轻量级轻量级网络结构总结
Posted 明天去哪
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了轻量级轻量级网络结构总结相关的知识,希望对你有一定的参考价值。
Depthwise-Wise convolutions是最近两年比较火的一种模块结构。这个结构第一次出现是在一篇博士论文中,L. Sifre. Rigid-motion scattering for image classification. hD thesis, Ph. D. thesis, 2014. 功力可想而知…
SqueezeNet
SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size
Abstract
这篇是ICLR 2017(2016年上传到arxiv)的文章.主要针对模型压缩的.使用的是分类网络中的AlenNet为代表.
目前很多方法都是只关注精度的,但是在同等精度的情况下,小的模型很多优点,比如:(1)训练等更快(2)在部署时更少的带宽要求,例如自动驾驶汽车(3)可以部署到FPGA等.正是由于有这些优点,本文提出了一种小的CNN架构,SqueezeNet.实现了AlexNet模型参数减少了50倍.在受用模型压缩技术情况下,可以做到减少510倍参数,只有0.5MB的模型大小.
Related work
模型压缩方面:本文工作的首要目标是确认一个模型,保证精度的情况下使用很少的参数.目前已经有许多模型压缩的方法了:SVD;设置阈值的方法;Deep Compression等.
CNN网络模块方面:目前有Inception modules等.
CNN网络架构方面:目前有bypass connections等.
Framework
本文针对保持精度减少参数提出了三个策略:(1)用1x1filters来代替3x3filters(2)减少3x3filters的输入通道数(3)推迟下采样,保证网络有大的activation maps.很容易看出来,(1)(2)是为了减少参数的,而(3)是为了在限制的参数数量条件下提高精度的.
针对(1)(2)本文提出了一种网络模块Fire Module.
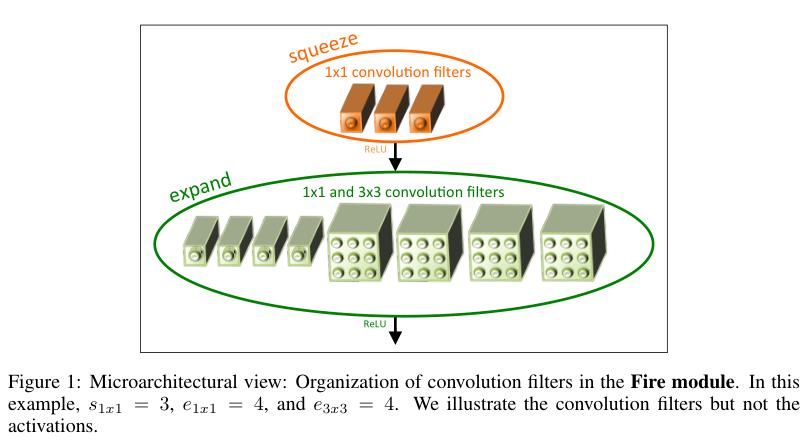
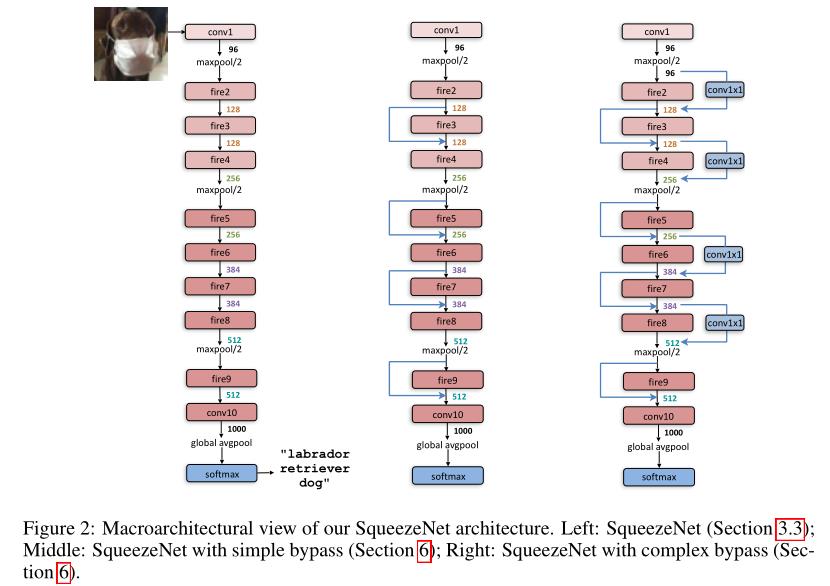
针对(3),本文对Fire Module进行了组合,创建了SqueezeNet.
Experiment
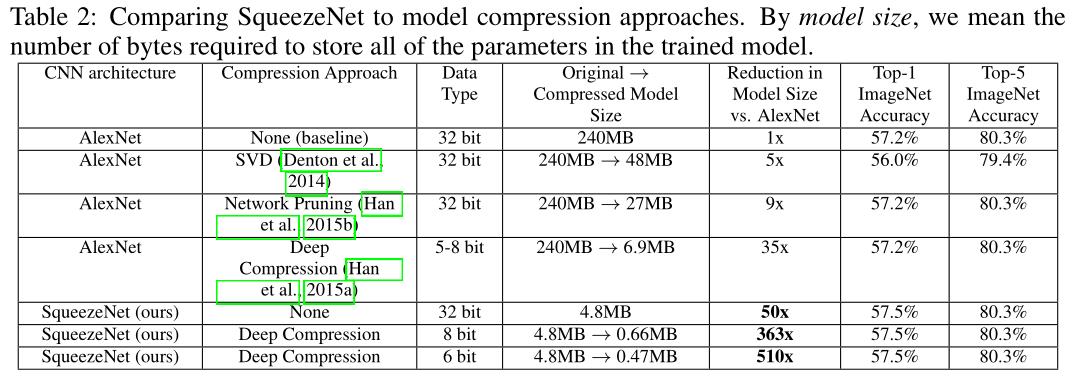
这部分做了本文提出的性能与其他方法的比较.
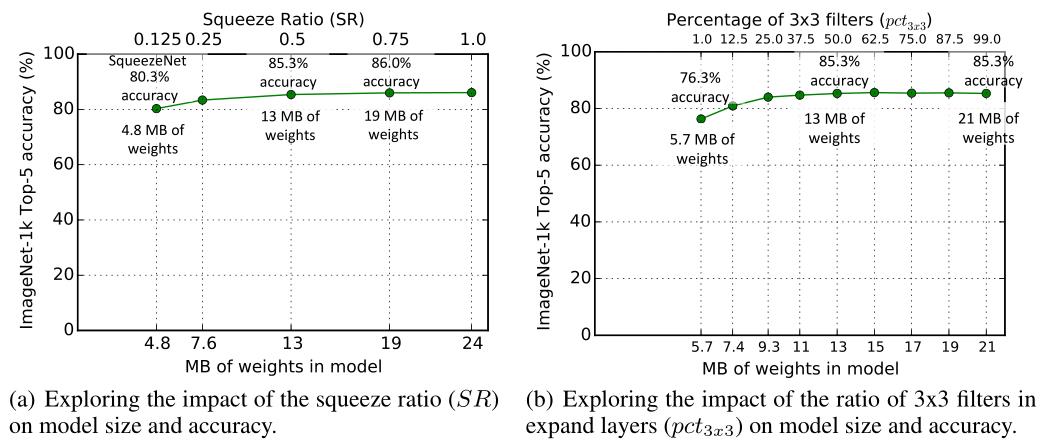
这一部分来分析Fire Module中超参数的合适取值,来保证准确率.
接着实验说明了bypass结构的使用对结果的影响.

Code
Xception
Xception: Deep Learning with Depthwise Separable Convolutions
Introduction
Xception是2016.10的文章,由Google提出,发表于CVPR 2017。值得一提的是,作者只有一个人。
Xception认为在卷积操作中channel和spatial相关性是可以解耦的,而普通的卷积时将两者混合起来进行的运算。通过解耦这两部分,可以精确控制channel和spatial上的运算,实验上可以提高性能。
Framework
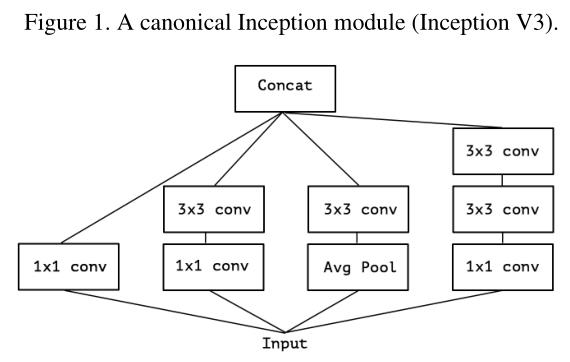
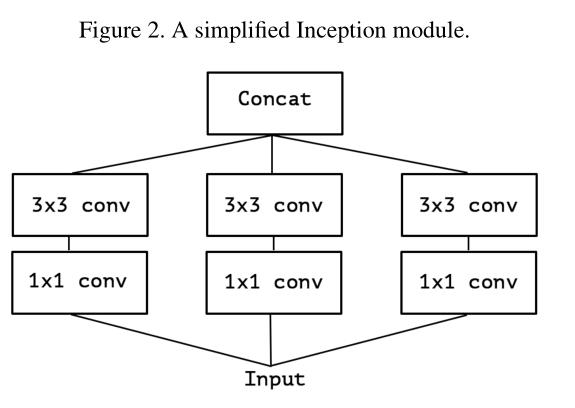
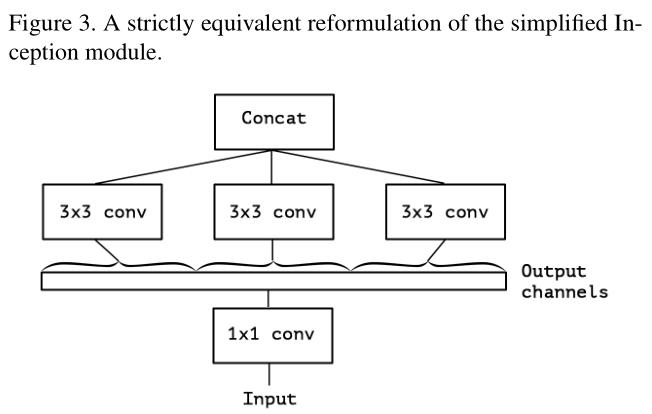
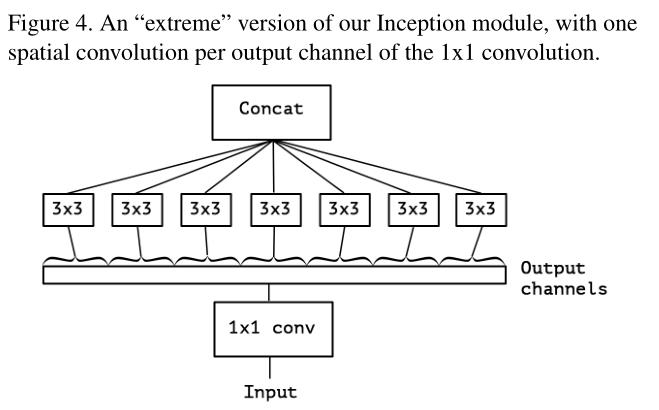
因此,Xception中的’X’是Extreme的意思.
Xception和原depth separable convolution有两个不同点:(1)DWC是先channel-wise,然后point-wise(1x1)而Xception与之相反,先point-wise,然后channel-wise.
总体架构如下:
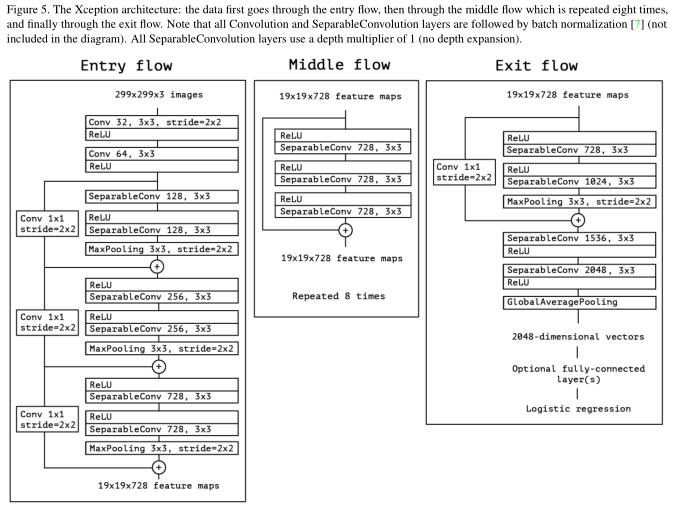
Experiment
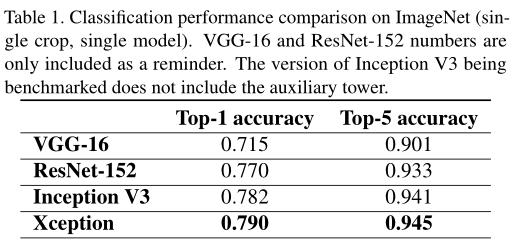

这个网络虽然不是针对轻量级网络进行设计的,但是depth-wise separable conv可以减少网络参数,提高网络性能,在后几篇文章中均使用这个思想。
Code
MobileNet v1
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
Abstract
CVPR 2017的论文,Google团队.
利用depth-wise separable convolution构建轻量级DNN. 同时引入了两个超参数来权衡精度和速度:width multiplier & resolution multiplier.
Motivation
DSC可以减少参数,并提高性能,也是受Xception的启发
Framework
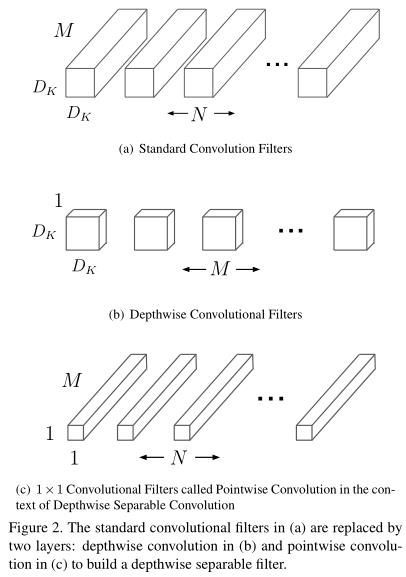
同时,为了使用不同应用场景,加入了两个超参数width multiplier (通道乘数/乘子) & resolution multiplier(分辨率乘子)

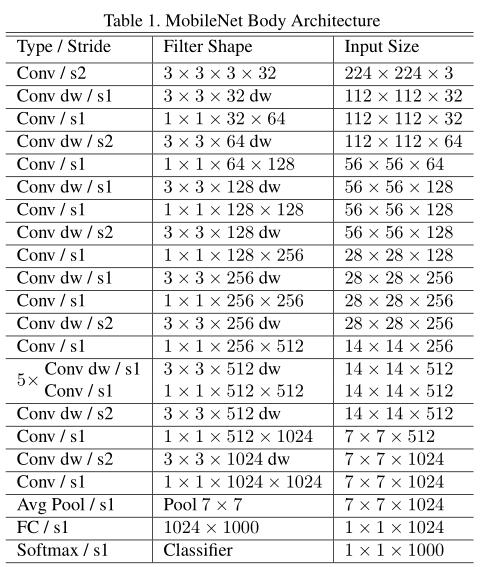
Experiment
在多种任务上进行评测:细粒度识别、大规模地形、人脸属性、物体检测、人脸嵌入
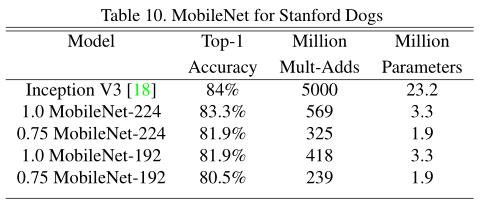
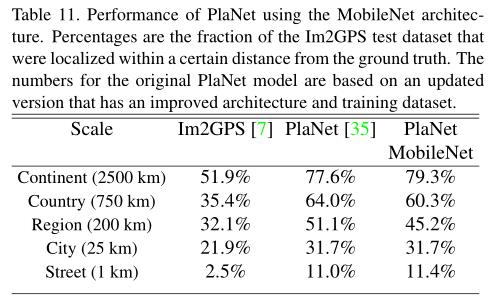
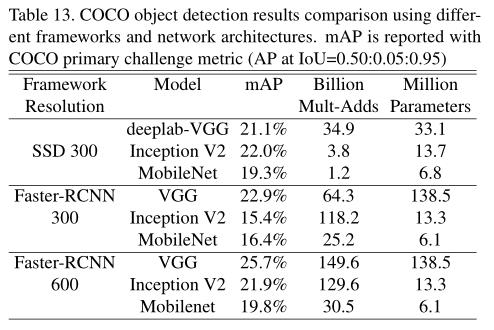
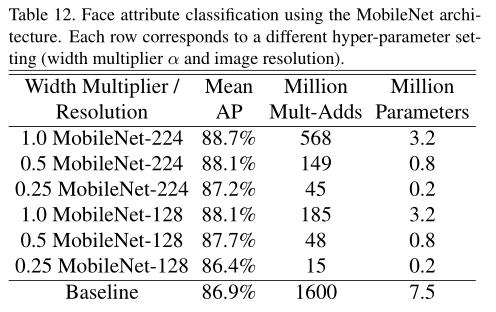
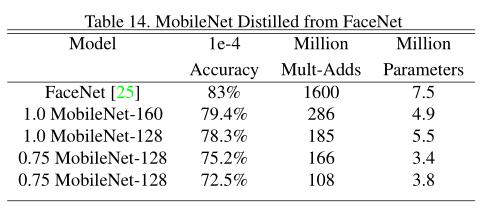
Code
ShuffleNet
ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
Abstract
CVPR 2017, Face ++ 团队. 一作Xiangyu Zhang是师兄的mentor…膜拜
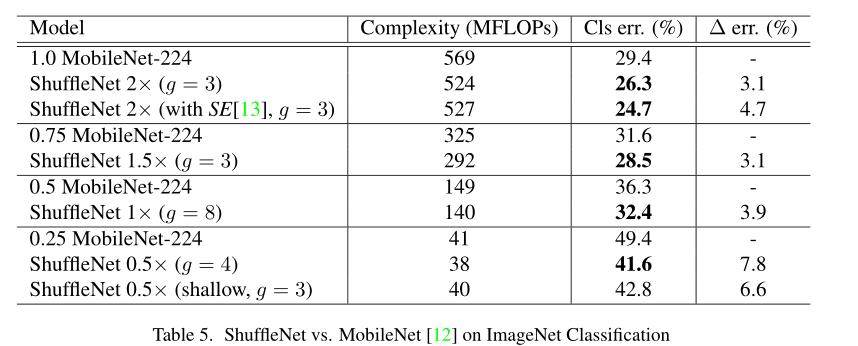
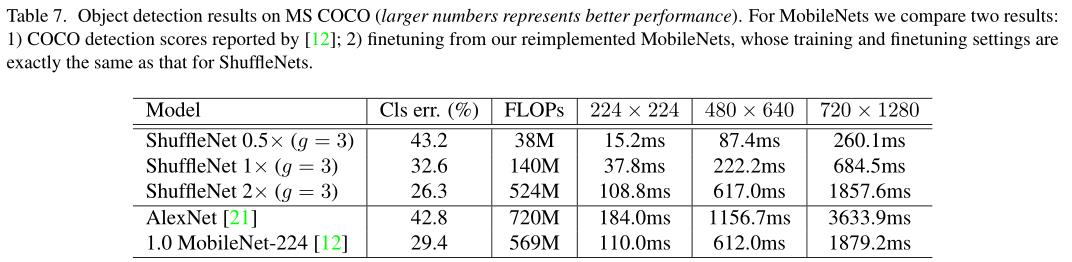
提出ShuffleNet,由两种操作组成:group conv和channel shuffle,最终的结果在性能和速度上超过mobilenet v1.
Movitation
在Xception和ResNeXt中发现,在特别小的网络中,1x1卷积花费很大,而1x1卷积存在的作用是group conv会导致不同group中的信息不流通,因此,本文提出channel shuffle代替point-wise conv,来提高效率和性能。
Framework
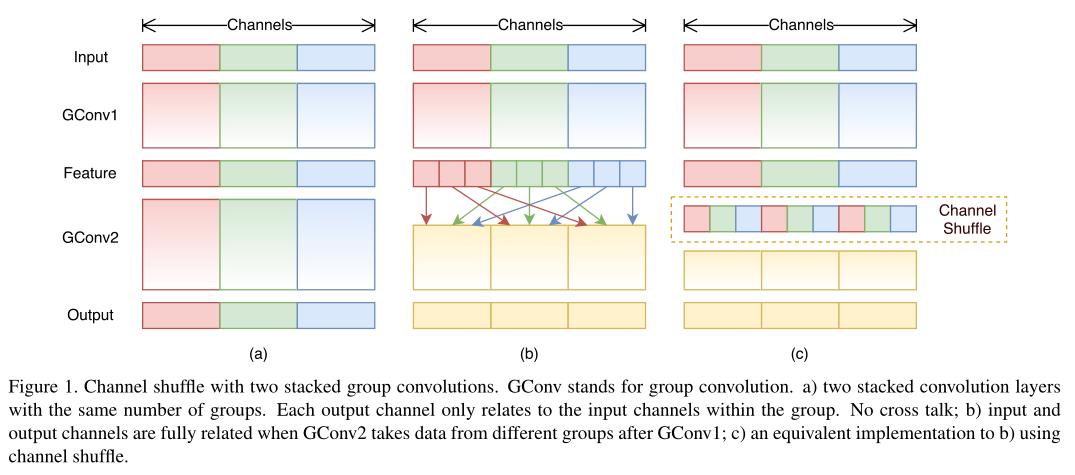
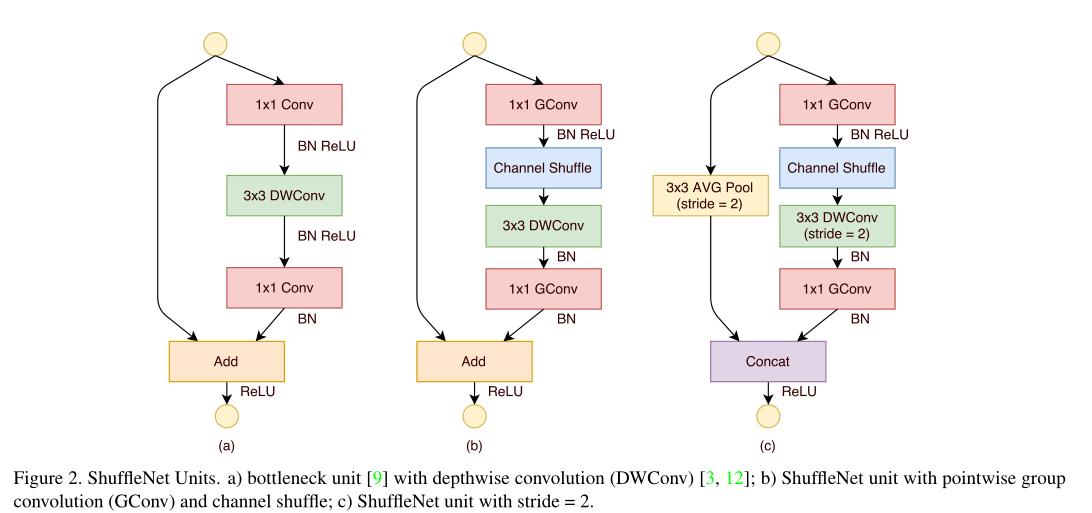
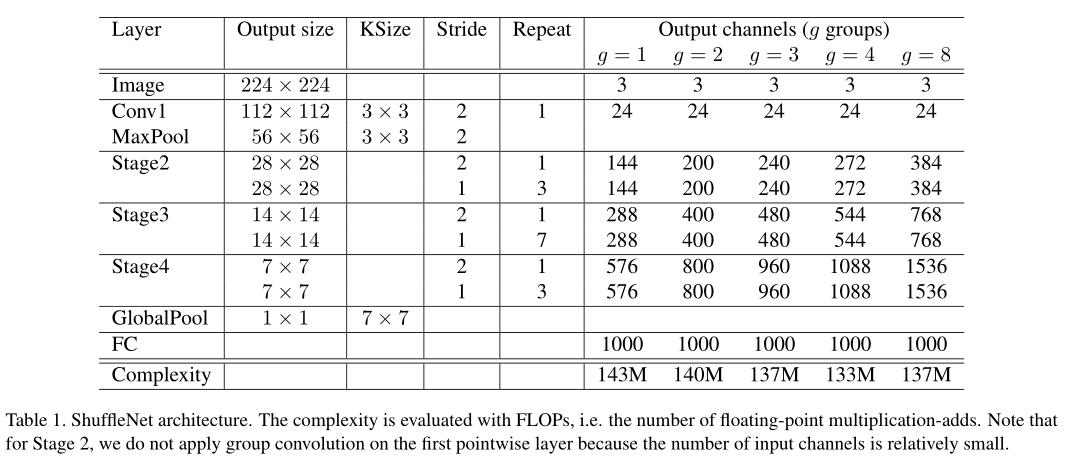
Experiment
Code
MobileNet v2
MobileNetV2: Inverted Residuals and Linear Bottlenecks
Abstract
暂时还没有发表,Google团队的工作
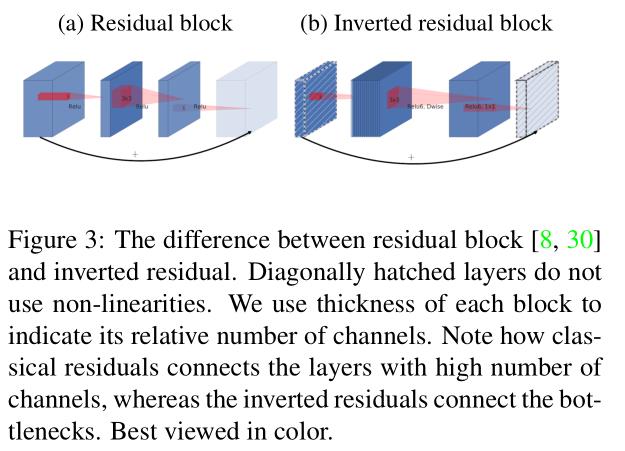
在MobileNet v1的基础上添加resdidual的思想,组成Inverted residual,并把窄的bottlenetck移除ReLU,换成Linear Bottleneck.
Framwork
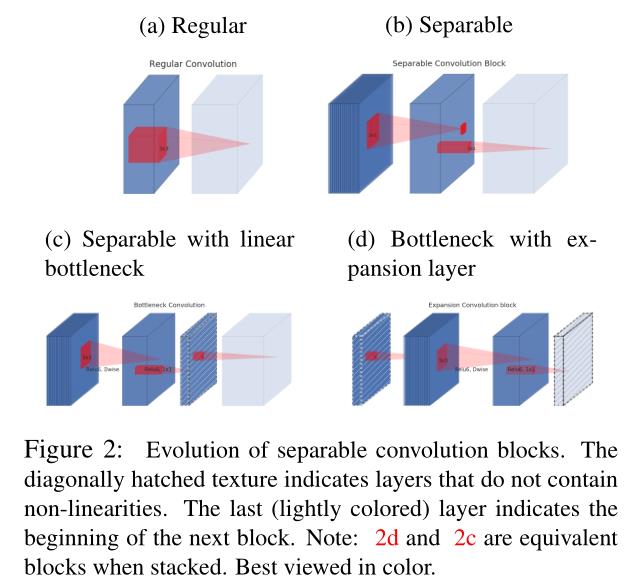
Linear Bottleneck

通过观察ReLu在channel比较低的时候在高维空间比较难恢复到原始的信息,推测原因是ReLu在channel较低时使很多地方变为0,无法恢复,因此提出Linear Bottleneck,不使用ReLU.
Inverted residual
使用skip connection.
Experiment
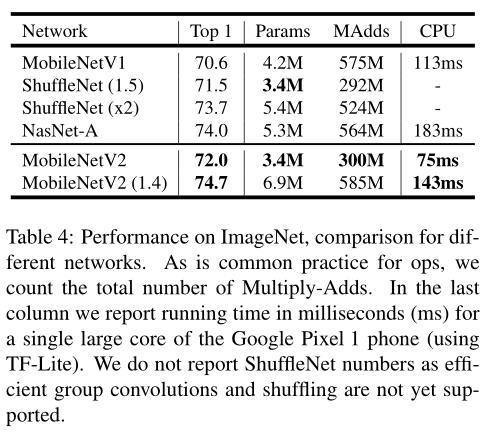
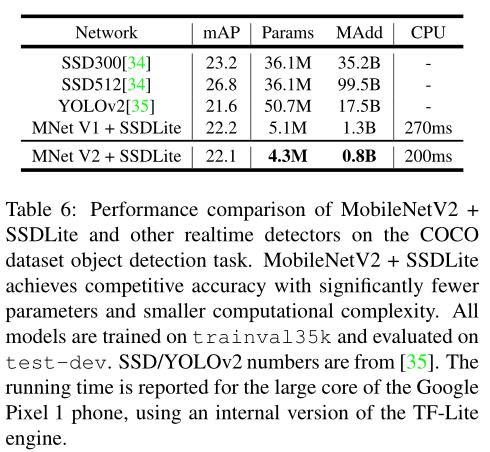
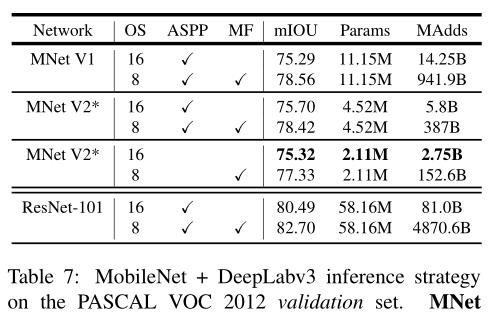
Code
- 非官方Caffe(同mobilenet v1): https://github.com/shicai/MobileNet-Caffe
以上是关于轻量级轻量级网络结构总结的主要内容,如果未能解决你的问题,请参考以下文章