python数据分析与挖掘学习笔记-淘宝商品数据清洗及预处理
Posted 小胖子小胖子
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python数据分析与挖掘学习笔记-淘宝商品数据清洗及预处理相关的知识,希望对你有一定的参考价值。
这一节开始就正式开始啦~~
这一部分主要是针对淘宝的部分商品数据(小零食)进行预处理。
1. 读取商品源数据
这里拿到的数据是sql数据,因此需要使用mysql。首先我们安装好mysql,可以直接通过指令安装:
> sudo apt-get install mysql-server
> apt-get install mysql-client
> sudo apt-get install libmysqlclient-dev
安装过程中别忘记自己设置的密码,最后连接数据库需要该密码。 安装完成后可以通过下面的指令检查是否安装成功:
> sudo netstat -tap | grep mysql
安装好之后,我们现在就需要建立数据库将我们的数据文件导入。
> mysql -u root -p
登录自己的root账户,-p表示需要输入用户密码,按照提示输入密码,登录到mysql。
登录好之后,
mysql> show databases;
创建自己的数据库:
mysql> create database XX;
这里的XX代表你的数据库名,我这里使用的是创建的数据库叫CSDN。
mysql> use CSDN;
这里的use表示切换数据库;现在切换到CSDN数据库上来。
mysql> show tables;
显示所有的表;
这里未创建之前应该是为空,这里我们将taobao.sql文件导入该数据库中,
mysql> source /home/hadoop/taobao.sql
使用source+path的指令将本地的数据导入到数据库中,这时再使用show tables应该就可以看到数据表了。
好,数据导入到数据库之后,现在我们需要用python来处理该数据,就需要用到python与mysql之间的交互。由于Mysqldb模块还不支持python3,因此使用python3想要连接mysql,需要安装pymysql模块。上一节提到过,可以直接使用pip安装,也可以直接在pycharm中安装第三方模块。
File] >> [settings] >> [Project: python] >> [Project Interpreter] >> [Install按钮]
安装好之后,我们可以使用来读取数据:
# coding:utf-8
import numpy as np
import pymysql
import pandas as pda
import matplotlib.pylab as pyl
conn = pymysql.connect(host="127.0.0.1", user="root", passwd="xxxxxx", db="csdn", charset='utf8')
sql = "select * from taobao"
data = pda.read_sql(sql, conn)这样就可以得到我们的原始数据了。
2. 数据清洗之发现缺失值并对缺失值进行处理
取到数据之后就开始准备处理数据。第一步,是先观察数据,或者是了解数据的属性等特征。
比如我们可以看到数据中含有下面的属性值:

一共有9616条数据,一共有四列数据,也就是四个属性值,分别为:title,link,price, comment。对应于该商品的名称,链接,价格和评论数。
下面对这些数据中的NA值进行清洗:
x = 0
data["price"][(data["price"]==0)] = None
for i in data.columns:
for j in range(len(data)):
if(data[i].isnull())[j]:
data[i][j] = 64
x += 1
print(x)将价格为空的数据的价格标为64.
3. 发现大量数据中的异常值并清洗
首先,为了更加直观地观察到异常值,我们可以通过作图来发现。
data2 = data.T
price = data2.values[2]
comment = data2.values[3]
pyl.plot(price, comment, "o")
pyl.show()
由于范围比较大,我们作出的价格与评论数的散点图分布并不很直观。因此,我们考虑缩小范围,将评论数大于5000的和价格大于400的都视为异常值,那我们就假设这样处理好了,异常数据的选取都是可以自己调整范围,逐步根据自己做出来的图形进行判断:
line = len(data.values)
col = len(data.values[0])
dt = data.values
for i in range(0, line):
for j in range(0, col):
if dt[i][3] > 5000: # comment
dt[i][3] = 562 if dt[i][2] > 400: # price
dt[i][2] = 64
dt2 = dt.T
price = dt2[2]
comment = dt2[3]
pyl.plot(price, comment, "o")
pyl.show()然后再次作图,得到如下效果:

得到这样的图看起来数据就集中多了。卖家可以通过自己的卖的平时的价格区间截取更加细致的区间,评论数可以一定程度上代表销量,可以从中分析出最好的价格制定点,可以帮助卖家制定合理的价格,获得尽可能大的收益。
4. 数据的离散化处理及分布的分析
要观察数据的分布,我们最好是通过作出数据的直方图来观察。
因此我们计算数据的最大值和最小值,计算组距(极差/组数),绘制直方图。
计算最值:
price_max = dt2[2].max()
price_min = dt2[2].min()
comment_max = dt2[3].max()
comment_min = dt2[3].min()计算极差:
price_rg = price_max - price_min
comment_rg = comment_max - comment_min计算组距:
price_dist = price_rg/13
comment_dist = comment_rg/13绘制直方图:
price_sty = np.arange(price_min, price_max, price_dist)
pyl.hist(dt2[2], price_sty)
pyl.show()
comment_sty = np.arange(comment_min, comment_max, comment_dist)
pyl.hist(dt2[3], comment_sty)
pyl.show()绘制出来的效果为:

价格的直方图
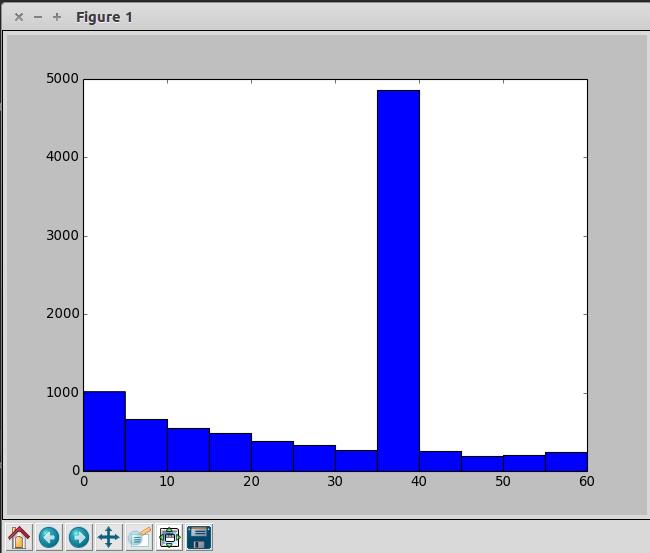
评论直方图
这里是将数据范围缩减到更小之后求得的数据。评论数是大于65设置为35,价格大于100的设置为64。
然后进一步分析数据的分布规律。
两个直方图中的峰值柱与我们处理数据时的设置值有非常大的关系,因此我们可以弱化这一列的特征,对整个数据进行分析。
以上是关于python数据分析与挖掘学习笔记-淘宝商品数据清洗及预处理的主要内容,如果未能解决你的问题,请参考以下文章