node.js做一个简单的爬虫,专爬网站接口
Posted 发奋图强_lee
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了node.js做一个简单的爬虫,专爬网站接口相关的知识,希望对你有一定的参考价值。
因为浏览器同源策略的限制,我们是不可以直接调用不在同一服务器的接口,这样会有跨域问题,除非那后台添加了跨域请求头。
所以很多vue的初学者,自己想练习项目,但苦于不会后端没法自造一些api供自己练习,这样只能把一些数据放在自定义的数组里面来模拟接口返回的数据结构,这个当然可以(或者用mock.js),不过造数据太麻烦,并且对于一个前端工发人员,必须要懂得调用接口和处理异步的问题。所以我今天教大家一个很简单爬网站接口方法,再供前端页面调用。
1、首先,你要下载安装node.js,这个对一个webpack管理项目的员工来说是再正常不过了。

2,npm init 初始化,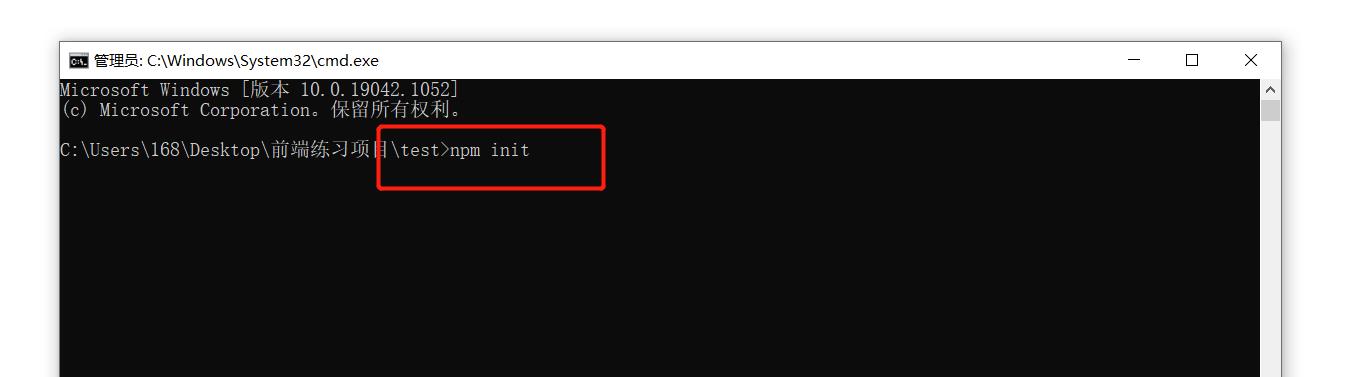
你可以一直按回车健
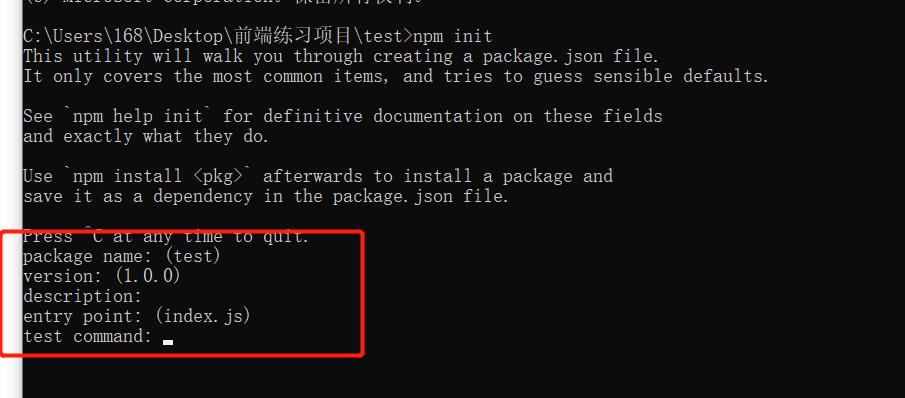
3、直到生成package.json

4,安装node.js的中间健
npm install express -S
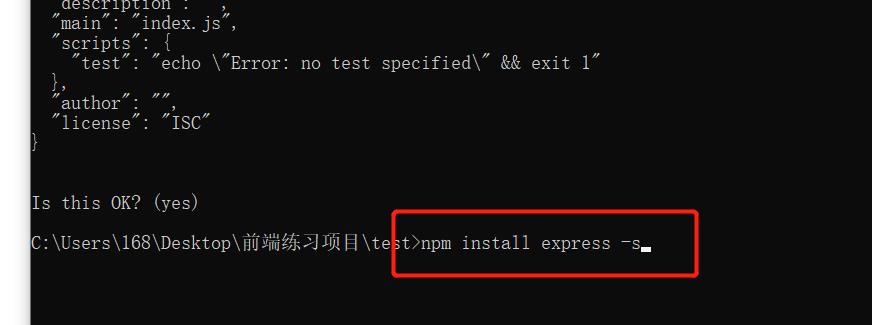
再装一个 npm install axios -S

装完之后就多了一个文件夹和一个文件

5,创建一个index.js,内容如下
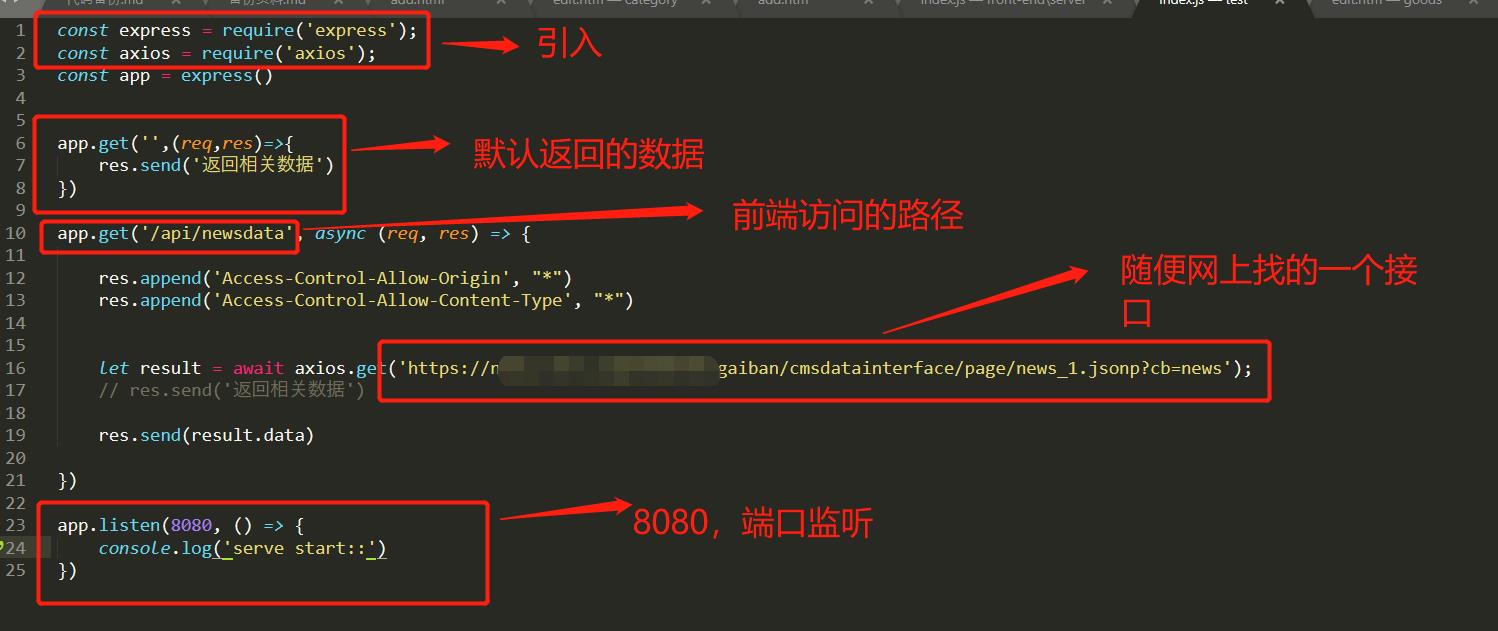 其中,如下图这个接口就是别人的官网的接口,把这个接口完整地址放在 axios.get('')里,如上图:
其中,如下图这个接口就是别人的官网的接口,把这个接口完整地址放在 axios.get('')里,如上图:
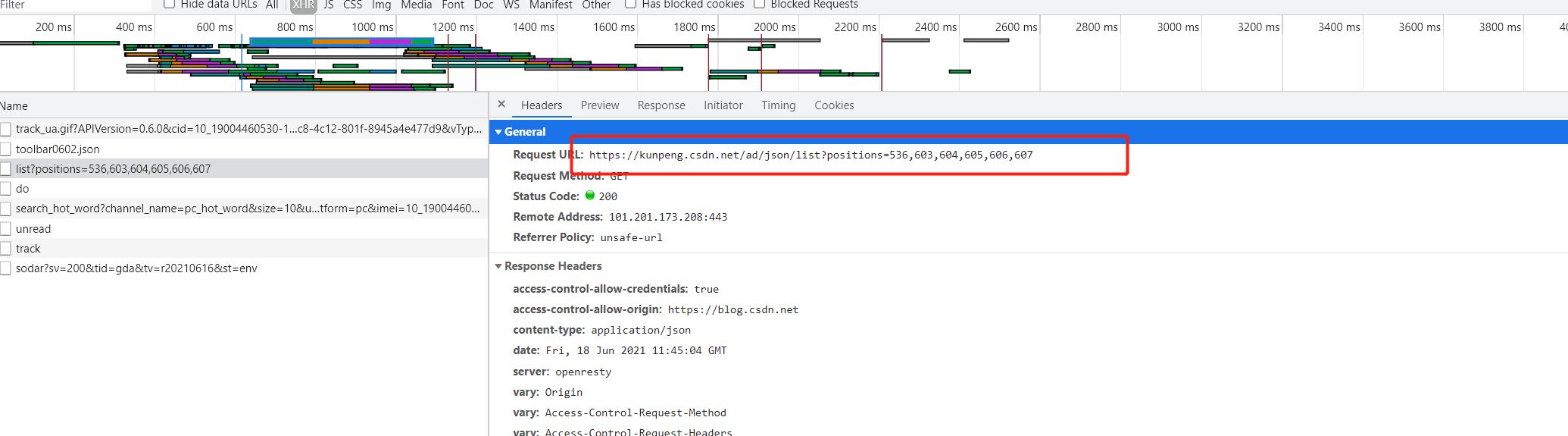
这样就可以把别人的接口爬出来了,
6,启动 node index.js

7,调用
默认打开

调用localhost:8080/api/newsdata

之后可以用 axios调用了


注意: 如果没有这两行代码,前端调用localhost:8080/api/newsdata会出现跨域的问题
res.append('Access-Control-Allow-Origin', "*")
res.append('Access-Control-Allow-Content-Type', "*")================================================

以上是关于node.js做一个简单的爬虫,专爬网站接口的主要内容,如果未能解决你的问题,请参考以下文章