海量数据处理--从分而治之到Mapreduce
Posted xiaoranone
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了海量数据处理--从分而治之到Mapreduce相关的知识,希望对你有一定的参考价值。
海量数据处理常用技术概述
如今互联网产生的数据量已经达到PB级别,如何在数据量不断增大的情况下,依然保证快速的检索或者更新数据,是我们面临的问题。
所谓海量数据处理,是指基于海量数据的存储、处理和操作等。因为数据量太大无法在短时间迅速解决,或者不能一次性读入内存中。
在解决海量数据的问题的时候,我们需要什么样的策略和技术,是每一个人都会关心的问题。今天我们就梳理一下在解决大数据问题
的时候需要使用的技术,但是注意这里只是从技术角度进行分析,只是一种思想并不代表业界的技术策略。
常用到的算法策略
- 分治:多层划分、MapReduce
- 排序:快速排序、桶排序、堆排序
- 数据结构:堆、位图、布隆过滤器、倒排索引、二叉树、Trie树、B树,红黑树
- Hash映射:hashMap、simhash、局部敏感哈希
海量数据处理--从分而治之到Mapreduce
分治
分治是一种算法思想,主要目的是将一个大问题分成多个小问题进行求解,之后合并结果。我们常用到的有归并排序:先分成两部分进行排序,之后在合并,
当然还有其他的很多应用,就比如是我们上篇文章中提到的Top K问题,就是将大文件分成多个小文件进行统计,之后进行合并结果。这里我们对分治进行抽象,
依然从上述提到的Top K频率统计开始出发。定义如下:有M多个Query日志文件记录,要求得到Top K的Query。
我们可以抽象成几个步骤:
- 多个文件的输入,我们叫做input splits
- 多进程同时处理多个文档,我们叫做map。
- partition 从上文中我们知道。因为我们要将相同的Query映射的一起
- 多进程处理划分或的文件,我们叫做reduce
- 合并过个文件的结果,我们叫做merge
上面的这四个步骤是我们从Top K问题抽象出来的,为什么我们对每一步进行一个取名字?因为这就是最简单的MapReduce的原理。我们现在就可以认为之前已经
用过Mapreduce的思想了,它就是这么简单,当然中的很多问题我都没有提出来,但是主要的思想就是这样,很成熟的MapReduce的实现,有Hadoop和CouchDB等。
我给出一张图片来表示这个过程。
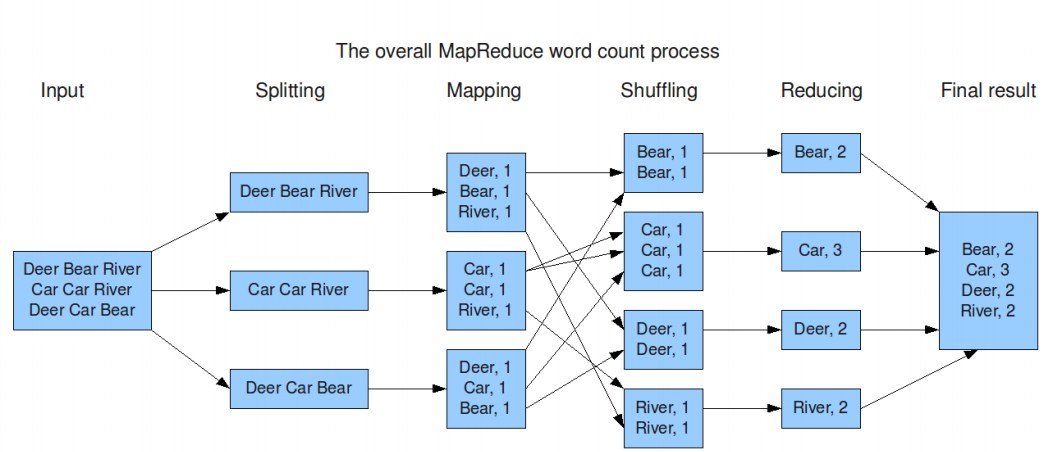
MapReduce
MapReduce是一种编程模式、大数据框架的并行处理接口和分布式算法计算平台,主要用于大规模数据集合的并行计算。一个Mapreduce的程序主要有两部分组成: map和reduce. 它主要借鉴了函数式编程语言和矢量编程语言特性。
MapReduce最早是由Google公司研究提出的一种面向大规模数据处理的并行计算模型和方法。Google公司设计MapReduce的初衷主要是为了解决其搜索引擎中大规模网页数据的并行化处理。
MapReduce组成
- Map:
用户根据需求设置的Map函数,每一个工作节点(主机)处理本地的数据,将结果写入临时文件,给调用Reduce函数的节点使用。
- Shuffle:
在MapReduce的编程模式中,我们要时刻注意到数据结构是(key, value)对,Shuffle就是打乱数据,也是我们之前提到过的Partition处理,主要目的是将相同的key的数据映射到同一个Reduce工作的节点(这是主要的功能,当然还有其他的功能)。
- Reduce:
Reduce函数,并行处理相同key的函数,返回结果。
Mapreduce模式这么流行,现在几乎所有的大公司都在使用Hadoop框架,当然可能会有一些优化,不过主要的思想依然是MapReduce模式。在公司中或者个人的使用的时候,我们一般会先搭建Hadoop环境,之后最简单的使用就是提供Map函数和Reduce函数即可,语言可以使用C++、Java、Python等。例如我们提到的Top k问题的伪代码的例子:
```
map(String key, String values):
// key: 文档名字
// values: 文档内容
for each line in values:
EmitIntemediate(line, "1")
..... // 这中间的省略号,表示还可以加一些代码,
..... // 不加也不影响结果,只是效率问题,后面会提到
reduce(String key, Iterator values):
// key: a query
// values: a lists of counts
int result = 0;
for each v in values:
result += ParseInt(v)
Emit(AsString(result))
```
代码抽象
map: (k1, v1) —> list(k2, v2)
reduce: (k2, list(v2)) —> list(v3)
MapReduce支持的数据格式,从上述的代码中,我们可以看到MapReduce的输入和输出都是(k, v)对的格式。当然这只是转换之后的格式,一般来书我们的输入文件都是文件,MapReduce认为第一个分隔符之前的字段是key,后面的values,(values可以不存在,例如我们的Top k问题就没有values)。所有在使用的时候,我们只需要用分隔符空格将key和values分开,每一行代表一个数据,提供我们需要的Map和Reduce函数即可。
文章到此应该已经可以结束了,我们可以在任何MapReduce框架下,根据需求写出map函数和reduce函数。对于想用使用MapReduce的程序员来说,在写函数的时候只需要注意key和value怎么设置,如何编写map和reduce函数,因为中间的细节,运行的框架已经帮我们封装的很好的,这就是为什么Mapreduce在业界流行。这种编程模式很简单,只要提map和reduce函数,对于那些没有并行计算和分布式处理经验的程序员,MapReduce框架帮我们处理好了并行计算、错误容忍、本地读取优化和加载平衡的细节,我们只需要关注业务,不用关心细节,还有就是这么编程模式可以简单的解决很多常见的问题,例如: linux中的grep命令,Sort,Top K,倒排索引等问题。
知其然而知其所以然,不仅更能帮助我们写出更优的代码,更重要的是如何在改进现有的技术,使其更好的应用到我们的业务上,因为很多大公司都会重写这种代码,使其在公司内部更好的应用。
浅谈技术细节
MapReduce模式下我们需要关注的问题如下(参考论文):
- 数据和代码如何存储?
设置一个Master,拷贝代码文件,分配给节点进行处理,指定Map或者Reduce已经输入和输出文件的路径。所有Master节点是一个管理节点负责调度。
- 如何Shuffle?
在MapReduce中都是(key, values)数据,输入的M个文件直接对应M的Map,产生的中间结果key2,通过哈希函数,
hash(key) % R(R是Reduce的个数)。当然我们需要设置一个好的hash函数,保证任务不平衡分到不同的Reduce节点上。
- 节点之间如何通信?
Master负责调度和通信,其他节点之和Master节点通信,master监控所有节点的信息,比如是map或者reduce任务,是否运行结束,占用的资源、文件读写速度等,master会重新分配那些已经完成的节点任务,对所有的错误的节点重新执行。
- 节点出现错误如何解决?
因为有master的存在,可以重新执行出现错误的运行节点,注意的是对于出错的map任务,其分配到的reduce任务也要重新执行。节点运行bug,我们可以修改代码,使其更鲁棒,但是有时候我们必须使用try-catch操作跳过一些错误的bad lines.
- Map和Reduce个数如何设置?
这个设置和集群的个数和经验有很大关系,建议我们每一个map任务的输入数据16-64MB, 因此map的个数 = 总的文件大小 / 16-64MB. reduce的个数建议大于节点的个数,这样可以保证更好的并行计算。
- 怎么控制负载平衡?
master会监控所有节点的运行状态,并且要对所有的运行完成的节点重新分配任务,来保证负载均衡,需要注意的是这里的并行计算是map和reduce的分别并行计算,必须保证map执行之后才能执行reduce(因为你有shuffle操作)。
- 技巧
- map任务运行时候尽可能的读取本地或者当前局域内的文件,减少文件传输的网络带宽
- M和R的设置会对master的监督有一定的影响,因为要监督所有的状态
- 备份运行状态很重要,可以知道那台节点运行的缓慢,可能出现异常,可以让其他节点代替它运行任务
- shuffle操作的hash函数真的很重要,可以有效的解决负载均衡
- map生成的中间文件要根据key进行排序,也可以便于划分
- map和reduce之间有时候需要加合并(combiner)操作,可以起到加速作用
参考
以上是关于海量数据处理--从分而治之到Mapreduce的主要内容,如果未能解决你的问题,请参考以下文章