trace的产率说明
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了trace的产率说明相关的知识,希望对你有一定的参考价值。
近期一直在学习和复现“根因分析”领域的相关文章,在这里跟大家一起分享下相关内容。这里不在赘述关于“可观测性”和“AIOps”的重要性和必要性,也不过多的陈述在“复杂系统”中进行快速根因诊断的必要性,直接进入到相关算法和系统设计部分。在智能运维的体系中,用来分析和建模的数据可以笼统的分为:Log + Trace + Metric,这里面的数据量是巨大的,且数据形态是复杂多样,对于企业来说,不仅仅要考虑存储系统的吞吐、以及架构在存储系统之上计算引擎的灵活性,同时也会很关注成本。
基于Trace我们可以做些什么?
业务场景
拓扑生成
架构梳理
各服务的流量估算
系统的热点分析
链路的性能分析
错误的传播分析
发布过程中,流量的灰度分析,发布质量的评估
各家根因分析系统(系统+算法)
EMonitor -> 基于Tracing和Metrics的诊断系统
该系统是来自阿里本地生活的故障诊断的分享,在特定场景中可以较好的解决如下问题:
哪些入口受到了影响?
受影响的入口的本地操作和远程操作的影响如何?
受影响的入口都抛出了哪些异常?
在该系统中,无法准确(无法直接根据数据给出,需要推断)的解决如下问题:
GC问题
容器问题
变更导致的问题
该诊断系统的上层出发点是源自于观测的核心SLO指标的抖动,去分析是哪些聚合维度的指标的异常导致了当前的扰动,从而定位到需要进一步诊断的下层入口,通过如此反复的确认,得到最终的定位信息。这里提供一张特定的图(来自知乎上的发表过的图)。
通过上述图中的描述,我们可以看到饿了么团队可以完成如下几个能力:
大量复杂的数据预处理,通过一定的手段将数据进行清洗后格式化(或者严格要求日志字段格式),较好的完成了Metrics、Logs、Trace的关联跳转;
开发了特定的计算策略(OLAP侧或者本地服务侧)支持扰动分析,提供出探寻的候选集;
在特定的业务场景中,支持多个服务模块之间的参数调用,得到较为完成的业务侧拓扑;
但是分析下来,里面必定特别多的定制化的操作和对于开发的严格日志结构的要求,且有较大的定制化开发需求,在云上快速拓展有一定的难度。
GMTA Explorer -> 基于Trace的监控和服务诊断
该系统是eBay建立并在企业中落地的诊断系统,这套系统可以解决eBay每天1500亿条Span数据,可以在一定程度上处理Trace数据中的断链和错链问题。这里最核心的概念在如下的图2中已经描述出来了,这里重新提取下:
BusinessFlow(业务流):最终是由业务方(使用方)来确定的;
Path:同一个业务在一段时间内的请求所构成的一个链路,最终是有多条Trace的路径合并出来的(业务请求在微服务系统中流经的节点所构成的Path)
数据流图+算法设计
在上图中,我们可以看到最核心的是要通过Flink计算出单条Trace的Path,然后通过一定的手段(聚类等)实现业务流的生成(Business Flow)。在数据处理的环节有几个重要的手段进行数据的处理:
根据特定业务输入,完成一些无效操作名称的替换;
根据标准的Trace定义,丢弃一些错误的数据,比如:根节点缺失、多个根节点等;
同时要尽可能关联一些错误日志数据,叫做错误传播链(EP Chains, Error Propagation Trace);
下图较为清晰的描述了几个核心概念之间的关系。
这里我们可以简单说下,产生最终业务流的依赖的数据。根据文中的数据来说,在图数据存储中,时刻更新着当前系统中操作粒度的调用关系图,在分析型存储中按照一定的需求,存储着Path信息和业务流信息。
通过文中这个图,我们可以基本知道分析型存储中的基本结构,其中对于后续分析问题较为重要的两个核心属性是:PathID和BusinessFlowName,其中重中之重的属性值是PathID。那么,我们查看下原文中对于PathID的生成部分的描述。这里我们就要查看下文中的一个SpanHash的策略了。
span
+ serviceName
+ operationName
+ level
+ duration
+ statusCode
+ labels
+ childSpans[]
Algorithm 1 SpanHash(span)
+ hash = HashCode(span.serviceName) + HashCode(span.operationName) + span.level * PrimeNumber
+ for each child in span.childSpans do
+ hash += SpanHash(child)
+ end for
+ return hash
这里面一个比较核心的问题在于:如何在海量的Trace数据中,以较小的成本去解决单个span在Trace链路中的level和childSpans的问题?(这个问题本质上将是:底层的存储和计算引擎的选型和问题,文中提到,在eBay中使用的是Neo4j+Druid+Flink进行存储和计算)
还有一点值得称赞的是,该平台的完整度问题,在GMTA Explorer中,提供了很多基础能力,我们一起来看下。
基于上述能力,可以解决不同场景的业务问题
作为开发人员,可视化业务流程中服务的依赖关系和依赖项,以确定服务的更改影响。
作为架构师,学习与关键业务(例如支付)相关的路径和指标,以支持架构决策。
作为 SRE,确认服务行为的变化或模式,并评估业务变化或其他因素对流量、延迟和错误率等指标的影响。
这里就提供下文中的实验例子,由于接口变更导致的服务指标的变化。
可以较为清晰的看到,上部分表达的是某个业务流中有三个核心链路,下面部分表示的是链路归并后的效果,我们可以很清晰的看到,在userCheckout这个链路中calculateMoney的调用接口由"coupon" -> "couponV2"后,可以较清楚的看到,对于createOrder来说,调用量上升了20%,延迟降低了5%。
在工程实践上的一些取舍
在后端存储和计算的选型上,不额外的造轮子,选择现有的大数据组件,且经过一些中间层粘合起来使用
对于如此大的数据规模,在实际中,也会进行一定的采样(文中提到了1%的采样率写入到Kafka中)
对于trace中数据的迟到和完整度的问题,采用Flink去解决
对于Flink消费之后的结果,一部分写入到Druid中,一部分直接提取后写入到neo4j中
在通过一些UI可视化组件解决后续的交互式分析问题
几点思考
这偏文章读下来更多的是偏向介绍数据在系统中的流转,并非过多的在介绍算法本身(单纯的看算法部分缺失不复杂),落地起来较为可行;
在PathID生成中,过分依赖Flink的State能力,并没有设计或优化下高效的生成PathID的策略,这里还需要进一步的提升;
在文末提到,对数据进行Trace数据的1%的采样,并没有透露出具体的采样策略,因为采样策略对数据质量和数据覆盖度有较为严重的影响;
文中提出了Business Flow的概念,这个让我眼前一样,继续探索下,如何能进一步自动生成BusinessFlow的策略,可以通过一个UI让用户可以来管理自己的业务就是很大的进步了;
根因诊断的下一步思考
算法侧需求
Trace场景的数据相对来说较为确定且具体,其中面临的问题也是确定的,这里更多的是是考虑如何在端上可以灵活的按需去采样,去解决后端的存储成本的问题,对于算法侧来说复杂度不是很高;
在解决Trace数据后,如何将Metric和Alarm整合在一起,去自动化的做因果分析,这个还是复杂一些的;
是否可以在以一步的让AI去学习我们的业务代码,能否将根因结果自动的和代码提交进行诊断,进一步定位到具体的更改(微软等已经在做了一些尝试)
下一步更多的需要去考虑多元数据的融合问题,能否在云上提供类似APM中的完整能力,做到简单、易用;
现阶段对于平台来说,要解决好信息抽取后的表达和管理工作,为后续的自动化分析和诊断扫清 障碍; 参考技术A trace的产率说明
加减号或者trace报告就是说明你的尿里有蛋白比减号的时候要多一点,但是还不足以达到一个加号的水平。所以尿蛋白trace,就是说尿里有少量的蛋白。
Oracle Trace dbms_monitor
Oracle 10g 增加的dbms_monitor方法,异步跟踪,可指定跟踪其他会话,获取对应的trace文件;除了可以设置trace以外还可以开启关闭对指定会话的统计信息;
一句话说明:
dbms_monitor方法提供了4种开启/关闭trace文件的功能+ 2种开启/关闭会话统计信息功能 (其中,统计信息功能类似V$MYSTAT视图);
SQL> desc dbms_monitor;
Element Type
-------------------------- ---------
ALL_MODULES CONSTANT
ALL_ACTIONS CONSTANT
CLIENT_ID_STAT_ENABLE PROCEDURE
CLIENT_ID_STAT_DISABLE PROCEDURE
SERV_MOD_ACT_STAT_ENABLE PROCEDURE
SERV_MOD_ACT_STAT_DISABLE PROCEDURE
CLIENT_ID_TRACE_ENABLE PROCEDURE
CLIENT_ID_TRACE_DISABLE PROCEDURE
SERV_MOD_ACT_TRACE_ENABLE PROCEDURE
SERV_MOD_ACT_TRACE_DISABLE PROCEDURE
SESSION_TRACE_ENABLE PROCEDURE
SESSION_TRACE_DISABLE PROCEDURE
DATABASE_TRACE_ENABLE PROCEDURE
DATABASE_TRACE_DISABLE PROCEDURE
4种方法开启/关闭trace文件:
-
SESSION_TRACE_ENABLE/SESSION_TRACE_DISABLE:
通过指定会话的SID和SERIAL#开启/关闭trace,实现异步跟踪; -
DATABASE_TRACE_ENABLE/DATABASE_TRACE_DISABLE过程:
设置数据库实例上所有会话的trace 开启/关闭,不建议这样做; -
CLIENT_ID_TRACE_ENABLE/CLIENT_ID_TRACE_DISABLE:
通过客户端ID开启/关闭指定客户端的TRACE,如果会话客户端ID为空,可以通过程序设置:DBMS_SESSION.SET_IDENTIFIER('YYC_TEST'); -
SERV_MOD_ACT_TRACE_ENABLE/SERV_MOD_ACT_TRACE_DISABLE:
通过SERVICE_NAME, MODULE_NAME和ACTION_NAME开启/关闭trace;
2种方法开启/关闭会话的统计信息功能:
-
SERV_MOD_ACT_STAT_ENABLE/SERV_MOD_ACT_STAT_DISABLE:
和trace方法4一样,都是通过SERVICE_NAME, MODULE_NAME和ACTION_NAME开启/关闭对应会话的统计信息,对应统计视图:V$SERV_MOD_ACT_STATS; -
CLIENT_ID_STAT_ENABLE/ CLIENT_ID_STAT_DISABLE:
和trace方法3一样,通过通过客户端ID开启/关闭指定客户端的统计信息,对应统计视图:V$CLIENT_STATS;
Session级跟踪,基于会话ID和序列号
不使用form界面跟踪,使用dbms_monitor根据系统用户的session信息获取form界面操作对应的trace数据;
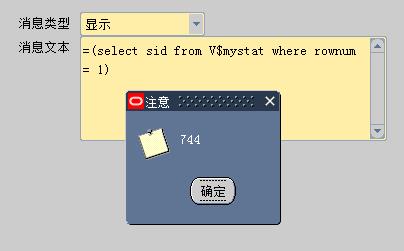
步骤一: 获取form界面所处的sid和serial#,可使用个性化方法获取信息(个性化活动页,通过消息文本输出数据);
=(select sid from V$mystat where rownum = 1)
=(select serial# from V$session where sid = 744)
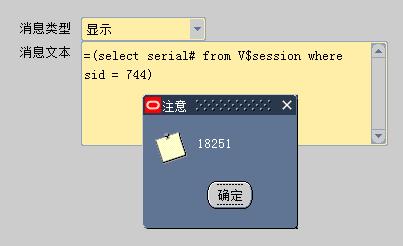
因此,获取到界面会话信息:
Sid = 744, serial# = 18251;
回到界面,到要执行跟踪的步骤之前,本例中为点击“关闭”功能之前;
步骤二:根据获取的sid 、 serial# 开启跟踪:
语法:
dbms_monitor.session_trace_enable(sid,serial#,waits,binds);
其中,waits表示等待信息是否记录在trace文件中,binds表示是否记录绑定变量的信息;
SQL> exec dbms_monitor.session_trace_enable(744, 18251,TRUE,FALSE);
PL/SQL procedure successfully completed
步骤三:在界面执行相关操作后,关闭跟踪:
SQL> exec dbms_monitor.SESSION_TRACE_DISABLE(744, 18251);
PL/SQL procedure successfully completed
步骤四:根据sid获取trace文件路径:
SELECT p.tracefile
FROM v$process p, v$session s
WHERE p.addr = s.paddr
AND s.sid = 744;

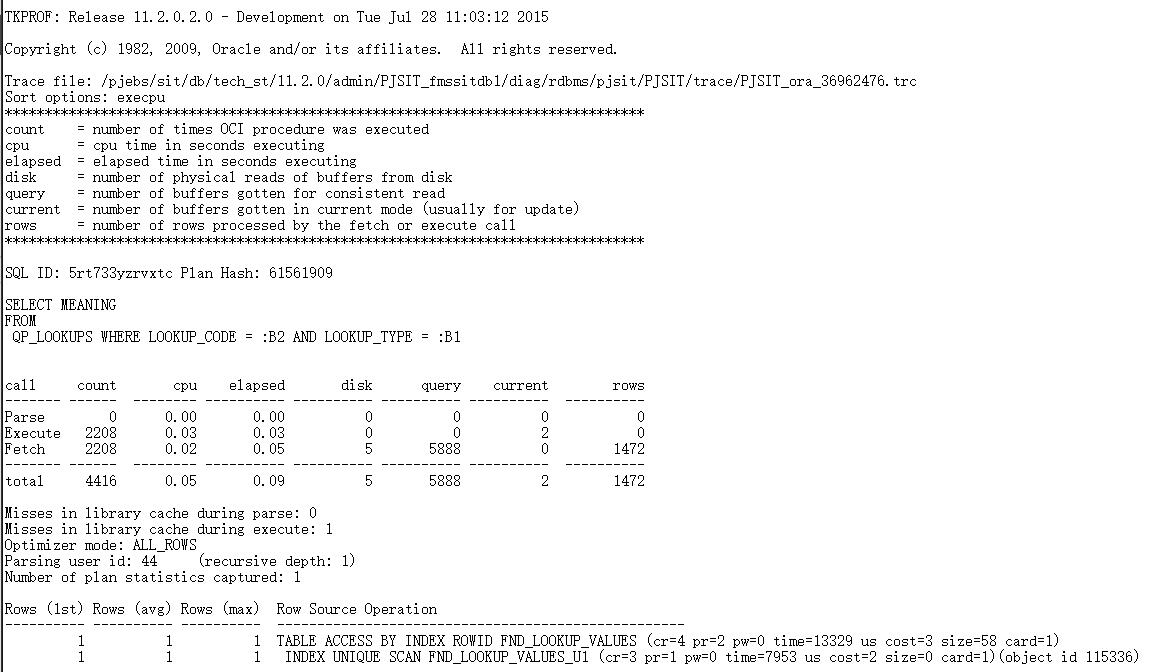
步骤五: tkprof转换trace文件(根据CPU执行时间排序)
tkprof /pjebs/sit/db/tech_st/11.2.0/admin/PJSIT_fmssitdb1/diag/rdbms/pjsit/PJSIT/trace/PJSIT_ora_36962476.trc /pjebs/sit/temp/2/PJSIT_ora_36962476.txt sort= "execpu"
文件中部分内容如下:

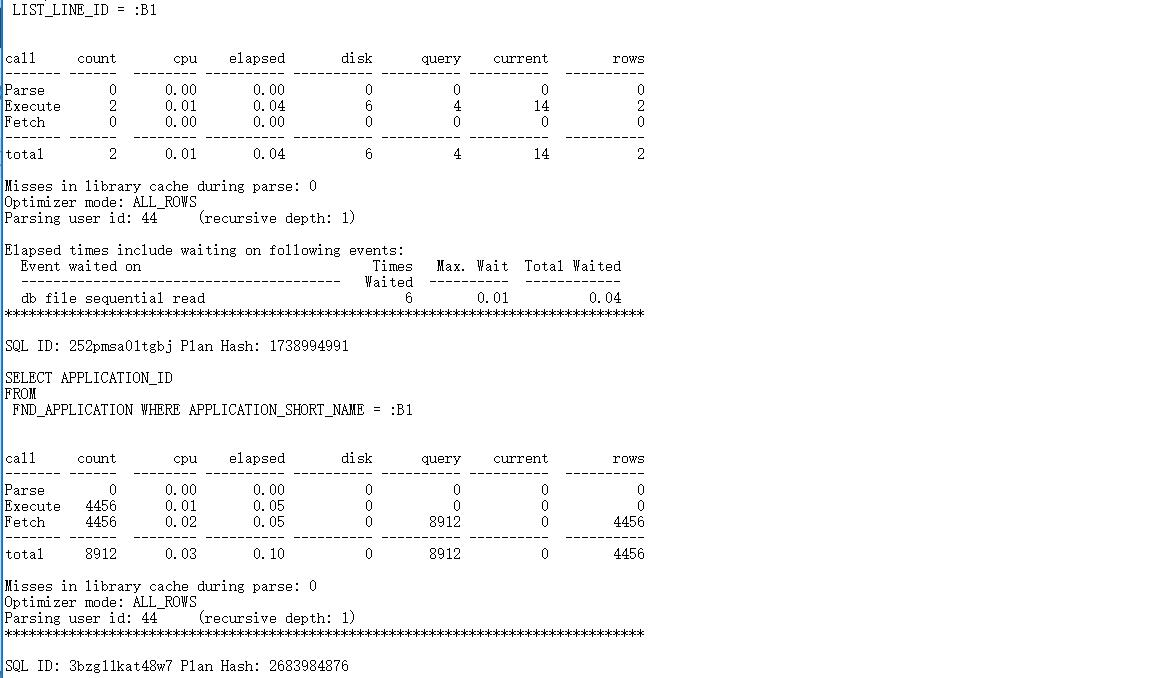
方法小结:
使用V$session视图获取sid和serial#,开启/关闭会话trace命令如下:
exec dbms_monitor.session_trace_enable(744, 18251,TRUE,FALSE);
exec dbms_monitor.SESSION_TRACE_DISABLE(744, 18251);
CLIENT_ID开启/关闭trace
在plsql中,新开一个会话,设置客户端标识为YYC_TEST,开启/关闭trace。
以client_id开启的trace,只要会话的客户端标识为YYC_TEST,会话内的操作均会记录在trace文件中。该方法可开启多个会话的trace记录;
步骤一:新开会话,设置客户端标识为YYC_TEST;
新开会话1,本例中sid = 17; 检查会话trace设置状态:
SELECT sid, client_identifier, sql_trace, sql_trace_waits, sql_trace_binds
FROM v$session
WHERE sid = 17;

因为客户段标识为空,可以选则指定一个标识,如:YYC_TEST;
SQL> EXEC DBMS_SESSION.SET_IDENTIFIER('YYC_TEST');
PL/SQL procedure successfully completed

步骤二:对客户端标识为YYC_TEST的会话开启trace
新开一个会话2,执行语句:
SQL> EXEC DBMS_MONITOR.CLIENT_ID_TRACE_ENABLE('YYC_TEST', TRUE, TRUE);
PL/SQL procedure successfully completed
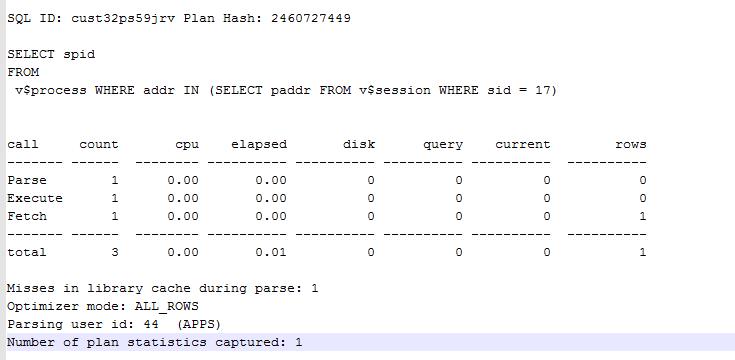
在原本的会话中执行一段查询语句,此语句会被写入trace文件中:
SQL> SELECT spid FROM v$process WHERE addr IN (SELECT paddr FROM v$session WHERE sid = 17);
SPID
------------------------
32113584
如果此时去查看session状态,会发现SQL_TRACE状态依然是FALSE;

注意:虽然SQL_TRACE= DISABLED,但是事实上会话的TRACE已经被启用了,执行的查询SPID的语句将会出现在生成的TRACE文件中。
由于是通过CLIENT_ID方式设置的,因此无法从当前会话的状态中看到。
步骤三:关闭trace;
SQL> EXEC DBMS_MONITOR.CLIENT_ID_TRACE_DISABLE('YYC_TEST');
步骤四:获取trace文件并使用tkprof格式化;
使用sql查看对应的trace文件目录:
SELECT p.*
FROM v$process p, v$session s
WHERE p.addr = s.paddr
AND s.sid = 17;

方法小结:
使用V$session视图获取client_identifier(如果为空,可以使用dbms_session.set_identifier()方法设置),开启/关闭会话trace命令如下:
EXEC DBMS_MONITOR.CLIENT_ID_TRACE_ENABLE('YYC_TEST', TRUE, TRUE);
EXEC DBMS_MONITOR.CLIENT_ID_TRACE_DISABLE('YYC_TEST');
CLIENT_ID开启/关闭统计信息功能
Dbms_monitor除了可以设置trace以外,还可以开启关闭对指定会话的统计功能;统计信息的功能和类似V$MYSTAT视图,可以查看会话的信息;
以 V$MYSTAT 为例,V$MYSTAT提供的只是会话级别的统计,该视图只可以查看当前会话的信息,而CLIENT_ID_STAT_ENABLE提供的是指定客户端标识符的统计功能,任何会话只要设置了指定统计的标识符,都会被累计到统计值之中。而只要更改了CLIENT_IDENTIFIER,这个会话的统计信息就不会再被统计。
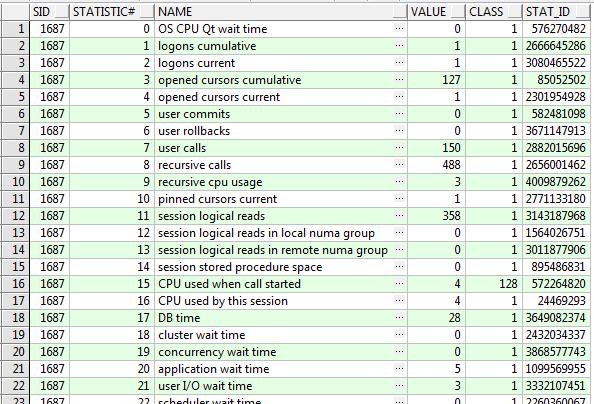
V$MYSTAT是当前用户session的各种统计信息,
sid是session的id,statistic#是统计量的编号(唯一确定统计量的名称),value是统计量的值,可与v$statname配合使用;
SELECT m.sid, m.statistic#, s.name, m.value, s.class, s.stat_id
FROM v$mystat m, v$statname s
WHERE m.statistic# = s.statistic#;
以CLIENT_ID_STAT为例:
步骤一:设置CLIENT_ID = ‘YYC_TEST’,开启统计信息功能:

查看此时会话的统计信息,因为会话并没有开启统计信息功能,因此视图V$CLIENT_STATS内容为空:
SQL> SELECT * FROM V$CLIENT_STATS;
CLIENT_IDENTIFIER STAT_ID STAT_NAME VALUE
-------------------------------------------------------------
设置会话的客户端标识为‘YYC_TEST’,此时视图V$CLIENT_STATS中内容为空:

在另外的会话启动CLIENT_ID为YYC_TEST客户端标识的统计功能,sql如下:
SQL> EXEC DBMS_MONITOR.CLIENT_ID_STAT_ENABLE('YYC_TEST');
PL/SQL procedure successfully completed
步骤二:执行查询语句,通过视图V$CLIENT_STATS查看会话统计信息;
回到开始的会话,此时执行一个查询sql后,检查统计信息:


可以发现视图V$CLIENT_STATS中出现了当前客户端会话的运行内容个,V$CLIENT_STATS的值会随着用户的操作不断的更新;
步骤三:关闭统计信息
可以通过CLIENT_ID_STAT_DISABLE过程关闭;
SQL> EXEC DBMS_MONITOR.CLIENT_ID_STAT_DISABLE('YYC_TEST');
PL/SQL procedure successfully completed
这时V$CLIENT_STAT视图中的统计信息消失;
SQL> SELECT * FROM V$CLIENT_STATS;
CLIENT_IDENTIFIER STAT_ID STAT_NAME VALUE
-------------------------------------------------------------
方法小结:
使用V$session视图获取client_identifier(如果为空,可以使用dbms_session.set_identifier()方法设置),开启/关闭会话统计信息功能:
EXEC DBMS_MONITOR.CLIENT_ID_STAT_ENABLE('YYC_TEST');
EXEC DBMS_MONITOR.CLIENT_ID_STAT_DISABLE('YYC_TEST');
使用V$CLIENT_STATS视图获取会话的统计信息:
SELECT * FROM V$CLIENT_STATS where CLIENT_IDENTIFIER = 'YYC_TEST';
##SERV_MOD_ACT方法开启/关闭统计信息
步骤一:获取SERV,MOD信息,开启统计信息功能

执行SERV_MOD_ACT_STAT_ENABLE过程,对使用PJDEV为服务名的PL/SQL Developer连接设置统计信息
SQL> EXEC DBMS_MONITOR.SERV_MOD_ACT_STAT_ENABLE('PJDEV', 'PL/SQL Developer');
PL/SQL procedure successfully completed
步骤二:使用视图V$SERV_MOD_ACT_STATS查看统计信息:

步骤三:SERV_MOD_ACT_STAT_DISABLE过程关闭统计信息:

和CLIENT_ID方式一样,这种统计信息是对应所有通过指定服务名登陆,且MODULE_NAME与指定的MODULE一致的会话的。
DBMS_MONITOR包提供的两种设置统计信息的方法,都是针对具有相同类型的一组会话,这使得检查或诊断一类用户的行为时,更加的方便,更有针对性。
方法小结:
使用V$session视图获取service_name, module,开启/关闭会话统计信息功能:
EXEC DBMS_MONITOR.SERV_MOD_ACT_STAT_ENABLE('PJDEV', 'PL/SQL Developer');
EXEC DBMS_MONITOR.SERV_MOD_ACT_STAT_DISABLE('PJDEV', 'PL/SQL Developer');
使用V$SERV_MOD_ACT_STATS视图获取会话的统计信息:
SELECT * FROM V$SERV_MOD_ACT_STATS where SERVICE_NAME = 'PJDEV' AND MODULE = 'PL/SQL Developer';
以上是关于trace的产率说明的主要内容,如果未能解决你的问题,请参考以下文章