英雄联盟数据分析专题
Posted Babyface Killer
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了英雄联盟数据分析专题相关的知识,希望对你有一定的参考价值。
写在前面的话

英雄联盟是一款在世界范围内拥有众多玩家的MOBA游戏,它陪伴了我们这一代人的成长。在游戏中以五人一队为单位分为红方和蓝方两个阵营,最先推掉对方基地水晶的队伍为胜者。队内每个玩家分担不同职责:上单,中单,ADC,辅助以及打野各司其职,不仅要专注于兵线运营和进攻对方防御塔还要掠夺地图资源来为队伍取得更大优势。英雄联盟这款游戏经历了这么多年已经发展出了各种不同的玩法,每个玩家也对游戏有不同的理解,所以游戏中的团队合作和沟通也尤其重要。正是因为其千变万化的玩法和每个版本更新带来的新体验才能使其收获众多玩家,同时这款游戏也推动了中国电竞行业的发展使我们这代人有了自己的独特记忆。
在英雄联盟数据分析这个专题我会使用我手中的英雄联盟数据集来从数据分析的角度多维度分析这款游戏的取胜之道以及各种因素对于游戏胜负的影响。同时也希望读者们能从不同的角度提供建议来帮助我完善这个专题分析。
背景介绍
该数据集包含了大约两万五千场铂金分段的单人排位游戏,所有数据皆来自于蓝色方(不分析Ban/Pick对游戏影响)。数据集中总共包含了55项可供分析的数据,除了队伍总击杀,总助攻,总死亡,总经济,总经验等显性影响游戏局势的因素,还包含了是否取得一塔,一血,击杀元素龙,峡谷先锋,男爵等潜在影响游戏走向的因素。每一局游戏都分为不同的时间节点,自10分钟开始,以2分钟为间隔逐渐增加。如一局游戏持续了25分钟,该局游戏在数据集中就会有第10,12,14,16,...,24分钟的各项数据值,这样我们就可以更深入地分析哪个因素最有可能影响游戏走势,成为游戏中的game changer。
因为数据集中只包含队伍整体数据,因此对英雄选择,队内阵容匹配对游戏的影响不做研究。
下面是该数据集中包含的字段以及对各字段的解释:
gameId:每场游戏独特的游戏ID,用来识别同一场游戏的数据
gameDuration:每场游戏时长,单位为毫秒
hasWon:游戏是否胜利
frame:同一场游戏不同的时间节点,单位为分钟
golddiff:与对方整体经济差距
expDiff:与对方整体经验差距
champLevelDiff:与对方整体英雄等级差距
.......(中间包含的众多游戏元素信息因篇幅过长在这里不做解释,分析用到时会另做解释)
kills:队伍总击杀数
deaths:队伍总死亡数
assists:队伍总助攻数
wardsPlaced:队伍放置视野总数
wardsDestroyed:队伍排除视野总数
wardsLost:队伍丢失视野总数
数据预处理
首先按照常规先进行数据预处理步骤。
因为数据集里的信息太多,所以我选择直接计算所有缺失值的总和如果缺失值过多再进一步分析每一列的缺失值如何处理。但是得到结果后我发现这个数据集非常完整,没有任何缺失值,但是不能高兴得太早,可能还会遇到其他问题。我们继续往下处理,现在来看一看数据集中的数据类型都有哪些。

同样地,因为数据集中信息太多,篇幅有限,我选择使用(value_counts())方法直接观察各类型数据分别有多少,结果显示该数据集中的数据全部为数值型(int或float),这为我们接下来的分析提供了很多便利。在这里不得不说一句,看到这么干净的数据,分析的心情都愉悦了不少。 
之前我也提到了,这个数据集总共有约两万五千场游戏的数据,其中每场游戏还包括不同时间节点的数据,那么这个数据集到底有多少条数据呢?

结果显示这个数据集中包含了二十四万多条游戏数据,有了这个数据量我们就可以得到更有质量的分析结果。
在之前对字段解释的时候细心的读者可能就发现了gameDuration和frame两列数据虽然都是表示时间,但是单位却不统一,为了使我们的分析结果更清晰,要把gameDuration这一列数据转化为以分钟为单位。

到这一步数据预处理过程基本就结束了,但是因为该数据集中信息量过大,我决定由浅入深分层次进行分析。第一步,我们先只看结果,把游戏结束时的统计结果单独提取出来进行分析。


这时我遇到了处理该数据集的第一个问题,明明这个数据集中只包含不到两万五千场游戏数据,可是我提取出来的数据怎么会有三万五千多场呢?这个时候我们来“zoom in”一下,看看是不是有重复的场次。

看来有很多场次都重复出现了两次,是什么导致了这个原因?我们继续“zoom in”。

注意⚠️ gameDuration和frame这两列,看来是因为frame是以两分钟为间隔增加的,有的场次frame只统计到了游戏结束之前的时间节点,而有的场次因为结束时间离下一个时间节点更近就统计到了下一个时间节点。找到了原因,我们就可以对症下药,直接删除重复场次中较早的时间节点。

处理之后我们的数据就正常了,可以开始进行下一步的分析了。
探索性数据分析和可视化
我们先来看一下数据集中胜利的场次和失败的场次分别有多少。
#先看看数据集中胜利和失败的游戏各占多少
win_ratio=lol_result[lol_result['hasWon']==1]['gameId'].count()/lol_result.shape[0]
#绘制饼图可视化一下
plt.figure(figsize=(6,6))
sizes=[win_ratio,1-win_ratio]
labels=('Victory','Defeat')
plt.pie(sizes,labels=labels,autopct='%1.0f%%')
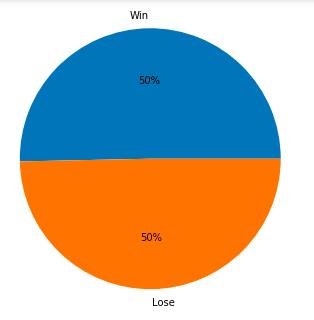 这个数据集相当均衡,胜利场次和失败场次刚好为1:1,这样我们在后面训练模型的时候就不用考虑样本均衡性的问题。
这个数据集相当均衡,胜利场次和失败场次刚好为1:1,这样我们在后面训练模型的时候就不用考虑样本均衡性的问题。
经验告诉我,越早结束的游戏双方的经济,经验差距会越大,也就是俗话说的心态被打崩了,让我们来看看是不是这样。我把数据分成结束时间在20分钟以内,20-25分钟,25-30分钟和30分钟以上四组。
#创建一个列表用来存放每场游戏所在的时间区间
time_interval=[]
for duration in lol_result['gameDuration']:
if duration < 20:
time_interval.append(1)
elif (duration >= 20) & (duration < 25) :
time_interval.append(2)
elif (duration >= 25 ) & (duration < 30):
time_interval.append(3)
else:
time_interval.append(4)
#把时间区间列表整合到lol_result数据框中
lol_result['time_interval']=time_interval
#对四个时间区间的golddiff和expdiff这两项求平均值后进行可视化
labels=['Within 20min','20min-25min','25min-30min','Over 30min']
golddiff_list=([abs(lol_result[lol_result['time_interval']==1]['goldDiff']).mean(),
abs(lol_result[lol_result['time_interval']==2]['goldDiff']).mean(),
abs(lol_result[lol_result['time_interval']==3]['goldDiff']).mean(),
abs(lol_result[lol_result['time_interval']==4]['goldDiff']).mean()])
expdiff_list=([abs(lol_result[lol_result['time_interval']==1]['expDiff']).mean(),
abs(lol_result[lol_result['time_interval']==2]['expDiff']).mean(),
abs(lol_result[lol_result['time_interval']==3]['expDiff']).mean(),
abs(lol_result[lol_result['time_interval']==4]['expDiff']).mean()])
plt.figure(figsize=(6,6))
gold=plt.bar(np.arange(4),height=golddiff_list,width=0.4,color='Orange',label='Gold')
exp=plt.bar([i+0.4 for i in np.arange(4)],height=expdiff_list,width=0.4,color='blue',label='Experience')
plt.xticks([i+0.2 for i in np.arange(4)],labels)
plt.legend()
plt.title('Gold and experience difference in different game duration interval')
 这个结果显示随着游戏时间的增加,胜方队伍的经济优势会越来越小,但游戏时间在30分钟以上的胜方队伍平均经济优势也超过了6000。这也提醒玩家:在早期有巨大经济优势的时候只要不浪就有很大几率取胜,同时在前期落后的情况下稳住不浪在后期也是有翻盘的可能性。
这个结果显示随着游戏时间的增加,胜方队伍的经济优势会越来越小,但游戏时间在30分钟以上的胜方队伍平均经济优势也超过了6000。这也提醒玩家:在早期有巨大经济优势的时候只要不浪就有很大几率取胜,同时在前期落后的情况下稳住不浪在后期也是有翻盘的可能性。

在游戏后期得男爵者得天下,男爵提供的buff加成不仅能使优势方扩大优势,如果劣势方能偷掉男爵也会给翻盘带来一丝希望。让我们通过数据分析来看看这样的经验能不能经得住数据的考验。数据集中有两个分别与男爵有关的字段,分别是:killBaronNashor 和 lostBatonNashor,代表着击杀男爵和丢失男爵,数据取值为整数型(0,1,2,...),因为有的队伍可能不止一次击杀或丢掉男爵。
#分别计算拿到男爵的队伍胜利的比例和丢掉男爵的队伍失败的比例
win_killed_baron=(lol_result[(lol_result['hasWon']==1)&(lol_result['killedBaronNashor']>0)]
['gameId'].count()/lol_result[lol_result['killedBaronNashor']>0]
['gameId'].count())
win_lost_baron=(lol_result[(lol_result['hasWon']==1)&(lol_result['lostBaronNashor']>0)]
['gameId'].count()/lol_result[lol_result['lostBaronNashor']>0]
['gameId'].count())
#绘制饼图可视化
plt.figure(figsize=(10,10))
axe1=plt.subplot(1,2,1)
axe1.pie([win_killed_baron,1-win_killed_baron],
labels=('Win','Lose'),
autopct='%1.1f%%')
axe1.set_title('Killed Baron')
axe2=plt.subplot(1,2,2)
axe2.pie([win_lost_baron,1-win_lost_baron],
labels=('Win','Lose'),
autopct='%1.1f%%')
axe2.set_title('Lost Baron')

从结果可以清晰地看到,击杀了男爵的队伍胜率高达百分之八十以上,而丢掉了男爵的队伍胜率仅为百分之十八点五(数据集仅包含蓝色方数据,所以不存在出现同一场游戏的两支的队伍的情况)。通过这项分析可以证明男爵对取胜的重要性,看来我们的经验是正确的。
下面我们来分析一下KDA(kills,deaths,assits)对游戏结果的影响,我们使用英雄联盟官方评选游戏内MVP的公式:KDA=(K+A)/D*3 来看看是不是KDA越高的队伍获胜的概率越大。
#先计算出每场游戏的KDA
KDA=[]
for k,d,a in zip(lol_result['kills'],lol_result['deaths'],lol_result['assists']):
if d == 0:
kda=(k+a)/(d+1)*3
else:
kda=(k+a)/d*3
KDA.append(kda)
#把KDA整合到数据集中
lol_result['KDA']=KDA
#先来看看KDA的分布怎么样
lol_result['KDA'].describe()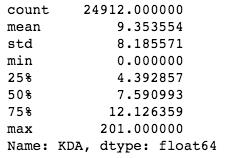 从描述性统计数据我们可以观察到KDA这一项平均值约为9.35,而标准差高达8.19,此外最小值和最大值也偏离平均值非常多,所以我就打消了用平均值来代表KDA水平的想法,转而使用箱线图来可视化KDA和游戏胜率的关系。
从描述性统计数据我们可以观察到KDA这一项平均值约为9.35,而标准差高达8.19,此外最小值和最大值也偏离平均值非常多,所以我就打消了用平均值来代表KDA水平的想法,转而使用箱线图来可视化KDA和游戏胜率的关系。
#使用箱线图来可视化队伍KDA数据和胜负的关系
win_kda=lol_result[lol_result['hasWon']==1]['KDA']
lose_kda=lol_result[lol_result['hasWon']==0]['KDA']
kda_list=[win_kda,lose_kda]
plt.figure(figsize=(6,6))
plt.boxplot(kda_list,patch_artist=True,showfliers=False,widths=0.8)
plt.xticks(np.arange(3),('','Win','Lose'))
plt.ylabel('KDA')
plt.title('KDA distribution for win and lose teams')
 从这个结果可以看到KDA也是体现游戏胜负最显性的因素之一,负方的KDA上限仅达到了胜方KDA的下四分位数,而且胜方和负方KDA中位数的差距也非常大。结合我们的游戏经验来解读这个结果就会更加容易理解,KDA越高的队伍经济和经验就会领先对方越多,而经济和经验又会转化成技能和装备最后直接的结果就是KDA高的队伍整体伤害会更高,整体防御性会更好。
从这个结果可以看到KDA也是体现游戏胜负最显性的因素之一,负方的KDA上限仅达到了胜方KDA的下四分位数,而且胜方和负方KDA中位数的差距也非常大。结合我们的游戏经验来解读这个结果就会更加容易理解,KDA越高的队伍经济和经验就会领先对方越多,而经济和经验又会转化成技能和装备最后直接的结果就是KDA高的队伍整体伤害会更高,整体防御性会更好。
下面再来看看视野对游戏结果的影响,在高分段的游戏中,双方队伍都会特别重视视野的排布,失去某个关键位置的视野可能直接就会导致队友被击杀从而让对方滚起雪球。如果视野没有做好,队友就会频繁打出这个信号:
我们使用一项我自定义的有效视野数(放置视野数 - 被排掉视野数)来评估每个队伍的视野水平。原数据集中相关字段有:wardsPlaced 和 wardsLost,分别表示放置视野数和丢失视野数。
#计算有效视野数并整合到数据集中
effective_wards=[i-j for i,j in zip(lol_result['wardsPlaced'],lol_result['wardsLost'])]
lol_result['effective_wards']=effective_wards
#同样地,我们来看看有效视野的分布
lol_result['effective_wards'].describe() 数据的分布情况和KDA类似,我们同样使用箱线图来可视化有效视野数和游戏胜率的关系。
数据的分布情况和KDA类似,我们同样使用箱线图来可视化有效视野数和游戏胜率的关系。
#使用箱线图来可视化队伍有效视野数和胜负的关系
win_wards=lol_result[lol_result['hasWon']==1]['effective_wards']
lose_wards=lol_result[lol_result['hasWon']==0]['effective_wards']
wards_list=[win_wards,lose_wards]
plt.figure(figsize=(6,6))
plt.boxplot(wards_list,patch_artist=True,showfliers=False,widths=0.8)
plt.xticks(np.arange(3),('','Win','Lose'))
plt.ylabel('Effective wards')
plt.title('Effective wards distribution for win and lose teams')
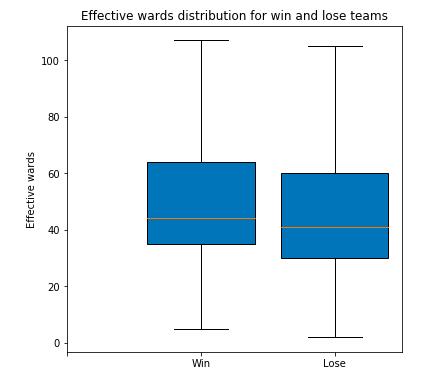 失败队伍的有效视野在各个水平稍低于胜利队伍,这个结果说明了虽然视野很重要,但在铂金分段这个因素并不能决定游戏的胜负。
失败队伍的有效视野在各个水平稍低于胜利队伍,这个结果说明了虽然视野很重要,但在铂金分段这个因素并不能决定游戏的胜负。
在之前的版本中,相同元素龙的属性叠加会在游戏后期带来相当客观的buff加成,让我们来看看如果一支队伍击杀或丢掉了两次及以上相同的元素龙会对游戏结果带来什么影响。原数据集中相关字段有:killedFireDrake, killedWaterDrake, killedAirDrake, killedEarthDrake, lostFireDrake, lostWaterDrake, lostAirDrake, lostEarthDrake, 分别代表击杀或丢失某元素龙。数据取值为整数型(0,1,2,...),因为有的队伍可能不止一次击杀或丢掉同一元素龙。
#我们先对击杀和丢失两条及以上同元素龙的游戏做标记
killed_same_drake_twoplus=[]
lost_same_drake_twoplus=[]
killed_cols=['killedFireDrake','killedWaterDrake','killedAirDrake','killedEarthDrake']
lost_cols=['lostFireDrake','lostWaterDrake','lostAirDrake','lostEarthDrake']
flag=0
for i in range(lol_result.shape[0]):
for col in killed_cols:
if lol_result.loc[i,col] >=2 :
flag=1
else:
flag=0
if flag == 1:
killed_same_drake_twoplus.append(1)
else:
killed_same_drake_twoplus.append(0)
for i in range(lol_result.shape[0]):
for col in lost_cols:
if lol_result.loc[i,col] >=2 :
flag=1
else:
flag=0
if flag == 1:
lost_same_drake_twoplus.append(1)
else:
lost_same_drake_twoplus.append(0)
#将标记整合到数据集中
lol_result['killed_same_drake_twoplus']=killed_drake_twoplus
lol_result['lost_same_drake_twoplus']=lost_drake_twoplus
#先来看看能拿到两条以上同元素龙的游戏占全部游戏的多少
same_drake_twoplus=(lol_result[(lol_result['killed_same_drake_twoplus']==1)|
(lol_result['lost_same_drake_twoplus']==1)]['gameId'].count()
/lol_result.shape[0])
#使用饼图可视化
plt.figure(figsize=(6,6))
sizes=[same_drake_twoplus,1-same_drake_twoplus]
labels=('Same Team Killed Same Drake','No Team Killed Same Drake')
plt.pie(sizes,labels=labels,autopct='%1.0f%%')
 能在同一场游戏中击杀同一属性元素龙的队伍只有百分之十三,其中一部分原因是游戏中刷新哪种元素龙的概率是随机的,所以游戏中刷新同种元素龙的基础上同一支队伍击杀了同种元素龙的概率就更低了。
能在同一场游戏中击杀同一属性元素龙的队伍只有百分之十三,其中一部分原因是游戏中刷新哪种元素龙的概率是随机的,所以游戏中刷新同种元素龙的基础上同一支队伍击杀了同种元素龙的概率就更低了。
#再来看看击杀和丢失了相同元素龙的队伍的胜率
win_killed_same_drake=(lol_result[(lol_result['hasWon']==1)&(lol_result['killed_same_drake_twoplus'] == 1)]
['gameId'].count()/lol_result[lol_result['killed_same_drake_twoplus'] == 1]
['gameId'].count())
win_lost_same_drake=(lol_result[(lol_result['hasWon']==1)&(lol_result['lost_same_drake_twoplus'] == 1)]
['gameId'].count()/lol_result[lol_result['lost_same_drake_twoplus'] == 1]
['gameId'].count())
#使用饼图可视化
plt.figure(figsize=(10,10))
axe1=plt.subplot(1,2,1)
axe1.pie([win_killed_same_drake,1-win_killed_same_drake],
labels=('Win','Lose'),
autopct='%1.1f%%')
axe1.set_title('Killed Same Drake')
axe2=plt.subplot(1,2,2)
axe2.pie([win_lost_same_drake,1-win_lost_same_drake],
labels=('Win','Lose'),
autopct='%1.1f%%')
axe2.set_title('Lost Same Drake') 这个结果和击杀大龙对胜负的影响基本持平,同时也从侧面说明了如果游戏中队伍失去了争夺男爵的机会,若可以拿到同种元素龙也会增大获胜的几率。
这个结果和击杀大龙对胜负的影响基本持平,同时也从侧面说明了如果游戏中队伍失去了争夺男爵的机会,若可以拿到同种元素龙也会增大获胜的几率。
到此探索性数据分析和可视化就告一段落了,从前面的分析我们得到:经济,男爵,KDA,同种元素龙是影响游戏胜负相对显性的因素,下一步我们会使用这几项数据建立一个决策树来更直观的观察这些因素到底在多大程度上影响了游戏胜负。
数据建模
在这个部分我们会使用非常经典的决策树模型来帮助我们判断绝对游戏胜负的因素到底有哪些以及重要性排序。先来简单介绍一下决策树分类模型(Decision Tree Classifier):决策树模型是分类问题中一种常用的机器学习模型,属于有监督学习。在初始阶段所有数据都存在于根结点,然后根据不同的特征节点把待测数据分入不同的叶子节点,从根结点到每个叶子节点都对应了一个判断路径。决策树模型的结果有较好的可解释性和不需要对特征做归一化处理等优点。(因本篇注重于实战理论涉及较少,后面我会单独写一篇关于决策树模型算法和技术型问题的文章)在生成了决策树分类模型后,我会对结果进行可视化来更清楚的展现不同因素对游戏结果的影响。
#导入要使用的决策树包
from sklearn.tree import DecisionTreeClassifier
#导入分割数据集要用的包
from sklearn.model_selection import train_test_split
#导入指标要使用的包
from sklearn.metrics import accuracy_score,f1_score,precision_score,recall_score,plot_confusion_matrix
#导入可视化要用到的graphviz
from sklearn.tree import export_graphviz
import graphviz
#先把我们要使用的特征都整合到同一个数据框
decision_tree_df=lol_result.loc[:,('goldDiff','killedBaronNashor','KDA','killed_same_drake_twoplus','hasWon')]
#分别把特征和标签提取出来
X=decision_tree_df.iloc[:,0:-1]
y=decision_tree_df.iloc[:,-1]
#把训练和测验数据集分开
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.3,random_state=23)
#实例化决策树模型,判定条件使用基尼系数(gini),最大深度为8,最多叶子节点为15
clf=DecisionTreeClassifier(max_depth=8,max_leaf_nodes=15,criterion='gini',random_state=23)
clf.fit(X_train,y_train)
predict_result=clf.predict(X_test)
#用不同指标看看模型效果
accuracy=accuracy_score(y_test,predict_result)
f1=f1_score(y_test,predict_result)
precision=precision_score(y_test,predict_result)
recall=recall_score(y_test,predict_result)
print('Accuracy:0:.2f\\nf1:1:.2f\\nprecision:2:.2f\\nrecall:3:.2f'.format(accuracy,f1,precision,recall))
 在训练模型前我们首先已经把所有对分类作用最强的信息提取出来了,而且提取出的数据集较小,特征也比较少,这些因素都会使得我们的模型各项指标结果比较乐观。(此处使用决策树是为了可视化,而且数据集也比较简单,因此在此处不使用网格搜索(GridSearch)来优化模型参数和GBDT这种复杂模型,以后处理复杂的数据集用到时会再做强调)
在训练模型前我们首先已经把所有对分类作用最强的信息提取出来了,而且提取出的数据集较小,特征也比较少,这些因素都会使得我们的模型各项指标结果比较乐观。(此处使用决策树是为了可视化,而且数据集也比较简单,因此在此处不使用网格搜索(GridSearch)来优化模型参数和GBDT这种复杂模型,以后处理复杂的数据集用到时会再做强调)
下面重点强调一下分类模型常用到的评价模型的指标:混淆矩阵(Confusion Matrix)
#绘制混淆矩阵
fig=plot_confusion_matrix(clf, X_test, y_test,
display_labels=('Lose','Win'),normalize='all')
先来介绍一下几个概念:
真阳性(True Positive):预测为正,实际结果也为正,对应图中右下角
假阳性(Fasle Positive):预测为正,实际结果为负,对应图中右上角
真阴性(True Negative):预测为负,实际结果也为负,对应图中左上角
假阴性(False Negative):预测为负,实际结果为正,对应图中左下角
精确率(Precision):在所有预测为正的样本中实际结果也为正的比例,
召回率(Recall):在所有实际为正的样本中预测也为正的比例,
F1值:F1值就是精确值和召回率的调和均值,
这三个值在上面的指标计算中都有体现,当样本分布不均时(正负样本数量差异特别大)准确率(Accuracy)就不能客观地衡量模型的准确性,就需要使用到上面三个指标。(当样本分布不均时,在训练模型时还涉及到上采样或者下采样的问题,本篇使用的数据集样本非常均衡所以不需要做处理,之后涉及到相关知识会再做强调)
最后我们将决策树结果可视化并打印出来。
#把决策树生成的结果实例化
dot_data=export_graphviz(clf,feature_names=['goldDiff','killedBaronNashor','KDA','killed_same_drake_twoplus'],
class_names=['Lose','Win'])
#使用graphviz生成可视化图像并保存
graph=graphviz.Source(dot_data)
graph.render('mytree')
上面这张图就是生成的决策树(上面的字当然是我自己写的,字丑勿怪🤣 🤣 🤣 ),因为比较复杂,所以我分成了四条路线我们逐一进行分析。为了方便阅读,我把经济差距分类条件用黄色马克笔,KDA分类条件用蓝色马克笔,击杀男爵分类条件用红色马克笔标记了出来。
在这棵树中没有体现击杀同种类元素龙对分类结果的影响,可能是因为能达成此成就的游戏对局在样本中比例太小,在层数较少的决策树中无法作为分类依据,若在训练模型时把树的深度设置的更大可能就会出现击杀同种元素龙的分类条件。
我们先来看路线1: 该条路线展示了队伍经济劣势一直增大的情况,当经济劣势超过4329.5的时候,在7456场游戏中只有21场游戏获得了胜利。
路线2: 该条路线展示了当经济劣势没有那么大的时候,决定因素为队伍整体KDA。当经济劣势小于1189时,KDA大于10.693的8支队伍获得了胜利,但我们需要注意的是,在上一层子节点中,经济劣势小于1189的队伍总共有156支。
路线3: 该条路线则展示了当经济领先没有那么大的时候,情况比路线3稍显复杂。先来看当经济领先少于833时,不管是以击杀大龙,KDA还是经济差距为分类条件,分类后胜利和失败的游戏场次差距都并不大(观察value值,第一个值为失败场次,第二个值为胜利场次),这也说明在经济领先为833以内时局势是十分不明朗的。再来分析当经济领先大于833时,若KDA大于5.512,胜利场次会大大超过失败场次,而经济领先大于1741.5时的3场失败场次可以当作异常值处理。
最后再来看路线4: 该条路线展示了队伍经济领先一直增大的情况,当经济领先超过3174.5时,7838场游戏中有7801场获得了胜利。
虽然决策树的可视化结果为我们呈现了决定游戏结果的因素,但在实际游戏中情势瞬息万变,该结果只做参考并不能以此为依据来在游戏中提前预测游戏结果。
写在最后的话
作者刚接触数据分析以及机器学习不久,本文中难免有错误或纰漏,希望各位读者可以及时指出
希望各位可以对本篇提出宝贵意见
转载请注明出处
以上是关于英雄联盟数据分析专题的主要内容,如果未能解决你的问题,请参考以下文章