Spark调研笔记第4篇 - PySpark Internals
Posted slvher
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark调研笔记第4篇 - PySpark Internals相关的知识,希望对你有一定的参考价值。
其实,有两个名为PySpark的概念,一个是指Spark客户端内置的pyspark脚本,而另一个是指Spark Python API中的名为pyspark的package。本文只对第1个pyspark概念做介绍。
1. Spark客户端内置的pyspark"命令"
Spark客户端支持交互模式以方便应用调试,通过调用pyspark可以进入交互环境:
cd /path/to/spark/ && ./bin/pyspark
用编辑器查看可知,pyspark其实是个shell脚本,部分内容摘出如下:
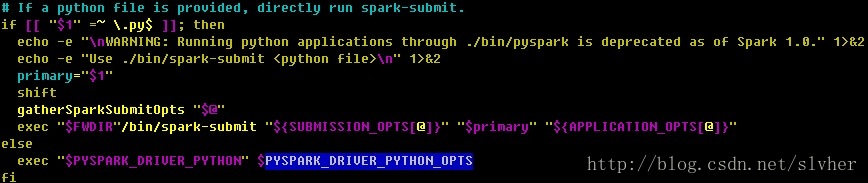
从上面的脚本片段可知,若调用./bin/pyspark时传入要执行的python脚本路径,则pyspark是直接调用spark-submit脚本向spark集群提交任务的;若调用./bin/pyspark时未带任何参数,则会通过调起Python解释器($PYSPARK_DRIVER_PYTHON)进入交互模式,其中调起Python解释器前,pyspark脚本会通过export PYTHONPATH将与Spark Python API相关的库加入Python解释器的加载路径,以便交互环境中能正确import与Spark相关的库。
通过上面的介绍,我们已经清楚Spark客户端内置pyspark脚本的用处,那么,当通过./bin/pyspark进入交互模式后,本地的Python driver进程(即Python解释器进程)和Spark集群worker节点的executor(s)进程是怎么交互的呢?下面来回答这个问题。
事实上,当我们在本地机器通过./bin/pyspark进入交互模式并向Spark集群提交任务时,本地会在执行pyspark脚本时先启动一个被称为driver program的Python进程并创建SparkContext对象,而后者会通过Py4J启动一个JVM进程并创建JavaSparkContext对象,该JVM进程负责与集群的worker节点传输代码或数据。
从Spark Wiki关于PySpark Internals的说明可知,PySpark建立在Spark Java API之上,数据按Python的语法行为被处理,执行结果由JVM负责cache或shuffle,数据流交互结构如下图所示:
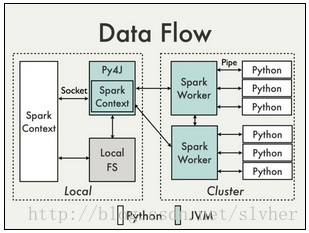
由上图可知,用户提交的Python脚本中实现的RDD transformations操作会在本地转换为Java的PythonRDD对象,后者由本地的JVM发往Spark集群节点。在远程的worker节点上,PythonRDD对象所在的JVM进程会调起Python子进程并通过pipe进行进程间通信(如向Python子进程发送用户提交的Python脚本或待处理的数据)。
以上就是当我们调用./bin/pyspark时,spark客户端和集群节点之间的内部结构。
理解这些内容有助于我们从总体上加深对Spark这个分布式计算平台的认识。例如,当调用rdd.collect()时,这个action操作会把数据从集群节点拉到本地driver进程。如果数据集比较大,则可能报出类似于"spark java.lang.OutOfMemoryError: Java heap space"的错误。而由本文的介绍可知,提交任务时,本地driver进程启动了一个JVM进程,默认的JVM是有最大内存限制的,如果数据集的大小超过driver默认的最大内存限制,就会报出OOM的错误。解决办法是在spark-defaults.conf中增加配置项spark.driver.memory,将其值设置到较大值。
1. Spark Wiki Homepage: PySpark Internals
========================== EOF ======================
以上是关于Spark调研笔记第4篇 - PySpark Internals的主要内容,如果未能解决你的问题,请参考以下文章