Linux上使用Python进行数据处理
Posted 除了心跳都忘掉
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Linux上使用Python进行数据处理相关的知识,希望对你有一定的参考价值。
文章目录
1 引言
在Linux上使用python的时候,刚开始会遇到一些问题,例如 如何在python中实现一些shell操作(如切换工作目录、遍历文件名),因此本文的目的在于帮助新手快速上手Linux操作,和用python脚本在Linux上实现批量的文件组织操作(复制/移动、重命名、遍历等)
本文会先介绍Linux的基本操作,然后介绍Python在Linux上常用的库函数及其用法,最后给出一个实例,分析针对一种数据处理问题如何理清编程思路
另外,笔者的Linux使用经历大部分为服务器,没有管理员权限,因此,本文的Linux代指Linux服务器
2 Linux 基本操作
2.1 Linux 的文件结构
首先介绍一下Linux的文件结构
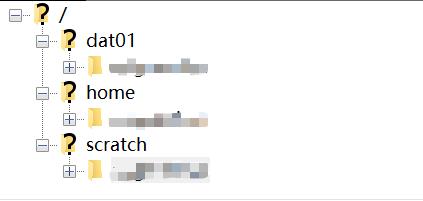
Linux采用多级树形结构,如上图所示,用户可以进入任何已授权的目录,访问那里的文件。在服务器上,我们的用户主目录为/home/$username,该目录下有通向dat01和scratch分区空间的软连接,即快捷方式
2.2 Linux 的文件类型
Linux系统中有三种基本的文件类型:普通文件、目录文件和设备文件
(1)普通文件
普通文件分为文本文件和二进制文件
(2)目录文件
在Linux系统中,目录以文件的形式存在,目录文件存储了一组相关文件的位置、大小等与文件有关的信息。目录文件简称为目录
(3)设备文件
Linux系统把每一个I/O设备都看成一个文件,与普通文件一样处理,这样可以使文件与设备的操作尽可能统一
一般来说,文件代指普通文件,目录代指目录文件
2.3 shell 及其常用命令
shell是命令行形式的用户界面,它提供了用户与内核进行交互的一种接口,它也是一个命令解释器,可以用来启动、挂起、停止程序,还允许用户编写由shell命令组成的程序。
下面给出shell常用命令及其含义,命令具体参数见 Linux命令大全
- cat
把文件(串接后)显示在标准输出上。用得少,一般都是用vi来查看文件内容 - cp
将一个文件拷贝成另一个文件(可以更名),或一个或多个文件拷贝至另一个目录 - rm
删除命令 - mv
与cp一样,只不过拷贝换成移动 - mkdir
创建目录,一般带-p - cd
切换工作目录 - ls
列出文件或目录的信息 - tar
备份命令,常见用法:tar -czf test.tar.gz ./test (将test目录打包压缩);tar -xzf test.tar.gz (还原备份文件并解压缩) - zip 与 unzip
压缩与解压缩,相比tar更常用,常见用法:zip -q -r 001-003obs.zip 001 002 003 (将001、002、003三个目录压缩成001-003obs.zip,-r表示递归处理,-q表示不显示详细信息);unzip -q 0.zip -d ./2021 (将0.zip内容解压至2021目录下)
3 Python 在 Linux 上的常用语法
3.1 os 库和 sys 库
下表列出了os库和sys库中常会用到的函数,其具体用法会在后面的示例中予以展示
| 方法 | 意义 |
|---|---|
| os.listdir() | 列出目录下所有文件名(目录也是一种文件) |
| os.chdir() | 切换工作目录 |
| os.system() | 执行shell命令 |
| os.path.isdir() | 判断是否为目录文件 |
| os.path.isfile() | 判断是否为普通文件 |
| os.path.join() | 合并路径 |
| sys.argv | 获取命令行参数 |
对于上表中的几个函数,有几点需要注意,初学者容易犯错
- os.system()
执行操作系统的命令,将结果输出到屏幕,只返回命令执行状态(0:成功,非 0 : 失败)
Note:
1)os.system()的每一次操作都是开启一个子进程,操作完成后,返回父进程。所以无法改变父进程的环境变量(工作目录PWD就是环境变量之一),要切换父进程工作目录,可以使用os.chdir()。
2)要在不切换工作目录的情况下查看子目录或进行其它操作,可以使用复合语句或者多个语句:例如 os.system(‘cd hello && ls’) 或者 os.system(‘cd hello;ls’) - os.popen()
执行操作系统的命令,会将结果保存在内存当中,可以用 read() 方法读取出来,例如 os.popen(‘ls’).read() 会返回pwd下所有文件名
3.2 time 和 datetime 库
关于 datetime 库的详细用法,有一篇很好的博客:Python datetime模块详解、示例
下面给出的是显示标准时间的一行代码,主要用于输出调试信息,以查看该程序或者该语句是何时执行的
import time
# 显示当前时间
print(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()))
# 2020-10-11 00:19:12
4 数据处理实例
4.1 获取前N天的日期
在GNSS数据处理中,经常需要进行事后处理,需要下载N天前的数据,那么如何获得N天前的日期和年-年积日(day of year)呢?自己写一个库的话也可以,但其实不需要这么麻烦,我们使用 datetime 库就可以轻松搞定
下面的代码中,先使用 datetime 库获取了当前的日期,然后使用 datetime 库中的 timedelta() 函数获取了十九天前的日期,再将其转化为对应的年-年积日。而后将其作为参数传给了下载数据的脚本。
代码中有一个将年月日转换为年-年积日的自定义函数。
import os
import datetime
def ymd2ydoy(year, month, day):
doy=0
for i in range(1,month): # 计算前面完整月份的天数
if i==2: # 如果是二月,需要判断是否为闰年
if (year%4==0 and year%100!=0) or year%400==0:
doy+=29
else:
doy+=28
elif i in [1,3,5,7,8,10]:
doy+=31
else:
doy+=30
doy+=day # 加上当前月份的天数
return year, doy
tm_today=datetime.date.today()
os.chdir('/dat01/___/scripts/DownLoad')
# 下载十九天前的 clk sp3
tm_19=tm_today+datetime.timedelta(days=-19)
year_19,doy_19=ymd2ydoy(*tm_19.timetuple()[:3])
os.system('csh download_prod.csh %d %d 1'%(year_19,doy_19))
注意这里 os.chdir() 和 os.system() 的用法,前者的参数是(绝对/相对)路径的字符串,一般都使用绝对路径,避免出错;后者的参数是命令行命令的字符串,容易理解。
4.2 根据文件名组织文件目录
现在我们需要完成一件事:有这样一个目录,暂且称其为根目录,其内容如下所示
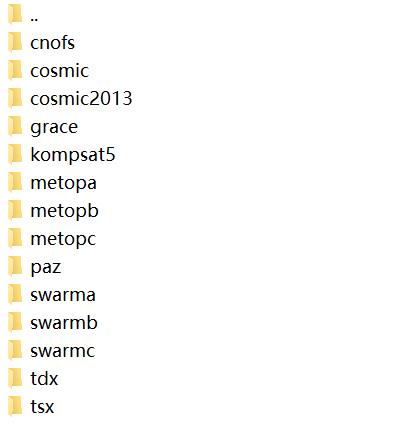
根目录下面的每一个子目录名称表示一种系列卫星(即一个卫星星座),每个子目录下面又有两个子目录,分别存储轨道文件(leoOrb)和观测文件(podObs),如下所示
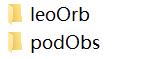
轨道文件的名称格式如下所示,其每一位的含义如下表所示

| 位数(从1开始) | 含义 |
|---|---|
| 1~3 | 卫星系列号名称 |
| 4 | 卫星编号 |
| 5~7 | 三位年积日 |
| 8~9 | 0. |
| 10~11 | 年份后两位 |
| 12~16 | o.sp3 |
观测文件的格式如下所示,其每一位的含义与轨道文件类似,只是少了末尾的.sp3

现在,我们要将根目录下 所有 卫星的 所有 轨道文件、观测文件根据 年—年积日 的方式重新组织(这里是复制,防止出错后原文件丢失),如下所示
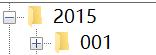
比如观测文件 gra10760.15o,我们就要将其放入 /…/2015/076 目录下
要做到这一步,只需要获取该文件的 5-7 位以获取其年积日,获取该文件的 10-11 位以获取其年份,然后再进行复制,就完成了单个文件的操作
现在,我们要对根目录下的所有卫星的所有文件都进行这样的操作,要完成这一步骤,有两个思路:
第一种是将所有卫星系列的文件夹名称和轨道、观测文件的文件夹名称都预先存起来,然后双重遍历,获取每一个需要移动的文件所在的目录
第二种是从根目录向下进行深度优先遍历DFS,递归遍历每一个目录,在这个过程中,只要检测到符合格式的文件,就复制它,直到再没有子目录为止
此处采用第二种方法,写起来比较方便,而且可扩展性也比较强,代码如下所示
import os
import sys
def dfs(cur_dir, des_root_dir, cons):
cur_dir+='/'
# 获取当前目录下的所有普通文件
files=[f for f in os.listdir(cur_dir) if os.path.isfile(cur_dir + f)]
for f in files:
if f.endswith('o') or f.endswith('.sp3'):
year = '20' + f[9:11]
doy = f[4:7]
# 如果不在输入要求的范围内则跳过
if cons and (cons[0]!=int(year) or not cons[1]<=int(doy)<cons[1]+cons[2]):
continue
des = des_root_dir + '/' + year + '/' + doy
os.system('mkdir -p %s'%des)
os.system('cp %s/%s %s'%(cur_dir, f, des))
# print('cp %s/%s %s'%(cur_dir, f, des)) # 实际操作前先打印以检查错误
# 获取当前目录下的目录文件
dirs = [d for d in os.listdir(cur_dir) if os.path.isdir(cur_dir + d)]
for d in dirs:
dfs(cur_dir + d, des_root_dir, cons)
if __name__=='__main__':
src_root_dir='/.../' # 前面所说的根目录
des_root_dir='/.../' # 复制过去的根目录,年份目录的上一级
argv=sys.argv # 获取命令行参数
if 4!=len(argv) and 2!=len(argv): # 判断参数个数的合法性
print('Usage:')
print('[1].py year doy num')
print('[2].py 0')
print('note:[2] will copy all files from ~/.../ to ~/.../')
exit(0)
cons=[] if 2==len(argv) else [int(a) for a in argv[1:4]]
dfs(src_root_dir, des_root_dir, cons)
该段代码写得比较早,因此没有用上 os.path.join() 函数,实际上在进行路径拼接时,还是使用 os.path.join() 函数更不易出错。
另外,该段代码给了两种输入模式,前面所述的思路主要是第二种模式,即全部重新组织;实际上第一种模式只是给定了一个时间范围,区别只是在DFS中多了一个判断语句,它们的思想是完全一样的。
以上是关于Linux上使用Python进行数据处理的主要内容,如果未能解决你的问题,请参考以下文章