Python数据分析之Pandas
Posted 程序员唐丁
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python数据分析之Pandas相关的知识,希望对你有一定的参考价值。
上一节介绍的Pandas的简单应用,包括pandas中Series和DataFrame类型数据的创建,以及对DataFrame的转置和排序。今天讲的是pandas的数据选择、设置值和处理丢失数据三类方法。
一、数据选择
#导库
import pandas as pd
import numpy as np
1、选择数据-简单选择-按列索引
df_DataFrame = pd.DataFrame(np.random.randn(3,4),index=['a','b','c'],columns=['A','B','C','D'])
df_DataFrame.sort_values(by='B')
df_DataFrame['A']
a -1.025688
b -0.264478
c -1.105921
Name: A, dtype: float64
2、选择数据-loc函数-按行索引(单行)
#选择数据-loc函数-按行索引(单行)
df_DataFrame.loc['a']
A -1.025688
B 0.880389
C -0.955020
D -0.432437
Name: a, dtype: float64
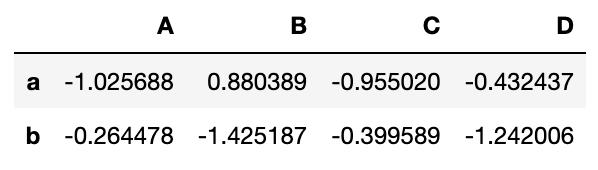
3、选择数据-loc函数-按行索引(多行)
#选择数据-loc函数-按行索引(多行)
df_DataFrame.loc[['a','b']]
4、选择数据-iloc函数-按位置索引(多行)
#选择数据-iloc函数-按位置索引(多行)
df_DataFrame.iloc[0,0]#0行0列
-1.0256883036288895
5、筛选B列大于0的行
#筛选B列大于0的行df_DataFrame[df_DataFrame.B > 0]

二、设置值
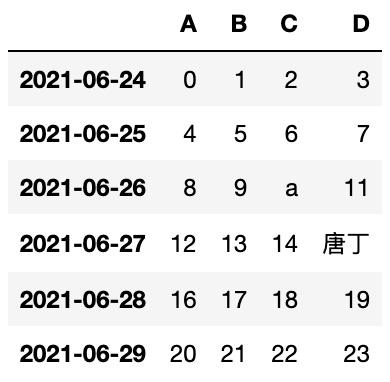
1、定义DataFrame数据
import pandas as pdimport numpy as npdates = pd.date_range('20210624',periods=6)df = pd.DataFrame(np.arange(24).reshape(6,4),index=dates,columns=["A","B","C","D"])print(df)
A B C D2021-06-24 0 1 2 32021-06-25 4 5 6 72021-06-26 8 9 10 112021-06-27 12 13 14 152021-06-28 16 17 18 192021-06-29 20 21 22 23
2、设置值-通过行列位置
#设置值-通过行列位置df.iloc[2,2] = 'a'

3、设置值-通过索引定位
#设置值-通过索引定位df.loc['2021-06-27','D'] = '唐丁'
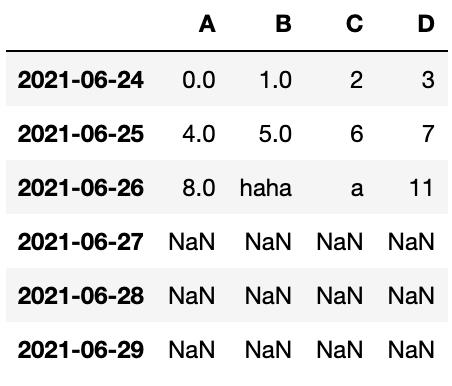
4、设置值-改变A列大于10的行数据
#设置值-改变A列大于10的行数据df[df.A > 10] = np.nan

5、设置值-改变A列大于7的某一列数据
#设置值-改变A列大于7的某一列数据
df.B[df.A > 7] = 'haha'
6、设置值-增加一列E,值都为0
#设置值-增加一列E,值都为0dates = pd.date_range('20210624',periods=6)df = pd.DataFrame(np.arange(24).reshape(6,4),index=dates,columns=["A","B","C","D"])df['E'] = 0

三、处理丢失数据
1、定义待处理数据
#处理丢失数据df.loc['2021-06-26','A'] = np.nanprint(df)
A B C D E2021-06-24 0.0 1 2 3 02021-06-25 4.0 5 6 7 02021-06-26 NaN 9 10 11 02021-06-27 12.0 13 14 15 02021-06-28 16.0 17 18 19 02021-06-29 20.0 21 22 23 0
2、dropna函数
#dropna函数是返回删除后的DataFrame,不改变原DataFrame#axis为0删除行,1删除列#how为any是只要有0就删除,all是都为0才删除a = df.dropna(axis=0,how='any')print(a)
A B C D E2021-06-24 0.0 1 2 3 02021-06-25 4.0 5 6 7 02021-06-27 12.0 13 14 15 02021-06-28 16.0 17 18 19 02021-06-29 20.0 21 22 23 0
3、将丢失数据填充为“唐丁”
#将丢失数据填充为“唐丁”a = df.fillna(value='唐丁')print(a)
A B C D E2021-06-24 0.0 1 2 3 02021-06-25 4.0 5 6 7 02021-06-26 唐丁 9 10 11 02021-06-27 12.0 13 14 15 02021-06-28 16.0 17 18 19 02021-06-29 20.0 21 22 23 0
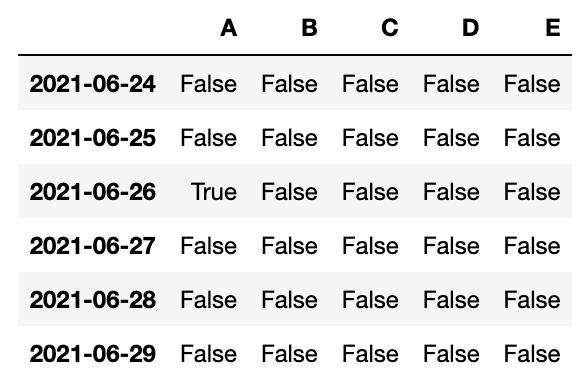
4、判断DataFrame中是否含有缺失值,缺失值部分为True
#判断DataFrame中是否含有缺失值,缺失值部分为Truedf.loc['2021-06-26','A'] = np.nandf.isnull()
今天就介绍到这里,下次见~~

以上是关于Python数据分析之Pandas的主要内容,如果未能解决你的问题,请参考以下文章