Keras深度学习实战——基于编码器-解码器的机器翻译模型
Posted 盼小辉丶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Keras深度学习实战——基于编码器-解码器的机器翻译模型相关的知识,希望对你有一定的参考价值。
Keras深度学习实战——基于编码器-解码器的机器翻译模型
0. 前言
在《机器翻译模型》一节中,我们已经学习了机器翻译的基本概念,并使用 Keras 构建了两种基本的机器翻译模型,但由于在传统模型中所有输入时间戳的信息仅存储在最后一个网络中间状态值中,因此会丢失大量信息。本节中,通过引入编码器-解码器结构改善机器翻译模型,以获得更加优秀的性能。
1. 模型与数据集分析
1.1 数据集分析
在本节中,我们继续使用在《机器翻译模型》一节中使用的数据集,并使用相同的数据预处理过程,因此在继续学习之前,需要结合《机器翻译模型》一节阅读。
1.2 模型分析
针对传统《机器翻译模型》体系结构的缺陷,我们从以下两个方面进行修改:
- 生成翻译时,利用单元状态中存在的信息
- 在预测下一个单词时,同时将先前翻译的单词用作输入
第二种技术称为 Teacher Forcing,其本质上,在生成当前时间戳输出时同时利用前一个时间戳的实际值作为输入,可以更快、更精确地调整网络。
我们用于构建编码器-解码器体系结构进行机器翻译的策略如下:
- 准备输入和输出数据集,包括
2个解码数据集:- 与
encoder_input_data结合的decoder_input_data作为输入(decoder_input_data以start单词开头),decoder_target_data作为输出
- 与
- 当我们在解码器中预测第
1个单词时,使用输入的单词集,将其转换为向量,然后通过一个以start作为输入的解码器模型传递, 预期输出是输出中start后的第一个单词 - 按照以上方式,将实际输出中的第
1个单词同时作为输入,预测第2个单词 - 基于此策略计算模型的准确率
2. 基于编码器-解码器结构的机器翻译模型
2.1 基于编码器-解码器体系结构
根据我们在上一小节分析的策略,我们继续使用在《机器翻译模型》中预处理后的输入和输出数据集构建模型。
(1) 建立模型,首先构建编码器网络:
embedding_size = 128
encoder_inputs = Input(shape=(None,))
en_x= Embedding(num_encoder_tokens+1, embedding_size)(encoder_inputs)
encoder = LSTM(256, return_state=True)
encoder_outputs, state_h, state_c = encoder(en_x)
encoder_states = [state_h, state_c]
(2) 由于我们需要提取编码器网络中间层的输出,且需要传递这些输出作为解码器输入,因此使用函数式 API。接下来,我们构建解码器网络:
decoder_inputs = Input(shape=(None,))
dex= Embedding(num_decoder_tokens+1, embedding_size)
final_dex= dex(decoder_inputs)
decoder_lstm = LSTM(256, return_sequences=True, return_state=True)
decoder_outputs, _, _ = decoder_lstm(final_dex, initial_state=encoder_states)
decoder_outputs = Dense(2000,activation='tanh')(decoder_outputs)
decoder_dense = Dense(num_decoder_tokens+1, activation='softmax')
decoder_outputs = decoder_dense(decoder_outputs)
(3) 最后,整合编码器-解码器,构建用于机器翻译的神经网络模型:
model3 = Model([encoder_inputs, decoder_inputs], decoder_outputs)
model3.summary()
构建的模型简要信息输入如下:
Model: "functional_1"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, None)] 0
__________________________________________________________________________________________________
input_2 (InputLayer) [(None, None)] 0
__________________________________________________________________________________________________
embedding (Embedding) (None, None, 128) 51200 input_1[0][0]
__________________________________________________________________________________________________
embedding_1 (Embedding) (None, None, 128) 53376 input_2[0][0]
__________________________________________________________________________________________________
lstm (LSTM) [(None, 256), (None, 394240 embedding[0][0]
__________________________________________________________________________________________________
lstm_1 (LSTM) [(None, None, 256), 394240 embedding_1[0][0]
lstm[0][1]
lstm[0][2]
__________________________________________________________________________________________________
dense (Dense) (None, None, 2000) 514000 lstm_1[0][0]
__________________________________________________________________________________________________
dense_1 (Dense) (None, None, 417) 834417 dense[0][0]
==================================================================================================
Total params: 2,241,473
Trainable params: 2,241,473
Non-trainable params: 0
__________________________________________________________________________________________________
(4) 编译并拟合构建完成的编码器-解码器模型:
model3.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['acc'])
history = model3.fit([encoder_input_data, decoder_input_data], decoder_target_data,
batch_size=32,
epochs=10,
validation_split=0.1)
(5) 计算正确翻译单词的占验证数据集中单词总数的百分比:
act = np.argmax(decoder_target_data, axis=2)
count = 0
correct_count = 0
pred = model3.predict([encoder_input_data[90000:],decoder_input_data[90000:]])
for i in range(10000):
t = np.argmax(pred[i], axis=1)
correct_count += np.sum((act[90000+i]==t) & (act[90000+i]!=target_token_index['end']))
count += np.sum(decoder_input_data[90000+i]!=target_token_index['end'])
print(correct_count/count)
# 0.522991966585094
计算完成后,我们可以看到大约有 52.30% 的单词可以被正确翻译。但是使用以上方法,在测试数据集上计算准确性时,我们不应使用 decoder_input_data,因为在实时场景中我们无法访问此数据。
(6) 因此,在实际中,我们应当将前一时间戳中的预测结果单词用作当前时间戳的解码器输入单词。首先,重新初始化 decoder_input_data 为 decoder_input_data_pred:
decoder_input_data_pred = np.zeros(
(len(lines.fr), fr_max_length),
dtype='float32')
final_pred = []
for i in range(10000):
word = target_token_index['start']
for j in range(fr_max_length):
decoder_input_data_pred[(90000+i), j] = word
pred = model3.predict([encoder_input_data[(90000+i)].reshape(1,eng_max_length),decoder_input_data_pred[90000+i].reshape(1,fr_max_length)])
t = np.argmax(pred[0][j])
word = t
if word==target_token_index['end']:
break
final_pred.append(list(decoder_input_data_pred[90000+i]))
在以上代码中,使用变量 word 对应 start 单词的索引。我们将单词 start 作为解码器输入中的第一个单词传递,并用预测概率最高的单词作为下一时间戳的结果。一旦我们预测了第 2 个单词,将更新 dcoder_input_word_pred,然后继续预测第 3 个单词,重复此过程,直到直到遇到停止词 end。
(7) 由于我们已经修改了预测翻译测试集单词的方法,因此需要重新计算翻译的准确率:
final_pred2 = np.array(final_pred)
count = 0
correct_count = 0
for i in range(10000):
correct_count += np.sum((decoder_input_data[90000+i]==final_pred2[i]) & (decoder_input_data[90000+i]!=target_token_index['end']))
count += np.sum(decoder_input_data[90000+i]!=target_token_index['end'])
print(correct_count/count)
# 0.5462158647594278
结果表示通过此方法,大约有 54.62% 的单词可以被正确翻译。尽管与传统的方法相比,翻译的准确率有了很大的提高,但我们并未考虑单词对齐问题,即源语言中位于开头的单词在目标语言中同样可能位于开头位置。因此,我们可以针对此问题进一步提高模型性能。
2.2 基于注意力机制的编码器-解码器体系结构
在上一小节中,我们了解到可以通过使用 Teacher Forcing 技术来提高翻译的准确率,该技术将目标输出中前一个时间戳中的实际单词用作模型的输入。
在本小节中,我们将进一步扩展此思想,并根据编码器和解码器向量在每个时间戳的相似度,为输入编码分配权重。通过这种方式,我们可以使某些单词在编码器的隐式向量中具有更高的权重,具体取决于解码器的时间戳。 接下来,让我们介绍如何构建基于注意力机制 (Attention Mechanism) 的编码器-解码器体系结构,关于注意力机制的介绍,可以参考《自注意力机制》。
(1) 首先,构建编码器:
embedding_size = 128
from keras.layers import Dropout, dot, Activation, concatenate
encoder_inputs = Input(shape=(eng_max_length,))
en_x= Embedding(num_encoder_tokens+1, embedding_size)(encoder_inputs)
en_x = Dropout(0.1)(en_x)
encoder = LSTM(256, return_sequences=True, unroll=True)(en_x)
encoder_last = encoder[:,-1,:]
(2) 然后,构建解码器:
decoder_inputs = Input(shape=(fr_max_length,))
dex= Embedding(num_decoder_tokens+1, embedding_size)
decoder= dex(decoder_inputs)
decoder = Dropout(0.1)(decoder)
decoder = LSTM(256, return_sequences=True, unroll=True)(decoder, initial_state=[encoder_last, encoder_last])
在以上代码中,我们尚未完全完成解码器体系结构,仅在解码器处提取了网络输出值。
(3) 构建注意力机制。注意力机制的构建基于每个时间戳编码器输出向量和解码器输出向量的相似度。基于这种相似性,使用 softmax 函数得到权重值,将权重分配给编码器向量。
将编码器和解码器向量通过激活层和全连接层,以便在获得向量点积前实现进一步的非线性,向量点积作为相似度的度量方法,即余弦相似度:
t = Dense(5000, activation='tanh')(decoder)
t2 = Dense(5000, activation='tanh')(encoder)
attention = dot([t, t2], axes=[2, 2])
确定要赋予每个输入时间戳的权重:
attention = Dense(eng_max_length, activation='tanh')(attention)
attention = Activation('softmax')(attention)
计算加权编码器向量:
context = dot([attention, encoder], axes = [2,1])
将解码器和加权编码器向量串联起来:
decoder_combined_context = concatenate([context, decoder])
将解码器和加权编码向量的串联结果连接到输出层:
output_dict_size = num_decoder_tokens+1
decoder_combined_context=Dense(2000, activation='tanh')(decoder_combined_context)
output=(Dense(output_dict_size, activation="softmax"))(decoder_combined_context)
(4) 编译并拟合模型:
model4 = Model(inputs=[encoder_inputs, decoder_inputs], outputs=[output])
model4.compile(optimizer='adam', loss='categorical_crossentropy',metrics = ['acc'])
history = model4.fit([encoder_input_data, decoder_input_data],
decoder_target_data,
batch_size=32,
epochs=10,
validation_split=0.1)
(5) 保存基于注意力机制的编码器-解码器模型架构图:
from keras.utils import plot_model
plot_model(model4, show_shapes=True, show_layer_names=True, to_file='model.png')
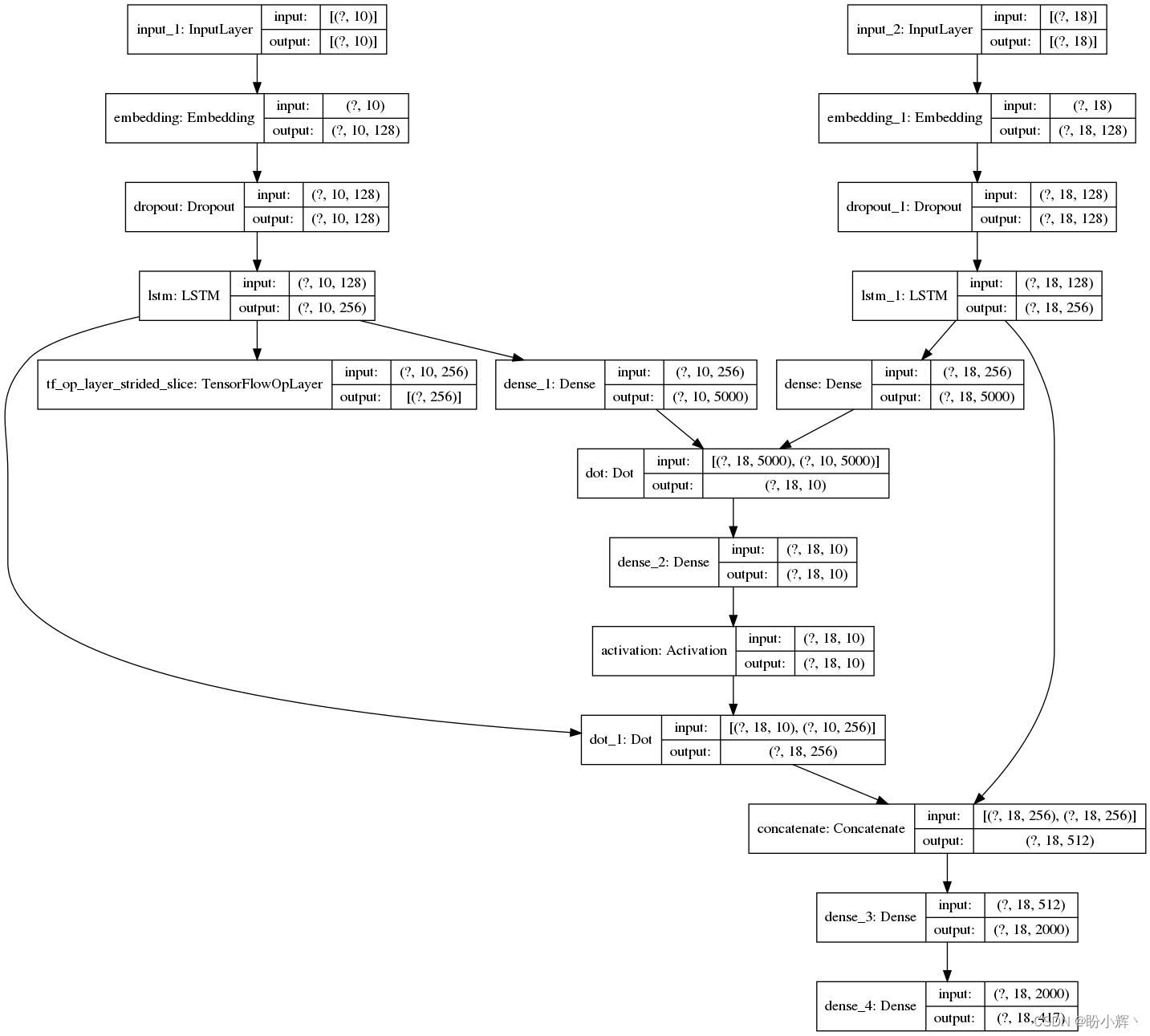
拟合模型后,可以看到该模型在测试集上的性能表现较未使用注意力机制的模型更加优异。
(6) 接下来,我们同样计算翻译的准确率:
decoder_input_data_pred = np.zeros(
(len(lines.fr), fr_max_length),
dtype='float32')
final_pred_att = []
for i in range(10000):
word = target_token_index['start']
for j in range(fr_max_length):
decoder_input_data_pred[(90000+i), j] = word
pred = model4.predict([encoder_input_data[(90000+i)].reshape(1,eng_max_length),decoder_input_data_pred[90000+i].reshape(1,fr_max_length)])
t = np.argmax(pred[0][j])
word = t
if word==target_token_index['end']:
break
final_pred_att.append(list(decoder_input_data_pred[90000+i]))
final_pred2_att = np.array(final_pred_att)
count = 0
correct_count = 0
for i in range(10000):
correct_count += np.sum((decoder_input_data[90000+i]==final_pred2_att[i]) & (decoder_input_data[47500+i]!=target_token_index['end']))
count += np.sum(decoder_input_data[90000+i]!=target_token_index['end'])
print(correct_count/count)
# 0.56823102
结果表示,通过在模型中添加注意力机制,大约有 56.82% 的单词可以被正确翻译。
(7) 现在,我们已经构建了具有较为合理准确率的翻译系统。接下来,我们检查测试数据集中的一些翻译结果:
k = -5000
t = model4.predict([encoder_input_data[k].reshape(1,encoder_input_data.shape[1]),decoder_input_data[k].reshape(1,decoder_input_data.shape[1])]).reshape(decoder_input_data.shape[1], num_decoder_tokens+1)
# 英文句子
for i in range(len(encoder_input_data[k])):
if int(encoder_input_data[k][i])!=0:
print(list(input_token_index.keys())[int(encoder_input_data[k][i]-1)])
根据输入单词提取预测的翻译:
t2 = np.argmax(t,axis=1)
for i in range(len(t2)):
if int(t2[i])!=0:
print(list(target_token_index.keys())[int(t2[i]-1)])
将英语句子转换为法语后,上述代码的输出如下:
la unk unk toute la journée end
提取单词的实际对应法语:
t2 = decoder_input_data[k]
for i in range(len(t2)):
if int(t2[i])!=0:
print(list(target_token_index.keys())[int(t2[i]-1)])
前面代码的输出如下:
start les unk unk toute la journée end
我们看到预测的翻译与原始翻译相当接近。以类似的方式,我们可以查看验证数据集上的更多翻译结果:
| 预测结果 | 实际结果 |
|---|---|
| le train était été retard à unk end | le train avait du retard ce unk end |
| la était été unk par end | leau a été unk hier end |
| la unk unk toute la journée end | les unk unk toute la journée end |
从上表中,可以看到模型的翻译效果虽然不错,但是仍有一些潜在的改进之处:例如使用更多训练数据,而不仅仅使用前 10000 条数据,或使用更大的语料库。
小结
机器翻译是人工智能的重要方向之一,为提高机器翻译的准确性,在传统神经网络模型的基础上,引入了一种基于编码器-解码器的机器翻译模型,并通过注意力机制对卷积神经网络进行改进,以提高传统输入中的语义信息特征,然后实现目标语言的翻译;并使用 Keras 实现了以上两种机器翻译模型。
系列链接
Keras深度学习实战(1)——神经网络基础与模型训练过程详解 以上是关于Keras深度学习实战——基于编码器-解码器的机器翻译模型的主要内容,如果未能解决你的问题,请参考以下文章
Keras深度学习实战(2)——使用Keras构建神经网络
Keras深度学习实战(3)——神经网络性能优化技术
Keras深度学习实战(4)——深度学习中常用激活函数和损失函数详解
Keras深度学习实战(5)——批归一化详解
Keras深度学习实战(6)——深度学习过拟合问题及解决方法
Keras深度学习实战(7)——卷积神经网络详解与实现
Keras深度学习实战(8)——使用数据增强提高神经网络性能
Keras深度学习实战(9)——卷积神经网络的局限性
Keras深度学习实战(10)——迁移学习详解
Keras深度学习实战(11)——可视化神经网络中间层输出
Keras深度学习实战(12)——面部特征点检测
Keras深度学习实战(13)——目标检测基础