Spark调研笔记第6篇 - Spark编程实战FAQ
Posted slvher
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark调研笔记第6篇 - Spark编程实战FAQ相关的知识,希望对你有一定的参考价值。
本文主要记录我使用Spark以来遇到的一些典型问题及其解决办法,希望对遇到同样问题的同学们有所帮助。
1. Spark环境或配置相关
Q: Spark客户端配置文件spark-defaults.conf中,spark.executor.memory和spark.cores.max应该如何合理配置?
A: 配置前,需要对spark集群中每个节点机器的core和memory的配置有基本了解。比如由100台机器搭建的spark集群中,每个节点的配置是core=32且memory=128GB,那么,向该集群提交应用时,应注意cores.max和executor.memory配置的”和谐”。具体而言,需要先预估应用涉及到的数据量和计算量,然后最大限度压榨单机core和memory,尽量避免core和memory配置比例失衡的情况。
举个例子,若某个应用配置了cores.max=1000且executor.memory=512m,则这个配置比例明显不合理,因为每个节点只有32个cores,1000个cores需要占用集群32台机器,而每个executor(即集群中的每个节点)只申请512MB内存,也即该应用占用的32台机器的全部cores,但只占用0.5G*32=16GB内存,这意味着剩余的(128G-0.5G)*32=4080GB内存被浪费了。
总之,合理的配置应该是在保证cores和memory都尽可能少的情况下,使得spark计算速度能满足业务需求。实际配置时,可将memory配置为机器最大阈值,cores的数目按实际计算量合理设定,尽量减少任务占用的节点数。
Q: 关于数据源与spark集群的问题,考虑这种场景对spark性能的影响:数据源在位于南方的hdfs集群上,而spark集群位于北方机房。
A: 数据源集群与spark计算集群物理距离较远的情况下,spark读入数据时会由很大网络开销,对作业运行速度影响非常明显。因此,搭建集群时,要尽量让spark集群靠近数据源。
Q: 提交任务后,运行报错"spark java.lang.OutOfMemoryError: Java heap space",如何处理?
A: 这个错误的引发原因较多,比如代码中global变量太大(如加载了大字典)或rdd.collect()太大。Spark的调度逻辑对transformations operations是lazy evaluation策略,即只有遇到action operations时才会计算整个job chain上涉及到的transformations和action,而actions的输出如果不是写磁盘,就会输出到driver program,典型如spark客户端所在机器的终端。driver 的jvm默认heap space是数百MB,无法hold住由action返回的大数据集时,就会报OOM。
解决思路有2个:一个思路是修改代码逻辑,比如将超大变量拆分成多个变量后多步执行(如将大dict或set拆分成N个小的,每步执行完后,销毁当前的变量并构造新变量),这个思路是典型的时间换空间,不过有时候业务逻辑不一定能做这种拆分处理;另一个思路是提交spark应用前,合理配置相关参数,如在spark-defaults.conf中增加配置项spark.driver.memory 12G,具体配置思路可以参考StackOverflow的这篇帖子。
Q: 提交任务时spark客户端报错"No space left on device",如下图所示,如何解决?
A: 这是由于任务运行过程中,Spark客户端可能会在本机写临时文件,默认情况下,它会写到/tmp目录,很容易写满/tmp,从而导致报错。
解决方法是在Spark客户端spark-defaults.conf中明确指定临时文件的写入路径:
spark.local.dir /home/slvher/tools/spark-scratch
Q: Spark客户端提交任务后,spark job的日志默认是输出到console的,与用户print的调试日志混到一起,不方便调试,如何配置使spark的内部日志单独打印到文件?
A: Spark借助log4j打印日志,而log4j的打印行为可以通过在conf目录创建log4j.properties并进行配置来控制(建议拷贝conf/log4j.properties.template为log4j.properties来配置log4j的打印行为),具体配置方法可以参考log4j的官网文档,这里不赘述。
2. Spark应用编程相关
Q: 考虑这种场景:待提交的Application包含多个python files,其中一个是main入口,其它都是自定义的module files且它们之间有依赖关系,通过spark-submit(已用--py-files参数指定要上传的文件)提交任务时,报错"ImportError: No module named xxx",如何解决?
A: 通过--py-files参数上传的.py文件只是上传而已,默认不会在集群节点python环境中将在这些文件中定义的module(s)加入解释器的search path。Spark文档Submiiting Applications其实对这种场景下提交任务的方式做了说明:
For Python, you can use the --py-files argument of spark-submit to add .py, .zip or .egg files to be distributed with your application. If you depend on multiple Python files we recommend packaging them into a .zip or .egg.
所以,正确的提交方法是,将除main入口以外的.py文件做成package(将这些文件放到某个目录下,并在该目录创建名为__init__.py的空文件)并打包成zip archives,然后通过--py-files上传这个zip包。因为python解释器默认可以处理zip archives的import场景,且由于上传的zip是个包含__init__.py的package,故集群节点机器上的python解释器会自动把它们加入对module的搜索路径中,这样就解决了Import Error的问题。
Q: 如何查看函数中通过print打印的调试信息?
A: Spark应用在传给spark operations api的函数中print的调试信息在本地driver program端是看不到的,因为这些函数是在集群节点上执行的,故这些print信息被打印到了为作业分配的节点机器上,需要从spartk master的http查看接口找到提交的应用,然后去应用执行节点的stderr中看看。
Q: PySpark的API中,map和flatMap有何区别?
A: 从函数行为来看,它们都是接受一个自定义函数f,然后对RDD中的每个元素调用这个函数。关键区别在于自定义函数f的类型:map接受的函数返回一个普通value;而flatMap接受的函数必须返回一个iterable value,即返回值必须可用于迭代,然后flatMap会对这个iterable value做flat操作(迭代这个value并flat成list)。可以借助下面的demo来理解。
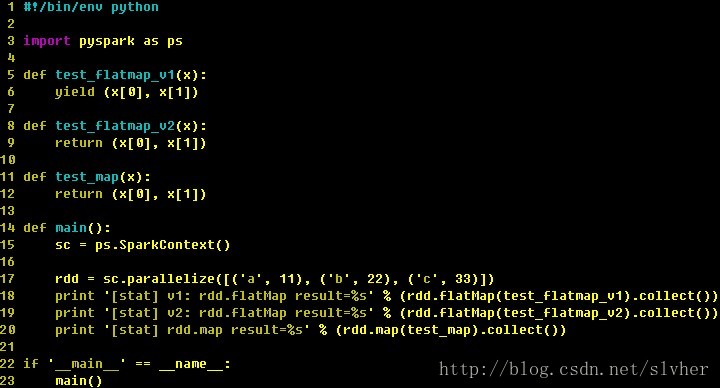
在spark集群上的执行结果如下:

下面对输出的每行结果稍做解释:
a. 代码第18行,rdd.flatMap接受的函数参数是test_flatmap_v1,而后者返回值是一个可迭代的generator object,故flatMap对返回值做flat操作后,generator object的每个element作为最终flattened结果的element。
b. 代码第19行,rdd.flatMap接受的函数参数是test_flatmap_v2,而后者返回值一个set,由于这个set本身是iterable的,故flatMap对set做flat操作后,set中的每个element做完最终flattened结果的element。
特别注意:若return的value不支持iterate(如int型),则flatMap会不错。感兴趣的话,可以亲自试验下。
c. 代码第20行,由于map不要求其函数参数的返回值是否iterable,也不会对iterable的value做flat操作,它只是将return value本身作为最终结果的一个element,因此它的输出结果也就很容易理解了。
Q: 对rdd执行cache有何注意事项?
A: 关于rdd persist对性能优化的原理,可以查看这里Persisting RDD in Spark,但并不是所有的persist/cache操作都与spark性能正相关。在persist前,最好遵循下面的原则:
a) rdd会被多次使用时再考虑cache
b) rdd需cache时,尽量对"靠近"算法的rdd做cache,而不要cache读入的raw数据
c) cache的rdd不再使用时,尽快调用unpersist释放其占用的集群资源(主要是memory)
Q: 如何在传给spark transformations操作的函数中访问共享变量?
A: 根据官网Programming Guide文档说明(参见这里),当作为参数传给spark操作(如map或reduce)的函数在远程机器的节点上执行时,函数中使用到的每个变量的副本(separate copies)也会被拷贝到这些节点上以便函数访问,如果这些变量在节点上被修改,那这些修改不会被反传回spark driver program,即在实现业务代码时,应由实现者保证这些变量的只读特性。因为在不同任务间维护通用的、支持读/写的共享变量会降低spark效率。
举个例子,下面的代码说明了如何在传给spark操作的函数中借助全局变量实现共享访问:
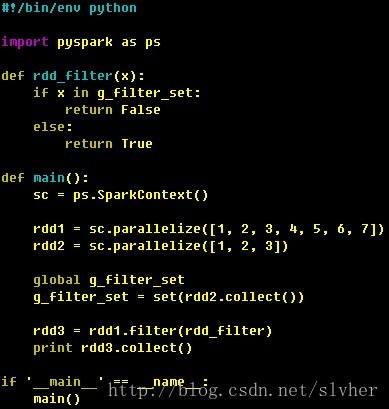
Q: 除通过global variable共享变量外,spark还支持什么方式共享变量?
A: Spark还支持broadcast变量和accumulators这两种共享变量的方式。其中,broadcast允许开发者在spark集群的每个节点上保持变量的一份只读cache,本质上,broadcast变量也是global变量,只不过它是由开发者显式分发到集群节点上的,而非spark根据每个task调用的函数对变量的访问情况自动拷贝。至于accumulators,顾名思义,它只支持add操作,具体语法可参考spark programming guide关于accumulators部分的说明。
Q: broadcast变量与普通global变量有何关系?各自的适用场合?
A: 实际上,broadcast变量是一种global变量,它们均可以实现在分布式节点中执行函数时共享变量。其中,普通global变量是随着spark对task的调度根据实际情况由spark调度器负责拷贝至集群节点的,这意味着若有需访问某global变量的多个task执行时,每个task的执行均有变量拷贝过程;而broadcast变量则是由开发者主动拷贝至集群节点且会一直cache直至用户主动调用unpersist或整个spark作业结束。
PS: 实际上,即使调用unpersist也不会立即释放资源,它只是告诉spark调度器资源可以释放,至于何时真正释放由spark调度器决定,参见SPARK-4030。
结论:若共享变量只会被某个task使用1次,则使用普通global变量共享方式即可;若共享变量会被先后执行的多个tasks访问,则broadcast方式会节省拷贝开销。
再次提醒:若使用了broadcast方式共享变量,则开发者应在确定该变量不再需要共享时主动调用unpersist来释放集群资源。
Q: 还有其他注意事项吗?
A: 上面提到的只是最常见的问题,实际编写复杂Spark应用时,如何高效利用spark集群的其它注意事项,强烈推荐参考Notes on Writing Complex Spark Applications这篇文章(Google Docs需翻墙访问)。
【参考资料】
1. StackOverflow: spark java.lang.OutOfMemoryError: Java heap space
2. Spark Doc: Submitting Applications
3. Spark Programming Guide: Shared Variables
4. Spark Issues: [SPARK-4030] "destroy" method in Broadcast should be public
5. [GoogleDoc] Notes on Writing Complex Spark Applications
========================= EOF =======================
以上是关于Spark调研笔记第6篇 - Spark编程实战FAQ的主要内容,如果未能解决你的问题,请参考以下文章