使用Python将NWPU VHR-10数据集的格式转换成VOC2007数据集的格式
Posted 大彤小忆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用Python将NWPU VHR-10数据集的格式转换成VOC2007数据集的格式相关的知识,希望对你有一定的参考价值。
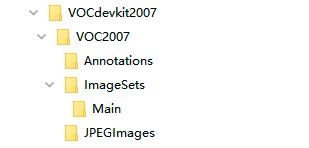
一、VOC2007数据集
VOC2007数据集的文件结构如下图所示。
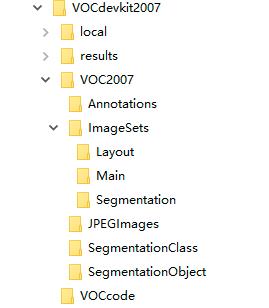
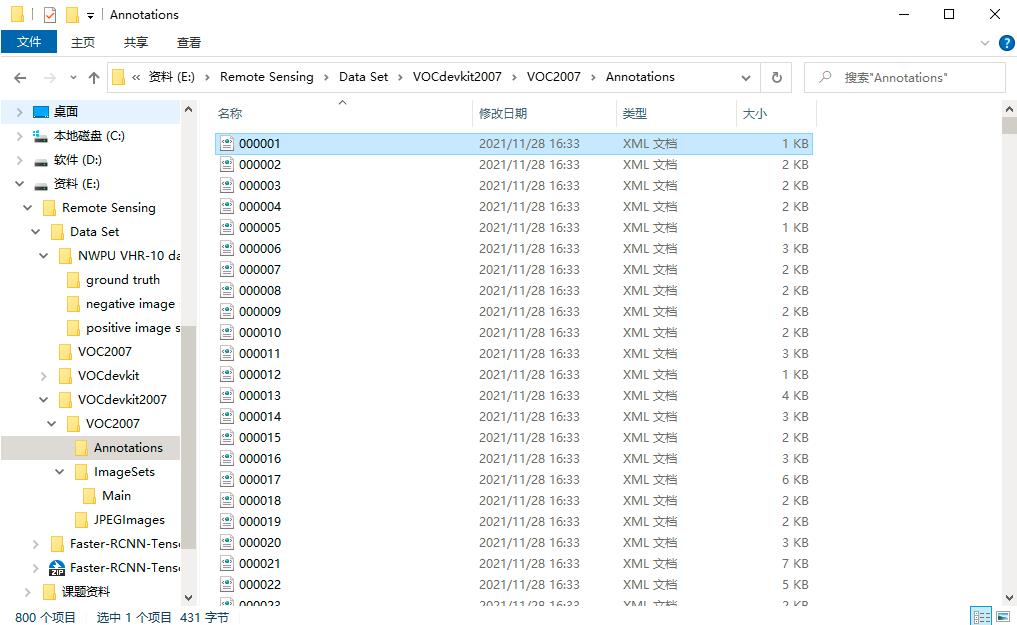
其中,文件夹Annotations中存放的是图像的标注信息的xml文件,命名从000001.xml开始;文件夹ImageSets中存放的是图像划分的集合的txt文件,目标检测任务对应的train、val、trainval、test数据集的txt文件存放在Main文件夹中;文件夹JPEGImages中存放的是所有图片的jpg文件,命名从000001.jpg开始;文件夹SegmentationClass和SegmentationObject中存放的是其他任务的数据信息。
文件夹Annotations中存放的某一张图像的标注信息的xml文件里面的内容如下所示。
<annotation>
<folder>VOC2007</folder>
<!--文件名-->
<filename>000007.jpg</filename>
<!--数据来源-->
<source>
<!--数据来源-->
<database>The VOC2007 Database</database>
<annotation>PASCAL VOC2007</annotation>
<!--来源是flickr,一个雅虎的图像分享网站,下面是id,对于我们没有用-->
<image>flickr</image>
<flickrid>194179466</flickrid>
</source>
<!--图片的所有者,也没有用-->
<owner>
<flickrid>monsieurrompu</flickrid>
<name>Thom Zemanek</name>
</owner>
<!--图像尺寸,宽、高、长-->
<size>
<width>500</width>
<height>333</height>
<depth>3</depth>
</size>
<!--是否用于分割,0表示用于,1表示不用于-->
<segmented>0</segmented>
<!--下面是图像中标注的物体,每一个object包含一个标准的物体-->
<object>
<!--物体名称,拍摄角度-->
<name>car</name>
<pose>Unspecified</pose>
<!--是否被裁减,0表示完整,1表示不完整-->
<truncated>1</truncated>
<!--是否容易识别,0表示容易,1表示困难-->
<difficult>0</difficult>
<!--bounding box的四个坐标-->
<bndbox>
<xmin>141</xmin>
<ymin>50</ymin>
<xmax>500</xmax>
<ymax>330</ymax>
</bndbox>
</object>
</annotation>
关于VOC2007数据集的其他详细信息可见→VOC2007数据集详细分析。
二、NWPU VHR-10数据集
NWPU VHR-10数据集的文件结构如下图所示。

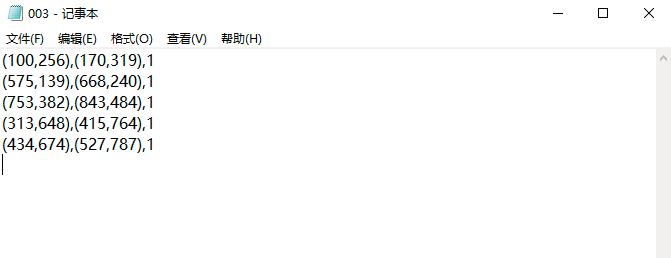
其中,文件夹ground truth中存放的是图像的标注信息的txt文件,某一张图像的标注信息的txt文件里面的内容如下所示。
文件夹positive image set中存放的是有对应标注信息txt文件的图片,命名从001.jpg开始。
文件夹negative image set中存放的是没有对应标注信息txt文件的图片,命名也从001.jpg开始。
三、将NWPU VHR-10数据集的格式转换成VOC2007数据集的格式
使用Python将NWPU VHR-10数据集的格式转换成VOC2007数据集的格式需要进行以下操作。
-
新建一个与VOC2007数据集的文件结构类似的文件夹结构,只保留我们需要的部分。
-
NWPU VHR-10数据集的
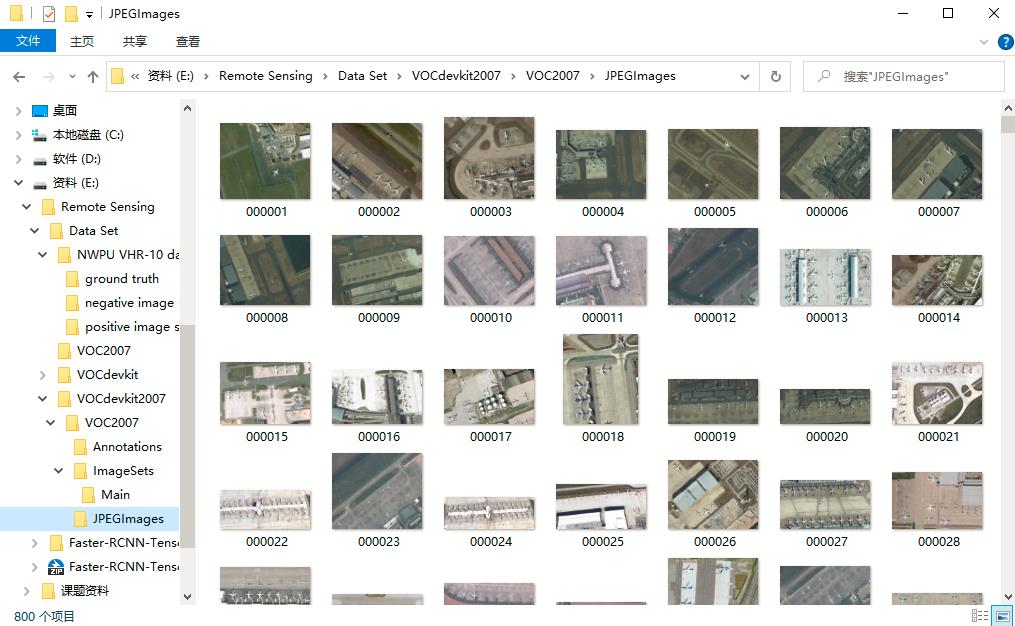
positive image set文件夹内的图片重命名为000001.jpg-000650.jpg,将negative image set文件夹内的图片重命名为000651.jpg-000800.jpg,并一起保存到新建文件夹的./VOCdevkit2007/VOC2007/JPEGImages/路径下。重命名的代码images_rename.py及结果如下所示。
import os
import shutil
def imag_rename(old_path, new_path,start_number = 0):
filelist = os.listdir(old_path) # 该文件夹下所有的文件(包括文件夹)
if os.path.exists(new_path) == False:
os.mkdir(new_path)
for file in filelist: # 遍历所有文件
Olddir = os.path.join(old_path, file) # 原来的文件路径
if os.path.isdir(Olddir): # 如果是文件夹则跳过
continue
filename = os.path.splitext(file)[0] # 文件名
filetype = os.path.splitext(file)[1] # 文件扩展名
if filetype == '.jpg':
Newdir = os.path.join(new_path, str(int(filename) + start_number).zfill(6) + filetype)
# 用字符串函数zfill 以0补全所需位数
shutil.copyfile(Olddir, Newdir)
if __name__ == "__main__":
# 解决positive image set文件夹中的重命名问题,start_number = 0
old_path = "E:/Remote Sensing/Data Set/NWPU VHR-10 dataset/positive image set/"
new_path = "E:/Remote Sensing/Data Set/VOCdevkit2007/VOC2007/JPEGImages/"
imag_rename(old_path, new_path)
# 解决negative image set文件夹中的重命名问题,start_number = 650
old_path = "E:/Remote Sensing/Data Set/NWPU VHR-10 dataset/negative image set/"
new_path = "E:/Remote Sensing/Data Set/VOCdevkit2007/VOC2007/JPEGImages/"
imag_rename(old_path,new_path,start_number = 650)
print("done!")
- 将NWPU VHR-10数据集的
ground truth文件夹内的标注信息txt文件转换为与VOC2007数据集的Annotations文件夹内的标注信息xml文件格式相同的xml文件,并重命名为000001.xml-000650.xml;由于negative image set文件夹内的图片没有对应的标注信息文件,所以生成包含图片的size信息、不包含object的bounding box信息的xml文件,并命名为000651.xml-000800.xml,并一起保存到新建文件夹的./VOCdevkit2007/VOC2007/Annotations/路径下。转换代码NWPU_VOC.py及结果如下所示。
from lxml.etree import Element,SubElement,tostring
from xml.dom.minidom import parseString
import xml.dom.minidom
import os
import sys
from PIL import Image
# 处理NWPU VHR-10数据集中的txt标注信息转换成 xml文件
# 此处的path应该传入的是NWPU VHR-10数据集文件夹下面的ground truth文件夹的目录
# 即 path = "E:/Remote Sensing/Data Set/NWPU VHR-10 dataset/ground truth"
def deal(path):
files=os.listdir(path) # files获取所有标注txt文件的文件名
# 此处可以自行设置输出路径 按照VOC数据集的格式,xml文件应该输出在数据集文件下面的Annotations文件夹下面
outpath = "E:/Remote Sensing/Data Set/VOCdevkit2007/VOC2007/Annotations/"
# 如果输出文件夹不存在,就创建它
if os.path.exists(outpath) == False:
os.mkdir(outpath)
# 遍历所有的txt标注文件,一共650个txt文件
for file in files:
filename=os.path.splitext(file)[0] # 获取ground truth文件夹中标注txt文件的文件名,比如如果文件名为001.txt,那么filename = '001'
sufix=os.path.splitext(file)[1]# 获取标注txt文件的后缀名 判断是否为txt
if sufix=='.txt': # 标注txt文件中每一行代表一个目标,(x1,y1),(x2,y2),class_number来表示
xmins=[]
ymins=[]
xmaxs=[]
ymaxs=[]
names=[]
# num,xmins,ymins,xmaxs,ymaxs,names=readtxt(path + '/' + file) # 调用readtxt文件获取信息,转到readtxt函数
path_txt = path + '/' + file # 获取txt标注文件的路径信息
# 打开txt标注文件
with open(path_txt, 'r') as f:
contents = f.read() # 将txt文件的信息按行读取到contents列表中
objects=contents.split('\\n') # 以换行划分每一个目标的标注信息,因为每一个目标的标注信息在txt文件中为一行
for i in range(objects.count('')):
objects.remove('') # 将objects中的空格移除
num=len(objects) # 获取一个标注文件的目标个数,objects中一个元素代表的信息就是一个检测目标
# 遍历 objects列表,获取每一个检测目标的五维信息
for objecto in objects:
xmin=objecto.split(',')[0] # xmin = '(563'
xmin=xmin.split('(')[1] # xmin = '563' 可能存在空格
xmin=xmin.strip() # strip函数去掉字符串开头结尾的空格符
ymin=objecto.split(',')[1] # ymin = '478)'
ymin=ymin.split(')')[0] # ymin = '478' 可能存在空格
ymin=ymin.strip() # strip函数去掉字符串开头结尾的空格符
xmax=objecto.split(',')[2] # xmax同理
xmax=xmax.split('(')[1]
xmax=xmax.strip()
ymax=objecto.split(',')[3] # ymax同理
ymax=ymax.split(')')[0]
ymax=ymax.strip()
name=objecto.split(',')[4] # 与上 同理
name=name.strip()
if name=="1 " or name=="1": # 将数字信息转换成label字符串信息
name='airplane'
elif name=="2 "or name=="2":
name='ship'
elif name== "3 "or name=="3":
name='storage tank'
elif name=="4 "or name=="4":
name='baseball diamond'
elif name=="5 "or name=="5":
name='tennis court'
elif name=="6 "or name=="6":
name='basketball court'
elif name=="7 "or name=="7":
name='ground track field'
elif name=="8 "or name=="8":
name='harbor'
elif name=="9 "or name=="9":
name='bridge'
elif name=="10 "or name=="10":
name='vehicle'
else:
print(path)
# print(xmin,ymin,xmax,ymax,name)
xmins.append(xmin)
ymins.append(ymin)
xmaxs.append(xmax)
ymaxs.append(ymax)
names.append(name)
filename_fill = str(int(filename)).zfill(6) # 将xml的文件名填充为6位数,比如1.xml就改为000001.xml
filename_jpg = filename_fill + ".jpg" # 由于xml中存储的文件名为000001.jpg,所以还得对所有的NWPU数据集中的图片进行重命名
print(filename_fill)
dealpath = outpath + filename_fill +".xml"
# 注意,经过重命名转换之后,图片都存放在E:/Remote Sensing/Data Set/VOCdevkit2007/VOC2007/JPEGImages/中
imagepath = "E:/Remote Sensing/Data Set/VOCdevkit2007/VOC2007/JPEGImages/" + filename_fill + ".jpg"
with open(dealpath, 'w') as f:
img=Image.open(imagepath) # 根据图片的地址打开图片并获取图片的宽 和 高
width=img.size[0]
height=img.size[1]
# 将图片的宽和高以及其他和VOC数据集向对应的信息
writexml(dealpath,filename_jpg,num,xmins,ymins,xmaxs,ymaxs,names, height, width)
# 同时也得给negative image set文件夹下面的所有负样本图片生成xml标注
negative_path = "E:/Remote Sensing/Data Set/NWPU VHR-10 dataset/negative image set/"
negative_images = os.listdir(negative_path)
for file in negative_images:
filename = file.split('.')[0] # 获取文件名,不包括后缀名
filename_fill = str(int(filename) + 650).zfill(6) # 将xml的文件名填充为6位数。同时加上650,比如1.xml就改为00001.xml
filename_jpg = filename_fill + '.jpg' # 比如第一个负样本001.jpg的filename_jpg 为000651.jpg
## 重命名为6位数
print(filename_fill)
## 生成不含目标的xml文件
dealpath = outpath + filename_fill +".xml"
# 注意,经过重命名转换之后,图片都存放在E:/Remote Sensing/Data Set/VOCdevkit2007/VOC2007/JPEGImages/中
imagepath = "E:/Remote Sensing/Data Set/VOCdevkit2007/VOC2007/JPEGImages/" + filename_fill + ".jpg"
with open(dealpath, 'w') as f:
img = Image.open(imagepath)
width = img.size[0]
height = img.size[1]
# 将宽高和空的目标标注信息写入xml标注
writexml(dealpath,filename_jpg,num = 0,xmins = [],ymins = [],xmaxs = [],ymaxs = [],names = [],width=width,height=height)
# NWPU数据集中标注的五维信息 (x1,y1) denotes the top-left coordinate of the bounding box,
# (x2,y2) denotes the right-bottom coordinate of the bounding box
# 所以 xmin = x1 ymin = y1, xmax = x2, ymax = y2 同时要注意这里的相对坐标是以图片左上角为坐标原点计算的
# VOC数据集对于包围框标注的格式是bounding-box(包含左下角和右上角xy坐标
# 将从txt读取的标注信息写入到xml文件中
def writexml(path,filename,num,xmins,ymins,xmaxs,ymaxs,names,height, width):# Nwpu-vhr-10 < 1000*600
node_root=Element('annotation')
node_folder=SubElement(node_root,'folder')
node_folder.text="VOC2007"
node_filename=SubElement(node_root,'filename')
node_filename.text="%s" % filename
node_size=SubElement(node_root,"size")
node_width = SubElement(node_size, 'width')
node_width.text = '%s' % width
node_height = SubElement(node_size, 'height')
node_height.text = '%s' % height
node_depth = SubElement(node_size, 'depth')
node_depth.text = '3'
for i in range(num):
node_object = SubElement(node_root, 'object')
node_name = SubElement(node_object, 'name')
node_name.text = '%s' % names[i]
node_name = SubElement(node_object, 'pose')
node_name.text = '%s' % "unspecified"
node_name = SubElement(node_object, 'truncated')
node_name.text = '%s' % "0"
node_difficult = SubElement(node_object, 'difficult')
node_difficult.text = '0'
node_bndbox = SubElement(node_object, 'bndbox')
node_xmin = SubElement(node_bndbox, 'xmin')
node_xmin.text = '%s'% xmins[i]
node_ymin = SubElement(node_bndbox, 'ymin')
node_ymin.text = '%s' % ymins[i]
node_xmax = SubElement(node_bndbox, 'xmax')
node_xmax.text = '%s' % xmaxs[i]
node_ymax = SubElement(node_bndbox, 'ymax')
node_ymax.text = '%s' % ymaxs[i]
xml = tostring(node_root, pretty_print=True)
dom = parseString(xml)
with open(path, 'wb') as f:
f.write(xml)
return
if __name__ == "__main__":
# path指定的是标注txt文件所在的路径
path = "E:/Remote Sensing/Data Set/NWPU VHR-10 dataset/ground truth"
deal(path)
print("done!")
- 对NWPU VHR-10数据集进行划分,划分为train、val、trainval、test四个文件。由于只有
positive image set文件夹中的650张图片包含目标的标注信息,所以训练集train及验证集val只能在从这650张图片中划分,negative image set文件夹中的150张图片不包含目标的标注信息,划分在测试集test中。划分代码split_data.py及结果如下所示。
import os
import random
trainval_percent = 0.8 # 表示训练集和验证集(交叉验证集)所占总图片的比例
train_percent = 0.75 # 训练集所占验证集的比例
xmlfilepath = 'E:/Remote Sensing/Data Set/VOCdevkit2007/VOC2007/Annotations'
txtsavepath = 'E:/Remote Sensing/Data Set/VOCdevkit2007/VOC2007/ImageSets/Main'
total_xml = os.listdir(xmlfilepath)
num = 650 # 有目标的图片数
list = range(num)
tv = int(num * trainval_percent) # xml文件中的交叉验证集数
tr = int(tv * train_percent) # xml文件中的训练集数,注意,我们在前面定义的是训练集占验证集的比例
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('E:/Remote Sensing/Data Set/VOCdevkit2007/VOC2007/ImageSets/Main/trainval.txt', 'w')
ftest = open('E:/Remote Sensing/Data Set/VOCdevkit2007/VOC2007/ImageSets/Main/test.txt', 'w')
ftrain = open('E:/Remote Sensing/Data Set/VOCdevkit2007/VOC2007/ImageSets/Main/train.txt', 'w')
fval = open('E:/Remote Sensing/Data Set/VOCdevkit2007/VOC2007/ImageSets/Main/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
for i in range(150):
num = str