04Spark 运行架构
Posted 一条coding
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了04Spark 运行架构相关的知识,希望对你有一定的参考价值。
大家好,我是一条~
5小时推开Spark的大门,第四小时,带大家理解Spark的核心概念。
话不多说,开干!
运行架构
大家还记得第一节的系统架构图吗,就是这张
有同学反馈说都是英文的看不太懂,对照起来看又特别麻烦。
这个是因为有些概念我也找不到特别标准且统一的翻译,这也是目前的一个现状,很多文档都是英文的,虽然有国人翻译,但是不沟通统一,难免会对新手造成困扰。
要改变这一现状,需要所有程序员的共同努力。
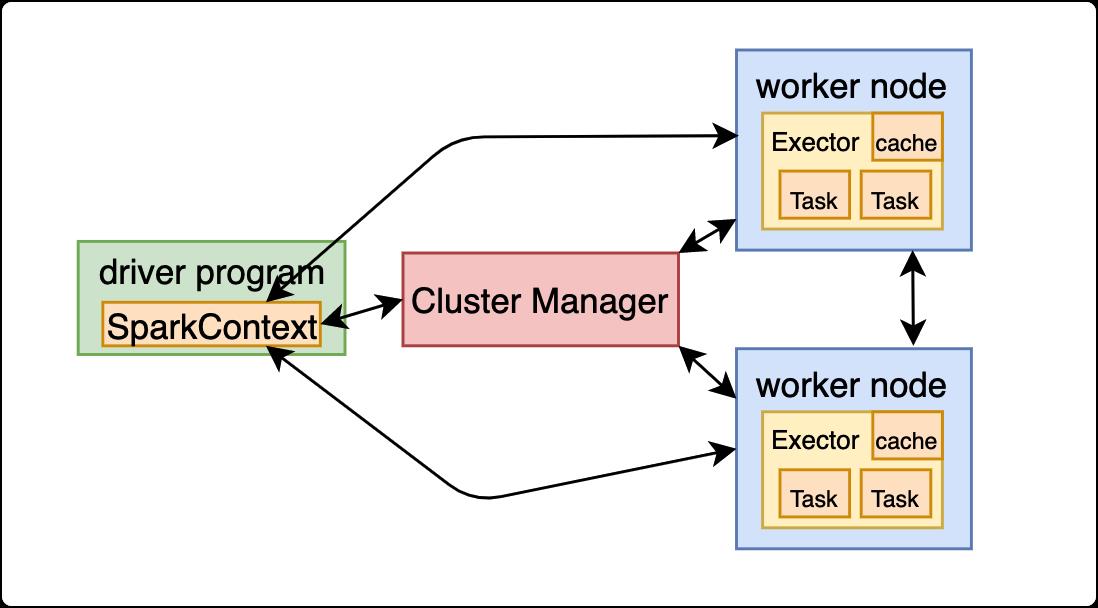
首先回顾一下每个节点都是什么意思:
Spark整体采用了标准master-slave的结构。
图中的Driver表示master,负责管理整个集群中的作业任务调度;Executor 则是 slave,负责实际执行任务。
1.Driver
负责实际代码的执行工作,即执行 Spark 任务中的 main 方法,在 Spark 作业执行时主要负责:
- 将用户程序转化为作业(job)
- 在Executor之间调度任务(task)
- 跟踪Executor的执行情况
- 通过WebUI展示查询运行情况
简单理解,所谓Driver就是驱使整个应用运行起来的程序。
2.SparkContext
每一个Spark应用都是一个SparkContext实例,可以理解为一个SparkContext就是一个spark application的生命周期,一旦SparkContext创建之后,就可以用这个SparkContext来创建RDD、累加器、广播变量,并且可以通过SparkContext访问Spark的服务,运行任务。
就像上一节课我们与Spark建立连接的代码:
// 创建 Spark 运行配置对象
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount")
// 创建 Spark 上下文环境对象(连接对象)
val sc = new SparkContext(sparkConf)
4.Master & Worker
Spark集群的独立部署环境中,不需要依赖其他的资源调度框架,自身就实现了资源调度的功能(当然也有Yarn调度模式),所以环境中还有其他两个核心组件:Master 和 Worker。
Master主要负责资源的调度和分配的进程,并进行集群的监控等职责。
Worker也是进程,运行在集群中的一台服务器上,由 Master 分配资源对数据进行并行的处理和计算。
简单理解,你是Worker,Master是你老板。
5.Executor
Spark Executor是集群中工作节点(worker node)中的一个进程,负责在Spark作业中运行具体任务,也就是真正干活的那个。
任务彼此之间相互独立。Spark应用启动时,Executor节点被同时启动,并且始终伴随着整个 Spark 应用的生命周期而存在。
如果有 Executor 节点发生了故障或崩溃,Spark 应用也可以继续执行,会将出错节点上的任务调度到其他 Executor节点上继续运行。
就好比这个人干不动了,换个人接着干。
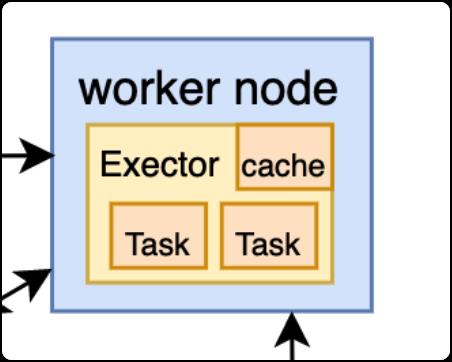
Executor的核心功能
-
负责运行组成 Spark 应用的任务,并将结果返回给驱动器进程。
-
它们通过自身的块管理器(Block Manager),作为用户程序的缓存,因此任务可以在运行时充分利用缓存,提高运算速度。
核心概念
了解了运行架构,还有一些Spark的核心概念需要理解。
1.并行度
我们常说高并发,是说同时处理大量请求的能力,那么在分布式计算框架中同样是多个任务同时执行,不同的是分布在不同的计算节点同时进行计算,是能够真正地实现多任务并行执行。
所以整个集群并行执行任务的数量称之为并行度。
那么一个作业到底并行度是多少呢?这个取决于框架的默认配置。应用程序也可以在运行过程中动态修改。
2.有向无环图
DAG(Directed Acyclic Graph)
大数据计算引擎框架我们根据使用方式的不同一般会分为四类,其中第一类就是Hadoop 所承载的 MapReduce,它将计算分为两个阶段,分别为 Map 阶段 和 Reduce 阶段。
对于上层应用来说,就不得不想方设法去拆分算法,甚至于不得不在上层应用实现多个Job的串联,以完成一个完整的算法,例如迭代计算。
由于这样的弊端,催生了支持DAG框架的产生。因此,支持 DAG 的框架被划分为第二代计算引擎。
接下来就是以 Spark 为代表的第三代的计算引擎。第三代计算引擎的特点主要是 Job 内部的DAG支持(不跨越 Job),以及实时计算。
这里所谓的有向无环图,并不是真正意义的图形,而是由 Spark 程序直接映射成的数据流的高级抽象模型。简单理解就是将整个程序计算的执行过程用图形表示出来,这样更直观,更便于理解,可以用于表示程序的拓扑结构。
DAG是一种非常重要的图论数据结构。如果一个有向图无法从任意顶点出发经过若干条边回到该点,则这个图就是有向无环图,如图:

3.RDD
到了最重要的了,也是最后一个大坑,内容比较多,留给明天填。
我们下期见!
以上是关于04Spark 运行架构的主要内容,如果未能解决你的问题,请参考以下文章