, n, CV_32F );
//step表示样本响应值的步长
int step = (_responses->cols > _responses->rows) ? 1 : _responses->step / CV_ELEM_SIZE(_responses->type);
//根据样本响应值_responses的数据类型,为orig_response赋值
switch (CV_MAT_TYPE(_responses->type))
case CV_32FC1: //32位浮点型数据
for (int i=0; i<n; ++i)
orig_response->data.fl[i] = _responses->data.fl[i*step];
; break;
case CV_32SC1: //32位整型数据
for (int i=0; i<n; ++i)
orig_response->data.fl[i] = (float) _responses->data.i[i*step];
; break;
default: //其他数据类型报错
CV_Error(CV_StsUnmatchedFormats, "Response should be a 32fC1 or 32sC1 vector.");
if (!is_regression) //如果构建的GBT模型是用于分类问题
class_count = 0; //表示样本类别的数量
//为每个样本定义一个掩码,用于判断样本的类别
unsigned char * mask = new unsigned char[n];
memset(mask, 0, n); //掩码清零
// compute the count of different output classes
for (int i=0; i<n; ++i) //遍历所有样本,得到类别的数量
//如果当前样本的掩码没有被置1,则说明当前样本属于新的类别
if (!mask[i])
class_count++; //样本类别数加1
//判断当前样本以后的所有样本的响应值是否与当前样本的响应值相同,即是否属于同一类,如果是同一类,则把样本掩码置1,说明它不再是新的类别
for (int j=i; j<n; ++j)
if (int(orig_response->data.fl[j]) == int(orig_response->data.fl[i]))
mask[j] = 1;
delete[] mask; //删除mask变量
//初始化样本类别标签,并赋首地址指针
class_labels = cvCreateMat(1, class_count, CV_32S);
class_labels->data.i[0] = int(orig_response->data.fl[0]);
int j = 1; //表示所有样本类别标签的索引值
for (int i=1; i<n; ++i) //遍历所有样本,为样本类别标签赋值
int k = 0; //表示已得到的样本类别标签的索引值
//while循环用于判断是否有新的类别标签出现。如果orig_response->data.fl[i]等于class_labels->data.i[k],说明当前样本的类别存在于已经得到的类别标签中,则退出while循环,继续for循环;如果k≥j,说明已经遍历完类别标签
while ((int(orig_response->data.fl[i]) - class_labels->data.i[k]) && (k<j))
k++; //索引值加1
if (k == j) //说明得到了新的类别标签
//赋值新的类别标签
class_labels->data.i[k] = int(orig_response->data.fl[i]);
j++; //索引值加1
// inside gbt learning proccess only regression decision trees are built
//GBT模型用到的是回归树,所以要把data->is_classifier赋值为false
data->is_classifier = false;
// preproccessing sample indices
//如果_sample_idx不为0,需要预处理那些被指定使用的样本数据
if (_sample_idx)
int sample_idx_len = get_len(_sample_idx); //被指定的要使用的样本数据的数量
switch (CV_MAT_TYPE(_sample_idx->type)) //判断样本的数据类型
case CV_32SC1: //32位整型
sample_idx = cvCreateMat( 1, sample_idx_len, CV_32S ); //初始化
//遍历指定的样本数据,赋值
for (int i=0; i<sample_idx_len; ++i)
sample_idx->data.i[i] = _sample_idx->data.i[i];
break;
//8位有、无符号位的整型,8位样本数据存储在32位数据中,即每32位数据包括4个8位样本数据,以节省内存空间
case CV_8S:
case CV_8U:
//变量active_samples_count表示8位样本数据需要多少个32位数据
int active_samples_count = 0;
for (int i=0; i<sample_idx_len; ++i) //得到active_samples_count值
active_samples_count += int( _sample_idx->data.ptr[i] );
sample_idx = cvCreateMat( 1, active_samples_count, CV_32S ); //初始化
active_samples_count = 0;
//为sample_idx赋值,赋的不是真正的样本值,而是索引值
for (int i=0; i<sample_idx_len; ++i)
if (int( _sample_idx->data.ptr[i] ))
sample_idx->data.i[active_samples_count++] = i;
break;
//其他数据类型报错
default: CV_Error(CV_StsUnmatchedFormats, "_sample_idx should be a 32sC1, 8sC1 or 8uC1 vector.");
//按从小到大的顺序对样本数据进行排序存放,以便后续处理
icvSortFloat(sample_idx->data.fl, sample_idx_len, 0);
else //全体样本数据都用于构建GBT模型
sample_idx = cvCreateMat( 1, n, CV_32S ); //初始化
for (int i=0; i<n; ++i)
sample_idx->data.i[i] = i; //赋样本的索引值
//初始化矩阵变量sum_response和sum_response_tmp
sum_response = cvCreateMat(class_count, n, CV_32F);
sum_response_tmp = cvCreateMat(class_count, n, CV_32F);
cvZero(sum_response); //sum_response矩阵清零
delta = 0.0f; //Huber损失函数的参数δ赋值为0
/*
in the case of a regression problem the initial guess (the zero term
in the sum) is set to the mean of all the training responses, that is
the best constant model
*/
// base_value表示F0(x)
//如果是回归问题,通过调用find_optimal_value函数得到F0(x),find_optimal_value函数详见后面的介绍
if (is_regression) base_value = find_optimal_value(sample_idx);
/*
in the case of a classification problem the initial guess (the zero term
in the sum) is set to zero for all the trees sequences
*/
//如果是分类问题,F0(x)设置为0
else base_value = 0.0f;
/*
current predicition on all training samples is set to be
equal to the base_value
*/
cvSet( sum_response, cvScalar(base_value) ); //使sum_response等于base_value
//初始化弱学习器weak,如果是回归问题,class_count为1,即一个弱学习器就是一个决策树;如果是分类问题,class_count为类别的数量,即一个弱学习器是由class_count个决策树构成
weak = new pCvSeq[class_count];
//初始化弱学习器
for (int i=0; i<class_count; ++i)
storage = cvCreateMemStorage();
weak[i] = cvCreateSeq( 0, sizeof(CvSeq), sizeof(CvDTree*), storage );
storage = 0;
// subsample params and data
rng = &cv::theRNG(); //实例化RNG类,用于得到随机数,以便随机选取训练样本数据
int samples_count = get_len(sample_idx); //得到样本总数
//如果subsample_portion太接近0或太接近1,则subsample_portion重新赋值为1
params.subsample_portion = params.subsample_portion <= FLT_EPSILON ||
1 - params.subsample_portion <= FLT_EPSILON
? 1 : params.subsample_portion;
//得到训练样本的数量
int train_sample_count = cvFloor(params.subsample_portion * samples_count);
// train_sample_count为0,则样本总数就是训练样本数量
if (train_sample_count == 0)
train_sample_count = samples_count;
int test_sample_count = samples_count - train_sample_count; //得到测试样本数量
//开辟一个大小为samples_count内存空间,idx_data指向该空间的首地址,该空间的前train_sample_count个单位存放着训练样本所对应的全体样本的索引值,后test_sample_count个单位存放着测试样本所对应的全体样本的索引值
int* idx_data = new int[samples_count];
//初始化subsample_train
subsample_train = cvCreateMatHeader( 1, train_sample_count, CV_32SC1 );
*subsample_train = cvMat( 1, train_sample_count, CV_32SC1, idx_data );
//初始化subsample_test
if (test_sample_count)
subsample_test = cvCreateMatHeader( 1, test_sample_count, CV_32SC1 );
*subsample_test = cvMat( 1, test_sample_count, CV_32SC1,
idx_data + train_sample_count );
// training procedure
//构建GBT模型
for ( int i=0; i < params.weak_count; ++i ) //遍历所有的弱学习器
do_subsample(); //随机选取训练样本集和测试样本集
//遍历当前弱学习器的所有决策树
for ( int k=0; k < class_count; ++k )
//计算负梯度,该函数在后面给出详细的解释
find_gradient(k);
CvDTree* tree = new CvDTree; //实例化决策树
tree->train( data, subsample_train ); //构建决策树
//优化决策树叶节点的值(即伪残差),该函数在后面给出详细的解释
change_values(tree, k);
if (subsample_test) //如果有测试样本集
CvMat x; //表示一个测试样本
CvMat x_miss; //表示缺失了某个特征属性的测试样本
int* sample_data = sample_idx->data.i; //表示全体样本数据的首地址
//表示测试样本数据的首地址
int* subsample_data = subsample_test->data.i;
//得到样本的步长
int s_step = (sample_idx->cols > sample_idx->rows) ? 1
: sample_idx->step/CV_ELEM_SIZE(sample_idx->type);
for (int j=0; j<get_len(subsample_test); ++j) //遍历所有测试样本
//得到当前测试样本的索引值
int idx = *(sample_data + subsample_data[j]*s_step);
float res = 0.0f; //当前决策树的预测结果,即为伪残差h(x)
//根据索引值得到当前的测试样本数据x
if (_tflag == CV_ROW_SAMPLE)
cvGetRow( data->train_data, &x, idx);
else
cvGetCol( data->train_data, &x, idx);
if (missing) //如果有缺失的特征属性
//得到缺失了特征属性的测试样本x_miss
if (_tflag == CV_ROW_SAMPLE)
cvGetRow( missing, &x_miss, idx);
else
cvGetCol( missing, &x_miss, idx);
res = (float)tree->predict(&x, &x_miss)->value; //得到预测结果
else //没有缺失特征属性的测试样本的预测
res = (float)tree->predict(&x)->value; //得到预测结果
//式29
sum_response_tmp->data.fl[idx + k*n] =
sum_response->data.fl[idx + k*n] +
params.shrinkage * res;
//把当前得到的决策树tree放入决策树序列中
cvSeqPush( weak[k], &tree );
tree = 0; //决策树清零
// k=0..class_count
//更新F(x),sum_response_tmp和sum_response交换
CvMat* tmp;
tmp = sum_response_tmp;
sum_response_tmp = sum_response;
sum_response = tmp;
tmp = 0;
// i=0..params.weak_count
//清除一些局部变量
delete[] idx_data;
cvReleaseMat(&new_responses);
data->free_train_data();
return true;
// CvGBTrees::train(...)
void CvGBTrees::find_gradient(const int k)
//k表示分类问题中的第k个分类,即类别的索引值;回归问题中,该参数没有意义
int* sample_data = sample_idx->data.i; //得到样本数据集
int* subsample_data = subsample_train->data.i; //得到训练样本数据集
float* grad_data = data->responses->data.fl; //得到样本的伪响应值
float* resp_data = orig_response->data.fl; //得到样本的真实响应值
float* current_data = sum_response->data.fl; //得到拟合函数F(x)
//根据损失函数的类型,计算负梯度
switch (params.loss_function_type)
// loss_function_type in
// SQUARED_LOSS, ABSOLUTE_LOSS, HUBER_LOSS, DEVIANCE_LOSS
case SQUARED_LOSS: //平方损失函数
for (int i=0; i<get_len(subsample_train); ++i) //遍历所有训练样本
//得到样本步长
int s_step = (sample_idx->cols > sample_idx->rows) ? 1
: sample_idx->step/CV_ELEM_SIZE(sample_idx->type);
//得到当前的训练样本索引值
int idx = *(sample_data + subsample_data[i]*s_step);
grad_data[idx] = resp_data[idx] - current_data[idx]; //式17
; break;
case ABSOLUTE_LOSS: //绝对值损失函数
for (int i=0; i<get_len(subsample_train); ++i) //遍历所有训练样本
//得到样本步长
int s_step = (sample_idx->cols > sample_idx->rows) ? 1
: sample_idx->step/CV_ELEM_SIZE(sample_idx->type);
//得到当前的训练样本索引值
int idx = *(sample_data + subsample_data[i]*s_step);
//式21,Sign()函数为系统定义的符号函数,
grad_data[idx] = Sign(resp_data[idx] - current_data[idx]);
; break;
case HUBER_LOSS: //Huber损失函数
float alpha = 0.2f;
int n = get_len(subsample_train); //得到训练样本的长度
//得到样本步长
int s_step = (sample_idx->cols > sample_idx->rows) ? 1
: sample_idx->step/CV_ELEM_SIZE(sample_idx->type);
//开辟一块用于存储n个残差yi-F(xi)的空间
float* residuals = new float[n];
for (int i=0; i<n; ++i) //遍历所有训练样本
//得到当前的训练样本索引值
int idx = *(sample_data + subsample_data[i]*s_step);
//计算残差yi-F(xi)的绝对值
residuals[i] = fabs(resp_data[idx] - current_data[idx]);
icvSortFloat(residuals, n, 0.0f); //对残差排序
//计算式20中的参数δ,即为五分之一处的残差值
delta = residuals[int(ceil(n*alpha))];
for (int i=0; i<n; ++i) //遍历所有训练样本
//得到当前的训练样本索引值
int idx = *(sample_data + subsample_data[i]*s_step);
//计算yi-F(xi)
float r = resp_data[idx] - current_data[idx];
grad_data[idx] = (fabs(r) > delta) ? delta*Sign(r) : r; //式22
delete[] residuals; //删除变量residuals
; break;
case DEVIANCE_LOSS: //偏差损失函数
for (int i=0; i<get_len(subsample_train); ++i) //遍历所有训练样本
double exp_fk = 0; //表示式26中分子部分的eF(x)
double exp_sfi = 0; //表示式26中分母部分的∑eF(x)
//得到样本步长
int s_step = (sample_idx->cols > sample_idx->rows) ? 1
: sample_idx->step/CV_ELEM_SIZE(sample_idx->type);
//得到当前的训练样本索引值
int idx = *(sample_data + subsample_data[i]*s_step);
//遍历所有的分类类别,计算eF(x)和∑eF(x)
for (int j=0; j<class_count; ++j)
double res;
res = current_data[idx + j*sum_response->cols]; //得到F(x)
res = exp(res); //得到eF(x)
//k为需要计算的第k个分类,j==k的含义就是式26中的1(y=k)
if (j == k) exp_fk = res; //计算eF(x)
exp_sfi += res; //计算∑eF(x)
int orig_label = int(resp_data[idx]); //得到当前样本的原始分类标签
/*
grad_data[idx] = (float)(!(k-class_labels->data.i[orig_label]+1)) -
(float)(exp_fk / exp_sfi);
*/
// ensemble_label表示当前样本的分类类别是第几个分类
int ensemble_label = 0;
while (class_labels->data.i[ensemble_label] - orig_label)
ensemble_label++; //累加递增
//式27
grad_data[idx] = (float)(!(k-ensemble_label)) -
(float)(exp_fk / exp_sfi);
; break;
default: break;
// CvGBTrees::find_gradient(...)
void CvGBTrees::change_values(CvDTree* tree, const int _k)
//tree表示决策树
//k表示分类问题中的第k个分类,即类别的索引值;回归问题中,该参数没有意义
//实例化CvDTreeNode结构,表示决策树的节点
CvDTreeNode** predictions = new pCvDTreeNode[get_len(subsample_train)];
int* sample_data = sample_idx->data.i; //得到样本数据
int* subsample_data = subsample_train->data.i; //得到训练样本数据
//得到样本步长
int s_step = (sample_idx->cols > sample_idx->rows) ? 1
: sample_idx->step/CV_ELEM_SIZE(sample_idx->type);
CvMat x; //表示一个测试样本
CvMat miss_x; //表示缺失了某个特征属性的测试样本
for (int i=0; i<get_len(subsample_train); ++i) //遍历所有测试样本
//得到当前的训练样本索引值
int idx = *(sample_data + subsample_data[i]*s_step);
//根据索引值得到当前的测试样本数据x
if (data->tflag == CV_ROW_SAMPLE)
cvGetRow( data->train_data, &x, idx);
else
cvGetCol( data->train_data, &x, idx);
if (missing) //如果有缺失的特征属性
//得到缺失了特征属性的测试样本miss_x
if (data->tflag == CV_ROW_SAMPLE)
cvGetRow( missing, &miss_x, idx);
else
cvGetCol( missing, &miss_x, idx);
predictions[i] = tree->predict(&x, &miss_x); //得到预测结果的叶节点
else //没有缺失特征属性的测试样本的预测
predictions[i] = tree->predict(&x); //得到预测结果的叶节点
CvDTreeNode** leaves; //表示决策树的一个叶节点
int leaves_count = 0; //表示决策树的叶节点总数
//GetLeaves函数的作用是由决策树tree得到所有的叶节点leaves,并得到leaves_count
leaves = GetLeaves( tree, leaves_count);
for (int i=0; i<leaves_count; ++i) //遍历所有叶节点
//该变量表示训练样本中的预测结果有多少是属于当前叶节点
int samples_in_leaf = 0;
for (int j=0; j<get_len(subsample_train); ++j) //遍历所有训练样本
//如果当前叶节点就是当前训练样本的预测叶节点,则samples_in_leaf累加
if (leaves[i] == predictions[j]) samples_in_leaf++;
//如果没有得到相同的叶节点,则继续处理下一个叶节点,这种情况其实是不可能出现的
if (!samples_in_leaf) // It should not be done anyways! but...
leaves[i]->value = 0.0;
continue;
//定义leaf_idx,用于记录相同叶节点的索引值
CvMat* leaf_idx = cvCreateMat(1, samples_in_leaf, CV_32S);
int* leaf_idx_data = leaf_idx->data.i; //提取首地址指针
for (int j=0; j<get_len(subsample_train); ++j) //遍历训练样本
int idx = *(sample_data + subsample_data[j]*s_step); //得到训练样本的索引
//如果叶节点相同,则赋值该样本的索引值
if (leaves[i] == predictions[j])
*leaf_idx_data++ = idx;
// 得到具体的优化值,find_optimal_value函数详见后面的介绍
float value = find_optimal_value(leaf_idx);
leaves[i]->value = value; //赋值该叶节点的值
leaf_idx_data = leaf_idx->data.i; //重新指向首地址指针
int len = sum_response_tmp->cols; //得到长度
for (int j=0; j<get_len(leaf_idx); ++j) //遍历所有相同的叶节点
int idx = leaf_idx_data[j]; //得到该叶节点对应的样本索引值
//式29
sum_response_tmp->data.fl[idx + _k*len] =
sum_response->data.fl[idx + _k*len] +
params.shrinkage * value;
leaf_idx_data = 0;
cvReleaseMat(&leaf_idx); //释放内存空间
// releasing the memory
//下面的语句都是用于释放内存空间
for (int i=0; i<get_len(subsample_train); ++i)
predictions[i] = 0;
delete[] predictions;
for (int i=0; i<leaves_count; ++i)
leaves[i] = 0;
delete[] leaves;
float CvGBTrees::find_optimal_value( const CvMat* _Idx )
// _Idx表示需要被处理的样本
double gamma = (double)0.0; //表示最佳值
int* idx = _Idx->data.i; //得到样本的索引值
float* resp_data = orig_response->data.fl; //得到样本的真实响应值
//得到拟合函数F(x),在没有构建GBT模型之前,sum_response为0
float* cur_data = sum_response->data.fl;
int n = get_len(_Idx); //样本的数量
//根据损失函数的类型,计算最佳值
switch (params.loss_function_type)
// SQUARED_LOSS=0, ABSOLUTE_LOSS=1, HUBER_LOSS=3, DEVIANCE_LOSS=4
case SQUARED_LOSS: //平方损失函数
for (int i=0; i<n; ++i) //遍历所有样本
gamma += resp_data[idx[i]] - cur_data[idx[i]]; //(伪)响应值和
gamma /= (double)n; //平均(伪)响应值,式9或式30
; break;
case ABSOLUTE_LOSS: //绝对值损失函数
//开辟一块用于存储n个残差yi-F(xi)的空间
float* residuals = new float[n];
for (int i=0; i<n; ++i, ++idx) //遍历所有样本,计算(伪)响应值
residuals[i] = (resp_data[*idx] - cur_data[*idx]);
icvSortFloat(residuals, n, 0.0f); //对(伪)响应值排序
//取(伪)响应值的中值作为gamma,式23或式31
if (n % 2)
gamma = residuals[n/2];
else gamma = (residuals[n/2-1] + residuals[n/2]) / 2.0f;
delete[] residuals; //释放内存
; break;
case HUBER_LOSS: //Huber损失函数
//开辟一块用于存储n个(伪)响应值的空间
float* residuals = new float[n];
for (int i=0; i<n; ++i, ++idx) //遍历所有样本,计算(伪)响应值
residuals[i] = (resp_data[*idx] - cur_data[*idx]);
icvSortFloat(residuals, n, 0.0f); //对(伪)响应值排序
int n_half = n >> 1; //表示n值的一半
//得到(伪)响应值的中值r_median,n == n_half<<1表示n是偶数
float r_median = (n == n_half<<1) ?
(residuals[n_half-1] + residuals[n_half]) / 2.0f :
residuals[n_half];
for (int i=0; i<n; ++i) //遍历所有样本
float dif = residuals[i] - r_median; //计算基于(伪)响应值中值的方差
gamma += (delta < fabs(dif)) ? Sign(dif)*delta : dif; //式25或式34中的g(yi)
gamma /= (double)n;
gamma += r_median; //式24或式32
delete[] residuals; //释放内存
; break;
case DEVIANCE_LOSS: //偏差损失函数
float* grad_data = data->responses->data.fl; //得到伪响应值,即负梯度
double tmp1 = 0;
double tmp2 = 0;
double tmp = 0;
for (int i=0; i<n; ++i) //遍历所有样本
tmp = grad_data[idx[i]]; //得到负梯度
tmp1 += tmp; //式35中第二个分式的分子部分
tmp2 += fabs(tmp)*(1-fabs(tmp)); //式35中第二个分式的分母部分
;
if (tmp2 == 0) //避免分母为0
tmp2 = 1;
//式35
gamma = ((double)(class_count-1)) / (double)class_count * (tmp1/tmp2);
; break;
default: break;
return float(gamma); //返回最佳值
// CvGBTrees::find_optimal_value
float CvGBTrees::predict( const CvMat* _sample, const CvMat* _missing,
CvMat* /*weak_responses*/, CvSlice slice, int k) const
//_sample表示预测样本
//_missing表示预测样本中所缺失的特征属性的掩码
// weak_responses表示得到的所有决策树的预测结果
// slice表示所使用的弱学习器的形式,如果为Range::all()表示应用所有的弱学习器
//k表示对于分类问题,第k个分类类别的预测结果作为样本的预测结果,如果为-1,表示应用完整的GBT模型,对于回归问题,k必须为-1
float result = 0.0f; //表示该函数的返回值
if (!weak) return 0.0f; //如果GBT模型还没构建好,则预测结果为0,并退出
float* sum = new float[class_count]; //表示最终的GBT的预测结果
for (int i=0; i<class_count; ++i)
sum[i] = 0.0f; //初始化sum
//定义所使用的弱学习器的起始和终止
int begin = slice.start_index;
int end = begin + cvSliceLength( slice, weak[0] );
pCvSeq* weak_seq = weak; //表示弱学习器队列
//实例化Tree_predictor类,该类在后面给出详细的解释
Tree_predictor predictor = Tree_predictor(weak_seq, class_count,
params.shrinkage, _sample, _missing, sum);
//并行处理,得到预测结果
cv::parallel_for_(cv::Range(begin, end), predictor);
//遍历所有分类类别,得到每一个分类的预测结果
for (int i=0; i<class_count; ++i)
sum[i] = sum[i] /** params.shrinkage*/ + base_value;
//如果是回归问题,则预测结果为sum[0]
if (class_count == 1)
result = sum[0];
delete[] sum;
return result;
//如果k有定义,则第k个分类类别的预测结果作为该样本的预测结果
if ((k>=0) && (k<class_count))
result = sum[k];
delete[] sum;
return result;
//对于分类问题,哪一类的预测结果大,则样本就属于哪一类
float max = sum[0]; //最大值
int class_label = 0; //类别标签
for (int i=1; i<class_count; ++i) //遍历所有的类别
if (sum[i] > max) //找到最大值
max = sum[i]; //更新最大值
class_label = i; //更新类别标签
delete[] sum; //清内存
int orig_class_label = class_labels->data.i[class_label]; //类别标签所对应的类别
return float(orig_class_label);
class Tree_predictor : public cv::ParallelLoopBody
private:
pCvSeq* weak; //弱学习器
float* sum; //弱学习器的预测结果
const int k; //分类类别数量
const CvMat* sample; //预测样本
const CvMat* missing; //缺失的特征属性掩码
const float shrinkage; //收缩因子v
static cv::Mutex SumMutex; //表示互斥
public:
//构造函数
Tree_predictor() : weak(0), sum(0), k(0), sample(0), missing(0), shrinkage(1.0f)
Tree_predictor(pCvSeq* _weak, const int _k, const float _shrinkage,
const CvMat* _sample, const CvMat* _missing, float* _sum ) :
weak(_weak), sum(_sum), k(_k), sample(_sample),
missing(_missing), shrinkage(_shrinkage)
Tree_predictor( const Tree_predictor& p, cv::Split ) :
weak(p.weak), sum(p.sum), k(p.k), sample(p.sample),
missing(p.missing), shrinkage(p.shrinkage)
Tree_predictor& operator=( const Tree_predictor& )
return *this;
//重载()运算符
virtual void operator()(const cv::Range& range) const
CvSeqReader reader;
int begin = range.start; //起始弱学习器
int end = range.end; //终止弱学习器
int weak_count = end - begin; //弱学习器的数量
CvDTree* tree; //决策树
//如果是分类问题的话,遍历所有分类类别,如果是回归问题,k为0,只执行一次
for (int i=0; i<k; ++i)
float tmp_sum = 0.0f;
if ((weak[i]) && (weak_count)) //如果当前弱学习器存在
cvStartReadSeq( weak[i], &reader ); //初始化reader为weak[i]
cvSetSeqReaderPos( &reader, begin ); //从begin开始
for (int j=0; j<weak_count; ++j) //遍历所有弱学习器
CV_READ_SEQ_ELEM( tree, reader ); //依次得到决策树tree
//式36或式37中的∑v h(k)m(x)
tmp_sum += shrinkage*(float)(tree->predict(sample, missing)->value);
cv::AutoLock lock(SumMutex);
sum[i] += tmp_sum; //式36或式37的结果
// Tree_predictor::operator()
//析构函数
virtual ~Tree_predictor()
; // class Tree_predictor
三、应用实例
房屋的售价由房屋的面积和房间的数量决定,下表是某一地区的样本统计:
| 序号 | 房屋面积 | 房间数量 | 售价 | 序号 | 房屋面积 | 房间数量 | 售价 |
| 1 | 210.4 | 3 | 399900 | 15 | 160.0 | 3 | 329900 |
| 2 | 240.0 | 3 | 369000 | 16 | 141.6 | 2 | 232000 |
| 3 | 300.0 | 4 | 539900 | 17 | 198.5 | 4 | 299900 |
| 4 | 153.4 | 3 | 314900 | 18 | 142.7 | 3 | 198999 |
| 5 | 138.0 | 3 | 212000 | 19 | 149.4 | 3 | 242500 |
| 6 | 194.0 | 4 | 239999 | 20 | 200.0 | 3 | 347000 |
| 7 | 189.0 | 3 | 329999 | 21 | 447.8 | 5 | 699900 |
| 8 | 126.8 | 3 | 259900 | 22 | 230.0 | 4 | 449900 |
| 9 | 132.0 | 2 | 299900 | 23 | 123.6 | 3 | 199900 |
| 10 | 260.9 | 4 | 499998 | 24 | 303.1 | 4 | 599000 |
| 11 | 176.7 | 3 | 252900 | 25 | 188.8 | 2 | 255000 |
| 12 | 160.4 | 3 | 242900 | 26 | 196.2 | 4 | 259900 |
| 13 | 389.0 | 3 | 573900 | 27 | 110.0 | 3 | 249900 |
| 14 | 145.8 | 3 | 464500 | 28 | 252.6 | 3 | 469000 |
#include "opencv2/core/core.hpp"
#include "opencv2/highgui/highgui.hpp"
#include "opencv2/imgproc/imgproc.hpp"
#include "opencv2/ml/ml.hpp"
#include <iostream>
using namespace cv;
using namespace std;
int main( int argc, char** argv )
double trainingData[28][2]=210.4, 3, 240.0, 3, 300.0, 4, 153.4, 3, 138.0, 3,
194.0,4, 189.0, 3, 126.8, 3, 132.0, 2, 260.9, 4,
176.7,3, 160.4, 3, 389.0, 3, 145.8, 3, 160.0, 3,
141.6,2, 198.5, 4, 142.7, 3, 149.4, 3, 200.0, 3,
447.8,5, 230.0, 4, 123.6, 3, 303.1, 4, 188.8, 2,
196.2,4, 110.0, 3, 252.6, 3 ;
Mat trainingDataMat(28, 2, CV_32FC1, trainingData);
float responses[28] = 399900, 369000, 539900, 314900, 212000, 239999, 329999,
259900, 299900, 499998, 252900, 242900, 573900, 464500,
329900, 232000, 299900, 198999, 242500, 347000, 699900,
449900, 199900, 599000, 255000, 259900, 249900, 469000;
Mat responsesMat(28, 1, CV_32FC1, responses);
//设置参数
CvGBTreesParams params;
params.loss_function_type = CvGBTrees::ABSOLUTE_LOSS;
params.weak_count = 10;
params.shrinkage = 0.01f;
params.subsample_portion = 0.8f;
params.max_depth = 3;
params.use_surrogates = false;
CvGBTrees gbt; //训练样本
gbt.train(trainingDataMat, CV_ROW_SAMPLE, responsesMat, Mat(), Mat(), Mat(), Mat(),params);
double sampleData[2]=185.4, 4; //待预测样本
Mat sampleMat(2, 1, CV_32FC1, sampleData);
float r = gbt.predict(sampleMat); //预测
cout<<endl<<"result: "<<r<<endl;
return 0;
最终的输出值为:
result: 312376以上是关于Opencv2.4.9源码分析——Gradient Boosted Trees的主要内容,如果未能解决你的问题,请参考以下文章
Win7下qt5.3.1+opencv2.4.9编译环境的搭建(好多 Opencv2.4.9源码分析的博客)