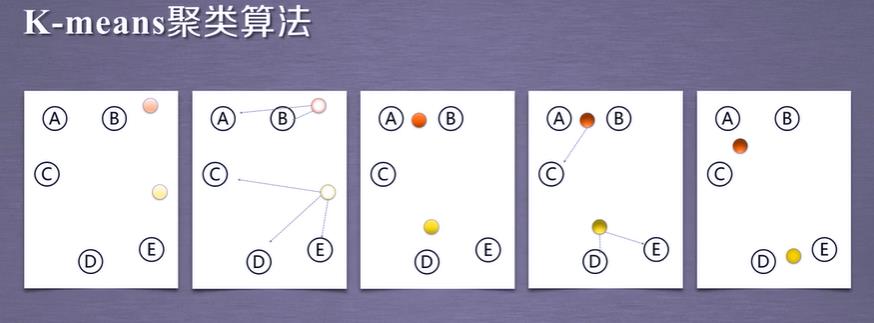
机器学习 sklearn 无监督学习 聚类算法 K-means
Posted 404detective
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习 sklearn 无监督学习 聚类算法 K-means相关的知识,希望对你有一定的参考价值。

import matplotlib.pyplot as plt
from sklearn.datasets.samples_generator import make_blobs
from sklearn.cluster import KMeans
# 生成测试数据
# X为样本特征,Y为样本簇类别,共1000个样本,每个样本2个特征,对应x和y轴,共4个簇,
# 簇中心在[-1,-1], [0,0],[1,1], [2,2], 簇方差分别为[0.4, 0.2, 0.2]
X, y = make_blobs(n_samples=1000, n_features=2 , centers=[[-1, -1], [0, 0], [1, 1], [2, 2]],
cluster_std=[0.4, 0.2, 0.2, 0.2], random_state=10)
#默认max_iter=300
y_pred = KMeans(n_clusters=4).fit_predict(X)
plt.figure(figsize=(12, 6))
plt.subplot(121)
plt.xlim((-3,3))
plt.ylim((-3,3))
plt.xlabel('X1')
plt.ylabel('X2')
plt.scatter(X[:, 0], X[:, 1], c=y_pred)
plt.subplot(122)
plt.xlim((-3,3))
plt.ylim((-3,3))
plt.xlabel('X1')
plt.ylabel('X2')
plt.scatter(X[:, 0], X[:, 1], c=y)
plt.show()
cluster_std=[0.7, 0.7, 0.7, 0.7]

cluster_std=[0.7, 0.7, 0.7, 0.7]

应用

from sklearn.cluster import KMeans
import sklearn
def loadData(filePath):
fr = open(filePath,'r+')
lines = fr.readlines()
retData = []
retCityName = []
for line in lines:
items = line.strip().split(",")
retCityName.append(items[0])
retData.append([float(items[i])
for i in range(1 ,len(items))])
return retData,retCityName
data,city=loadData("E:\\Desktop\\python_code\\sklearn\\课程数据\\聚类\\city.txt")
y_pred = KMeans(n_clusters=4).fit_predict(data)
CityCluster = [[],[],[],[]]
for i in range(len(city)):
CityCluster[y_pred[i]].append(city[i])
for i in range(len(CityCluster)):
print(CityCluster[i])
运行多次 北上广总在一类

以上是关于机器学习 sklearn 无监督学习 聚类算法 K-means的主要内容,如果未能解决你的问题,请参考以下文章