JavaArrayListVectorStack和LinkedList的区别
Posted remo0x
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JavaArrayListVectorStack和LinkedList的区别相关的知识,希望对你有一定的参考价值。
继承关系
ArrayList继承自AbstractList
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.SerializableVector继承自AbstractList
public class Vector<E>
extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.SerializableStack继承自Vector
public
class Stack<E> extends Vector<E>LinkedList继承自AbstractSequentialList,而AbstractSequentialList继承自AbstractList
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable四者的继承关系如下
Object
|--AbstractCollection
|--AbstractList
|--ArrayList
|--Vector
|--Stack
|--AbstractSequentialList
|--LinkedList集合中的关系非常复杂,需要仔细理清其中的继承和实现关系,List的框架图如下(图片来自《Java 集合系列08之 List总结(LinkedList, ArrayList等使用场景和性能分析)》)
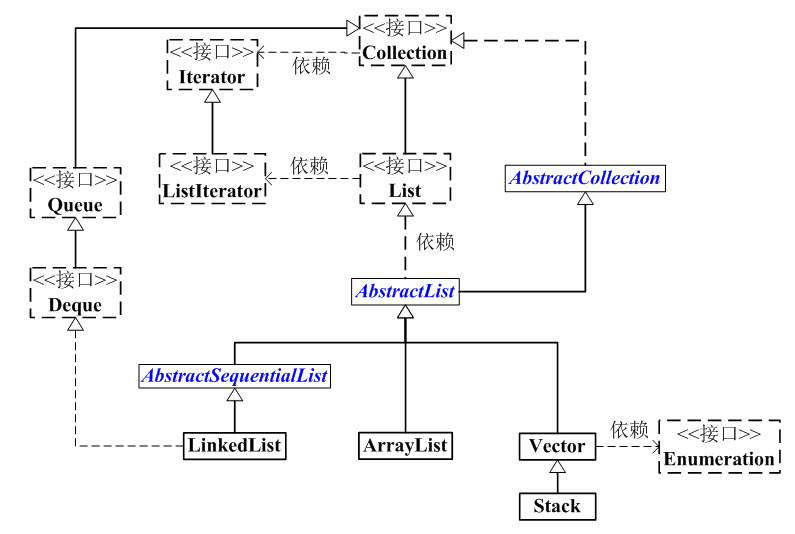
总的来说,它们的关系及用途如下
- ArrayList主要用于随机访问
- Vector相当于ArrayList的同步版
- Stack继承自Vector,用于实现后进先出
- LinkedList主要用于新增和删除操作
Collection和List
Collection是集合最上层的接口,List、Set和Queue接口都是继承自Collection,Collection接口继承自Iterator接口,Iterator主要有如下方法
| 方法 | 描述 |
|---|---|
| boolean hasNext() | 如果next()还能返回元素,则返回true |
| E next() | 返回下一个元素 |
| void remove() | 移除next()最近返回的一个元素 |
Collection主要描述了一个集合应该具有什么基本功能,Collection中声明的主要方法如下
| 方法 | 描述 |
|---|---|
| int size() | 返回集合中的元素数量 |
| boolean isEmpty() | 集合是否为空 |
| boolean contains(Object o) | 集合是否包含该对象 |
| Iterator<E> iterator() | 返回一个迭代器 |
| Object[] toArray() | 将集合转为对象数组 |
| <T> T[] toArray(T[] a) | 将集合转为给定类型的数组 |
| boolean add(E e) | 添加一个元素 |
| boolean remove(Object o) | 移除该元素 |
| void clear() | 清空集合 |
List继承自Collection,添加了一些列表应该具有的方法,相对于Collection添加的方法如下
| 方法 | 描述 |
|---|---|
| void sort(Comparator c) | 给列表排序 |
| E get(int index) | 用索引获取元素 |
| E set(int index, E element) | 设置索引处的元素 |
| void add(int index, E element) | 在索引处插入一个元素 |
| int indexOf(Object o) | 获取该对象的索引 |
| int lastIndexOf(Object o) | 获取最后一个出现的该对象的索引 |
| ListIterator<E> listIterator() | 返回一个列表迭代器 |
| List<E> subList(int fromIndex, int toIndex) | 返回一个范围的子列表 |
AbstractCollection和AbstractList
AbstractCollection实现了Collection接口,提供了一个基本的Collection实现,为了最小化实现该接口所需的工作
AbstractList继承了AbstractCollection,实现了List接口,提供了一个基本的List实现,也是为了最小化实现List接口时所需的工作。
AbstractList为了迭代而定义了两个私有内部类Itr和ListItr,Itr实现了Iterator接口,ListItr继承了Itr并实现了ListIterator接口。两个类的主要区别是ListItr可以从后向前迭代,并且需要指定迭代开始的位置。ListItr中相比于Itr添加的方法如下
| 方法 | 描述 |
|---|---|
| ListItr(int index) | 唯一构造器,指定迭代开始的位置 |
| boolean hasPrevious() | 前面是否有元素 |
| E previous() | 返回前一个元素 |
| int nextIndex() | 返回后一个元素的索引 |
| int previousIndex() | 返回前一个元素的索引 |
| void set(E e) | 设置最近返回的元素的值 |
| void add(E e) | 在当前位置插入一个元素 |
AbstractCollection并没有重写equals()和hashCode(),而AbstractList重写了这两个方法
public boolean equals(Object o)
// 如果指向同一个对象则true
if (o == this)
return true;
// 如果对象不是List的实例则false
if (!(o instanceof List))
return false;
// 比较两个List的元素是否相等
ListIterator<E> e1 = listIterator();
ListIterator<?> e2 = ((List<?>) o).listIterator();
while (e1.hasNext() && e2.hasNext())
E o1 = e1.next();
Object o2 = e2.next();
if (!(o1==null ? o2==null : o1.equals(o2)))
return false;
// 比较两个List的大小是否相等
return !(e1.hasNext() || e2.hasNext());
public int hashCode()
int hashCode = 1;
// (31*1+h1)*31+h2)=31^2+31*h1+h2
// 即表达式:31^size+31^(size-1)*h1+31(size-2)*h2+...+hn
for (E e : this)
hashCode = 31*hashCode + (e==null ? 0 : e.hashCode());
return hashCode;
equals()方法用于比较两个List是否相等,不过我觉得是不是先比较两个List的长度是否相等比较好。hashCode()则利用列表中的所有元素生成hash值,这个表达式和String的hashCode()计算hash的表达式s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1]很相似
AbstractList文件中还提供了一个包访问权限的SubList,SubList继承自AbstractList,主要是用于返回List的子列表,这个子列表仅仅是一个原List的视图。SubList中提供了列表中的部分方法,而对SubList的所有操作都是在原List上实现的,所以对元素的增删改都会影响到原List(这个类总感觉怪怪的)。对于实现了RandomAccess接口的列表,返回的是一个RandomAccessSubList,该类继承自SubList,并实现了RandomAccess接口,RandomAccess是一个标记接口,表明实现了该接口的类具有快速随机访问的性能
ArrayList、Vector和Stack
ArrayList的底层实现是使用对象数组存储元素,如果使用默认构造函数则会将该数组赋值为一个代表空的数组EMPTY_ELEMENTDATA,另外需要使用一个size记录该数组中实际存储的元素个数,而默认大小DEFAULT_CAPACITY是仅在扩展数组时使用的数组大小的最小值
private static final int DEFAULT_CAPACITY = 10;
private static final Object[] EMPTY_ELEMENTDATA = ;
transient Object[] elementData;
private int size;Vector的底层也是使用的对象数组存储元素,使用了一个elementCount记录实际存储的元素个数,还有Vector扩展数组时使用的一个增量capacityIncrement,如果使用默认构造器则数组的初始大小为10
protected Object[] elementData;
protected int elementCount;
protected int capacityIncrement;ArrayList扩展数组容量时是至少增加现有容量的一半
int newCapacity = oldCapacity + (oldCapacity >> 1);Vector扩展数组时是使用了一个容量增量,如果该增量不大于0,则每次扩展数组时就将其大小加倍
int newCapacity = oldCapacity + ((capacityIncrement > 0) ?
capacityIncrement : oldCapacity);Vector除了将方法用synchronized修饰,还有一个不同之处在于可以用elements()返回Enumeration对象
public Enumeration<E> elements()
return new Enumeration<E>()
int count = 0;
public boolean hasMoreElements()
return count < elementCount;
public E nextElement()
synchronized (Vector.this)
if (count < elementCount)
return elementData(count++);
throw new NoSuchElementException("Vector Enumeration");
;
Stack继承自Vector,添加了五个方法实现后进先出栈,Stack也是线程安全的
| 方法 | 描述 |
|---|---|
| public E push(E item) | 将元素入栈 |
| public synchronized E pop() | 将元素出栈 |
| public synchronized E peek() | 查看栈顶元素 |
| public boolean empty() | 栈是否为空 |
| public synchronized int search(Object o) | 查找元素并返回其到栈顶的偏移量(1-based) |
LinkedList
LinkedList继承自AbstractSequentialList,而AbstractSequentialList继承自AbstractList,提供了一些序列化访问式列表的默认实现
LinkedList底层实现是使用了一个双向链表,分别用first和last记录表头和表尾,并使用了size记录元素个数
transient int size = 0;
transient Node<E> first;
transient Node<E> last;Node的定义非常简单,存储了元素及其前后指针
private static class Node<E>
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next)
this.item = element;
this.next = next;
this.prev = prev;
LinkedList中提供了许多方法用于操作元素,访问元素时需要遍历链表,而增删元素时只需要更改指针。相比于ArrayList,增删元素时性能更好,因为ArrayList需要移动元素
LinkedList中提供了一些后进先出栈的方法,可以将其作为栈使用,比如push()、pop()
迭代器方面,除了提供了正向迭代的ListItr,还提供了一个逆向访问的DescendingIterator,分别对应方法listIterator(int index)和descendingIterator()
参考文章
以上是关于JavaArrayListVectorStack和LinkedList的区别的主要内容,如果未能解决你的问题,请参考以下文章