架构师成长记_第八周_01_分布式搜索引擎 ElasticSearch 快速入门
Posted _大木_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了架构师成长记_第八周_01_分布式搜索引擎 ElasticSearch 快速入门相关的知识,希望对你有一定的参考价值。
文章目录
- 分布式搜索引擎 ElasticSearch 快速入门
分布式搜索引擎 ElasticSearch 快速入门
1. 搜索引擎的对比(Lucene vs Solr vs Elasticsearch)
1.1 Lucene
Lucene 是java类库, 它完全是由java进行开发编写的, 它并不是应用程序, 是一些api来提供调用, 本质就是一个jar包, 通过导入项目来调用API的方法.
它只能适用于java语言, 并且很难进行分布式的横向扩展.
1.2 Solr
Solr 是基于 Lucene 构建的一个开源搜索引擎, 本质上是对Lucene 的一层封装, 是Apache 使用java进行开发的, 可以独立的部署在 tomcat 或者其他容器之中, 可以配合 zookeeper 进行集群实现, 它的容错性, 可扩展性也很高.
1.3 Elasticsearch(官网描述)
ES 也是基于 Lucene, 也封装了一些Lucene的类库, 出现于 Solr 之后, 也是分布式的搜索引擎, 提供了一系列的restful接口来让我们进行查询操作, 可以对任何的开发语言进行对接, 所以它的可扩展性是非常高的.
ES 也提供了一些近实时检索的搜索服务, 也支持PB级别(1024T)的搜索.
2. ES 核心术语
与关系型数据库进行类比: 一个ES 就相当于 一个数据库
2.1 索引库 index (相当于 数据库中的表)
2.2 类型 type (相当于 数据库的 表逻辑类型)
比如该表是描述 food食物的等, 用于区分不同的表, 所以type 是用于区分索引index的
PS: 最新的 ES 已经取消了 type, 在5.x, 6.x版本存在
2.3 文档 document (相当于 表的行(记录), 它是以 json的形式存在)
2.4 字段 fields (相当于 表的列)
PS:
在一个ES库, 是可以有多个索引库.
文档是以json的形式存在在, 一个文档就是表中的一条记录.
索引是由很多的文档构成, 文档是由多个字段构成.
如下:
user_index (这是一个索引库, 下面是大括号就是多个文档,文档中的 id,name,age 就是字段)
id: 1001,
name: jason,
age: 18
,
id: 1002,
name: kason,
age: 15
2.5 映射 mapping (相当于表的结构类型)
如一个表中的 id 是int类型, name 是varchar 类型, 在ES 中也有类似的定义, 称为 mapping, 如字段是怎么样的数据类型, 是否是被索引, 是否进行分词等等.
2.6 近实时 NRT (Near real time)
当一个新的索引建立新的文档之后, 这个文档就需要被用户去搜索, 用户在搜索这个文档的中间会有一定的延时(1秒左右), 称之为近实时.
2.7 节点 node (每一个服务器)
ES 一般是处于集群中的, 我们可以构建多个节点作为 ES 服务.
2.8 shard replica 数据分片与备份
分片(shard):
把索引库拆分为多份, 分别放在不同的节点上, 比如有3个节点, 3个节点的所有内容加在一起是一个完整的索引库, 分别保存到三个节点上, 目的是为了水平扩展, 提高吞吐量.
备份(replica):
每个 shard 的备份.
PS1: ES 集群架构原理
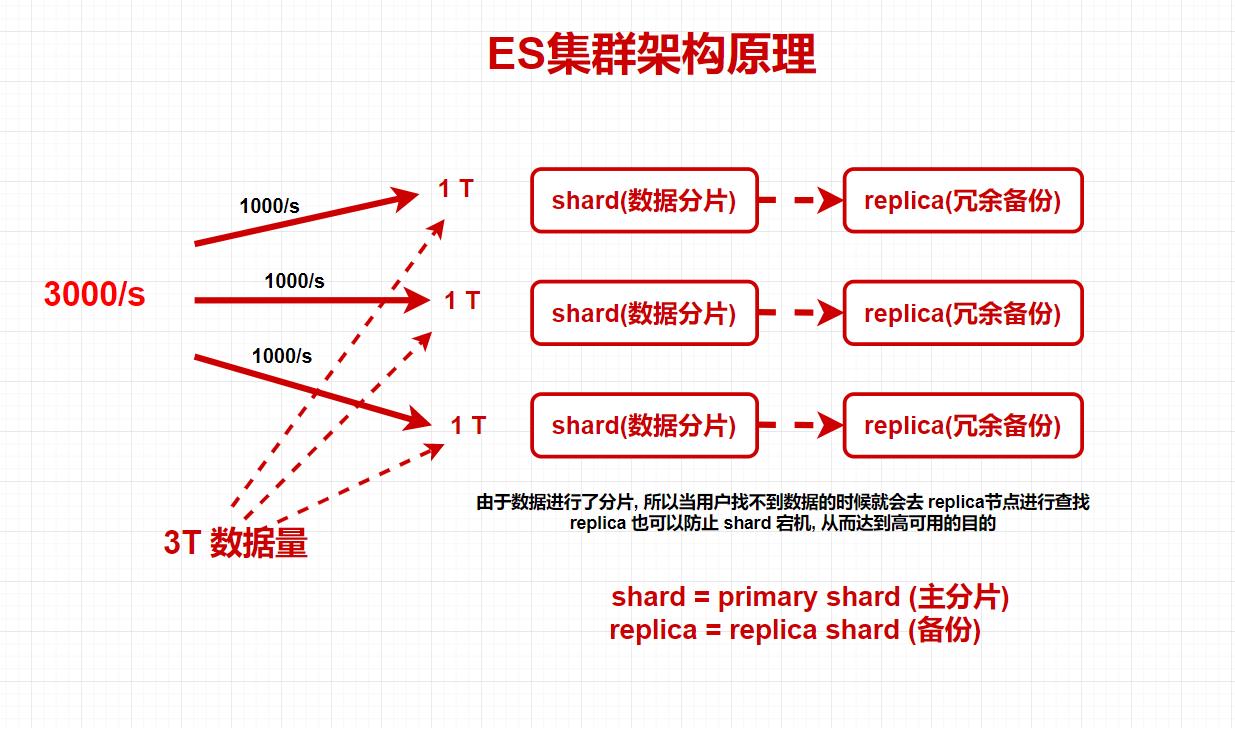
PS2 : 简称
shard = primary shard (主分片)
replica = replica shard (备份节点)
3. 倒排索引
倒排索引源于实际应用中需要根据属性的值来查找记录, 这种索引表中的每一项都包括一个属性值和包含该属性值的各个记录地址. 由于不是根据记录来确定属性, 而是根据属性来确定记录的位置, 所以称为倒排索引

以上是关于架构师成长记_第八周_01_分布式搜索引擎 ElasticSearch 快速入门的主要内容,如果未能解决你的问题,请参考以下文章