C语言共用体
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了C语言共用体相关的知识,希望对你有一定的参考价值。
#include <stdio.h>
union pw
int i;
char ch[2];
a;
main()
a.ch[0]=13;
a.ch[1]=0;
printf("%d\n",a.i);
怎么算
int和char占用的字节数跟编译器有关,可以用sizeof()查看。
这里假设int占4个字节,char占1个字节,共用体变量a的内存分布如下图所示:
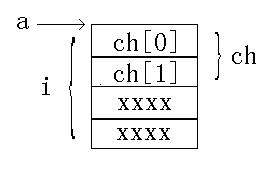
因此,如果之前未对 i 赋值,那打印 i 的值实际上就是打印二进制(xxxx xxxx ch[1] ch[0])数对应的十进制数。xxxx表示该字节的数是不确定的。当xxxx是0的时候,则 i = (00 00 00 0C),对应的十进制数就是13。
参考技术A 联合表示几个变量公用一个内存位置, 在不同的时间保存不同的数据类型和不同长度的变量。下面是MSDN的引用:
If a union of two types is declared and one value is stored, but the union is accessed with the other type, the results are unreliable. For example, a union of float and int is declared. A float value is stored, but the program later accesses the value as an int. In such a situation, the value would depend on the internal storage of float values. The integer value would not be reliable.
具体值为多少其实是不定的,大多数返回为13.
一般用union来判断高低端的
int i=1; char *p=(char *)&i;
if(*p==1)
printf("1");
else
printf("2");
大小端存储问题,如果小端方式中(i占至少两个字节的长度)则i所分配的内存最小地址那个字节中就存着1,其他字节是0.大端的话则1在i的最高地址字节处存放,char是一个字节,所以强制将char型量p指向i则p指向的一定是i的最低地址,那么就可以判断p中的值是不是1来确定是不是小端。
请写一个C函数,若处理器是Big_endian的,则返回0;若是Little_endian的,则返回1
解答:
int checkCPU( )
union w
int a;
char b;
c;
c.a = 1;
return(c.b ==1);
剖析:
嵌入式系统开发者应该对Little-endian和Big-endian模式非常了解。采用Little-endian模式的CPU对操作数的存放方式是从低字节到高字节,而Big-endian模式对操作数的存放方式是从高字节到低字节。例如,16bit宽的数0x1234在Little-endian模式CPU内存中的存放方式(假设从地址0x4000开始存放)为:
内存地址0x40000x4001存放内容0x340x12
而在Big-endian模式CPU内存中的存放方式则为:
内存地址0x40000x4001存放内容0x120x34
32bit宽的数0x12345678在Little-endian模式CPU内存中的存放方式(假设从地址0x4000开始存放)为:
内存地址0x40000x40010x40020x4003存放内容0x780x560x340x12
而在Big-endian模式CPU内存中的存放方式则为:
内存地址0x40000x40010x40020x4003存放内容0x120x340x560x78
联合体union的存放顺序是所有成员都从低地址开始存放,面试者的解答利用该特性,轻松地获得了CPU对内存采用Little-endian还是Big-endian模式读写。如果谁能当场给出这个解答,那简直就是一个天才的程序员。
补充:
所谓的大端模式,是指数据的低位(就是权值较小的后面那几位)保存在内存的高地址中,而数据的高位,保存在内存的低地址中,这样的存储模式有点儿类似于把数据当作字符串顺序处理:地址由小向大增加,而数据从高位往低位放; 所谓的小端模式,是指数据的低位保存在内存的低地址中,而数 据的高位保存在内存的高地址中,这种存储模式将地址的高低和数据位权有效地结合起来,高地址部分权值高,低地址部分权值低,和我们的逻辑方法一致。
为什么会有大小端模式之分呢?这是因为在计算机系统中,我们是以字节为单位的,每个地址单元都对应着一个字节,一个字节为 8bit。但是在C语言中除了8bit的char之外,还有16bit的short型,32bit的long型(要看具体的编译器),另外,对于位数大于 8位的处理器,例如16位或者32位的处理器,由于寄存器宽度大于一个字节,那么必然存在着一个如果将多个字节安排的问题。因此就导致了大端存储模式和小 端存储模式。例如一个16bit的short型x,在内存中的地址为0x0010,x的值为0x1122,那么0x11为高字节,0x22为低字节。对于 大端模式,就将0x11放在低地址中,即0x0010中,0x22放在高地址中,即0x0011中。小端模式,刚好相反。我们常用的X86结构是小端模 式,而KEIL C51则为大端模式。很多的ARM,DSP都为小端模式。有些ARM处理器还可以由硬件来选择是大端模式还是小端模式。
下面这段代码可以用来测试一下你的编译器是大端模式还是小端模式:short int x;
char x0,x1;
x=0x1122;
x0=((char*)&x)[0]; //低地址单元
x1=((char*)&x)[1]; //高地址单元
若x0=0x11,则是大端; 若x0=0x22,则是小端......
上面的程序还可以看出,数据寻址时,用的是低位字节的地址。
参考资料:http://blog.csdn.net/duola_rain/article/details/7821770
参考技术B 因为你这个是联合体,它在内存中每一个瞬间只能存放一个成员,共同体所占的内存的长度等于最长的成员的长度.这里的共同体占两个字节(一个字符占一个字节)a.ch[0]=13;
a.ch[1]=0;
这两句在内存中是这样存放的0000 0000 0000 1101(计算机内是二进制);输出a.i其实就是这串数字的值.
再举个列子,a.ch[0]=2;a.ch[1]=1;这时输出a.i=258;原因是这样的,0000 0001 0000 0010转化成十进制就是258了本回答被提问者采纳 参考技术C 一个int一般有4个字节
ch只有2个字节
所以低16位能确定
高16位无法确定
低16位考虑高高低低就是ch[1]放前面,一个char是8位,就是00000000 00001101
打印出来低16位就是13 参考技术D 这要看机器是大端还是小端的,x86架构都是小端的,所以结果是13。
C语言编程基础
共用体(Union)
共用体的定义格式为:
union 共用体名
{
成员列表
};
结构体和共用体的区别在于:
结构体的各个成员会占用不同的内存,互相之间没有影响;
而共用体的所有成员占用同一段内存,修改一个成员会影响其余所有成员。
结构体占用的内存大于等于所有成员占用的内存的总和(成员之间可能会存在缝隙),共用体占用的内存等于最长的成员占用的内存。共用体使用了内存覆盖技术,同一时刻只能保存一个成员的值,如果对新的成员赋值,就会把原来成员的值覆盖掉。
例子:
union data {
int n;
char ch;
double m;
};
int main()
{
union data a;
printf("union 大小为:%d\\n\\n",sizeof(a));
a.n = 888;
printf(" %-10u, %-10c, %-10f\\n", a.n, a.ch, a.m);
a.ch = %;
printf(" %-10u, %-10c, %-10f\\n", a.n, a.ch, a.m);
a.m = 6.66;
printf(" %-10u, %-11c, %-10f\\n", a.n, a.ch, a.m);
printf("\\n n 指向%p \\n ch指向%p \\n m 指向%p \\n", &(a.n), &(a.ch), &(a.m));
}输出为:

我们可以观察到:
1)共用体的长度与共同体中最大数据类型(double)长度一致(都是8)
2)共同体中各个成员所在的地址相同
下面让我们来看内存的变化,为何会出现上面的结果
1)首先定义一个data型共同体a

2)将int型改为888

888转化为十六进制是0x0378,占用4个字节
0x78转化为十进制是120,查看ascii码,120位是小写x
0x0378转化为二进制是:
1100 1100 1100 1100 1100 1100 1100 1100 0000 0000 0000 0000 0000 0011 0111 1000
c c c c c c c c 0 0 0 0 0 3 7 8
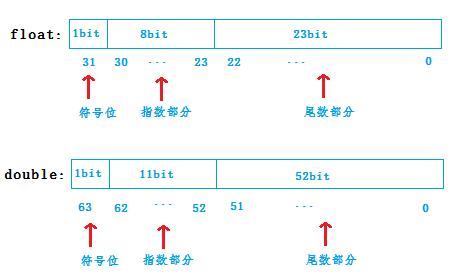
符号位位1,表明是负数
指数部分是100 1100 110 转化为十进制是614
尾数部分是0 1100 1100 1100 1100 1100 0000 0000 0000 0000 0000 0011 0111 1000
整数部分为011,转化为10进制为3,
小数部分为0.00 1100 1100 1100 1100 0000 0000 0000 0000 0000 0011 0111 1000
int xiaoshu[] = { 0,0,0 ,1,1,0,0, 1,1,0,0, 1,1,0,0, 1,1,0,0 ,0,0,0,0, 0,0,0,0, 0,0,0,0 ,0,0,0,0, 0,0,0,0, 0,0,1,1, 0,1,1,1 ,1,0,0,0};
int len = sizeof(xiaoshu) / sizeof(int);
double sum = 0;
for (int i = 0; i < len; i++)
{
sum += xiaoshu[i] * pow(0.5, i);
}
printf("\\n小数部分为%.20f\\n\\n", sum);
尾数部分为3.1999969482429762024366937112063169479370
3.2*2^614超出了计算范围
3)将char型改为%

%对应的ascii码为37号,转化为二进制就是0x25
0x0325转化为十进制是805
4)最后将double型改为6.66

十六进制为401A A3D7 0A3D 70A4,转化为二进制为:
100 0000 0001 1010 1010 0011 1101 0111 0000 1010 0011 1101 0111 0000 1010 0100
符号位位0,表明为正数
指数为0,表明不移动,正数部分为110,转化为十进制是6,
小数部分为0.10 1010 0011 1101 0111 0000 1010 0011 1101 0111 0000 1010 0100
转化为十进制
int xiaoshu[] = { 0,1,0, 1,0,1,0, 0,0,1,1, 1,1,0,1, 0,1,1,1 ,0,0,0,0, 1,0,1,0, 0,0,1,1, 1,1,0,1, 0,1,1,1, 0,0,0,0, 1,0,1,0, 0,1,0,0 };
int len = sizeof(xiaoshu) / sizeof(int);
double sum = 0;
for (int i = 0; i < len; i++)
{
sum += xiaoshu[i] * pow(0.5, i);
}
printf("\\n\\n小数部分为%20f\\n\\n", sum);结果为:

小数部分为0.66。
表示的double为6.66
以上是关于C语言共用体的主要内容,如果未能解决你的问题,请参考以下文章