利用二级指针进行链表操作
Posted yutianzuijin
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了利用二级指针进行链表操作相关的知识,希望对你有一定的参考价值。
Linus曾经在网上吐槽很多程序员不会写真正的底层核心代码,并用简单的单链表删除举例。常规的链表删除除了当前的遍历指针还需要维护一个prev指针,用来连接被删除节点的下一个节点,但实际上利用二级指针就可以避免多维护一个指针,使代码更加简洁。Linus的吐槽没错,到目前为止,我几乎没有在实际工作中看到过用二级指针进行链表删除的相关代码,除了各种网页中对Linus描述的解释。二级指针不光能够简化链表的删除操作,事实上它可以完成所有的链表操作。特别是在插入,删除,复制操作中更能简化代码,使代码更加整洁美观。
链表的插入
我们先来看一下链表的插入操作,插入可以选择在头部或者尾部插入,也可以根据某种条件在链表的任意位置插入。在头部插入比较简单,无需遍历链表,不做过多介绍,我们着重看一下尾部插入和有序插入两种情况。给出链表的定义:
typedef struct _Node
int value;
struct _Node* next;
Node;
typedef struct _LinkList
int len;
Node* head;
LinkList;
LinkList* createList()
LinkList* list=(LinkList*)malloc(sizeof(LinkList));
list->len=0;
list->head=NULL;
return list;
定义比较简单,和常规直接访问链表节点不同,我们在此对链表头进行了一个简单封装,方便我们对链表进行扩展。然后我们用常规的链表插入方法实现尾部插入和有序插入:
void insertTail(LinkList* list,int value)
Node* n=(Node*)malloc(sizeof(Node));
n->value=value;
n->next=NULL;
list->len++;
if(list->head==NULL)
list->head=n;
return;
Node* cur=list->head;
while(cur->next!=NULL)
cur=cur->next;
cur->next=n;
//降序
void insertSorted(LinkList* list,int value)
Node* n=(Node*)malloc(sizeof(Node));
n->value=value;
n->next=NULL;
list->len++;
Node* prev=NULL;
Node* cur=list->head;
while(cur!=NULL)
if(cur->value<value) break;
prev=cur;
cur=cur->next;
if(prev)
prev->next=n;
n->next=cur;
else
n->next=cur;
list->head=n;
这两种情况都需要遍历链表,而且需要针对链表头是否为空做分支判断。我们再看一下如何用二级指针来完成两种插入操作:
void insertTail2(LinkList* list,int value)
Node* n=(Node*)malloc(sizeof(Node));
n->value=value;
n->next=NULL;
list->len++;
Node** cur=&list->head;
while(*cur)
cur=&(*cur)->next;
*cur=n;
void insertSorted2(LinkList* list,int value)
Node* n=(Node*)malloc(sizeof(Node));
n->value=value;
list->len++;
Node** cur=&list->head;
while(*cur)
if((*cur)->value<value) break;
cur=&(*cur)->next;
n->next=*cur;
*cur=n;
利用二级指针来完成链表的插入操作,核心在于定义的遍历指针是Node**类型,而且无需对链表头是否为空进行判断,所以使代码更加简洁。从上面的代码我们也可以看出,二级指针也可以完成对链表的遍历,不过相比Node*方式的遍历,利用二级指针没有什么优势。利用二级指针可以简化链表插入的原理我们最后介绍。
链表的复制
我们再看看复制一个链表的操作,常规方法实现的代码如下:
LinkList* copyList(LinkList* list)
LinkList* newList=createList();
Node* cur=list->head;
Node* newCur=newList->head;
while(cur)
Node* n=(Node*)malloc(sizeof(Node));
n->value=cur->value;
if(newCur!=NULL)
newCur->next=n;
else
newList->head=n;
newCur=n;
cur=cur->next;
newCur->next=NULL;
newList->len=list->len;
return newList;
复制一个链表,相当于遍历原始链表,同时在新链表尾部插入节点。和单个节点插入一样,常规方法复制一个链表也需要判断链表头是否为空。利用二级指针也可以避免这个问题,同时简化代码:
LinkList* copyList2(LinkList* list)
LinkList* newList=createList();
Node* cur=list->head;
Node** newCur=&newList->head;
while(cur)
Node* n=(Node*)malloc(sizeof(Node));
n->value=cur->value;
*newCur=n;
newCur=&n->next;
cur=cur->next;
*newCur=NULL;
newList->len=list->len;
return newList;
链表的删除
最后看一下链表的删除操作,这块的介绍网上有非常多的文档,但是绝大多数都是对Linus描述的解释,我们在此给出可以执行的代码。常规的链表删除操作,删除链表中特定值的所有元素:
void deleteValue(LinkList* list,int value)
Node* prev=NULL;
Node* cur=list->head;
while(cur!=NULL)
Node* n=cur->next;
if(cur->value==value)
if(prev)
prev->next=n;
else
list->head=n;
free(cur);
else
prev=cur;
cur=n;
基于二级指针的链表删除操作:
void deleteValue2(LinkList* list,int value)
Node** cur=&list->head;
while(*cur!=NULL)
Node* entry=*cur;
if(entry->value==value)
*cur=entry->next;
free(entry);
else
cur=&entry->next;
通过对比链表的插入,复制和删除操作,我们可以发现二级指针相比常规方法可以简化代码,减少分支判断,所以非常值得大家在日常工作中使用。
链表的二级指针操作分析
虽然已经给出了代码,但是估计很多人对二级指针能完成上述操作的原理还是一脸懵逼,下面我就给出一个简单的分析。
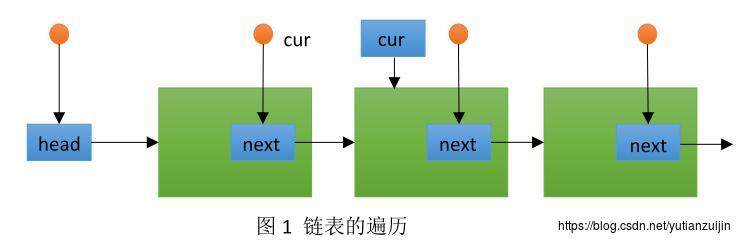
在上图中有三种类型的节点,绿色方框表示链表的节点Node,蓝色方框表示链表节点的指针Node*,橙色圆圈表示链表节点指针的指针也即二级指针Node**。
在常规的链表遍历中,我们用cur=cur->next来实现,这句代码实现的功能就是创建一个Node*指针使其指向下一个链表节点,犹如图中的蓝色cur一级指针一样。执行完这句代码之后,我们就和上一个节点没有任何关系,再也不可能访问到上一个节点。基于二级指针的链表遍历用cur=&(*cur)->next来实现。这句赋值操作可以拆分为三步:1,计算*cur;2,计算(*cur)->next;3,计算&(*cur)->next。例如在上图中的橙色cur二级指针,*cur获取二级指针指向的链表指针,该指针和蓝色cur指针一个作用,指向了下一个节点,(*cur)->next获取了下一个节点的next指针,&(*cur)->next获取next指针的地址,然后将其赋给新的cur二级指针,如此便完成了基于二级指针的链表遍历。
在链表的尾部插入中,在遍历到最后一个节点之后,只需要执行*cur=n即可插入一个节点。这是因为*cur获取的是当前最后一个节点的next指针,将该next赋值也就使其指向了下一个节点。在链表的有序插入中,当遍历到(*cur)->value<value的时候退出循环,此时注意的是cur二级指针其实还在上一个节点中,而没有指向value为10节点的next指针,而常规链表在退出循环时,cur一级指针已经指向value为10的节点,这就是和常规链表遍历最大的不同。接着我们通过语句n->next=*cur让新增节点的next指向值为10的节点,然后通过*cur=n来将值为100的节点next指针指向新的节点。
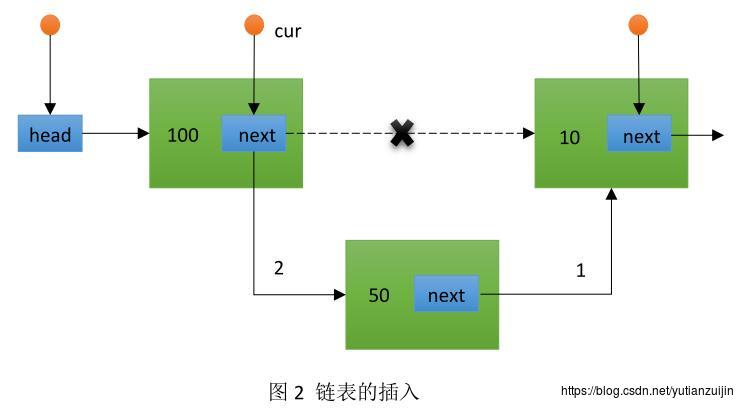
通过链表的插入,大家需要明白一点,二级指针遍历和常规链表遍历最大的不同就是:常规链表的遍历总是会遍历到当前节点,而二级指针的遍历总是会遍历到当前节点的上一个节点。这句话不完全正确,但是我想强调的就是二级指针的遍历总是比常规的遍历提前一个位置。正是因为这个提前,我们才能简化链表操作。
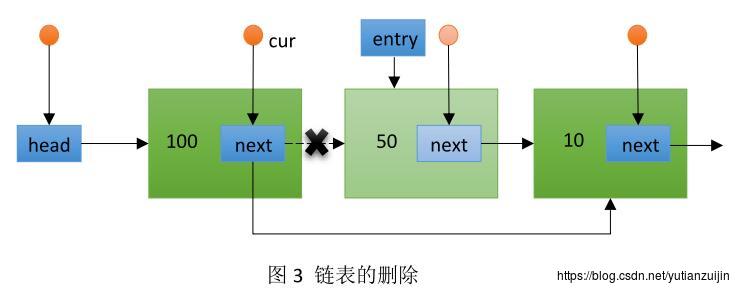
在基于二级指针的链表删除操作中,entry是一个一级指针,指向当前待删除节点,*cur=entry->next就使entry的上一个节点的next指针指向了entry的下一个节点,接着我们再释放entry就达到了释放当前节点的目的。这里的核心也在于cur还是处在当前节点的上一个位置。
除了上面的加粗描述,在具体实现中我们还需要对相关操作进行深入理解:*cur是对二级指针指向的一级指针取值或赋值,具体含义就是对链表中的next指针进行操作;&(*cur)->next是一个取地址操作,获取的是链表中next指针的地址,正好对应一个二级指针。
上面的描述我们都假定遍历到链表中间的某个位置,没有对head进行描述。用二级指针操作链表无需关注head是否为空,因为二级指针指向head,可以直接对head进行赋值和访问。
一旦大家明白了二级指针操作链表的真谛就会欲罢不能,在实际工作中会不自觉地应用该技巧。我也非常希望在今后看到的代码中都不会再看到常规方法的链表操作。
以上是关于利用二级指针进行链表操作的主要内容,如果未能解决你的问题,请参考以下文章