Tokens-to-Token ViT: Training Vision Transformers from Scratch on ImageNet | 全面超越ResNet
Posted 人工智能博士
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Tokens-to-Token ViT: Training Vision Transformers from Scratch on ImageNet | 全面超越ResNet相关的知识,希望对你有一定的参考价值。

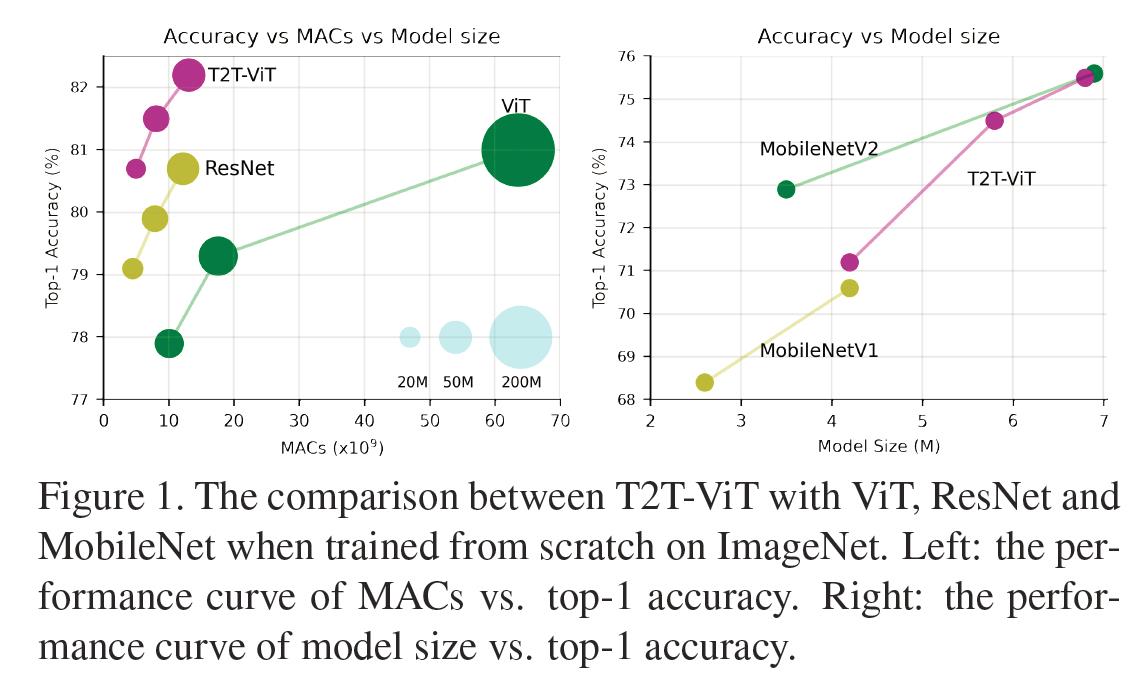
与之前ViT、Detr、Deit等不同之处在于:本文针对ViT的特征多样性、结构化设计等进行了更深入的思考,提出了一种新颖的Tokens-to-Token机制,用于同时建模图像的局部结构信息与全局相关性,同时还借鉴了CNN架构设计思想引导ViT的骨干设计。最终,仅仅依赖于ImageNet数据,而无需JFT-300M预训练,所提方案即可取得全面超越ResNet的性能,且参数量与计算量显著降低;与此同时,在轻量化方面,所提方法只需简单减少深度与隐含层维度即可取得优于精心设计的MobileNet系列方案的性能。
分析发现:(1) 输入图像的简单token化难以很好的建模近邻像素间的重要局部结构(比如边缘、线条等),这就导致了少量样本时的低效性;(2) 在固定计算负载与有限训练样本约束下,ViT中的冗余注意力骨干设计限制了特征的丰富性。
本文的主要贡献包含以下几个方面:
-
首次通过精心设计Transformer结构在标准ImageNet数据集上取得了全面超越CNN的性能,而无需在JFT-300M数据进行预训练;
-
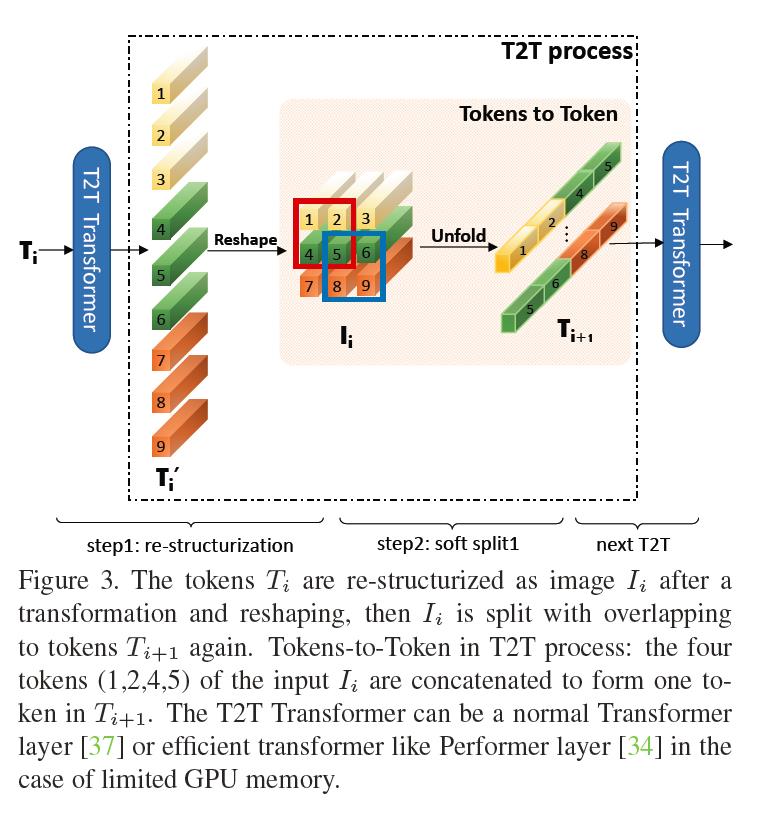
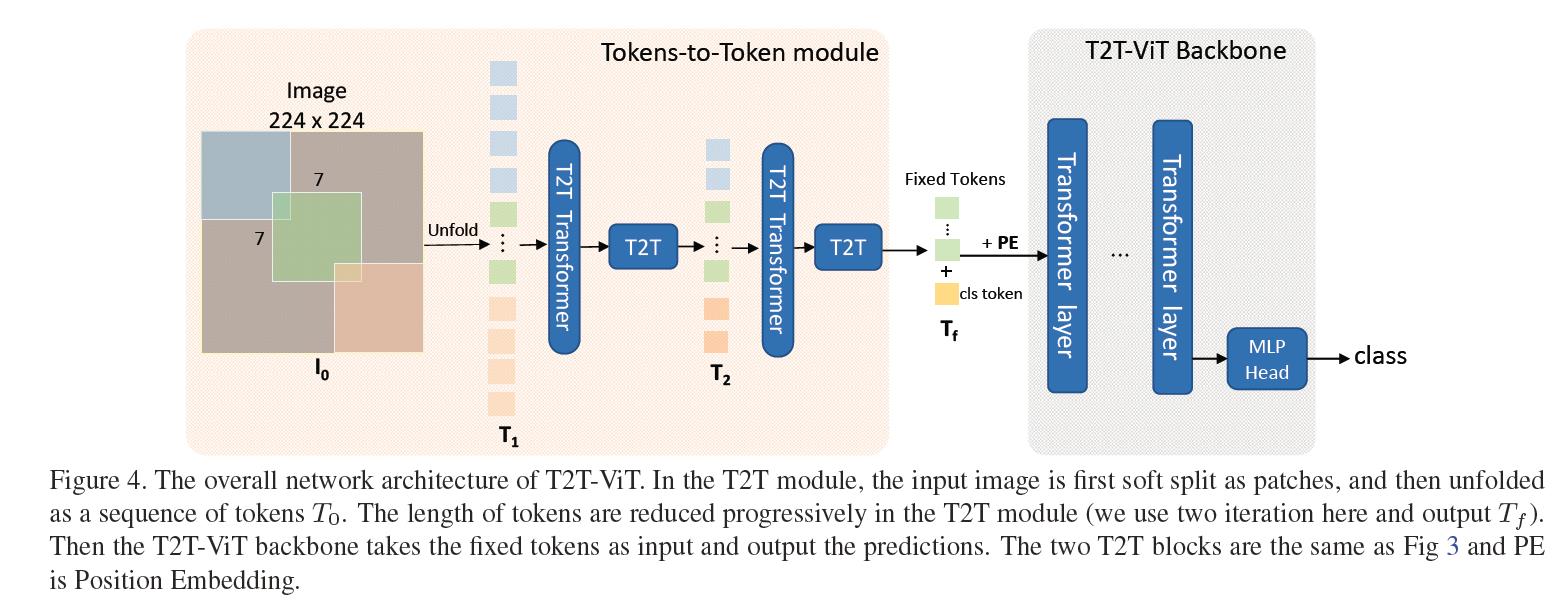
提出一种新颖的渐进式Token化机制用于ViT,并证实了其优越性,所提T2T模块可以更好的协助每个token建模局部重要结构信息;
-
CNN的架构设计思想有助于ViT的骨干结构设计并提升其特征丰富性、减少信息冗余。通过实验发现:
deep-narrow结构设计非常适合于ViT。

以上是关于Tokens-to-Token ViT: Training Vision Transformers from Scratch on ImageNet | 全面超越ResNet的主要内容,如果未能解决你的问题,请参考以下文章