(2021-03-18)ElasticSearch学习之基于Kibana练习操作命令
Posted Mr. Dreamer Z
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了(2021-03-18)ElasticSearch学习之基于Kibana练习操作命令相关的知识,希望对你有一定的参考价值。
之前搞定了ES的基础知识和安装。今天来学习一下ES的基本操作,当然了,是在kibana下操作。
OK话不多说,开始今天的学习。
首先打开你的kibana,选择Dev Tools

然后开始今天的命令操作。
1.创建索引
众所周知的是ES相当于一个索引库。第一步让我们来创建索引
PUT /testtest是我们创建的索引名称,创建成功之后我们能看到相应的提示

翻译一下对应的英文描述:
弃用:在7.0.0中,默认的分片数将从[5]更改为[1];如果您希望继续使用默认的[5]分片,则必须在创建索引请求或使用索引模板进行管理。
从中我们可以知道在es7.0之后,默认的分片数会从原来的5改为1
2.查看索引
创建索引成功之后,我们可以通过命令查看
GET /_cat/indices?v可以看到当前所有的索引以及它的具体信息

health:代表索引的健壮性。yellow代表不健壮,green代表健壮
status:代表索引是否启用
index:代表我们创建的索引的名称
uuid:代表这个索引对应的id
3.删除索引
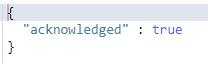
DELETE /test删除成功显示:
4.创建一个完整的索引
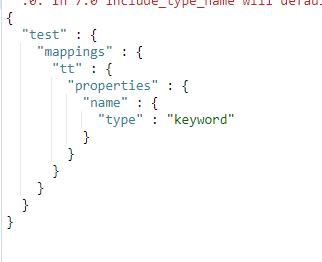
PUT /test
"mappings":
"tt":
"properties":
"name":
"type":"keyword"
这个是创建索引,类型以及属性
语法:
"mappings":
"类型":
"properties":
"属性":
"type":"属性类型"
这里说一句,对应的属性类型:
keyword(相当于小型的string),text(相当于string),integer,long,boolean,date
注意了,text是会自动分词的。比如,你添加一个name叫张二狗,它会自动分次成为:张,二,狗。之前的文章中我们提到过,es内部结构是由索引区和元数据区构成。这样的话我们是无法通过搜索”张二狗“得到对应的数据信息的。
除了text之后,其余都不会分词。所以请尽量在字符串不是太长的情况使用keyword,就算你安装了ik分词器。也要谨慎使用。不然会很酸爽。
5.查询自己创建的索引内容
GET /test/_mapping语法:GET /索引名/_mapping
可以看到我们创建的索引以及它的属性
6.插入文档
PUT /test
"mappings":
"book":
"properties":
"id":
"type":"keyword"
,
"name":
"type":"keyword"
,
"price":
"type":"double"
,
"author":
"type":"keyword"
,
"des":
"type":"text"
再次之前,请大家先删除对应的索引。重新创建
PUT /test/book/1
"id":1,
"name":"十万个为啥",
"price":25.2,
"author":"小张",
"des":"这是一本奇书"
PUT /索引/类型/文档id(也就是该条记录的id)
7.根据文档id查询数据
GET /test/book/1PUT /索引/类型/文档id

8.插入文档(自定义生成文档id)
POST /test/book
"id":2,
"name":"小小鸟",
"price":35.2,
"author":"小王",
"des":"动物世界"
可以看到,和之前指定id生成不同。这个是自己生成的文档id
POST /索引/类型

9.通过id更新-不保留原始数据(先删除后插入,只会保留插入的数据)
POST /test/book/Mo6TAXgB8W1sqhC4XMcW
"name":"王二狗",
"age":99
POST /索引/类型/文档id
操作成功之后,让我们来看看这条数据
GET /test/book/Mo6TAXgB8W1sqhC4XMcW可以看到的是,我们的id没有变化,但是属性只有这两个了。

10.批量操作
bulk代表批量操作
POST /test/book/_bulk
"index":"_id":1
"id":1,"name":"总部","price":87.1
"index":
"id":2,"name":"分布","price":17.1
"update":"_id":"M46ZAXgB8W1sqhC4sMeC"
"doc":"name":"哈塞克"
"delete":"_id":"OY6zAXgB8W1sqhC4YseZ"11.特定领域的查询语言 match_all-匹配所有
GET /test/book/_search
"query":
"match_all":
12. 查询所有并排序
GET /test/book/_search
"query":
"match_all":
,
"sort": [
"age":
"order": "desc"
,
"bir":
"order": "desc"
]
13. 分页查询
GET /test/book/_search
"query":
"match_all":
,
"size": 2,
"from":0
14.指定查询结果中返回字段 _source
GET /test/book/_search
"query":
"match_all":
,
"_source":"name"
GET /test/book/_search
"query":
"match_all":
,
"_source":["name","age"]
15. 基于关键词进行查询
GET /test/book/_search
"query":
"term":
"name":
"value": "小黑"
16. 高亮查询
GET /test/book/_search
"query":
"term":
"content":
"value": "redis"
,
"highlight":
"pre_tags": ["<span style='color:red'>"],
"post_tags": ["</span>"],
"fields":
"content":
--------------------------------------------------------------
过滤查询
1.查询所有
GET /test/book/_search
"query":
"term":
"content":
"value": "武侠"
2.过滤使用 filter
GET /test/book/_search
"query":
"bool":
"must": [
"term":
"content":
"value": "搜索"
],
"filter":
"range":
"age":
"gte": 10,
"lte": 100
3.基于指定关键词过滤 term
GET /test/book/_search
"query":
"bool":
"must": [
"term":
"name":
"value": "小黑"
],
"filter":
"term":
"content": "架构"
GET /test/book/_search
"query":
"bool":
"must": [
"match_all":
],
"filter":
"terms":
"content": [
"架构",
"redis"
]
4.过滤存在指定字段,获取字段不为空的索引记录使用 exists filter
GET /test/book/_search
"query":
"bool":
"must": [
"match_all":
],
"filter":
"exists":
"field": "address"
以上是关于(2021-03-18)ElasticSearch学习之基于Kibana练习操作命令的主要内容,如果未能解决你的问题,请参考以下文章