程序员自我修养阅读笔记——内存
Posted 落樱弥城
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了程序员自我修养阅读笔记——内存相关的知识,希望对你有一定的参考价值。
1 程序的内存布局
进程的虚拟地址空间一般包含几个部分:
- 内核使用的部分,进程不可访问,不同系统占用的大小不同;
- 栈内存:用于维护程序的临时变量和函数调用使用,分配与销毁由系统完成;
- 堆内存:用户可以通过特定的系统调用分配的内存,分配和释放由用户完成;
- 可执行文件映像:存储着可执行文件的内存映射;
- 保留区:内存中禁止访问的部分。
- 动态库映射区:用于加载动态库。

2 栈与调用约定
2.1 栈
在进程的VMA中,栈是一块具有FILO特性的内存区域,该区域的内存分配与释放由系统完成。VMA中的栈综上向下增长,即栈顶地址减小为压栈,栈顶地址增大为弹栈。一般esp寄存器保存栈顶的地址,即esp++表示弹栈,esp–表示入栈。
栈不仅仅可以保存临时变量,也是实现函数的重要工具。函数调用时,栈中会保存函数调用需要的信息,称之为堆栈帧或者活动记录。堆栈帧一般包含:
- 函数的返回地址和参数;
- 临时变量:包括函数的非静态局部变量和编译期自动生成的其他临时变量;
- 保存的上下文:包括在函数调用前后需要保持不变的寄存器。

函数执行时会使用到寄存器,一个是esp始终指向栈顶,另一个是ebp又称之为帧指针,始终指向一个固定的位置,即调用该函数之前的ebp。只有保存这个ebp,才能恢复到调用到调用前的状态。
一个函数调用的基本步骤如下:
- 把所有或者一部分参数压入栈中,如果其他参数没有入栈则使用特定的寄存器传递;
- 把当前指令的下一条指令的地址压栈;
- 跳转到函数体中执行。
在函数返回时执行相反的过程,即弹栈,跳转到需要返回的地址。下面通过一个函数调用的反汇编说明上述过程。下面是使用到的main.c代码:
int add(int a)
return a + 2;
int main()
int a = 2;
a = add(3);
return 0;
使用gcc -S main.c将代码汇编为汇编代码,简略的代码如下(64位上rbp,rsp仅仅是32bit系统上ebp,esp的扩展):
add:
.LFB0:
.cfi_startproc
pushq %rbp #将rbp压入栈
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp #让rbp指向当前的栈顶,即rsp
.cfi_def_cfa_register 6
movl %edi, -4(%rbp) # edi的值拷贝到rbp - 4
movl -4(%rbp), %eax #%eax = %ebp - 2
addl $2, %eax #%eax = 2 + %eax
popq %rbp # 弹出rbp
.cfi_def_cfa 7, 8
ret
main:
.LFB1:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
subq $16, %rsp #移动rsp栈顶指针,预留一部分空间
movl $2, -4(%rbp) # a = 2,a的地址是rbp - 4
movl $3, %edi # %edi = 3
call add #jump to add
movl %eax, -4(%rbp) #将eax的值写入到rbp - 4,即a
movl $0, %eax
leave
大部分函数调用的汇编代码符合上面的基本流程,但是并不是所有的,有些为了达到优化的效果,会修改进入的方式,比如:
- 函数被声明为static;
- 函数仅仅在本单元被直接使用,没有显示或者隐式取地址(即没有任何函数指针指向过这个函数)。
2.2 调用约定
即函数调用时,是由调用者还是被调用者维护对应的栈,如何处理参数返回值等的约定,不同的约定规定不同,一般涉及:
- 函数传参的顺序和方式;
- 栈的维护方式;
- 符号名的修饰方式。
详细内容请参考调用约定。
2.3 函数返回值传递
对于比较小的数据,仅仅使用eax便可以返回,多余大于一个eax寄存器大小的返回值可以使用eax和edx联合返回。更大的返回值,eax存储返回值起始地址,栈上分配返回值所需字节的空间,将空间起始地址赋值给eax。这一条目前可能无法保证完全正确。
3 堆与内存管理
3.1 堆
栈上的数据由系统管理,安全且高效,但是无法适应比较大的内存和灵活的使用。而堆空间相比栈空间要大很多,C中用户可以使用malloc等api申请内存自行管理。
malloc的实现并不是每次都会调用到系统调用取申请一块内存,而是由运行库预先申请一块内存然后将该部分内存再分发给应用程序。因此应用程序面向的内存管理者实际上是运行库。
3.2 Linux进程堆管理
Linux提供了两种系统调用用于分配内存:brk和mmap。
brk的作用是设置进程数据段结束地址,可以扩大或者缩小数据段。
int brk(void *addr);
void *sbrk(intptr_t increment);
DESCRIPTION
brk() and sbrk() change the location of the program break, which defines the end of the process's data segment (i.e., the program break is the first location after the end of the uninitialized data segment). Increasing the program break has the effect of allocating memory to the process; decreasing the break deallocates memory.
brk() sets the end of the data segment to the value specified by addr, when that value is reasonable, the system has enough memory, and the process does not exceed its maximum data size (see setrlimit(2)).
sbrk() increments the program's data space by increment bytes. Calling sbrk() with an increment of 0 can be used to find the current location of the program break.
mmap的作用是想操作系统申请一块虚拟地址空间,该空间可能是某个映射文件,因此mmap可以用来做文件映射。
void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);
DESCRIPTION
mmap() creates a new mapping in the virtual address space of the calling process. The starting address for the new mapping is specified in addr. The length argument specifies the length of the mapping (which must be greater than 0).
glibc的malloc处理用户的空间申请的基本逻辑是:
- 当申请的空间大小小于128kb,则在现有的堆空间中,按照堆分配算法分配一块空间返回;
- 当申请的空间大小大于128kb,则利用
mmap函数分配一块匿名空间,然后在这个匿名空间中为用户分配空间。
而堆实际能够申请到的空间大小完全取决于进程空间中其他部分占用的空间的剩余,因此一般小于理论上的值,视具体情况而定。
3.3 windows进程堆管理
windows的继承VMA空间类似于linux,包含dll、exe影响文件、堆、栈。下图中栈存在多个的原因是多线程,每个线程有独立的栈。windwos系统提供了VirtualAlloc函数来向系统申请一块虚拟内存空间。使用该API要求系统空间大小必须为页的整数倍。
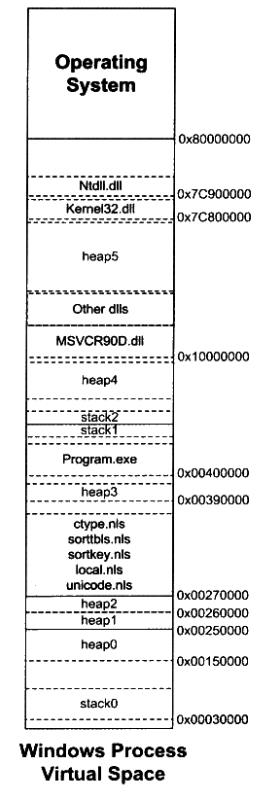
windows下又一个堆管理器,提供了一套与堆相关的API可以用来创建、分配、释放和销毁对空间:
HeapCreate:创建一个堆;HeapAlloc:在一个堆里面分配内存;HeapFree:释放已经分配的内存;HeapDestroy:销毁一个堆。
每个进程会默认有一个堆,该堆是在进程启动时创建直到进程结束都一直存在,默认堆大小为1Mb,当然也可以通过编译参数指定。
3.4 堆分配算法
堆管理算法就是管理一块从系统申请来的大块内存分配给应用程序,其基本思路类似于操作系统的内存管理,一般的方法有:
- 空闲链表法:用双向链表将所有空间链接串连起来,同时若用户申请了K个字节的内存大小,则分配K+4个字节的空间,额外的4个字节位于空间的起始位置,用来指示K的大小;
- 位图法:将堆划分个固定大小的块,每块大小相同。当用户请求内存时,总是分配整数块的空间,第一个块称为已分配区域的头(head),其余称为分配区域的主体(body);
- 对象池:对象池的思路很简单,如果每次分配的空间大小都一样(假设为K字节),那么就可以以此空间大小作为一个单位,把整个空间划分为大量的K字节大小的块,每次请求时只需要找到一个小块就可以。对象池的管理方法可以是空闲链表,也可以用位图。
实际应用时采用复合算法。比如对于glibc来说
- 对于小于64字节的空间申请,采用类似对象池的算法;
- 对于大于512字节的空间申请方法,采用最佳适配算法;
- 对于大于64字节小于512字节的空间申请,采用上述的最佳折衷策略;
- 对于大于128KB的申请,使用mmap机制。
以上是关于程序员自我修养阅读笔记——内存的主要内容,如果未能解决你的问题,请参考以下文章