目标检测系列 Mask R-CNN—图片预处理
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了目标检测系列 Mask R-CNN—图片预处理相关的知识,希望对你有一定的参考价值。
参考技术A在图片输入到神经网络前需要进行有些必要预处理工作。
减去均值 :均值向量(3 X 1,为每个颜色通道的均值)是所有训练图像上像素值的均值,并且在测试阶段也从输入图像中减去图像。
重新缩放 :这里会考虑两个参数分别是目标尺寸和最大尺寸。将图片的较短的边(宽或高)调整为目标尺寸,然后保持长宽比例来调整较长边 (宽或高),以保持长宽比不变。但是,如果调整后较长边(宽或高)超过了最大尺寸,则需要将该边的尺寸调整为最大尺寸,并根据原始长宽比例来调整较短边(宽或高),从而保持长宽比不变。目标大小和最大大小的默认值分别为 800 和 1333。
边缘填充 :因为使用 FPN,所以边缘填充是必要的。 所有填充仅在最右边和最底端的边缘,因此目标坐标不会受到影响,坐标系是从最左上角开始的。 如果不使用 FPN,则无需执行此步骤。
图片宽度为最小边 (600) ,将其重新缩放为 800 后,另一个高尺寸根据宽高比例调整大小得到新的高为(1200),但是 1200 不是 32 的倍数,需要对其进行填充为使得结果大小为 32 倍数(1216/32 = 38)。
注意 :用于锚点生成和卷积步骤的图像高度和宽度将被视为调整大小后的图像,而不是填充后的高度。
Mask R-CNN解读

摘要
本文提出了一个概念上简单、灵活和通用的目标实例分割框架。该方法有效地检测图像中的目标,同时为每个实例生成高质量的分割掩码。该方法被称为 Mask R-CNN,在 Faster R-CNN的基础上,通过添加一个分支来预测一个目标掩码,并与现有的目标检测分支并行。Mask R-CNN很容易训练,只增加了很小的开销,可以以5帧/秒的速度运行。
此外,Mask R-CNN很容易推广到其他任务,例如,人体姿态估计。本文在COCO数据集上进行了大量实验,结果表明Mask R-CNN在实例分割、目标检测和人关键点检测任务上优于其他所有的单一模型。
代码开源: https://github.com/facebookresearch/Detectron
一、引言
原则上,Mask R-CNN 是 Faster R-CNN 的直观扩展,但正确构建 Mask 分支对于良好的结果至关重要。最重要的是,Faster RCNN 不是为网络输入和输出之间的像素对像素对齐而设计的。这一点在 RoIPool 中最为明显,它实际上是处理实例的核心操作,它执行粗空间量化来提取特征。为了修正偏差,我们提出了一个简单的、无量化的层,称为 RoIAlign,它忠实地保持准确的空间位置。
尽管看似一个很小的变化,但是 RoIAlign 具有很大的影响力。它将 Mask 精度提高了10%至50%,在更严格的定位指标下显示出更大的增益。其次,我们发现将掩码和类预测分离是必要的: 我们为每个类独立预测一个二进制掩码,类之间不存在竞争,并依靠网络的 RoI 分类分支来预测类别。相比之下,FCN 通常进行逐像素的多类分类,分割和分类相结合,根据我们的实验,对于实例分割效果较差。
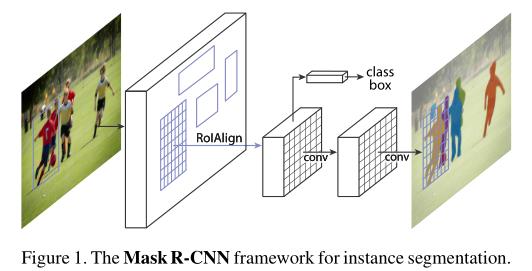
二、Mask R-CNN
2.1 Faster R-CNN
Faster R-CNN由两个阶段组成。第一个阶段,称为区域建议网络(RPN),提出候选对象边界框。第二阶段,本质上是Fast R-CNN,使用 RoIPool 从每个候选框中提取特征,并进行分类和边界框回归。这两个阶段所使用的特征可以共享,以便更快地推理。
2.2 Mask R-CNN
Mask R-CNN 采用相同的两阶段流程,第一阶段相同(即RPN)。在第二阶段,在预测类和框偏移的同时,Mask R-CNN 也为每个 RoI 输出一个二进制掩码。我们的方法遵循了 Fast R-CNN 的方法,它并行地应用了边界盒分类和回归,在很大程度上简化了原始R-CNN的多阶段结构。
2.3 Mask Representation
掩码对输入对象的空间布局进行编码。因此,不同于类标签或盒偏移不可避免地被全连接(fc)层压缩成短输出向量,提取掩码的空间结构可以通过卷积提供的像素到像素的对应来自然地解决。
具体来说,我们使用 FCN 从每个RoI预测 m × m 掩码。这使得蒙版分支中的每一层都可以保持明确的 m × m 对象空间布局,而无需将其折叠成缺乏空间维度的矢量表示。与以往依靠fc层进行掩码预测的方法不同,我们的全卷积表示需要较少的参数,而且实验证明更准确。
这种像素到像素的行为需要我们的RoI特性(它们本身就是小的特性映射)很好地对齐,以忠实地保持显式的每个像素的空间对应。这促使我们开发了以下的RoIAlign层,它在蒙版预测中扮演着关键的角色。
2.4 RoIAlign
RoIPool 是从每个 RoI 中提取小特征图(例如7×7)的标准操作。RoIPool 首先将一个浮点的 RoI 量化到特征映射的离散粒度上,然后将这个量化的 RoI 细分为空间容器,这些空间容器本身也被量化,最后将每个容器所覆盖的特征值进行聚合(通常是通过最大池化)。量化,例如,通过计算[x/16]对连续坐标x进行量化,其中16是特征地图步幅,[·]是四舍五入;同样地,在划分为多个容器时进行量化(例如7×7)。这些量化引入了RoI和提取的特征之间的偏差。虽然这可能不会影响分类,这对小的转换是稳健的,但它对预测像素精确的蒙版有很大的负面影响。
为了解决这个问题,我们提出了一个 RoIAlign 层,它消除了 RoIPool 的苛刻量化,将提取的特征与输入正确对齐。我们提出的改变很简单: 我们避免对 RoI 边界进行量化(即,我们使用x/16而不是[x/16])。我们使用双线性插值来计算每个RoI bin中四个定期采样的位置上输入特征的精确值,并将结果(使用max或average)汇总,详见图3。我们注意到,只要不执行量化,结果对精确的采样位置或采样的点数并不敏感。

三、网络架构
Mask R-CNN 的网络架构较为简单,由两大块组成:
- 用于对整个图像进行特征提取的卷积主干网络。
- 用于边界盒识别和掩码预测的网络头,分别应用于每个RoI。
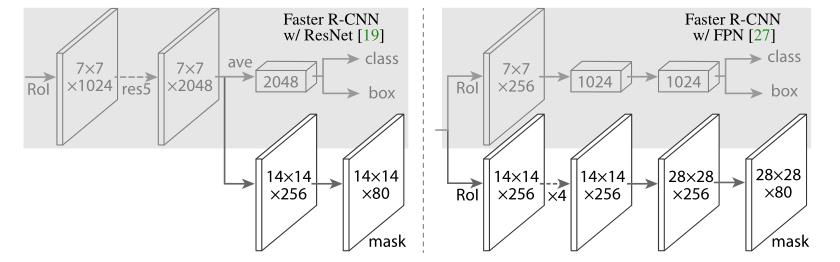
如下图所示,是网络头的示意图,其主干网络分别采用的是 ResNet 和 FPN 的主干网络部分。
四、实验
1、实例分割效果

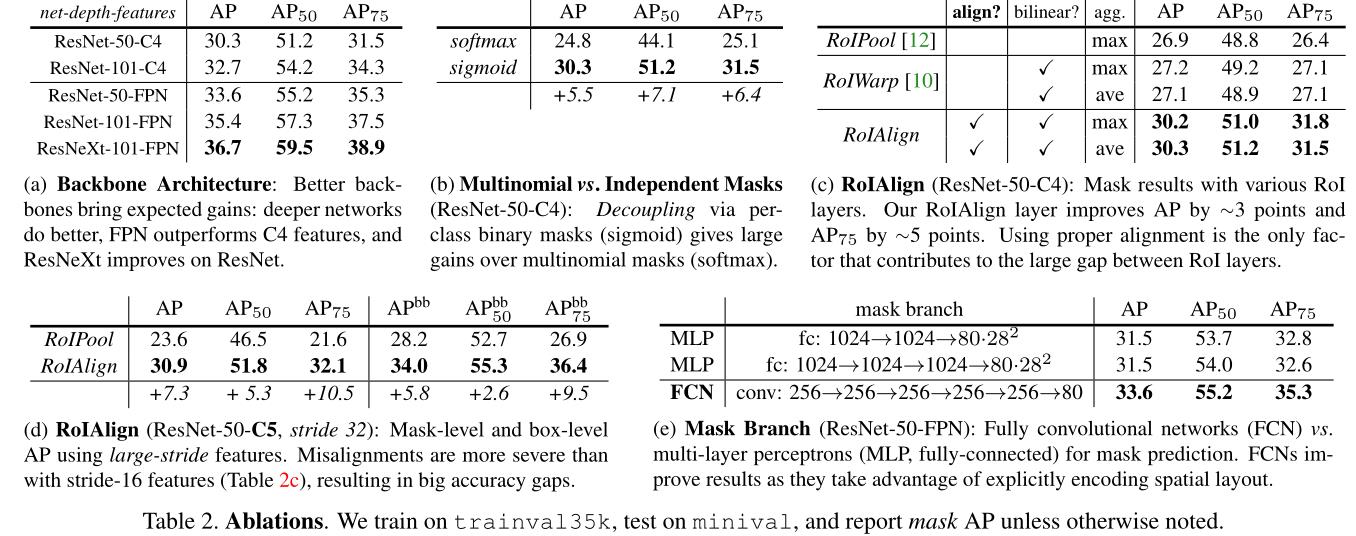
2、消融实验
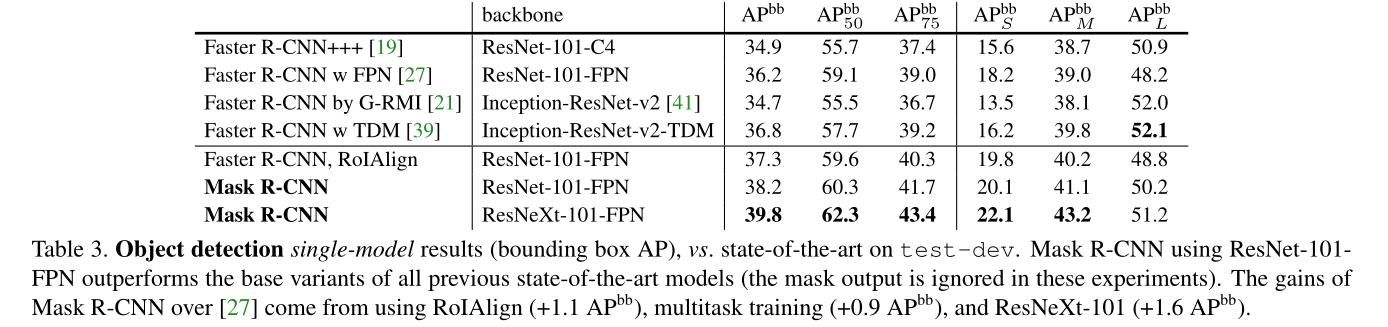
3、目标检测
4、行人姿态估计

以上是关于目标检测系列 Mask R-CNN—图片预处理的主要内容,如果未能解决你的问题,请参考以下文章