hadoop生态之hive
Posted 运维Linux和python
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hadoop生态之hive相关的知识,希望对你有一定的参考价值。
序言
大数据的生态包含各种各样的组件,hive是其中之一,hive主要是作为数据仓库的工具,简化相关人员的代码工作,只要编写简单的SQL就可以实现mapreduce效果。
hive是建立在hadoop之上的,也就是将海量的数据存储在HDFS之中,而对于数据的分析和计算则是借助mapreduce。
HIVE
1 hive的作用及组成部分
hive主要是将用户编写的SQL语句,进行词法分析,语法解析,最后将SQL转变成mapreduce程序在hadoop之中执行,最后拿到结果返回给用户。
hive将hdfs中的结构化文件映射成数据库,表,从而需要一个元数据中心保存相关的信息,一般保存在mysql中,这部分主要就是metastore;hive的服务端提供提供编译器,执行器,根据mr的模板程序将sql转变为mr程序,然后由执行器将job提交给yarn进行调度,读取hdfs的数据,运行mapreduce程序。
hive本身是不提供计算引擎,在低版本中,主要是mapreduce来负责,不过这个map阶段,shuffle阶段,reduce阶段都是需要大量的磁盘读写,性能不高,从而有了tez计算框架,使用DAG有向无环图的方式来进行各个阶段的复用,从而能提升部分性能,比较推荐的是使用spark的计算引擎,这种全部都是内存的操作,从而能大大提升性能。
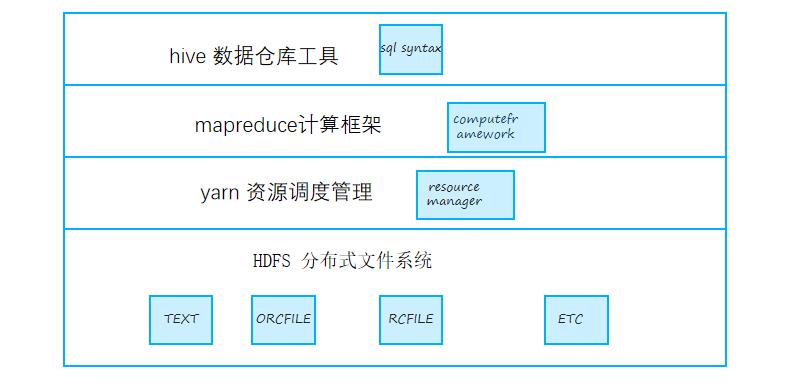
hive主要适合于离线数据的批量计算,也就是通常所说的batch computing,适合于数据的转换处理。
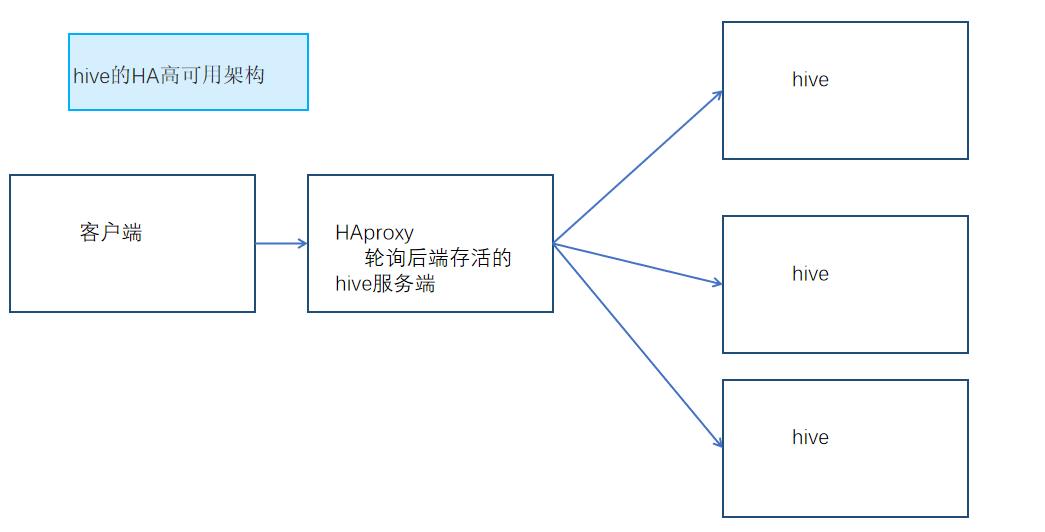
hive的高可用架构比较简单,也就是后端同时运行几个hive服务,反正自己也不用保存啥数据,因为需要保存的数据都是元数据,持久化存储在mysql中。

2 hive的配置
hive首先需要一个metstore,也就是元数据存储的地方,一般使用mysql主从来实现,可以查看保存在其中的元数据信息。
mysql> use hive;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> SELECT * FROM VERSION;
+--------+----------------+----------------------------+
| VER_ID | SCHEMA_VERSION | VERSION_COMMENT |
+--------+----------------+----------------------------+
| 1 | 1.2.0 | Hive release version 1.2.0 |
+--------+----------------+----------------------------+
1 row in set (0.00 sec)
mysql> SELECT * FROM DBS;
+-------+-----------------------+--------------------------------------+---------+------------+------------+
| DB_ID | DESC | DB_LOCATION_URI | NAME | OWNER_NAME | OWNER_TYPE |
+-------+-----------------------+--------------------------------------+---------+------------+------------+
| 1 | Default Hive database | hdfs://ns/user/hive/warehouse | default | public | ROLE |
| 2 | NULL | hdfs://ns/user/hive/warehouse/kel.db | kel | root | USER |
+-------+-----------------------+--------------------------------------+---------+------------+------------+
2 rows in set (0.01 sec)
mysql> SELECT * FROM PARTITIONS;
+---------+-------------+------------------+---------------------------+-------+--------+----------------+
| PART_ID | CREATE_TIME | LAST_ACCESS_TIME | PART_NAME | SD_ID | TBL_ID | LINK_TARGET_ID |
+---------+-------------+------------------+---------------------------+-------+--------+----------------+
| 1 | 1613477304 | 0 | country=CHINA | 13 | 12 | NULL |
| 2 | 1613477401 | 0 | country=USA | 14 | 12 | NULL |
| 3 | 1613478060 | 0 | dt=2021%2F02%2F16/hour=12 | 16 | 13 | NULL |
| 4 | 1613478129 | 0 | dt=2021%2F02%2F16/hour=11 | 17 | 13 | NULL |
| 5 | 1613478134 | 0 | dt=2021%2F02%2F17/hour=11 | 18 | 13 | NULL |
+---------+-------------+------------------+---------------------------+-------+--------+----------------+
5 rows in set (0.00 sec)
在安装hive的时候,会自动初始化这个元数据库,各个表之间的关系可以在官网上查看到。
//hive和hadoop的联系
[root@KEL1 conf]# grep hadoop hive-env.sh
# Set HADOOP_HOME to point to a specific hadoop install directory
HADOOP_HOME=/opt/module/hadoop-2.7.2
//hive连接元数据库配置
[root@KEL1 conf]# cat hive-site.xml
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
</property>
//防止远程会话超时断开
<property>
<name>hive.server2.idle.session.timeout</name>
<value>0</value>
</property>
<property>
<name>hive.server2.idle.operation.timeout</name>
<value>0</value>
</property>
<property>
<name>hive.server2.session.check.interval</name>
<value>0</value>
</property>
</configuration>
启动hive之后,可以看到如下的进程:
[root@KEL1 conf]# jps
2321 QuorumPeerMain
12321 Jps
2610 JournalNode
2455 DataNode
3050 RunJar
2555 NodeManager
2382 NameNode
2911 ResourceManager
[root@KEL1 conf]# ps -ef|grep 3050
root 3050 2275 0 Feb16 pts/0 00:01:15 /opt/module/jdk1.8.0_181//bin/java -Xmx256m -Djava.net.preferIPv4Stack=true -Dhadoop.log.dir=/opt/module/hadoop-2.7.2/logs -Dhadoop.log.file=hadoop.log -Dhadoop.home.dir=/opt/module/hadoop-2.7.2 -Dhadoop.id.str=root -Dhadoop.root.logger=INFO,console -Djava.library.path=/opt/module/hadoop-2.7.2/lib/native -Dhadoop.policy.file=hadoop-policy.xml -Djava.net.preferIPv4Stack=true -Xmx512m -Dhadoop.security.logger=INFO,NullAppender org.apache.hadoop.util.RunJar /opt/module/apache-hive-1.2.2/lib/hive-service-1.2.2.jar org.apache.hive.service.server.HiveServer2
root 12332 2294 0 05:43 pts/1 00:00:00 grep --color=auto 3050
[root@KEL1 conf]# netstat -tnlp|grep 3050
tcp 0 0 0.0.0.0:10000 0.0.0.0:* LISTEN 3050/java
远程连接如下所示:
[root@KEL2 bin]# ./beeline
Beeline version 1.2.2 by Apache Hive
beeline> ! connect jdbc:hive2://kel1:10000
Connecting to jdbc:hive2://kel1:10000
Enter username for jdbc:hive2://kel1:10000: root
Enter password for jdbc:hive2://kel1:10000: ****
Connected to: Apache Hive (version 1.2.2)
Driver: Hive JDBC (version 1.2.2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://kel1:10000> show databases;
+----------------+--+
| database_name |
+----------------+--+
| default |
| kel |
+----------------+--+
2 rows selected (0.214 seconds)
0: jdbc:hive2://kel1:10000>
远程连接的时候,只要把相关的hive包传输到远程机器上,使用beeline进行连接即可。
安装的时候,由于hive是用java写的,从而要在lib中加上连接mysql的驱动程序。
[root@KEL1 lib]# pwd
/opt/module/apache-hive-1.2.2/lib
[root@KEL1 lib]# ls -l mysql-connector-java.jar
-rw-r--r-- 1 root root 2407112 Feb 15 19:15 mysql-connector-java.jar
如果是通过rpm包安装的方式安装的驱动,那么可以通过如下方式找到驱动的jar包,然后拷贝到lib目录中。
[root@KEL1 lib]# rpm -qa |grep java|grep mysql
mysql-connector-java-8.0.23-1.el7.noarch
[root@KEL1 lib]# rpm -ql mysql-connector-java|grep jar
/usr/share/java/mysql-connector-java.jar
当启动的时候,如果出现如下报错:
java.sql.SQLException: No suitable driver found for jdbc://localhost:3306/hive?createDtabaseIfNotExist=true
at java.sql.DriverManager.getConnection(DriverManager.java:689)
at java.sql.DriverManager.getConnection(DriverManager.java:208)
at com.jolbox.bonecp.BoneCP.obtainRawInternalConnection(BoneCP.java:361)
at com.jolbox.bonecp.BoneCP.<init>(BoneCP.java:416)
at com.jolbox.bonecp.BoneCPDataSource.getConnection(BoneCPDataSource.java:120)
at org.datanucleus.store.rdbms.ConnectionFactoryImpl$ManagedConnectionImpl.getConnection(ConnectionFactoryImpl.java:501)
at org.datanucleus.store.rdbms.RDBMSStoreManager.<init>(RDBMSStoreManager.java:298)
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at org.datanucleus.plugin.NonManagedPluginRegistry.createExecutableExtension(NonManagedPluginRegistry.java:631)
at org.datanucleus.plugin.PluginManager.createExecutableExtension(PluginManager.java:301)
at org.datanucleus.NucleusContext.createStoreManagerForProperties(NucleusContext.java:1187)
at org.datanucleus.NucleusContext.initialise(NucleusContext.java:356)
at org.datanucleus.api.jdo.JDOPersistenceManagerFactory.freezeConfiguration(JDOPersistenceManagerFactory.java:775)
at org.datanucleus.api.jdo.JDOPersistenceManagerFactory.createPersistenceManagerFactory(JDOPersistenceManagerFactory.java:333)
at org.datanucleus.api.jdo.JDOPersistenceManagerFactory.getPersistenceManagerFactory(JDOPersistenceManagerFactory.java:202)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
可能是因为jdbc的连接字符串中缺少mysql,也就是配置文件出错。
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value>
</property>
如果出现报错,说元数据库中的表不存在:
2021-02-15 19:27:12,717 ERROR [main]: DataNucleus.Datastore (Log4JLogger.java:error(115)) - Error thrown executing ALTER TABLE `PARTITIONS` ADD COLUMN `TBL_ID` BIGINT NULL : Table 'hive.PARTITIONS' doesn't exist
java.sql.SQLSyntaxErrorException: Table 'hive.PARTITIONS' doesn't exist
at com.mysql.cj.jdbc.exceptions.SQLError.createSQLException(SQLError.java:120)
at com.mysql.cj.jdbc.exceptions.SQLExceptionsMapping.translateException(SQLExceptionsMapping.java:122)
at com.mysql.cj.jdbc.StatementImpl.executeInternal(StatementImpl.java:762)
at com.mysql.cj.jdbc.StatementImpl.execute(StatementImpl.java:646)
at com.jolbox.bonecp.StatementHandle.execute(StatementHandle.java:254)
at org.datanucleus.store.rdbms.table.AbstractTable.executeDdlStatement(AbstractTable.java:760)
at org.datanucleus.store.rdbms.table.AbstractTable.executeDdlStatementList(AbstractTable.java:711)
at org.datanucleus.store.rdbms.table.TableImpl.validateColumns(TableImpl.java:259)
at org.datanucleus.store.rdbms.RDBMSStoreManager$ClassAdder.performTablesValidation(RDBMSStoreManager.java:3393)
at org.datanucleus.store.rdbms.RDBMSStoreManager$ClassAdder.addClassTablesAndValidate(RDBMSStoreManager.java:3190)
at org.datanucleus.store.rdbms.RDBMSStoreManager$ClassAdder.run(RDBMSStoreManager.java:2841)
at org.datanucleus.store.rdbms.AbstractSchemaTransaction.execute(AbstractSchemaTransaction.java:122)
at org.datanucleus.store.rdbms.RDBMSStoreManager.addClasses(RDBMSStoreManager.java:1605)
at org.datanucleus.store.AbstractStoreManager.addClass(AbstractStoreManager.java:954)
at org.datanucleus.store.rdbms.RDBMSStoreManager.getDatastoreClass(RDBMSStoreManager.java:679)
at org.datanucleus.store.rdbms.query.RDBMSQueryUtils.getStatementForCandidates(RDBMSQueryUtils.java:408)
at org.datanucleus.store.rdbms.query.JDOQLQuery.compileQueryFull(JDOQLQuery.java:947)
可能是内部derby数据库或者是其他操作导致数据丢失,可以进行重新初始化源数据库。
./schematool -dbType mysql -initSchema
3 hive执行mr程序
简单程序是不需要进行mr的,如下:
0: jdbc:hive2://kel1:10000> select * from t_t2;
+----------+------------+-----------+--+
| t_t2.id | t_t2.name | t_t2.age |
+----------+------------+-----------+--+
| 1 | kel | 33 |
| 2 | tom | 33 |
+----------+------------+-----------+--+
2 rows selected (0.218 seconds)
一看这个,这不就是个数据库么。。。不过对于大量数据来说,延迟还是很高的,比不上RDBMS,而且不能修改数据,只能进行查询统计分析。
0: jdbc:hive2://kel1:10000> select count(*) from t_t1;
INFO : Number of reduce tasks determined at compile time: 1
INFO : In order to change the average load for a reducer (in bytes):
INFO : set hive.exec.reducers.bytes.per.reducer=<number>
INFO : In order to limit the maximum number of reducers:
INFO : set hive.exec.reducers.max=<number>
INFO : In order to set a constant number of reducers:
INFO : set mapreduce.job.reduces=<number>
INFO : number of splits:2
INFO : Submitting tokens for job: job_1613471830232_0007
INFO : The url to track the job: http://KEL2:8088/proxy/application_1613471830232_0007/
INFO : Starting Job = job_1613471830232_0007, Tracking URL = http://KEL2:8088/proxy/application_1613471830232_0007/
INFO : Kill Command = /opt/module/hadoop-2.7.2/bin/hadoop job -kill job_1613471830232_0007
INFO : Hadoop job information for Stage-1: number of mappers: 2; number of reducers: 1
INFO : 2021-02-17 05:56:10,859 Stage-1 map = 0%, reduce = 0%
INFO : 2021-02-17 05:56:24,718 Stage-1 map = 17%, reduce = 0%, Cumulative CPU 10.01 sec
INFO : 2021-02-17 05:56:27,157 Stage-1 map = 50%, reduce = 0%, Cumulative CPU 13.7 sec
INFO : 2021-02-17 05:56:28,303 Stage-1 map = 67%, reduce = 0%, Cumulative CPU 16.39 sec
INFO : 2021-02-17 05:56:30,426 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 17.89 sec
INFO : 2021-02-17 05:56:36,589 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 19.27 sec
INFO : MapReduce Total cumulative CPU time: 19 seconds 270 msec
INFO : Ended Job = job_1613471830232_0007
+-----------+--+
| _c0 |
+-----------+--+
| 58405614 |
+-----------+--+
1 row selected (41.96 seconds)
复杂的查询,会经历一个完整的mr程序,而且可以在jobhistory中查看到mr的执行。

不是每一个SQL的执行都会经历MR过程,要不然你从各种日志去查。。。是根本查不到的。
//查看hive的执行引擎,此处为MapReduce
0: jdbc:hive2://kel1:10000> set hive.execution.engine;
+---------------------------+--+
| set |
+---------------------------+--+
| hive.execution.engine=mr |
+---------------------------+--+
1 row selected (0.011 seconds)
4 网上的一些例子
创建内部表,复杂数据类型的支持:
[root@KEL1 hdfsdata]# cat map
1,kel,唱歌:非常喜欢-跳舞:喜欢-游泳:一般
2,tom,打游戏:非常喜欢-跳舞:喜欢-游泳:一般
[root@KEL1 hdfsdata]# hdfs dfs -put map /user/hive/warehouse/kel.db/usermapc
0: jdbc:hive2://kel1:10000> create table usermap(id int,name string,hobby map<string,string>)
0: jdbc:hive2://kel1:10000> row format delimited
0: jdbc:hive2://kel1:10000> fields terminated by ','
0: jdbc:hive2://kel1:10000> collection items terminated by'-'
0: jdbc:hive2://kel1:10000> map keys terminated by ":";
No rows affected (0.41 seconds)
0: jdbc:hive2://kel1:10000> show tables;
+-----------+--+
| tab_name |
+-----------+--+
| t_t1 |
| t_t2 |
| usermap |
+-----------+--+
3 rows selected (0.064 seconds)
0: jdbc:hive2://kel1:10000> select * from usermap;
+-------------+---------------+--------------------------------------+--+
| usermap.id | usermap.name | usermap.hobby |
+-------------+---------------+--------------------------------------+--+
| 1 | kel | "唱歌":"非常喜欢","跳舞":"喜欢","游泳":"一般" |
| 2 | tom | "打游戏":"非常喜欢","跳舞":"喜欢","游泳":"一般" |
+-------------+---------------+--------------------------------------+--+
2 rows selected (0.312 seconds)
分区表,分区的字段是在进行load导入数据的时候指定的:
[root@KEL2 hdfsdata]# cat user
1,kel
2,tom
3,jun
0: jdbc:hive2://kel1:10000> create table ods_user(id int,name string) partitioned by (country string) row format delimited fields terminated by ',';
0: jdbc:hive2://kel1:10000> load data local inpath '/opt/module/apache-hive-1.2.2/hdfsdata/user' into table ods_user partition(country='CHINA');
INFO : Loading data to table kel.ods_user partition (country=CHINA) from file:/opt/module/apache-hive-1.2.2/hdfsdata/user
INFO : Partition kel.ods_usercountry=CHINA stats: [numFiles=1, numRows=0, totalSize=18, rawDataSize=0]
No rows affected (1.201 seconds)
0: jdbc:hive2://kel1:10000> select * from ods_user;
+--------------+----------------+-------------------+--+
| ods_user.id | ods_user.name | ods_user.country |
+--------------+----------------+-------------------+--+
| 1 | kel | CHINA |
| 2 | tom | CHINA |
| 3 | jun | CHINA |
+--------------+----------------+-------------------+--+
3 rows selected (0.196 seconds
分区的时候,就是按照分区进行了一个目录的整理,相当于对数据进行了一个分割目录存放。

二级分区:
0: jdbc:hive2://kel1:10000> create table ods_user_day(id int,name string) partitioned by (dt string,hour string) row format delimited fields terminated by ',';
No rows affected (0.185 seconds)
0: jdbc:hive2://kel1:10000> select * from ods_user_day;
+------------------+--------------------+------------------+--------------------+--+
| ods_user_day.id | ods_user_day.name | ods_user_day.dt | ods_user_day.hour |
+------------------+--------------------+------------------+--------------------+--+
+------------------+--------------------+------------------+--------------------+--+
No rows selected (0.14 seconds)
0: jdbc:hive2://kel1:10000> load data local inpath '/opt/module/apache-hive-1.2.2/hdfsdata/user' into table ods_user_day partition(dt='2021/02/16',hour='12');
INFO : Loading data to table kel.ods_user_day partition (dt=2021/02/16, hour=12) from file:/opt/module/apache-hive-1.2.2/hdfsdata/user
INFO : Partition kel.ods_user_daydt=2021/02/16, hour=12 stats: [numFiles=1, numRows=0, totalSize=18, rawDataSize=0]
No rows affected (0.772 seconds)
0: jdbc:hive2://kel1:10000> select * from ods_user_day;
+------------------+--------------------+------------------+--------------------+--+
| ods_user_day.id | ods_user_day.name | ods_user_day.dt | ods_user_day.hour |
+------------------+--------------------+------------------+--------------------+--+
| 1 | kel | 2021/02/16 | 12 |
| 2 | tom | 2021/02/16 | 12 |
| 3 | jun | 2021/02/16 | 12 |
+------------------+--------------------+------------------+--------------------+--+
3 rows selected (0.174 seconds)
二级分区就是按照分区进行了二级目录的数据整理。

数据分桶,主要为了提高join的查询效率:
0: jdbc:hive2://kel1:10000> set hive.enforce.bucketing;
+-------------------------------+--+
| set |
+-------------------------------+--+
| hive.enforce.bucketing=false |
+-------------------------------+--+
1 row selected (0.014 seconds)
0: jdbc:hive2://kel1:10000> set hive.enforce.bucketing=true;
No rows affected (0.008 seconds)
0: jdbc:hive2://kel1:10000> set mapreduce.job.reduces;
+--------------------------+--+
| set |
+--------------------------+--+
| mapreduce.job.reduces=2 |
+--------------------------+--+
1 row selected (0.009 seconds)
0: jdbc:hive2://kel1:10000> set mapreduce.job.reduces=4
0: jdbc:hive2://kel1:10000> ;
No rows affected (0.004 seconds)
0: jdbc:hive2://kel1:10000> create table ods_bucket(id int,name string,sex string,age int)
0: jdbc:hive2://kel1:10000> clustered by(id)
0: jdbc:hive2://kel1:10000> sorted by (id desc)
0: jdbc:hive2://kel1:10000> into 4 buckets
0: jdbc:hive2://kel1:10000> row format delimited fields terminated by ',';
No rows affected (0.161 seconds)
0: jdbc:hive2://kel1:10000> select * from ods_bucket;
+----------------+------------------+-----------------+-----------------+--+
| ods_bucket.id | ods_bucket.name | ods_bucket.sex | ods_bucket.age |
+----------------+------------------+-----------------+-----------------+--+
+----------------+------------------+-----------------+-----------------+--+
No rows selected (0.221 seconds)
0: jdbc:hive2://kel1:10000>
[root@KEL2 hdfsdata]# cat bucket
11,kel,femail,20
322,tom,mail,32
分桶的数量主要是和mr的数量一致,指定分桶的字段进行哈希取值,从而相同的进行分在一起,最终结果如下:

分桶的数据导入需要临时表:
0: jdbc:hive2://kel1:10000> load data local inpath '/opt/module/apache-hive-1.2.2/hdfsdata/bucket'into table ods_tmp_bucket;;
INFO : Loading data to table kel.ods_tmp_bucket from file:/opt/module/apache-hive-1.2.2/hdfsdata/bucket
INFO : Table kel.ods_tmp_bucket stats: [numFiles=1, totalSize=33]
No rows affected (0.428 seconds)
0: jdbc:hive2://kel1:10000> insert overwrite table ods_bucket select * from ods_tmp_bucket cluster by (id);
INFO : Number of reduce tasks determined at compile time: 4
INFO : In order to change the average load for a reducer (in bytes):
INFO : set hive.exec.reducers.bytes.per.reducer=<number>
INFO : In order to limit the maximum number of reducers:
INFO : set hive.exec.reducers.max=<number>
INFO : In order to set a constant number of reducers:
INFO : set mapreduce.job.reduces=<number>
INFO : number of splits:1
INFO : Submitting tokens for job: job_1613471830232_0006
INFO : The url to track the job: http://KEL2:8088/proxy/application_1613471830232_0006/
INFO : Starting Job = job_1613471830232_0006, Tracking URL = http://KEL2:8088/proxy/application_1613471830232_0006/
INFO : Kill Command = /opt/module/hadoop-2.7.2/bin/hadoop job -kill job_1613471830232_0006
INFO : Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 4
INFO : 2021-02-16 21:12:10,818 Stage-1 map = 0%, reduce = 0%
INFO : 2021-02-16 21:12:23,172 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.93 sec
INFO : 2021-02-16 21:12:41,606 Stage-1 map = 100%, reduce = 25%, Cumulative CPU 4.6 sec
INFO : 2021-02-16 21:12:43,831 Stage-1 map = 100%, reduce = 50%, Cumulative CPU 7.79 sec
INFO : 2021-02-16 21:12:46,199 Stage-1 map = 100%, reduce = 83%, Cumulative CPU 12.49 sec
INFO : 2021-02-16 21:12:49,722 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 14.61 sec
INFO : MapReduce Total cumulative CPU time: 14 seconds 610 msec
INFO : Ended Job = job_1613471830232_0006
INFO : Loading data to table kel.ods_bucket from hdfs://ns/user/hive/warehouse/kel.db/ods_bucket/.hive-staging_hive_2021-02-16_21-11-54_234_1896420245480628354-1/-ext-10000
INFO : Table kel.ods_bucket stats: [numFiles=4, numRows=26, totalSize=423, rawDataSize=397]
No rows affected (58.564 seconds)
0: jdbc:hive2://kel1:10000> select * from ods_bucket;
在进行load数据的时候,本地的数据必须位于启动的机器上,也就是hiveserver的本地目录中,而不是beeline连接的服务器的本地目录中:
0: jdbc:hive2://kel1:10000> load data local inpath '/opt/module/apache-hive-1.2.2/hdfsdata/bucket'into table ods_tmp_bucket;
Error: Error while compiling statement: FAILED: SemanticException Line 1:23 Invalid path ''/opt/module/apache-hive-1.2.2/hdfsdata/bucket'': No files matching path file:/opt/module/apache-hive-1.2.2/hdfsdata/bucket (state=42000,code=40000)
一些显示命令:
0: jdbc:hive2://kel1:10000> show partitions ods_user;
+----------------+--+
| partition |
+----------------+--+
| country=CHINA |
| country=USA |
+----------------+--+
2 rows selected (0.132 seconds)
0: jdbc:hive2://kel1:10000> desc formatted ods_user;
0: jdbc:hive2://kel1:10000> describe extended ods_user;
0: jdbc:hive2://kel1:10000> describe database kel;
+----------+----------+---------------------------------------+-------------+-------------+-------------+--+
| db_name | comment | location | owner_name | owner_type | parameters |
+----------+----------+---------------------------------------+-------------+-------------+-------------+--+
| kel | | hdfs://ns/user/hive/warehouse/kel.db | root | USER | |
+----------+----------+---------------------------------------+-------------+-------------+-------------+--+
1 row selected (0.042 seconds)
hive最好的地方就是不用使用mr来写java代码了,能写SQL的,就不要写code了,毕竟BUG多。
以上是关于hadoop生态之hive的主要内容,如果未能解决你的问题,请参考以下文章