python实现删除重复行并计数
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python实现删除重复行并计数相关的知识,希望对你有一定的参考价值。
实例如图所示,删除重复的行,并统计重复的行的个数作为新增的一列,希望高效的实现此功能

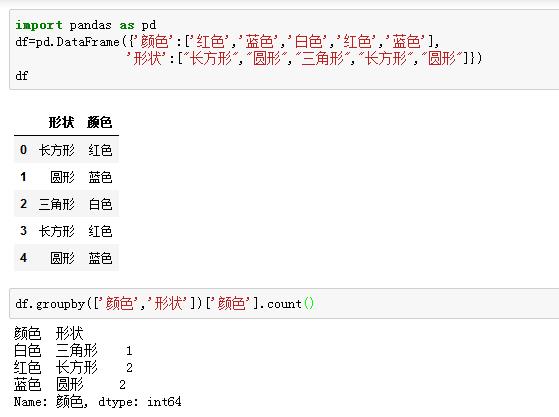
Leetcode上:从排序数组中删除重复项
// nums 是以“引用”方式传递的。也就是说,不对实参做任何拷贝int len = removeDuplicates(nums);// 在函数里修改输入数组对于调用者是可见的。// 根据你的函数返回的长度, 它会打印出数组中该长度范围内的所有元素。for (int i = 0; i < len; i++) print(nums[i]);
我当时的解决方法:class Solution:
def removeDuplicates(self, nums):
"""
:type nums: List[int]
:rtype: int
"""
nums = list(set(nums)) return len(nums)
然而这个方法一直没通过,我看了测试过程后才发现原来nums并没有被修改。这是为什么呢?原来 nums = list(set(nums)) 这个被重新赋值的nums并不是指向的原来传进来的nums 的地址,set()后重新申请了一块空间,然后list()又重新申请了一块空间,最后将nums指向这个空间当然就不是原来的实参(形参)原来的空间了,自然实参的值没有得到改变。
python中不需要像C++中那样传引用或是传地址,而是只用在函数内对传进来的变量重新赋值即可,python函数传参的过程可看做是深拷贝,地址是相同的,所以可以通过改变形参的值来改变实参的值。但是如果是整型是不可以的。
a = 1print(id(a)) =>1624465632def do1(nums):
nums = 2do1(a)
print(id(a)) =>1624465632print(a) => a=1----
b = [1,2]
print(id(b)) =>2578463263304def do2(list):
list.append(3)
do2(b)
print(id(b)) =>2578463263304print(b) => [1,2,3]
a=1只是a引用了1,指向了1这个地址。10的引用计数位0的时候,解释器会自动回收。
当然这跟python中整型分配内存空间的方式也有关。
num = 10print(id(num))
print(id(10) )
#=>结果是相同的.
#num_2=10 id(num_2)=id(num)=id(10)
更进一步说明:print(num is 10) # => True
其中操作符is的作用就是判断两个是否指向同一个内存。在python中,相当于给"10"这个数值分配了内存,然后让变量"num"去指向“10”(可以看做是指针),num可以看做是10的引用。而python中的id()则可以用来查询地址。
在python中,一开始初始化存储在内存的东西是不可以更改的,python中对内存的操作是由解释器来管理的。对于整型来说,我们并不能改变地址,我们所能更改的只是它的指向。
然而对于python的内置数据类型如列表list(),字典,集合来说。又是另外一种情况。
list1 = [1,2,3]
list2 = [1,2,3]print(id(list1) ) # =>1904062761544print(id(list2) ) # =>1904062762952print(id([1,2,3])) # =>1904092664008#=>结果是不同的.
更进一步说明:print(list1 is list2) # => False
Python中list内存的分配方式是动态的:
创建时:if (numfree)
numfree--;
op = free_list[numfree];
_Py_NewReference((PyObject *)op);
else
op = PyObject_GC_New(PyListObject, &PyList_Type); if (op == NULL) return NULL;
resize时:
new_allocated = (newsize >> 3) + (newsize < 9 ? 3 : 6); /* check for integer overflow */
if (new_allocated > PY_SIZE_MAX - newsize)
PyErr_NoMemory(); return -1;
else
new_allocated += newsize;
即使是相同内容的列表,但他们的地址是不同的,相当于仅仅是一次浅拷贝。
至于为什么整型、元组不能改变他们内存上的值,而字典、列表可以,我个人认为主要还是python对它们内存管理方式上的不同。学识尚欠,不敢误言,以后整明白了再补上吧。
Python sys.getsizeof(int())
print(id(2)) #=>1624465664
print(id(3)) #=>1624465696
print(id(4)) #=>1624465728
发现整型地址之间只差了32,这似乎意味着在64位里python是占4字节的。于是为了证实这个想法,我使用了sys.getsizeof(int())。
△.注:sys.getsizeof(int()) 为<class 'int'>这个类的总大小
>>> sys.getsizeof(0)24>>> sys.getsizeof(1)28>>> sys.getsizeof(2 ** 30 - 1)28>>> sys.getsizeof(2 ** 30)32>>> sys.getsizeof(2 ** 60 - 1)32>>> sys.getsizeof(2 ** 60)36
可以看到的是,随着存储的数字大小不同,int占有的空间也是不同的,越大的数,需要的存储空间越大。这种能够变得更长的表现暗示着它像列表之类的数据类型。事实上,在C语言中python的int是这样定义的:
typedef struct
PyObject_HEAD
long ob_ival; #类型为长整型
PyIntObject;
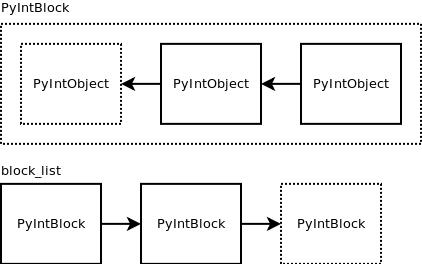
为了避免每次需要一个新的整数对象时都要申请新的对象,python提前为未使用的整数对象分配了一块空的区间。struct _intblock struct _intblock *next;
PyIntObject objects[N_INTOBJECTS];
;
typedef struct _intblock PyIntBlock;
▲.0是没有价值的,所以不在存储值内,所以getsizeof(0)==24.
通常在32、64位中的int都是4字节的,然而得到的结果明显远大于这个值,原因是在python中int已经很完善了,实现多种功能的同时,就意味着它需要占用更多的空间,消耗更多的内存。
总的来说,这些都是跟硬件有关的,在32位和64位中不同数据类型所占的空间还是不同的。
继续讨论下那块已经提前分配好的整数空间
print(id(-6)) #3221839702960
print(id(-5)) #1624465440
print(id(255)) #1624473760
print(id(256)) #1624473792
print(id(257)) #2143657436272
print(id(258)) #2143657438960
可以看到-6到-5和256到257,地址突然跃变了,这其实是因为重新为[-5,256]之外的数分配了新的内存空间。
#define NSMALLPOSINTS 257#define NSMALLNEGINTS 5static PyIntObject *small_ints[NSMALLNEGINTS + NSMALLPOSINTS];
A specific structure is used to refer small integers and share them so access is fast. It is an array of 262 pointers to integer objects. Those integer objects are allocated during initialization in a block of integer objects we saw above. The small integers range is from -5 to 256. Many Python programs spend a lot of time using integers in that range so this is a smart decision.
if integer value in range -5,256: return the integer object pointed by the small integers array at the
offset (value + 5).else: if no free integer object available:
allocate new block of integer objects set value of the next free integer object in the current block of integers. return integer object
为了让更小的数字被访问的更快,事先python已经为[-5,256]之间的整数分配好了内存。如果要使用这个范围里面的数直接访问即可,加上相应的偏移量就能得到正确的数值,(-5的偏移量为0,-4的偏移量则为1)。如果不在这个范围内,python将另外创建个新的block来存放PyIntObject。
Oracle 删除表中的重复行并使用另一个表中的值更新行
【中文标题】Oracle 删除表中的重复行并使用另一个表中的值更新行【英文标题】:Oracle Remove Duplicates and Update Rows in a Table with a Value from Another Table 【发布时间】:2020-07-14 21:13:09 【问题描述】:在我的 associates 表中,我有 4,978 个人,至少有 1 个重复。
asscssn | count(*)
--------- --------
123456789 8
987654321 5
234567890 5
一个人的每个副本在 associates 表中都有一个唯一的 id (asscid)。
asscid | asscssn
------ -------
53492 987654321
53365 987654321
53364 987654321
52104 987654321
50185 987654321
我的 case 表有一个与每个 asscid 相关的 case
docketnumber | asscid
----------- -------
2010JV0000 53492
2010JV1111 53365
2010JV2222 53364
2010JV3333 52104
2010JV4444 50185
我想获取每个有重复项的人,从 associates 表中获取该人的最新 asscid 并更新 case 表。结果将是:
docketnumber | asscid
----------- -------
2010JV0000 53492
2010JV1111 53492
2010JV2222 53492
2010JV3333 53492
2010JV4444 53492
【问题讨论】:
【参考方案1】:如果我理解正确,你想要:
select c.docketnumber, max_asscid
from cases c join
(select a.*, max(asscid) over (partition by asscssn) as max_asscid
from associations a
) a
on c.asscid = a.asscid;
这假定“最新的”asscid 是具有最大值的那个。如果您有另一列指定顺序(例如日期),则可以改用first_value()。
编辑:
如果你真的想更新数据:
update cases c
set assc_id = (select max_asscid
from (select a.*, max(asscid) over (partition by asscssn) as max_asscid
from associations a
where asscssn is not null
) a
where a.asscid = c.asscid
);
【讨论】:
谢谢@gordon linoff 先生。查询有效。我应该把更新声明放在哪里? 脚本运行良好。我确实注意到一件事。我有 33K 条记录,其中 asscssn 为空,它将所有这些记录更改为最大的 asscid。要忽略 asscssn 为空的记录,我是否将and asscssn is not null 放在 where a.asscid = c.asscid 之后?
@belmer01。 . .您可以在set 之后添加where assc_id is not null。
那行不通。 asscid 永远不会为空,因为它是主键。只要 asscssn 不为空,我就想在 associates 表中select max_asscid。【参考方案2】:
获取最新的asscid后,您可以使用cross join。这是demo。
select
docketnumber,
q.asscid
from table2
cross join
(
select
max(asscid) as asscid
from table1
) q
输出:
| docketnumber | asscid |
| ------------ | ------ |
| 2010JV0000 | 53492 |
| 2010JV1111 | 53492 |
| 2010JV2222 | 53492 |
| 2010JV3333 | 53492 |
| 2010JV4444 | 53492 |
【讨论】:
谢谢@zealous。我需要按 asscssn 分组。我有近 5k 人,每个人都有多个重复项。我认为您的查询将采用整个表中最高的 asscid 并将其复制到所有其他人。这会破坏关系。【参考方案3】:我了解到您正在寻找 update 声明 - 到目前为止没有提供其他答案。
update 查询的语法往往是针对每个数据库的。既然已经澄清您使用的是 Oracle,我建议您使用相关子查询。
您可以自行加入associates 表:
update cases c
set asscid = (
select max(a1.asscid)
from associates a
inner join associates a1 on a1.asscssn = a.asscssn
where a.asscid = c.asscid
)
或者你也可以使用窗口函数:
update cases c
set asscid = (
select max_asscid
from (
select asscid, max(asscid) over(partition by asscssn) max_asscid
from associates
) a
where a.asscid = c.asscid
)
Demo on DB Fiddle:update查询执行后,cases表包含:
【讨论】:
以上是关于python实现删除重复行并计数的主要内容,如果未能解决你的问题,请参考以下文章