Google 深度学习笔记 卷积神经网络
Posted 梦里茶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Google 深度学习笔记 卷积神经网络相关的知识,希望对你有一定的参考价值。
Convolutional Networks
转载请注明作者:梦里风林
Github工程地址:https://github.com/ahangchen/GDLnotes
欢迎star,有问题可以到Issue区讨论
官方教程地址
视频/字幕下载
deep dive into images and convolutional models
Convnet
BackGround
- 人眼在识别图像时,往往从局部到全局
- 局部与局部之间联系往往不太紧密
- 我们不需要神经网络中的每个结点都掌握全局的知识,因此可以从这里减少需要学习的参数数量
Weight share
- 但这样参数其实还是挺多的,所以有了另一种方法:权值共享
Share Parameters across space
- 取图片的一小块,在上面做神经网络分析,会得到一些预测
将切片做好的神经网络作用于图片的每个区域,得到一系列输出
可以增加切片个数提取更多特征
- 在这个过程中,梯度的计算跟之前是一样的
Concept
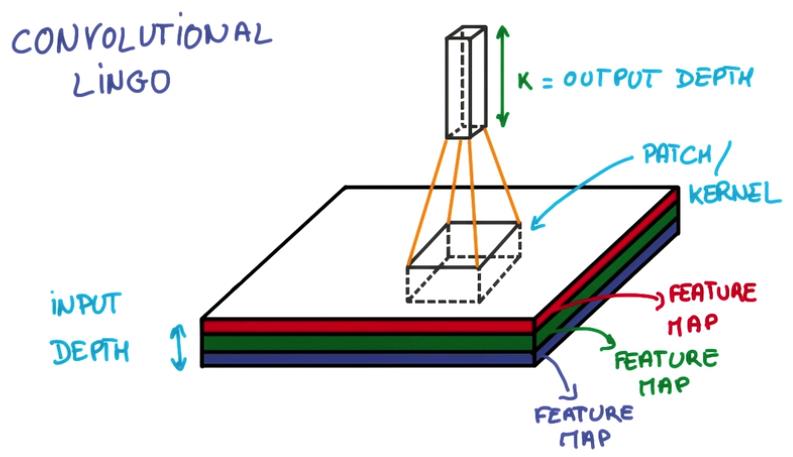
- Patch/Kernel:一个局部切片
- Depth: 数据的深度,图像数据是三维的,长宽和RGB,神经网络的预测输出也属于一维
- Feature Map:每层Conv网络,因为它们将前一层的feature映射到后一层(Output map)
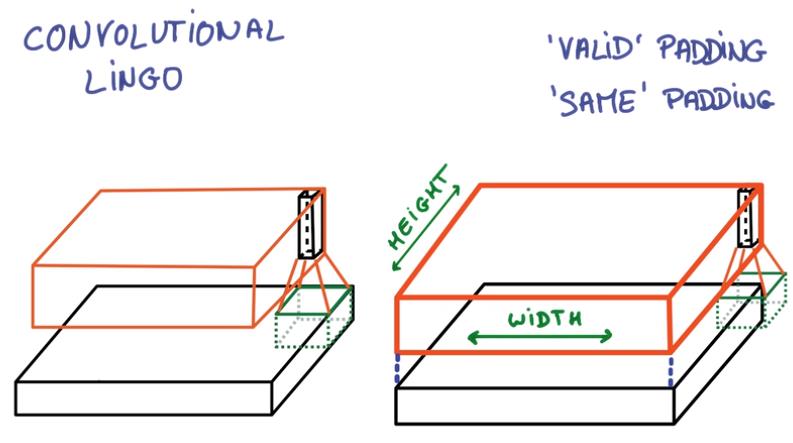
- Stride: 移动切片的步长,影响取样的数量
- 在边缘上的取样影响Conv层的面积,由于移动步长不一定能整除整张图的像素宽度,不越过边缘取样会得到Valid Padding, 越过边缘取样会得到Same Padding
- Example
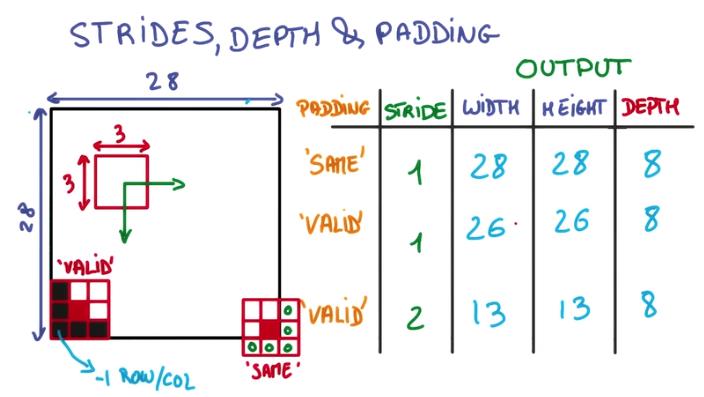
- 用一个3x3的网格在一个28x28的图像上做切片并移动
- 移动到边缘上的时候,如果不超出边缘,3x3的中心就到不了边界
- 因此得到的内容就会缺乏边界的一圈像素点,只能得到26x26的结果
- 而可以越过边界的情况下,就可以让3x3的中心到达边界的像素点
- 超出部分的矩阵补零就行
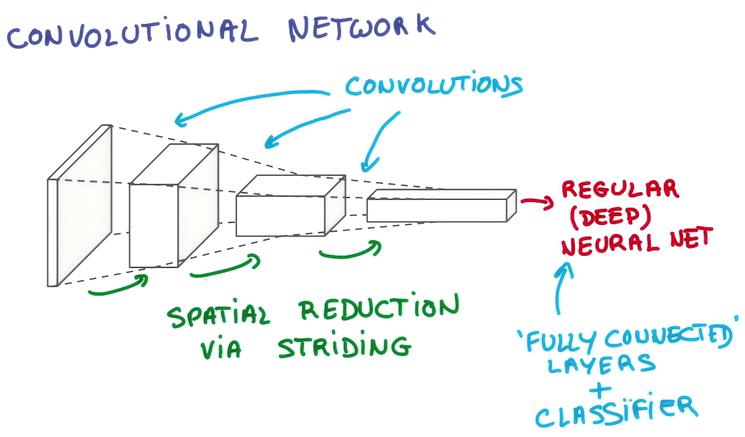
Deep Convnet
在Convnet上套Convnet,就可以一层一层综合局部得到的信息
OutPut
将一个deep and narrow的feature层作为输入,传给一个Regular神经网络
Optimization
Pooling
将不同Stride的卷积用某种方式合并起来,节省卷积层的空间复杂度。
- Max Pooling
在一个卷积层的输出层上取一个切片,取其中最大值代表这个切片 - 优点
- 不增加需要调整的参数
- 通常比其他方法准确
- 缺点:更多Hyper Parameter,包括要取最值的切片大小,以及去切片的步长
LENET-5, ALEXNET
- Average Pooling
在卷积层输出中,取切片,取平均值代表这个切片
1x1 Convolutions
在一个卷积层的输出层上,加一个1x1的卷积层,这样就形成了一个小型的神经网络。
- cheap for deeper model
- 结合Average Pooling食用效果更加
Inception
对同一个卷积层输出,执行各种二次计算,将各种结果堆叠到新输出的depth方向上
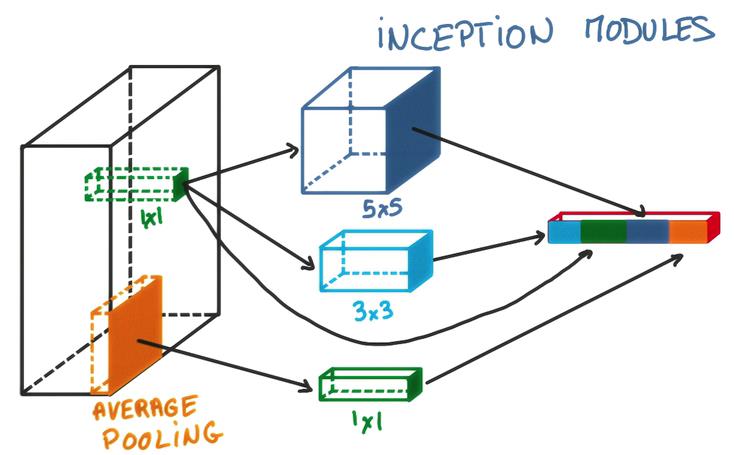
TensorFlow卷积神经网络实践
数据处理
- dataset处理成四维的,label仍然作为one-hot encoding
def reformat(dataset, labels, image_size, num_labels, num_channels):
dataset = dataset.reshape(
(-1, image_size, image_size, num_channels)).astype(np.float32)
labels = (np.arange(num_labels) == labels[:, None]).astype(np.float32)
return dataset, labels- 将lesson2的dnn转为cnn很简单,只要把WX+b改为conv2d(X)+b即可
- 关键在于conv2d
tf.nn.conv2d(input, filter, strides, padding, use_cudnn_on_gpu=None, data_format=None, name=None)
给定四维的input和filter tensor,计算一个二维卷积
Args:
input: ATensor. type必须是以下几种类型之一:half,float32,float64.filter: ATensor. type和input必须相同strides: A list ofints.一维,长度4, 在input上切片采样时,每个方向上的滑窗步长,必须和format指定的维度同阶padding: Astringfrom:"SAME", "VALID". padding 算法的类型use_cudnn_on_gpu: An optionalbool. Defaults toTrue.data_format: An optionalstringfrom:"NHWC", "NCHW", 默认为"NHWC"。
指定输入输出数据格式,默认格式为”NHWC”, 数据按这样的顺序存储:
[batch, in_height, in_width, in_channels]
也可以用这种方式:”NCHW”, 数据按这样的顺序存储:
[batch, in_channels, in_height, in_width]name: 操作名,可选.
Returns:
A Tensor. type与input相同
Given an input tensor of shape [batch, in_height, in_width, in_channels]
and a filter / kernel tensor of shape
[filter_height, filter_width, in_channels, out_channels]
conv2d实际上执行了以下操作:
- 将filter转为二维矩阵,shape为
[filter_height * filter_width * in_channels, output_channels]. - 从input tensor中提取image patches,每个patch是一个virtual tensor,shape
[batch, out_height, out_width,.
filter_height * filter_width * in_channels] - 将每个filter矩阵和image patch向量相乘
具体来讲,当data_format为NHWC时:
output[b, i, j, k] =
sum_di, dj, q input[b, strides[1] * i + di, strides[2] * j + dj, q] *
filter[di, dj, q, k]
input 中的每个patch都作用于filter,每个patch都能获得其他patch对filter的训练
需要满足strides[0] = strides[3] = 1. 大多数水平步长和垂直步长相同的情况下:strides = [1, stride, stride, 1].
- 然后再接一个WX+b连Relu连WX+b的全连接神经网络即可
Max Pooling
在tf.nn.conv2d后面接tf.nn.max_pool,将卷积层输出减小,从而减少要调整的参数
tf.nn.max_pool(value, ksize, strides, padding, data_format='NHWC', name=None)
Performs the max pooling on the input.
Args:
value: A 4-DTensorwith shape[batch, height, width, channels]and
typetf.float32.ksize: A list of ints that has length >= 4. 要执行取最值的切片在各个维度上的尺寸strides: A list of ints that has length >= 4. 取切片的步长padding: A string, either'VALID'or'SAME'. padding算法data_format: A string. ‘NHWC’ and ‘NCHW’ are supported.name: 操作名,可选
Returns:
A Tensor with type tf.float32. The max pooled output tensor.
优化
仿照lesson2,添加learning rate decay 和 drop out,可以将准确率提高到90.6%
参考链接
觉得我的文章对您有帮助的话,给个star可好?
以上是关于Google 深度学习笔记 卷积神经网络的主要内容,如果未能解决你的问题,请参考以下文章