Hadoop&Spark搭建
Posted ythunder
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop&Spark搭建相关的知识,希望对你有一定的参考价值。
概念
Hadoop,一种分析和处理大数据的软件平台。是Appach的一个用JAVA语言实现的开源软件的加框,在大量计算机组成的集群中实现了对于海量数据进行的分布式计算。
Hadoop的框架核心设计是:HDFS和MapReduce.HDFS为海量数据提供了存储,则MapReduce为海量数据提供了计算。
关于HDFS分布式文件系统
用于数据的存储
大文件被分成多块,以冗余镜像的方式分布在不同的机器中。
关于MapReduce
Hadoop为每个input split创建一个task调用Map计算,task计算input中的每个记录,然后Map将结果以key-value形式输出。按照key值将结果整理交给Reduce,Reduce输出结果。保存在HDFS。
Hadoop集群组成
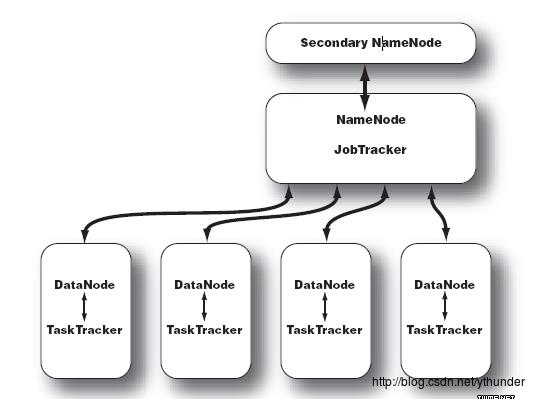
NameNode
- 文件如何拆分
- 被拆分部分都存储在哪些DataNode节点
- 文件系统运行的状态信息(从DataNode接受心跳信号,管理节点工作状态)
Secondary NameNode
- 帮助NameNode收集文件系统运行的状态信息
JobTracker
- 当有任务提交到Hadoop集群的时候负责Job的运行,负责调度多个TaskTracker
TaskTracker
- 负责某一个map或者reduce任务.
数据处理流程:
数据文件被分割,分割块以冗余镜像的方式下放到DataNode上。分割方法及分割后文件块的去向记录在NameNode中,有计算任务提交时,JobTracker调度TaskTracker执行计算任务。
Secondary NameNode收集文件系统运行的状态信息。
1.下载安装Hadoop的发行版
下载 http://hadoop.apache.org/releases.html
解压
2.配置java环境
$ cd hadoop-2.8.2/etc/hadoop修改hadoop-env.sh文件中的jdk路径为:
export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk-9.0.1.jdk/Contents/Home/修改后执行:
bin/hadoop version 显示版本信息,安装成功
单机模式的操作方法
默认情况下,Hadoop被配置成以非分布式模式运行的一个独立Java进程。这对调试非常有帮助。
下面的实例将已解压的 conf 目录拷贝作为输入,查找并显示匹配给定正则表达式的条目。输出写入到指定的output目录。
$ mkdir input
$ cp etc/hadoop/*.xml input
$ cp ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.2.jar .
$ bin/hadoop jar hadoop-*-examples.jar grep input output 'dfs[a-z.]+'
$ cat output/*4. 通过命令与HDFS交互

伪分布式配置
1.首先设置HADOOP的环境变量,追加~/.bash_profile文件
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/binhadoop的配置文件有两个:
hdfs-site.xml 和 core-site.xml
2.修改core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>3. 修改hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>4.执行namenode格式化命令
$./bin/hadoop namenode -format显示:
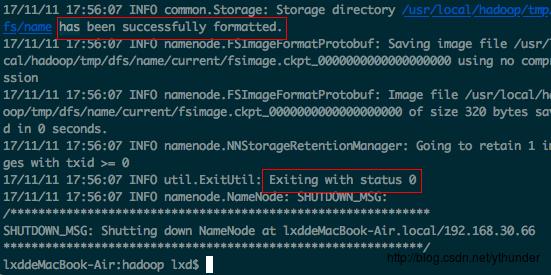
格式化成功
5.开启Namenode和DataNode守护进程
$ ./sbin/start-dfs.sh 可能遇到问题:

打开ssh服务即可
遇到询问,就填yes
开启后,运行jps命令,查看开启是否成功
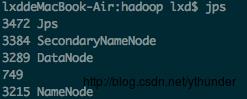
成功启动后,可以访问 Web 界面 http://localhost:50070 查看 NameNode 和 Datanode 信息,还可以在线查看 HDFS 中的文件。
6.关闭时运行:
./sbin/stop-dfs.sh下次启动不需要格式化namenode,直接运行start-dfs.sh即可。
Spark搭建
1.下载安装Spark开发包
http://mirrors.tuna.tsinghua.edu.cn/apache/spark/spark-2.2.0/spark-2.2.0-bin-hadoop2.7.tgz
$ tar -zxvf spark-2.2.0-bin-hadoop2.7.tgz -C /usr/local/
$ cd /usr/local/
$ mv spark-2.2.0-bin-hadoop2.7/ spark/2.修改配置文件
spark的配置文件为spark-env.sh
将 spark/conf/spark-env.sh.template改为spark/conf/spark-env.sh配置文件生效
然后追加配置文件加入JAVA路径:
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
保存后,spark就可以运行了
3.运行Spark
测试用例计算PI值
$ ./bin/run-example SparkPi使用grep过滤输出:
./bin/run-example SparkPi 2>&1 | grep "Pi is roughly"也有运行python程序的命令:
./bin/spark-submit examples/src/main/python/pi.py4.SHELL交互
Spark shell 提供了简单的方式来学习 API,也提供了交互的方式来分析数据。Spark Shell 支持 Scala 和 Python,本教程选择使用 Scala 来进行介绍。
执行命令:
./bin/spark-shell可能遇到问题1:

解决:
查看JDK版本是否不兼容(我的9.0.1版本用不了),更换版本为1.8.0版本,下载地址:
http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
安装后配置环境变量,修改~/.bash_profile文件:
export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_151.jdk/Contents/Home
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar:.然后安装scala包:
下载地址:
http://www.scala-lang.org/download/2.11.11.html/解压到/usr/local下
添加环境变量:
$ open -e ~/.bash_profile加入:
export SCALA_HOME=/usr/local/scala
export PATH=$SCALA_HOME/bin:$PATH可能遇到问题2:

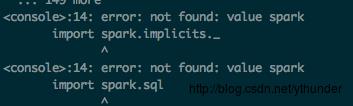
图1是缺少创建 metastore_db的权限
解决:
$ chmod 777 /usr/local/spark 执行启动命令:
$ ./bin/spark-shell成功
以上是关于Hadoop&Spark搭建的主要内容,如果未能解决你的问题,请参考以下文章