这个疯子整理的十万字Java面试题汇总,终于拿下40W offer!(JDK源码+微服务合集+并发编程+性能优化合集+分布式中间件合集)
Posted 训练营资料福利官
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了这个疯子整理的十万字Java面试题汇总,终于拿下40W offer!(JDK源码+微服务合集+并发编程+性能优化合集+分布式中间件合集)相关的知识,希望对你有一定的参考价值。
爆肝一周,不眠不休!就为 点赞+好评+收藏 三连
收藏党可以通过百度网盘下载全部文档:
链接:https://pan.baidu.com/s/1nwlBO2tYXDDl7OjGhs4e4Q
提取码:1111
目录
word文档下载地址:链接:https://pan.baidu.com/s/1BaUi8KUjvjJ6RPN7CmMSyw
提取码:1111爆肝一周,不眠不休!就为 点赞+好评+收藏 三连
HashMap篇
1、并发修改异常
原因
迭代器中修改数 和hashmap中的 modCount 不相等
目的
暴露异常,快速失败
出现场景
- 多线程,一个迭代器迭代,一个线程增删操作
- 迭代器迭代的时候,使用hashmap本身的remove方法
解决方案
- 多个线程,操作使用ConcurrentHashMap,或者hashTable
- 在迭代的时候,使用迭代器中的remove方法。保存修改数和modCount一致
2、HashMap底层数据结构
1.7:数组+链表
1.8:数组+链表+红黑树(其中红黑树,也是用了双向链表,主要是为了链表操作方便,在扩容,链表转红黑树,红黑树转链表的过程中都要操作链表。)
3、hash 数组的最大值
1 << 30
- 首先必须是2的倍数,方便计算对应的table下标,
- 为什么不是32位 高1位 为正负标识,不能占有。
- 为什么不是31位 他达不到2^31,因为Integer的最大值就是2^31-1,如果threadhold超过2^30,会把Integer的最大值赋给他。
4、hash 寻址算法
hash值 和 数组长度 -1 做与运算。
- 数组长度为2的幂次方
- 长度-1,那么低位全部为1,做运算那么下标 肯定落到数组长度范围内。
5、1.7 HashMap的put方法的实现过程
- 判断当前的数组是否为空,如果为空则初始化该数组
- 判断key是否为null
- 遍历tab[0],如果有key为null的entry,重新设置新值,返回oldValue。
- 没有找到则将key,value封装成entry,存到数组下标0的位置。返回null。
- 根据key做hash运算得到hashcode
- 根据hashCode和数组长度-1,逻辑与运算,算出hashcode基于当前数组对应的数组下标i
- 遍历tab[i]位置的链表,当找到节点的key和传入的key相同时,则重新设置为新值,返回oldValue。
- 没有找到这,说明是新的key,modCount++
- 再将hashcode,key,value,i 封装成Entry对象,通过头插法插入到改tab[i]位置
- 如果当前size是否大于等于阈值,并且当前桶位不为null 则进行扩容。
6、HashMap1.7 扩容机制
扩容条件:
当前容量大于等于阈值 并且 当前桶位不为null
扩容流程
- rehash,当容量大于等于我们设置的hash阈值,生成一个新的hash种子
- new 一个2倍长度的新数组
- 循环每个桶上的链表
- 重新计算hashcode,然后再和新的数组长度-1做与运算,得到新数组下标
- 判断新数组当tab[i]位置是否有元素
- 没有元素则直接封装成Entry对象赋值到当前tab[i]位置
- 有元素,则通过头插法插入到链表中,再赋值到tab[i]位置
8、HashMap1.7 扩容产生循环链表
场景
- 两个(多)线程同时转移同一个桶对应的链表
- 线程1依次将链表倒序方式转移到新数组中,
- 线程2此时转移比如当前指针指向 1节点,下个指针指向2节点。 而链表中2的next节点指向的是1节点。
- 当插入的时候会1节点会指向2节点,2节点指向1节点,形成环形链表。
影响
- put时候,会造成死循环。(需要循环判断链表中是否有相同的key)
- get时候,会造成死循环。
9、1.8 hash运算的实现方式
将hashcode 高16 和 低16位 异或,算出hash值。
然后再和 数组的长度 -1 比较。
要 高16和低16异或?
目的是当数组的的长度为 2的 小于等于 16次方,也是就是2进制 小于等于 16位,。两个key的hashcode运算出的低16位一样,而高16位不一样,如果高16低16位不做运算,那么他们做与运算等到的是通过样的数组下标。对每个hash值,在他的低16位中,让高低16位进行了异或,让他的低16位同时保持了高低16位的特征,尽量避免一些hash值后续出现冲突,大家可能会进入数组的同一个位置, key 更加散列。
10、1.8 HashMap的put方法的实现过程
- 根据key生成hash 值
- 判断当前hashMap对象的数组是否为空,如果为空则初始化该数组
- 根据逻辑与运算,算出hashcode基于当前数组对应的数组下标i
- 判断数组的第i个位置的元素(tab[i])是否为空
- 如果为空,则将key,value封装成Node对象赋值给tab[i]
- 如果不为空
- 如果put方法传入进来的key等于tab[i].key,那么证明存在相同的key
- 如果不等于tab[i].key,则:
- 如果tab[i]的类型是TreeNode,则表示数组的第i位置上是一颗红黑树,那么将key和value插入到红黑树中,并且在插入之前会判断在红黑树中是否存在相同的key
- 如果tab[i]的类型不是TreeNode,则表示数组的第i位子上是一个链表,那么遍历循环找是否存在相同的key,并且在遍历的过程中会对链表中的节点数进行计数,当遍历到最后一个节点时,会将key,value封装成Node插入到链表的尾部,同时判断在插入新节点之前的链表节点个数是不是大于等于8,并且table长度大于等64,如果是,则将链表改为红黑树
- 如果上述步骤中发现存在相同的key,则根据onlyIfAbsent标记来判断是否需要更新value值,然后返回oldValue
- modCount++
- hashMap的元素个数size加1
- 如果size大于扩容的阈值,则进行扩容
11、1.8 HashMap 扩容机制
扩容条件:
- 当前容量大于等于阈值
- 或 在树化之前,当前数组的长度小于64,链表长度大于等于8 也会发生扩容。
扩容流程:
- new 2倍数组长度的,新数组
- 节点对应的hashcode和新数组长度做与运算
- 结果为0,为低位链表,不为0为高位链表
- 低位插入新数组老下标位置(i),高位插入新数组的老数组长度+老下标位置。(oldLength+i)
- 判断是否进行树化。
12、1.8 HashMap 树化过程
树化条件:
链表的长度大于等于8 且 数组的长度大于等于64
树化实现:
- 现将单向链表转变为双向链表
- 再将双向链表,将头结点作为root节点,然后依次将next节点插入到根节点,转变红黑树。
- 再插入时候key比较
- 如果key实现了comparable接口,通过实现方式比较
- 否则比较key的hashCode
- 否则比较key的class.getName
- 否则比较key的System.identityHashCode比较
- 最后树化后,取出root节点(TreeNode),放到entry位置
13、1.8 HashMap 的get实现过程
- 根据key生成hashcode
- 如果数组为空,则直接返回空
- 如果数组不为空,则利用hashcode和数组长度-1通过逻辑与操作算出key所对应的数组下标i
- 如果数组的第i个位置上没有元素,则直接返回空
- 如果数组的第i个位置的元素的key等于get方法锁传进来的key,则返回该元素,并获取该元素的value。
- 如果不等于则判断该元素还有没有下个元素,如果没有返回空
- 如果有则判断钙元素的类型是链表节点还是红黑树节点
- 如果是链表则遍历链表
- 如果是红黑树则遍历红黑树
- 找到即返回元素,没找到则返回空
14、1.8 HashMap 的Remove实现过程
- 找到对应的位置(和get方式类似)
- 链表节点直接删除
- 红黑树节点
- 先删除链表的对应的节点,实现方式将上个节点指向下下个节点
- 然后再维护红黑树上的节点,可能会发生退化成链表
- modCount--
- size--
15、1.8 HashMap 为什么使用红黑树,不使用AVL树,二分查找树,链表
- 因为AVL树插入节点或者删除节点,整体的性能是不如红黑树的。AVL每个左右节点的高度是不能大于1的。所以维持这种结构比较消耗性能。
- 二分查找树,他的左右节点不平衡,一开始就固定了root,那么极端的情况下会成为链表结构。
- 链表长度越长,那么他的插入和查询效率都很低。
- 而红黑树他的整体查找,增删节点的效率都是比较高的。
16、1.8 HashMap 什么时候将链表转化成红黑树
- 当发现链表的元素个数大于8
- 并且当前的数组长度大于等于64的时候。
因为当数组比较小的时候,我们可以通过扩容的方式,将链表的长度变短。这样就用树化。
17、1.7 和 1.8 HashMap 不同点
- 结构:1.8使用了红黑树
- 插入法:1.7使用了头插法(多线程情况会出现循环链表,导致CPU飙升),1.8是用来尾插法(1.8中反正要去计算链表当前节点的个数,需要遍历链表,所以直接使用了尾插法。)
- hash算法复杂度:1.7 的hash算法比1.8钟的更复杂,hash算法越复杂,生成hashcode则更散列,那么hashmap中的元素则更散列,更散列则hashmap的查询性能更好,jdk7中没有红黑树,所以只能优化hash算法使元素更散列。1.8中重甲了红黑树,查询性能得到了保障,所以可以简化一下hash算法,毕竟hash算法越复杂越消耗CPU。
- 扩容的过程中:1.7可能会重新对key进行哈希(重新hash跟哈希种子有关系。),而1.8中没有这部分逻辑
- 扩容的条件不一样:1.7除了判断是否大于等于阈值,同时还判断了tab[i]是否为空,不为空才会进行扩容。1.8则没有这部分逻辑。
- 扩容的转移逻辑不一样:jdk7是每次转移一个元素,jdk8是先算出当前位置,高低位链表,再一次性转移过去
- jdk8 多了一个api :putIfAbsent(key,value)。
ConcurrentHashMap篇
1、JDK7 ConcurrentHashMap是怎么保证并发安全的?
主要利用了Unsafe操作+ReentrantLock+分段思想。
主要使用了Unsafe操作中的:
- compareAndSwapObject:通过cas的方式修改对象的属性
- putOrderedObeject:并发安全的给数组的某个位置赋值
- getObjectVolatile:并发安全的获取数组某个位置的元素
分段思想:
为了提高ConcurrentHashMap的并发量,分段数越高则支持的最大并发量越高,程序员可以通过concurrencyLevel参数来指定并发量。ConcurrentHashMap的内部类Segment就是用来表示某一个段的。
ReentrantLock:
每个Segement就是一个小型的 HashMap,当调用ConcurrentHashMap的put方法时,最终会调用到Segment的put方法,而Segment类继承了ReentrantLock,所以Segment自带可重入锁,当调用到Segment的put方法时,会先利用可重入锁加锁,加锁成功后再将待插入的key,value插入到小型HashMap中,插入完成后解锁。
2、JDK7 ConcurrentHashMap的底层原理
ConcurrentHashMap底层是由两层嵌套数组来实现的
- ConcurrentHashMap对象中有一个属性segments,类型为segment[];
- Segment对象中有一个属性table,类型为hashEntry[];
当调用ConcurrentHashMap的put方法时,先根据key计算出对应的Segment[]数组下标j,确定好当前key,value应该插入到哪个segment对象中,如果segments[j] 为空,则利用自旋锁的方式在j位置生成一个Segment对象。
然后调用Segment对象的put方法。
Segment对象的put方法会先加锁,然后也根据key计算出对应的HashEntry[]数组下标i,然后将key,value封装为Entry对象放入该位置,此过程和1,.7的put方法一样,然后解锁。
3、JDK7 ConcurrentHashMap的put实现过程
- 判断key不能为null
- 通过hashcode和segment数组长度-1,算出segment下标
- 判断segement是否为空,如果为空,从segment[0]原型中获取segment初始化的属性,用来初始化segment对象。
- tryLock,
- 获取锁,走类似put的插入逻辑。
- 没有获取锁,通过自旋的方式,找到head节点。
- 算出key对应的HashEntry数组下标i,走类似put的插入逻辑
4、JDK7 ConcurrentHashMap的扩容
特点:
局部扩容,只扩容segment中的hashEntry数组。并且在单线程下扩容,不会有并发问题。
条件:
当segment中hashEntry数组容量大于等于阈值就会发生扩容。
流程:
- new 2倍数组长度,得到新数组
- 循环hashEntry,处理每一个桶位链表。
- 循环链表,计算出每个节点新的数组的下标。这里会找到不间断的局部链表都在同一个下标位置。将从不变化的开始位置,到链表的尾部,一次性到转移到新的数组下标上。
- 再循环链表将其他的节点依次转移到新的数组中。
5、JDK7 ConcurrentHashMap的Size
- 第一层死循环
- 为每个segment加锁
- 第二层循环累加每个segment的modCount 和 size。
- 然后比较上次循环中的modCount总数和当前循环的modCount总和。
- 相等则跳出死循环,返回size总和
6、JDK8 ConcurrentHashMap是怎么保证并发安全的
主要利用Unsafe操作+synchronized关键字
主要使用了Unsafe操作中的:
- compareAndSwapObject:通过cas的方式修改对象的属性
- putOrderedObeject:并发安全的给数组的某个位置赋值
- getObjectVolatile:并发安全的获取数组某个位置的元素
Synchronized主要负责在需要操作某个位置时进行加锁(该位置不能为空),比如向某个位置的链表进行插入节点,向某个位置的红黑树插入节点
JDK中其实仍然有分段锁的思想,只不过JDK7中段数是可以控制的,而JDK8中是数组的每一个位置都有一把锁。
7、JDK8 ConcurrentHashMap的put实现过程
- 首先根据key计算对应的数组下标i,如果该位置没有元素,则通过自旋的方式去向该位置赋值
- 如果该位置有元素,则通过synchronized将tab[i] 元素加锁
- 加锁成功之后,再判断该元素的类型
- 如果是链表节点则进行添加节点到链表中
- 如果是红黑树则添加到红黑树中
- 添加成功后,走出了同步块,判断是否需要进行树化
- addCount,这个方法的意思是ConcurrentHashMap的元素个数加1,但是这个操作也是需要并发安全的,并且元素个数加1成功后,会继续判断是否需要进行扩容,如果需要,则会进行扩容,所以这个方法很重要。
- 同时一个线程在put时如果发现当前ConcurrentHashMap正则进行扩容则会去帮助扩容
8、JDK8 ConcurrentHashMap的树化
树化条件:
当发现链表的元素个数大于等于8 (hashmap还会判断数组大小大于等于64)
树化流程:
- 对当前tab[i]加锁,锁TreeBin对象
- 将链表转变成双向链表,目的是方便红黑树操作
- 将双向链表插入到TreeBin中
9、JDK8 ConcurrentHashMap的TreeBin
相当于红黑树的壳子,他本身就是红黑树,他有属性root表示根节点,无论树结构怎么变,treebin都不会变。
10、JDK8 ConcurrentHashMap的addCount
- 判断是否初始化了baseCount,没有通过自旋的方式去初始化
- 通过随机数,计算出对应的countCells下标i
- countCells数组不为空,判断当前conuntCells[i] 是否有值,有值自旋方式 conuntCells[i] 值+1.
- 为空,循环
- 先自旋方式 baseCount+1
- 不成功则初始化countCells数组
- 找到对应的countCells数组下标自旋方式 conuntCells[i] 值+1.
- 再不成功再自旋 baseCount+1
11、JDK8 ConcurrentHashMap的扩容
扩容条件
- 当一个线程自旋2次 为counterCells +1都失败
- 或 元素个数大于等于了阈值
特点
- 当线程在put的时候,发现有正在扩容标记的时候,他会加入协助扩容
- 扩容到一定程度就不会扩容了
扩容流程
- new 2倍数组长度,得到新数组
- 首先为线程设置固定长度的步长,分配起始位置和结束位置。每个线程都会扩容自己那部分
- 每个线程先锁住桶,依次将自己负责的桶转移到新数组中
- 节点对应的hashcode和新数组长度做与运算
- 结果为0,为低位链表,不为0为高位链表
- 低位插入新数组老下标位置(i),高位插入新数组的老数组长度+老下标位置。(oldLength+i)
- 这里会先找局部链表,该链表从头到尾节点的下标都一致,对应新数组的位置,直接转移过去。再将其他的节点转移过去。
- 判断是否进行树化。
12、JDK8 ConcurrentHashMap的size
累加countCells数组每个元素值,再加上baseCount。
13、JDK8 ConcurrentHashMap的remove
减size,不减容量
14、JDK7和JDK8 ConcurrentHashMap的区别
- jdk8中没有分段锁,而是使用了synchronize的来进行控制
- jdk8中的扩容性能更高,支持多线程同时扩容,实际上jdk7中也支持多线程扩容,因为jdk7中的扩容是针对每个Segment的,所以也可能多线程扩容,但是性能没有jdk8高,因为jdk8中对于任何一个线程都可以去帮助扩容
- jdk8的元素个数统计实现不一样,jdk8是 counterCell数组元素+baseCount。jdk7是通过循环 遍历每个segment对象加锁统计累加的modCount和累加的size,和上次得出modCount的结果比较。
- 外加hashmap中的不同点
Java JDK源码 word文档下载地址:链接:https://pan.baidu.com/s/1BaUi8KUjvjJ6RPN7CmMSyw
提取码:1111爆肝一周,不眠不休!就为 点赞+好评+收藏 三连
常用主流框架面试合辑
Spring框架篇
1、什么是 Spring 框架?Spring 框架有哪些主要模块?
Spring 框架是一个为 Java 应用程序的开发提供了综合、广泛的基础性支持的 Java 平台。Spring 帮助开发者解决了开发中基础性的问题,使得开发人员可以专注于应用程序的开发。
Spring 框架本身亦是按照设计模式精心打造,这使得我们可以在开发环境中安心的集成 Spring 框架,不必担心 Spring 是如何在后台进行工作的。Spring 框架至今已集成了 20 多个模块。这些模块主要被分如下图所示的核心容器、数据访问/集成,、Web、AOP(面向切面编程)、工具、消息和测 试模块。
2、使用 Spring 框架能带来哪些好处?
下面列举了一些使用 Spring 框架带来的主要好处:
• Dependency Injection(DI) 方法使得构造器和 JavaBean properties 文件中的依赖关系一目了然。
• 与 EJB 容器相比较,IoC 容器更加趋向于轻量级。这样一来 IoC 容器在有限的内存和 CPU 资源的情况下进行应用程序的开发和发布就变得十分有利。
• Spring 并没有闭门造车,Spring 利用了已有的技术比如 ORM 框架、logging 框架、J2EE、Q uartz和JDK Timer,以及其他视图技术。
• Spring 框架是按照模块的形式来组织的。由包和类的编号就可以看出其所属的模块,开发者仅仅需要选用他们需要的模块即可。
• 要测试一项用 Spring 开发的应用程序十分简单,因为测试相关的环境代码都已经囊括在框架中了。更加简单的是,利用 JavaBean 形式的 POJO 类,可以很方便的利用依赖注入来写入测试数据。
• Spring 的 Web 框架亦是一个精心设计的 Web MVC 框架,为开发者们在web 框架的选择上提供了一个除了主流框架比如 Struts、过度设计的、不流行 web 框架的以外的有力选项。
• Spring 提供了一个便捷的事务管理接口,适用于小型的本地事物处理(比如在单 DB 的环境下)和复杂的共同事物处理(比如利用 JTA 的复杂 DB 环境)。
3、什么是控制反转(IOC)?什么是依赖注入?
控制反转是应用于软件工程领域中的,在运行时被装配器对象来绑定耦合对象的一种编程技巧,对象之间耦合关系在编译时通常是未知的。在传统的编程方式中,业务逻辑的流程是由应用程序中的早已被设定好关联关系的对象来决定的。在使用控制反转的情况下,业务逻辑的流程是由对象关系图来决定的,该对象关系图由装配器负责实例化,这种实现方式还可以将对象之间的关联关系的定义抽象化。而绑定的过程是通过“依赖注入”实现的。
控制反转是一种以给予应用程序中目标组件更多控制为目的设计范式,并在我们的实际工作中起到了有效的作用。
依赖注入是在编译阶段尚未知所需的功能是来自哪个的类的情况下,将其他对象所依赖的功能对象实例化的模式。这就需要一种机制用来激活相应 的组件以提供特定的功能,所以依赖注入是控制反转的基础。否则如果在组件不受框架控制的情况下,框架又怎么知道要创建哪个组件?
在 Java 中依然注入有以下三种实现方式:
1. 构造器注入
2. Setter 方法注入
3. 接口注入
4、请解释下 Spring 框架中的 IoC?
Spring 中的 org.springframework.beans 包和 org.springframework.context包构成了 Spring 框架 IoC 容器的基础。BeanFactory 接口提供了一个先进的配置机制,使得任何类型的对象的配置成为可能。
ApplicationContex 接口对 BeanFactory(是一个子接口)进行了扩展,在 BeanFactory 的基础上添加了其他功能,比如与 Spring 的AOP 更容易集成,也提供了处理 message resource 的机制(用于国际化)、事件传播以及应用层的特别配置,比如针对 Web 应用的WebApplicationContext。
org.springframework.beans.factory.BeanFactory 是 Spring IoC 容器的具体实现,用来包装和管理前面提到的各种 bean。BeanFactory 接口是 Spring IoC 容器的核心接口。
IOC:把对象的创建、初始化、销毁交给 spring 来管理,而不是由开发者控制,实现控制反转。
5、BeanFactory 和 ApplicationContext 有什么区别?
BeanFactory 可以理解为含有 bean 集合的工厂类。BeanFactory 包含了种bean 的定义,以便在接收到客户端请求时将对应的 bean 实例化。BeanFactory 还能在实例化对象的时生成协作类之间的关系。此举将 bean 自身与 bean 客户端的 配置中解放出来。BeanFactory 还包含了 bean 生命周期的控制,调用客户端的初始化方法 (initialization methods)和销毁方法(destruction methods)。
从表面上看,application context 如同 bean factory 一样具有 bean 定义、bean 关联关系的设置,根据请求分发 bean 的功能。但 applicationcontext 在此基础上还提供了其他的功能。
1. 提供了支持国际化的文本消息
2. 统一的资源文件读取方式
3. 已在监听器中注册的bean的事件
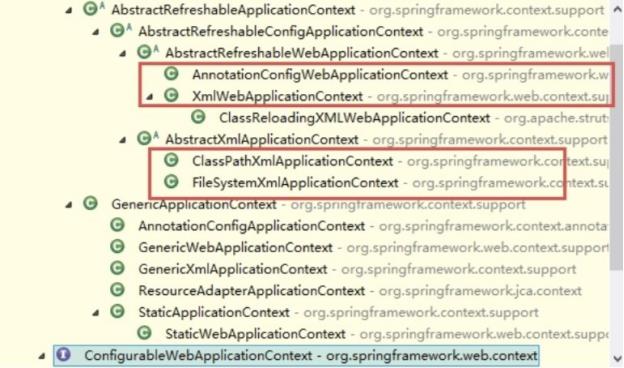
以下是三种较常见的 ApplicationContext 实现方式:
1、ClassPathXmlApplicationContext:从 classpath 的 XML 配置文件中读取上下文,并生成上下文定义。应用程序上下文从程序环境变量中
ApplicationContext context = new ClassPathXmlApplicationContex t(“bean.xml”);2、FileSystemXmlApplicationContext :由文件系统中的 XML 配置文件读取上下文。
ApplicationContext context = new FileSystemXmlApplicationConte xt(“bean.xml”);3、XmlWebApplicationContext:由 Web 应用的 XML 文件读取上下文。
4、AnnotationConfigApplicationContext(基于 Java 配置启动容器)
6、Spring 有几种配置方式?
将 Spring 配置到应用开发中有以下三种方式:
1. 基于XML的配置
2. 基于注解的配置
3. 基于Java的配置
7、如何用基于 XML 配置的方式配置 Spring?
在 Spring 框架中,依赖和服务需要在专门的配置文件来实现,我常用的XML 格式的配置文件。这 些配置文件的格式通常<beans>开头,然后一系列的 bean 定义和专门的应用配置选项组成。
SpringXML 配置的主要目的时候是使所有的 Spring 组件都可以用 xml 文件的形式来进行配置。这意味着不会出现其他的 Spring 配置类型(比如声明的方式或基于 Java Class 的配置方式)
Spring 的 XML 配置方式是使用被 Spring 命名空间的所支持的一系列的XML 标签来实现的。Spring 有以下主要的命名空间:context、beans、jdbc、tx、aop、mvc 和 aso。
如:

下面这个 web.xml 仅仅配置了 DispatcherServlet,这件最简单的配置便能满足应用程序配置运行时组件的需求


8、如何用基于 Java 配置的方式配置 Spring?
Spring 对 Java 配置的支持是由@Configuration 注解和@Bean 注解来实现的。由@Bean 注解的方法将会实例化、配置和初始化一个 新对象,这个对象将由 Spring 的 IoC 容器来管理。@Bean 声明所起到的作用与 <bean>元素类似。被 @Configuration 所注解的类则表示这个类的主要目的是作为 bean 定义的资源。被@Configuration 声明的类可以通过在同一个类的内部调 用@bean 方法来设置嵌入 bean 的依赖关系。
最简单的@Configuration 声明类请参考下面的代码:

对于上面的@Beans 配置文件相同的 XML 配置文件如下:
<beans>
<bean id="myService" class="com.somnus.services.MyServiceI mpl"/>
</beans>上述配置方式的实例化方式如下:利用 AnnotationConfigApplicationContext
public static void main(String[] args)
ApplicationContext ctx = new
AnnotationConfigApplicationContext(AppConfig.class);
MyService myService = ctx.getBean(MyService.class);
myService.doStuff();
要使用组件组建扫描,仅需用@Configuration 进行注解即可:
@Configuration
@ComponentScan(basePackages = "com.somnus")
public class AppConfig
... 在上面的例子中,com.acme 包首先会被扫到,然后再容器内查找被@Component 声明的类,找到后将这些类按照 Sring bean 定义进行注册。
如果你要在你的 web 应用开发中选用上述的配置的方式的话,需要用
AnnotationConfigWebApplicationContext 类来读取配置文件,可以用来配置 Spring 的 Servlet 监听器 ContextLoaderListener 或者 Spring MVC 的
<web-app>
<!-- Configure ContextLoaderListener to use AnnotationConfigWebApplicationContext
instead of the default XmlWebApplicationContext -->
<context-param>
<param-name>contextClass</param-name>
<param-value> org.springframework.web.context.support.AnnotationConfigWebApp licatio
nContext
</param-value>
</context-param>
<!-- Configuration locations must consist of one or more comma
- or space-delimited
fully-qualified @Configuration classes. Fully-qualifie
d
packages may also be
specified for component-scanning -->
<context-param>
<param-name>contextConfigLocation</param-name>
<param-value>com.howtodoinjava.AppConfig</param-value>
</context-param>
<!-- Bootstrap the root application context as usual using ContextLoaderListener -->
<web-app>
<!-- Configure ContextLoaderListener to use AnnotationConfigWebApplicationContext
instead of the default XmlWebApplicationContext -->
<context-param>
<param-name>contextClass</param-name>
<param-value> org.springframework.web.context.support.AnnotationConfigWebApp
licatio nContext
</param-value>
</context-param>
<!-- Configuration locations must consist of one or more comma
- or space-delimited
fully-qualified @Configuration classes. Fully-qualifie
d
packages may also be
specified for component-scanning -->
<context-param>
<param-name>contextConfigLocation</param-name>
<param-value>com.howtodoinjava.AppConfig</param-value>
</context-param>
<!-- Bootstrap the root application context as usual using ContextLoaderListener -->9、怎样用注解的方式配置 Spring?
Spring 在 2.5 版本以后开始支持用注解的方式来配置依赖注入。可以用注解的方式来替代 XML 方式的 bean 描述,可以将 bean 描述转移到组件类的内部,只需要在相关类上、方法上或者字段声明上使用注解即可。注解注入将会被容器在 XML 注入之前被处理,所以后者会覆盖掉前者对于同一个属性的处理结果。
注解装配在 Spring 中是默认关闭的。所以需要在 Spring 文件中配置一下才能使用基于注解的装配模式。如果你想要在你的应用程序中使用关于注 解的方法的话,请参考如下的配置。
<beans>
<context:annotation-config/>
<!-- bean definitions go here -->
</beans>在<context:annotation-config/>标签配置完成以后,就可以用注解
的方式在 Spring 中向属性、方法和构造方法中自动装配变量。下面是几种比较重要的注解类型:
1. @Required:该注解应用于设值方法。
2. @Autowired:该注解应用于有值设值方法、非设值方法、构造方法和变 量。
3. @Qualifier:该注解和@Autowired 注解搭配使用,用于消除特定 bean 自动装配的歧义。
4. JSR-250 Annotations:Spring 支持基于 JSR-250 注解的以下注解,
@Resource、 @PostConstruct 和 @PreDestroy。
10、请解释 Spring Bean 的生命周期?
Spring Bean 的生命周期简单易懂。在一个 bean 实例被初始化时,需要执行一系列的初始化操作以达到可用的状态。同样的,当一个 bean 不在被调用时需要进行相关的析构操作,并从 bean 容 器中移除。
Spring bean factory 负责管理在 spring 容器中被创建的 bean 的生命周期。Bean 的生命周期由两组回调(call back)方法组成。
1. 初始化之后调用的回调方法。
2. 销毁之前调用的回调方法。
Spring 框架提供了以下四种方式来管理 bean 的生命周期事件:
• InitializingBean 和 DisposableBean 回调接口
• 针对特殊行为的其他 Aware 接口
• Bean配置文件中的Custom init()方法和destroy()方法
• @PostConstruct 和@PreDestroy 注解方式
使用 customInit()和 customDestroy()方法管理 bean 生命周期的代码样例如下:
<beans>
<bean id="demoBean" class="com.somnus.task.DemoBean"
init- method="customInit" destroy-method="customDestroy"></bean>
</beans>11、Spring Bean 的作用域之间有什么区别?
Spring 容器中的 bean 可以分为 5 个范围。所有范围的名称都是自说明的,但是为了避免混淆,还是让我们来解释一下:
1. singleton:这种 bean 范围是默认的,这种范围确保不管接受到多少个请求,每个容器中只有一个 bean 的实例,单例的模式由 bean factory 自身来维护。
2. prototype:原形范围与单例范围相反,为每一个 bean 请求提供一个实例。
3. request:在请求 bean 范围内会每一个来自客户端的网络请求创建一个实例,在请求完成以后,bean 会失效并被垃圾回收器回收。
4. Session:与请求范围类似,确保每个 session 中有一个 bean 的实例,在
session 过期后,bean 会随之失效。
5. global- session:global-session 和 Portlet 应用相关。当你的应用部署在Portlet 容器中工作时,它包含很多 portlet。如果你想要声明让所有的portlet 共用全局的存储变量的话,那么这全局变量需要存储在 global- session 中。
全局作用域与 Servlet 中的 session 作用域效果相同。
12、什么是 Spring inner beans?
在 Spring 框架中,无论何时 bean 被使用时,当仅被调用了一个属性。一个明智的做法是将这个 bean 声明为内部 bean。内部 bean 可以用 setter 注入“属性”和构造方法注入“构造参数”的方式来 实现。
比如,在我们的应用程序中,一个 Customer 类引用了一个 Person 类, 我们的要做的是创建一个 Person 的实例,然后在 Customer 内部使用。
public class Customer private Person person;
//Setters and Getters
public class
Person private String name; private String address; private int age内部 bean 的声明方式如下:
<bean id="CustomerBean" class="com.somnus.common.Customer">
<property name="person">
<!-- This is inner bean -->
<bean class="com.howtodoinjava.common.Person">
<property name="name" value="lokesh" />
<property name="address" value="India" />
<property name="age" value="34" />
</bean>
</property>
</bean>13、Spring 框架中的单例 Beans 是线程安全的么?
Spring 框架并没有对单例 bean 进行任何多线程的封装处理。关于单例bean 的线程安全和并发问题需要开发者自行去搞定。但实际上,大部分的 Spring bean 并没有可变的状态(比如 Serview 类和 DAO 类),所以在某种程度上说 Spring 的单例 bean 是线程安全的。如果你的 bean 有多种状态的话(比如 View Model 对象),就需要自行保证线程安全。
最浅显的解决办法就是将多态 bean 的作用域由“singleton”变更为“prototype”。
14、请举例说明如何在 Spring 中注入一个 Java Collection?
Spring 提供了以下四种集合类的配置元素:
- <list>该标签用来装配可重复的 list 值。
- <set>该标签用来装配没有重复的 set 值。
- <map>该标签可用来注入键和值可以为任何类型的键值对
- <props>该标签支持注入键和值都是字符串类型的键值对。
下面看一下具体的例子:
<beans>
<!-- Definition for javaCollection -->
<bean id="javaCollection" class="com.howtodoinjava.JavaCollect ion">
<!-- java.util.List -->
<property name="customList">
<list>
<value>INDIA</value>
<value>Pakistan</value>
<value>USA</value>
<value>UK</value>
</list>
</property>
<!-- java.util.Set -->
<property name="customSet"
<set>
<value>INDIA</value>
<value>Pakistan</value>
<value>USA</value>
<value>UK</value>
</set>
</property>
<!-- java.util.Map -->
<property name="customMap">
<map>
<entry key="1" value="INDIA"/>
<entry key="2" value="Pakistan"/>
<entry key="3" value="USA"/>
<entry key="4" value="UK"/>
</map>
</property>
<!-- java.util.Properties -->
<property name="customProperies">
<props>
<prop key="admin">admin@nospam.com</prop>
<prop key="support">support@nospam.com</prop>
</props>
</property>
</bean>
</beans>15、如何向 Spring Bean 中注入一个 Java.util.Properties?
第一种方法是使用如下面代码所示的<props>标签:
<bean id="adminUser" class="com.somnus.common.Customer">
<!-- java.util.Properties -->
<property name="emails">
<props>
<prop key="admin">admin@nospam.com</prop>
<prop key="support">support@nospam.com</prop>
</props>
</property>
</bean>
也可用”util:”命名空间来从 properties 文件中创建出一个 propertiesbean,然后利用 setter 方 法注入 bean 的引用。
16、请解释 Spring Bean 的自动装配?
在 Spring 框架中,在配置文件中设定 bean 的依赖关系是一个很好的机 制,Spring 容器还可以自 动装配合作关系 bean 之间的关联关系。这意味着 Spring 可以通过向 Bean Factory 中注入的方 式自动搞定 bean 之间的依赖关系。自动装配可以设置在每个 bean 上,也可以设定在特定的 bean 上。下面的 XML 配置文件表明了如何根据名称将一个 bean 设置为自动装配:
<bean id="employeeDAO" class="com.howtodoinjava.EmployeeDAOImp l"
autowire="byName" />
除了 bean 配置文件中提供的自动装配模式,还可以使用@Autowired 注解来自动装配指定 的 bean。在使用@Autowired 注解之前需要在按照如下的配置方式在 Spring 配置文件进行配置才可以使用。
<context:annotation-config />也可以通过在配置文件中配置 AutowiredAnnotationBeanPostProcessor 达到相同的效果。
<bean class
="org.springframework.beans.factory.annotation.AutowiredAnnota tionBea
nPostProcessor"/>配置好以后就可以使用@Autowired 来标注了。
@Autowired
public EmployeeDAOImpl ( EmployeeManager manager ) this.manager = manager;
17、请解释自动装配模式的区别?
在 Spring 框架中共有 5 种自动装配,让我们逐一分析。
1. no:这是 Spring 框架的默认设置,在该设置下自动装配是关闭的,开发者需要自行在 bean 定义 中用标签明确的设置依赖关系。
2. byName:该选项可以根据 bean 名称设置依赖关系。当向一个 bean 中自动装配一个属性时,容器将根据 bean 的名称自动在在配置文件中查询一个匹配的 bean。如果找到的话,就装配这个属性,如果没找到的话就报错。
3. byType:该选项可以根据 bean 类型设置依赖关系。当向一个 bean 中自动装配一个属性时,容器将根据 bean 的类型自动在在配置文件中查询一个匹配的 bean。如果找到的话,就装配这个属性,如果没找到的话就报错。
4. constructor:构造器的自动装配和 byType 模式类似,但是仅仅适用于与有构造器相同参数的 bean,如果在容器中没有找到与构造器参数类型一致的 bean,那么将会抛出异常。
5. autodetect:该模式自动探测使用构造器自动装配或者 byType 自动装配。首先,首先会尝试找合适的带参数的构造器,如果找到的话就是用构造器自动装配,如果在 bean 内部没有找到相应的构造器或者是无参构造器,容器就会自动选择 byTpe 的自动装配方式。
18、如何开启基于注解的自动装配?
要使用 @Autowired,需要注册 AutowiredAnnotationBeanPostProcessor,可以
有以下两种方式来实现:
引入配置文件中的<bean>下引入<context:annotation-config>
<beans>
<context:annotation-config />
</beans>
class="org.springframework.beans.factory.annotation.AutowiredA nnotati
onBeanPostProcessor"/>在 bean 配置文件中直接引入 AutowiredAnnotationBeanPostProcessor
19、请举例解释@Required 注解?
在产品级别的应用中,IoC 容器可能声明了数十万了 bean,bean 与 bean
之间有着复杂的依赖关系。设值注解方法的短板之一就是验证所有的属性
是否被注解是一项十分困难的操作。可以通过在 中设置“dependency-check”来解决这个问题。
在应用程序的生命周期中,你可能不大愿意花时间在验证所有 bean 的属性是否按照上下文件正确配置。或者你宁可验证某个 bean 的特定属性是否被正确的设置。即使是用“dependency- check”属性也不能很好的解决这个问题,在这种情况下,你需要使用@Required 注解。
需要用如下的方式使用来标明 bean 的设值方法:
public class EmployeeFactoryBean extends AbstractFactoryBean<O bject>
private String designation; public String getDesignation()
return designation;
@Required
public void setDesignation(String designation)
this.designation = designation;
//more code here
RequiredAnnotationBeanPostProcessor 是 Spring 中的后置处理用来验证被 @Required 注解的 bean 属性是否被正确的设置了。在使用RequiredAnnotationBeanPostProcesso 来验证 bean 属性之前,首先要在IoC 容器中对其进行注册: 但是如果没有属性被用 @Required 注解过的话,后置处理器会抛出一个BeanInitializationException 异常。
20、请举例解释@Autowired 注解?
@Autowired 注解对自动装配何时何处被实现提供了更多细粒度的控制。@Autowired 注解可 以像@Required 注解、构造器一样被用于在 bean 的设置方法上自动装配 bean 的属性,一个参数或者带有任意名称或带有多个参数的方法。比如,可以在设值方法上使用@Autowired 注解来替代配置文件中的<property>元素当 Spring 容器在 setter 方法上找到@Autowired 注解时,会尝试用 byType 自动装配。当然我们也可以在构造方法上使用@Autowired 注解。带有@Autowired 注解的构造方法意味着 在创建一个 bean 时将会被自动装配,即便在配置文件中使用<property>元素。
public class TextEditor
private SpellChecker spellChecker; @Autowired
public TextEditor(SpellChecker spellChecker)
System.out.println("Inside TextEditor constructor." );
this.spellChecker = spellChecker;
public void spellCheck() spellChecker.checkSpelling();下面是没有构造参数的配置方式:
<beans>
<context:annotation-config/>
<!-- Definition for textEditor bean without constructor-arg
-->
<bean id="textEditor" class="com.howtodoinjava.TextEditor"/
>
<!-- Definition for spellChecker bean -->
<bean id="spellChecker" class="com.howtodoinjava.SpellCheck er"/>
</beans>21、请举例说明@Qualifier 注解?
@Qualifier 注解意味着可以在被标注 bean 的字段上可以自动装配。Qualifier 注解可以用来取消 Spring 不能取消的 bean 应用。下面的示例将会在 Customer 的 person 属性中自动装配 person 的值
public class Customer @Autowired
private Person person
<bean id="customer" class="com.somnus.common.Customer" />
<bean id="personA" class="com.somnus.common.Person" >
<property name="name" value="lokesh" />
</bean>
<bean id="personB" class="com.somnus.common.Person" >
<property name="name" value="alex" />
</bean>下面我们要在配置文件中来配置 Person 类。
Spring 会知道要自动装配哪个 person bean 么?不会的,但是运行上面的示例时,会抛出下面的异常:
Caused by: org.springframework.beans.factory.NoSuchBeanDefinitionExceptio n:
No unique bean of type [com.howtodoinjava.common.Person] is de fined: expected single matching bean but found2: [personA, pe rsonB]要解决上面的问题,需要使用 @Quanlifier 注解来告诉 Spring 容器要装配哪个 bean:
public class Customer @Autowired @Qualifier("personA") private Person person;
22、构造方法注入和设值注入有什么区别? 请注意以下明显的区别:
1. 在设值注入方法支持大部分的依赖注入,如果我们仅需要注入int、 string和long型的变量,我们不要用设值的方法注入。对于基本类型,如果我们没有注入的话,可以为基本类型设置默认值。在构造方法 注入不支持大部分的依赖注入,因为在调用构造方法中必须传入正确的构造参数,否 则的话为报错。
2. 设值注入不会重写构造方法的值。如果我们对同一个变量同时使用了构 造方法注入又使用了设置方法注入的话,那么构造方法将不能覆盖由设值方法注入的值。很明显,因为构造方法在对象被创建时调用。
3. 在使用设值注入时有可能还不能保证某种依赖是否已经被注入,也就是说这时对象的依赖关系有可能是不完整的。而在另一种情况下,构造器注入则不允许生成依赖关系不完整的对象。
4. 在设值注入时如果对象A和对象B互相依赖,在创建对象A时Spring会抛出 sObjectCurrentlyInCreationException 异常,因为在 B 对象被创建之前A 对 象是不能被创建的,反之亦然。所以 Spring 用设值注入的方法解决了循环依赖的问题,因对象的设值方法是在对象被创建之前被调用的。
23、Spring 框架中有哪些不同类型的事件?
Spring 的 ApplicationContext 提供了支持事件和代码中监听器的功能。我们可以创建 bean 用来监听在 ApplicationContext 中发布的事件。ApplicationEvent 类和在 ApplicationContext 接口中处理的事件,如果一个bean 实现了 ApplicationListener 接口,当一个 ApplicationEvent 被发布以后,bean 会自动被通知。
public class AllApplicationEventListener implements Applicatio nListener < ApplicationEvent >
@Override
public void onApplicationEvent(ApplicationEvent applicatio nEvent)
//process event
Spring 提供了以下 5 种标准的事件:
1. 上下文更新事件(ContextRefreshedEvent):该事件会在ApplicationContext被初始化或者更新时发布。也可以在调用 ConfigurableApplicationContext接口中的 refresh()方法时被触发。
2. 上下文开始事件(ContextStartedEvent):当容器调用ConfigurableApplicationContext的 Start()方法开始/重新开始容器时触发该事件。
3. 上下文停止事件(ContextStoppedEvent):当容器调用ConfigurableApplicationContext的 Stop()方法停止容器时触发该事件。
4. 上下文关闭事件(ContextClosedEvent):当ApplicationContext被关闭时触发该事件。容器被关闭时,其管理的所有单例 Bean 都被销毁。
5. 请求处理事件(RequestHandledEvent):在Web应用中,当一个http请求(request)结束 触发该事件。
public class CustomApplicationEvent extends ApplicationEvent public CustomApplicationEvent ( Object source, final String ms g )
super(source);
System.out.println("Created a Custom event");
为了监听这个事件,还需要创建一个监听器:
public class CustomEventListener implements ApplicationListene r <
CustomApplicationEvent > @Override
public void onApplicationEvent(CustomApplicationEvent applicationEvent)
//handle event
之后通过 applicationContext 接口的 publishEvent()方法来发布自定义事件。
CustomApplicationEvent customEvent = new
CustomApplicationEvent(applicationContext, "Test message");
applicationContext.publishEvent(customEvent);24、FileSystemResource 和 ClassPathResource 有何区别?
在 FileSystemResource 中需要给出 spring-config.xml 文件在你项目中的相对路径或者绝对路径。在 ClassPathResource 中 spring 会在 ClassPath 中自动搜寻配置文件,所以要把 ClassPathResource 文件放在 ClassPath下。
如果将 spring-config.xml 保存在了 src 文件央下的话,只需给出配置文件的名称即可,因为 src 文件央是默认。
简而言之,ClassPathResource 在环境变量中读取配置文件,
FileSystemResource 在配置文件中读取配置文件。
25、Spring 框架中都用到了哪些设计模式?
Spring 框架中使用到了大量的设计模式,下面列举了比较有代表性的:
- 代理模式—在AOP和remoting中被用的比较多。
- 单例模式—在spring配置文件中定义的bean默认为单例模式。
- 模板方法—用来解决代码重复的问题。比 如.RestTemplate,JmsTemplate,JpaTempl ate。
- 前端控制器—Spring提供了DispatcherServlet来对请求进行分发。
- 视图帮助(ViewHelper)—Spring提供了一系列的JSP标签,高效宏来辅助 将分散的代码整合在视图里。
- 依赖注入—贯穿于BeanFactory/ApplicationContext接口的核心理念。
- 工厂模式—BeanFactory用来创建对象的实例
26、开发中主要使用 Spring 的什么技术 ?
1. IOC 容器管理各层的组件
2. 使用 AOP 配置声明式事务
3. 整合其他框架.
27、简述 AOP 和 IOC 概念 AOP:
Aspect Oriented Program, 面向(方面)切面的编程;Filter(过滤器) 也是一种AOP. AOP 是一种新的方法论, 是对传统 OOP(Object-Oriented Programming, 面向对象编程) 的补充. AOP 的 主要编程对象是切面(aspect), 而切面模块化横切关注点.可以举例通过事务说明.
IOC: Invert Of Control, 控制反转. 也成为 DI(依赖注入)其思想是反转资源获取的方向. 传统的资源查找方式要求组件向容器发起请求查找资源.作为回应, 容器适时的返回资源. 而应用了 IOC 之后, 则是容器主动地将资源推送给它所管理的组件,组件所要做的仅是选择一种合适的方式来接受资源. 这种行为也被称为查找的被动形式
28、在 Spring 中如何配置 Bean ?
Bean 的配置方式:
- 通过全类名(反射)
- 通过工厂方法(静态工厂方法 & 实例工厂方法)
- FactoryBean
29、IOC 容器对 Bean 的生命周期:
1. 通过构造器或工厂方法创建 Bean 实例
2. 为 Bean 的属性设置值和对其他 Bean 的引用
3. 将 Bean 实例传递给 Bean 后置处理器的 postProcessBeforeInitialization方法
4. 调用 Bean 的初始化方法(init-method)
5. 将 Bean 实例传递给 Bean 后置处理器的 postProcessAfterInitialization方法
6. Bean 可以使用了
7. 当容器关闭时, 调用 Bean 的销毁方法(destroy-method)
下载链接:https://pan.baidu.com/s/1nwlBO2tYXDDl7OjGhs4e4Q
提取码:1111
SpringMVC原理篇
1、什么是 SpringMvc?
SpringMvc 是 spring 的一个模块,基于 MVC 的一个框架,无需中间整合层来整合。
2、Spring MVC 的优点:
1. 它是基
以上是关于这个疯子整理的十万字Java面试题汇总,终于拿下40W offer!(JDK源码+微服务合集+并发编程+性能优化合集+分布式中间件合集)的主要内容,如果未能解决你的问题,请参考以下文章