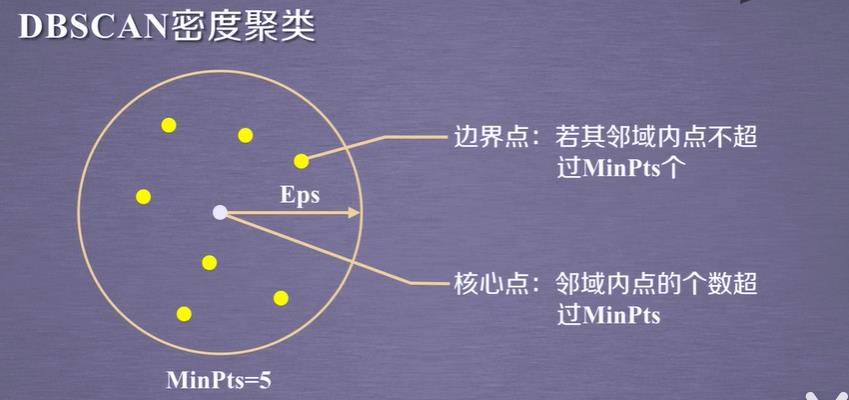
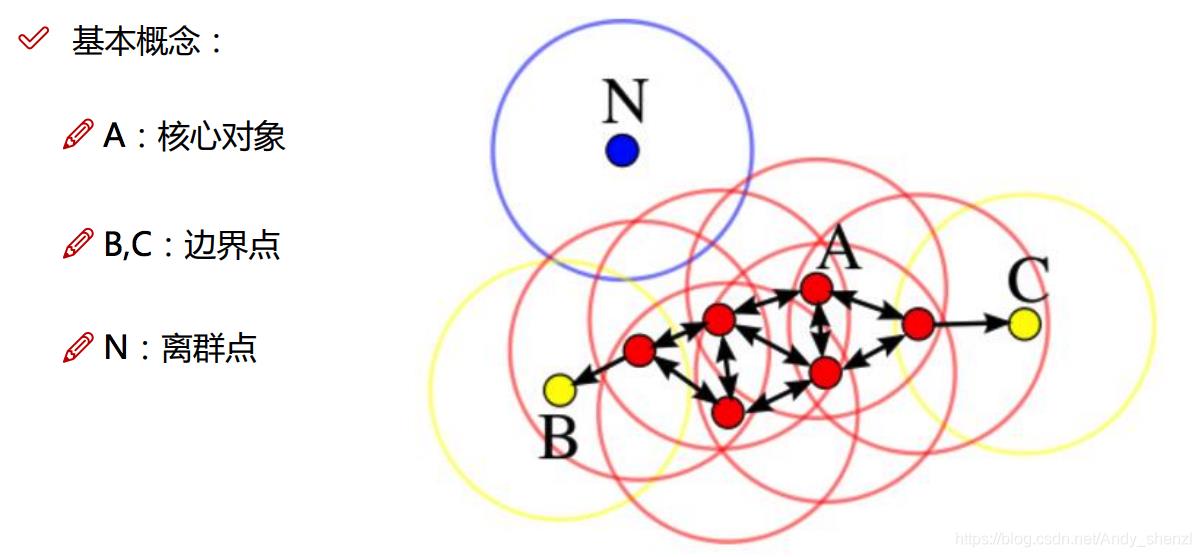
机器学习 sklearn 无监督学习 聚类算法 DBSCAN
Posted 404detective
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习 sklearn 无监督学习 聚类算法 DBSCAN相关的知识,希望对你有一定的参考价值。



import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import DBSCAN
from sklearn.cluster import KMeans
from sklearn import datasets
# 生成数据
x1, y1 = datasets.make_circles(n_samples=2000, factor=0.5, noise=0.05)
x2, y2 = datasets.make_blobs(n_samples=1000, centers=[[1.2, 1.2]], cluster_std=[[0.1]])
x = np.concatenate((x1, x2))
# k-means方法聚类
model = KMeans(n_clusters=3)
model.fit(x)
y_pred = model.predict(x)
plt.scatter(x[:, 0], x[:, 1], c=y_pred)
# DBSCAN方法聚类
model = DBSCAN(eps=0.2, min_samples=50)
model.fit(x)
y_pred = model.fit_predict(x)
plt.figure()
plt.scatter(x[:, 0], x[:, 1], c=y_pred)
plt.show()
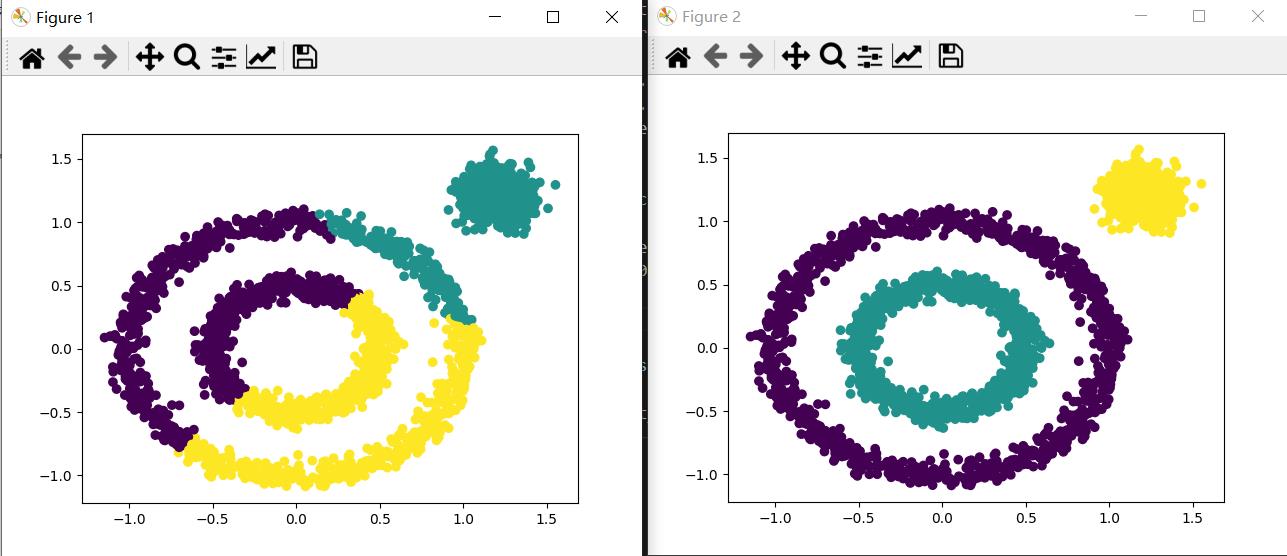
k-means聚类方法,它有一个很大的缺陷,就是它对于简单成团的数据样本聚类效果较好,但是对于复杂的样本数据分布就搞不定了,比如环形分布的样本数据。
应用

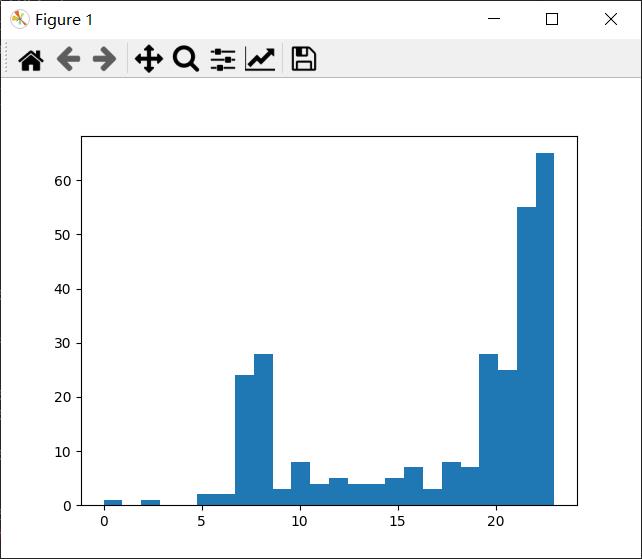
先放一下直方图,集中在7、8、20、21、22、23。(6类)
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import DBSCAN
from sklearn import metrics
def loadData(filePath):
f = open(filePath)
lines = f.readlines()
# print(lines)
mac2id=dict()
online_times=[]
for line in lines:
# lines[1]
# 2c929293466b97a6014754607e457d68,U201215025,A417314EEA7B,10.12.49.26,2014-07-20 22:44:18.540000000,2014-07-20 23:10:16.540000000,1558,15,本科生动态IP模版,100元每半年,internet
# .split(',' )[0] .split(',' )[1] .......
mac=line.split(',' )[2]
#1558时间单位为秒
online_time=int(line.split(',')[6])
# line.split(',')[4] 2014-07-20 22:44:18.540000000
# .split(' ')[1] 22:44:18.540000000
# .split(':')[0] 22
start_time= int(line.split(',')[4].split(' ')[1].split(':')[0])
# print(mac,online_time,start_time)
if mac not in mac2id:
mac2id[mac]= len(online_times)
# print(mac2id) #'A417314EEA7B': 0, 'F0DEF1C78366': 1, '88539523E88D': 2,,,,
# print(online_times) #[(22, 1558), (12, 40261),,,,()]
online_times.append((start_time,online_time/12000))
else:
#如果有相同的MAC地址 则以最后一条为准 实际上没有
online_times[mac2id[mac]]=[(start_time,online_time)]
print(online_times)
# print(online_times) [(22, 1558), (12, 40261),,,,,
# print(np.array(online_times)) .reshape((-1,2))要两列数据 -1为unspecified value
# [[ 22 1558]
# [ 12 40261]
# [ 22 1721].....]
#
real_X=np.array(online_times).reshape((-1,2))
return real_X
X=loadData("E:\\Desktop\\python_code\\sklearn\\课程数据\\聚类\\\\time2.txt")
# print(X)
db=DBSCAN(eps=0.5 ,min_samples=20,metric='euclidean').fit(X)
labels = db.labels_
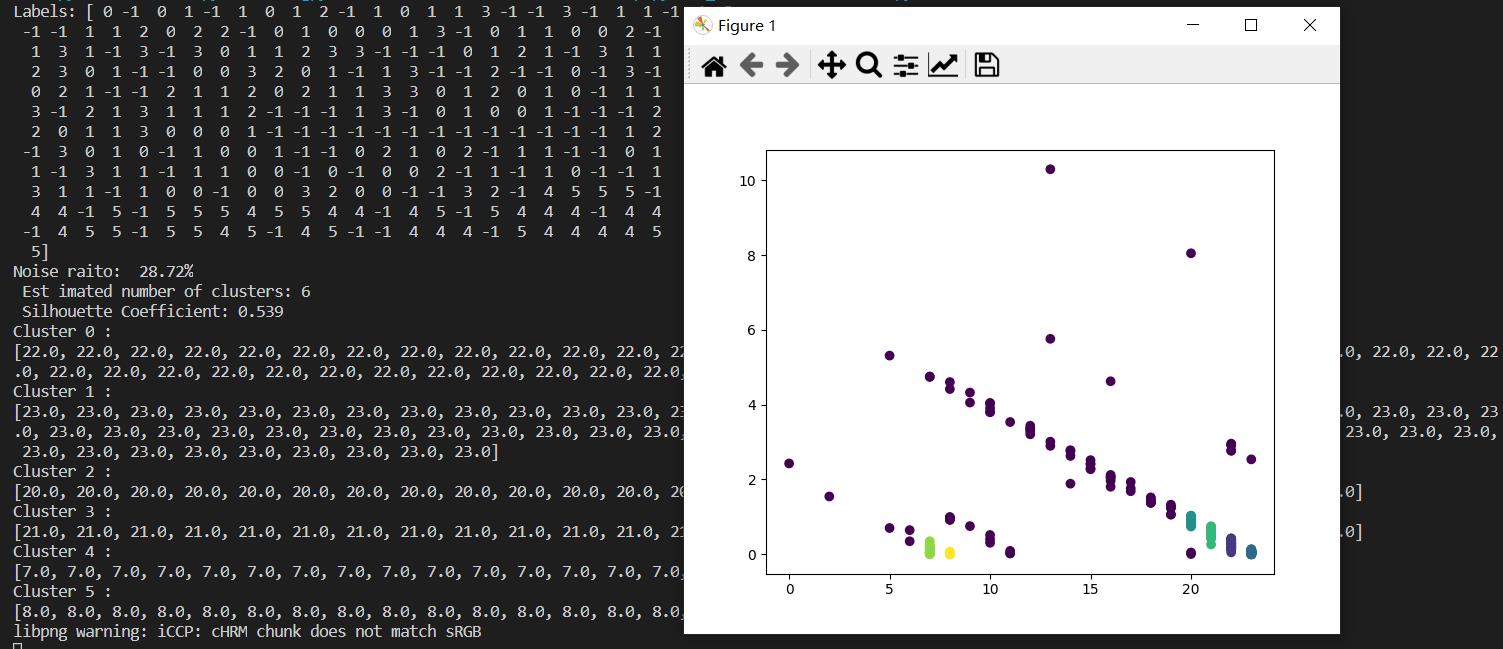
print('Labels:',labels)
raito=len(labels[labels[:] == -1]) / len(labels)
print( 'Noise raito: ',format(raito,'.2%'))
n_clusters_= len(set(labels)) - (1 if -1 in labels else 0)
print( ' Est imated number of clusters: %d' % n_clusters_)
print( " Silhouette Coefficient: %0.3f" % metrics.silhouette_score(X, labels))
for i in range(n_clusters_):
print('Cluster',i,':')
print(list(X[labels == i,0].flatten()))
plt.scatter(X[:, 0], X[:, 1],c=labels)
plt.show()
# plt.hist(X[:,0],24)
# plt.show()
课程中的代码有问题,对应参数是不会得出课程中的结果。
不断调参,尝试。
经过思考,发现了问题,横轴间距太小,如果调大eps,必然会横向误判。
如果纵向缩小一些。。。
于是尝试进行了归一化,结果与课程相符。
不过课程后面提到用对数变换,不过我貌似那是针对第二个例子。应该也可以。
以上是关于机器学习 sklearn 无监督学习 聚类算法 DBSCAN的主要内容,如果未能解决你的问题,请参考以下文章