转载Google MediaPipe:设备端机器学习完整解决方案背后的技术实现
Posted 字节卷动
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了转载Google MediaPipe:设备端机器学习完整解决方案背后的技术实现相关的知识,希望对你有一定的参考价值。
PS: 原文地址:https://aijishu.com/a/1060000000359284
上周TFLite社区举办了一场名为**《On-Device Machine Learning Solution with MediaPipe》的分享活动**,分享嘉宾是来自Google MediaPipe的Jiuqiang Tang,恰巧前不久谷歌开发者大会也有相关活动对MediaPipe做了如何使用的基本介绍,本次将会从MediaPipe技术角度和最近的工作来与大家交流。
MediaPipe推出已经有好几年了,先前看过MediaPipe的文档,但是有些背后的细节不是很理解,这次分享明白了。其实类似的生态工具链已有不少,如Face++的MegFlow是针对服务器的部署工具,而MediaPipe类似MNN工作台、模型集市,目标是端侧等平台。
MediaPipe在中国目前没有团队,这次分享MediaPipe背后的技术实现,机会也较为难得。
MediaPipe从设计之初便是考虑设备端开发与部署,其搭建围绕TFLite,后者是一个推理引擎,**推理完全是交给TFLite runtime,MediaPipe本身并不涉及推理引擎这部分,只是说MediaPipe围绕推理引擎与完整应用这一层的前后,做了不少如前后处理计算、相应加速以及渲染等工作。**与TF-Serving的方案是不同,如果在服务器上没有很好的计算资源(NVIDIA GPU)下,用MediaPipe跑可能是一个不错的方案,需要注意与TF-Server计算资源富足条件下二者使用场景的不同,因为TFLite不用CUDA,服务端使用MediaPipe自然也不会用CUDA。

这次分享主要从MediaPipe是什么、并从一个具体实际的端上机器学习解决方案的流程案例讲起,案例实为19年的Google AI Blog:MediaPipe Hands: On-device Real-time Hand Tracking(https://arxiv.org/abs/2006.10214,见下图)、MediaPipe所包含的工具集组件、MediaPipe Tasks和Model Maker API这四部分构成。

图0 MediaPipe Hands: On-device Real-time Hand Tracking:https://arxiv.org/abs/2006.10214
1. 什么是设备端机器学习
设备端机器学习就是在浏览器、嵌入式设备上部署甚至开发机器学习模型,其好处体现在:在低延迟、便捷性、离线复杂环境、隐私敏感数据的保护性等方面,这些个特点也都是老生常谈了,Google的设备端机器学习的MediaPipe已经落地到不少产品:
- Google Meet在手机和浏览器的背景模糊替换能力,即实时的人像与背景的图像分割能力;
- Google Nest实现的人物检测与手势识别能力;
- YouTube的APP AR虚拟试妆功能,用户试用不同颜色唇膏与唇彩,且该功能是建立在MediaPipe FaceNet基础上,其实现是先定位人脸关键特征点,如嘴唇位置,最后完成着色。
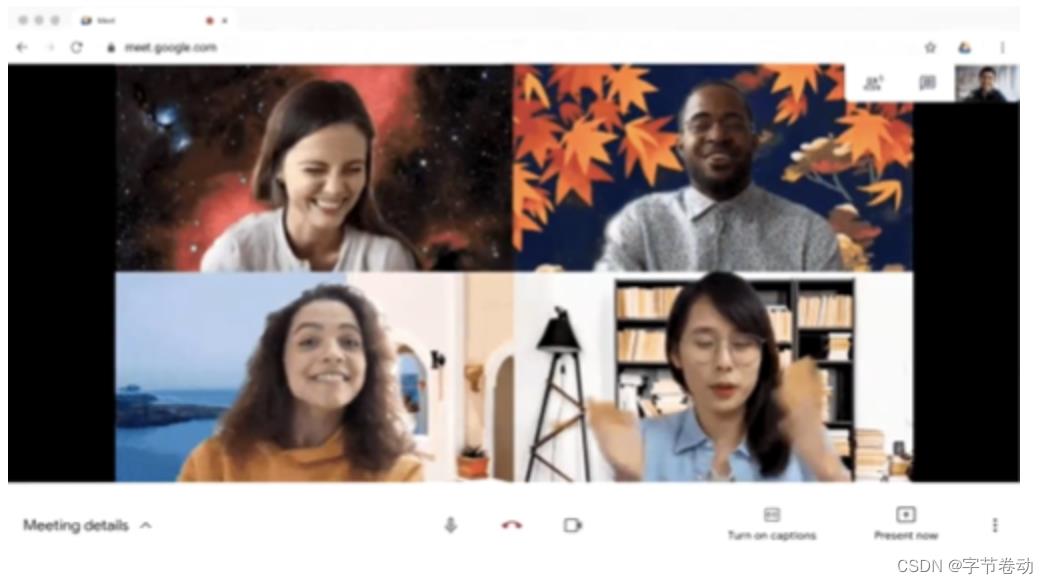
图1 Google Meet在手机和浏览器端实现实时背景分割
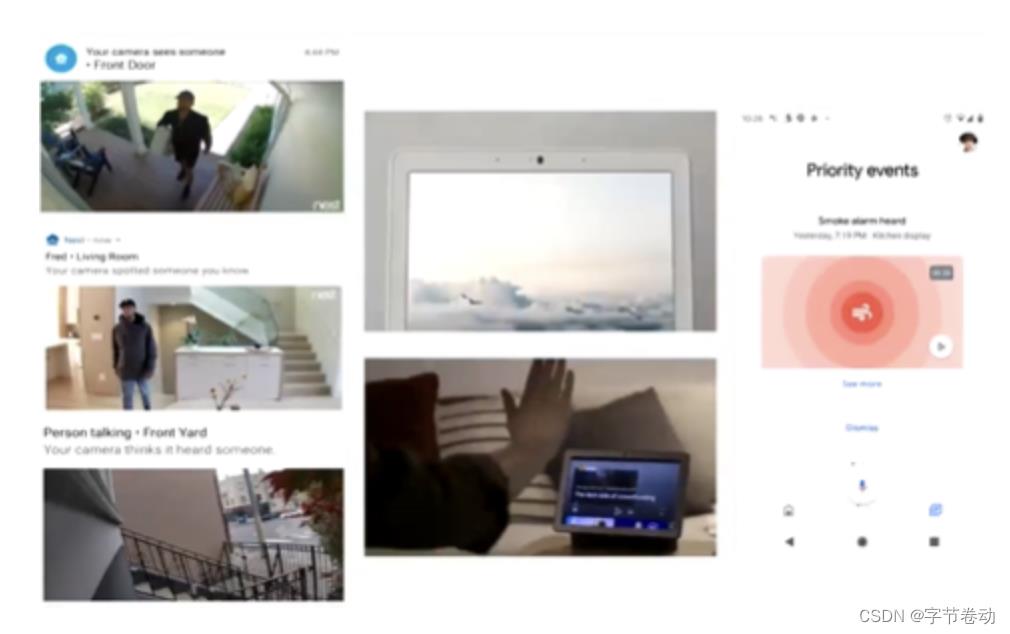
图2 Google Nest实现嵌入式设备的端上手势识别
此外,MediaPipe也落地在别的产品中,如Google Mobile中的实时OCR,YouTube的服务器上视频的Preview功能,而且该框架也可以跨平台,既可以在安卓上,也可以在Chrome里用,谷歌所有的AR都是建立在MediaPipe基础上的,如ARCore产品也是建立在其基础上的。
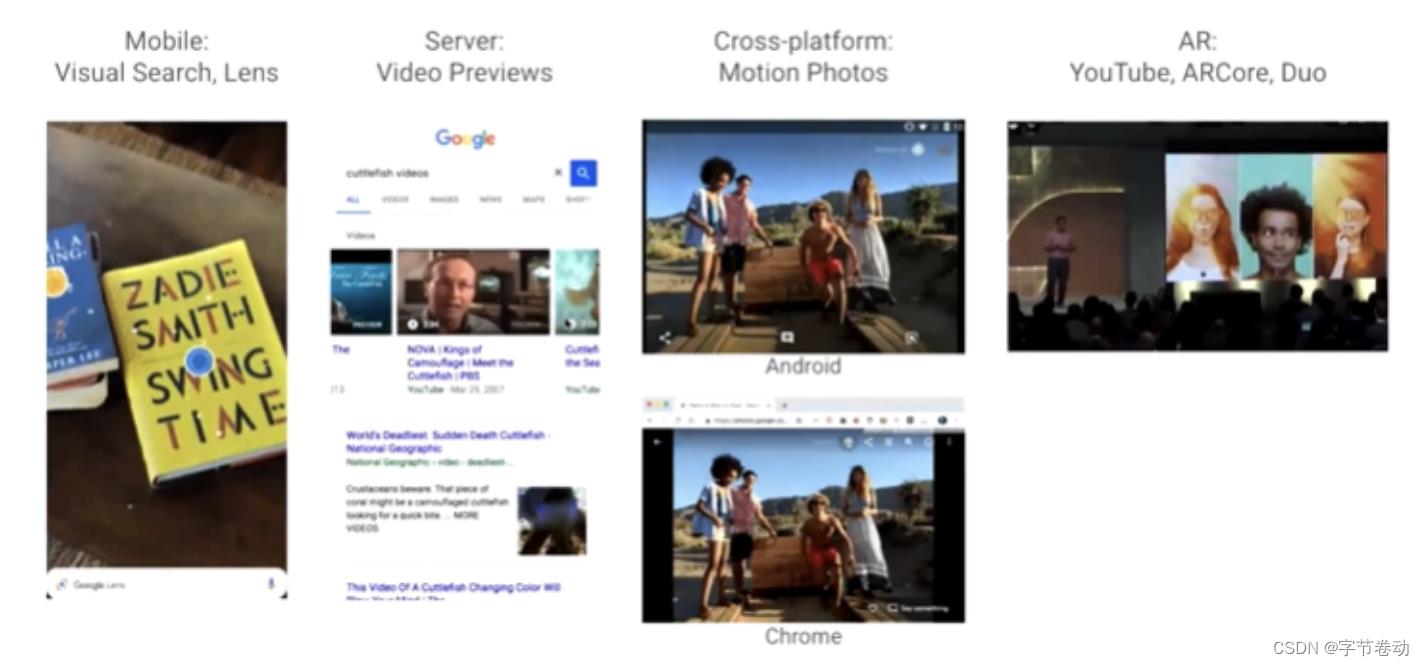
图3 内部产品的落地从移动端到Server端,Android端再到Chrome浏览器,以及AR能力等
2. 设备端机器学习方案的组成
通常我们所说的设备端机器学习方案,都包括核心模型和机器学习流水线的搭建,模型既要贴合场景也要满足准确性,达到足够的终端的小型化和高效率,尤其是算力、内存开销、功耗的要求。而且整个流水线也要覆盖从原始数据接入到最终结果输出。一般来说都有如下要求:
- 该流水线搭建需要满足专业领域的要求,如NLP、CV、audio,包含前后处理流程;
- 资源调配与硬件加速,如CPU、GPU、EdgeTPU、DSP上的运算,也要同步在不同硬件设备上的数据,Mediapipe也能完成这个任务;
- 能做到跨平台部署,要满足iOS、安卓、Web以及嵌入式平台。

图4 端上机器学习是围绕模型来开展的(定制化、高性能、目标硬件稀疏化等方面都是在保证满足精度条件下的性能要求)
以上的流水线搭建,对技术开发者而言,还是蛮头疼的。
3. 机器学习流水线:Hand Landmarks搭建部署案例

下面以一个真实的设备端机器学习流水线,来看看MediaPipe的搭建和部署流程。这个例子是Hand tracking,即拿到图片,检测手上的关键特征点,如指尖、指节、手掌的特征点。听起来这个任务还是蛮简单。
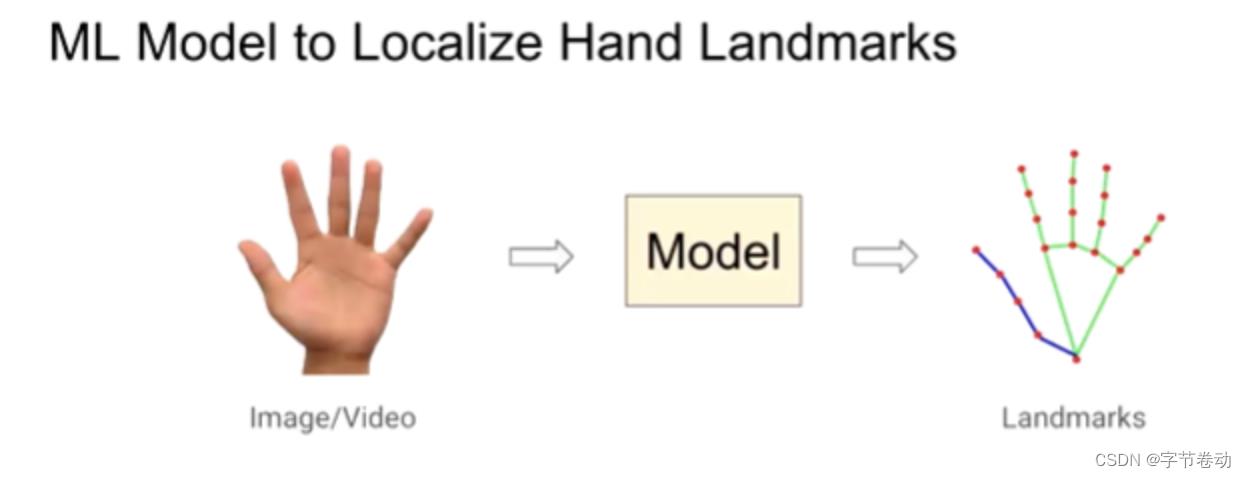
图5 通过机器学习模型定位输入图像或视频的人手特征关键点
对于训练模型的同学,需求就是输入一张图片,然后要求模型输出关键点,搞CVPR你发了论文就结束了,但对产品团队而言,算法落地过程中还有很多事情要做。我们可以先想一下整个流程中必不可少的5个步骤:
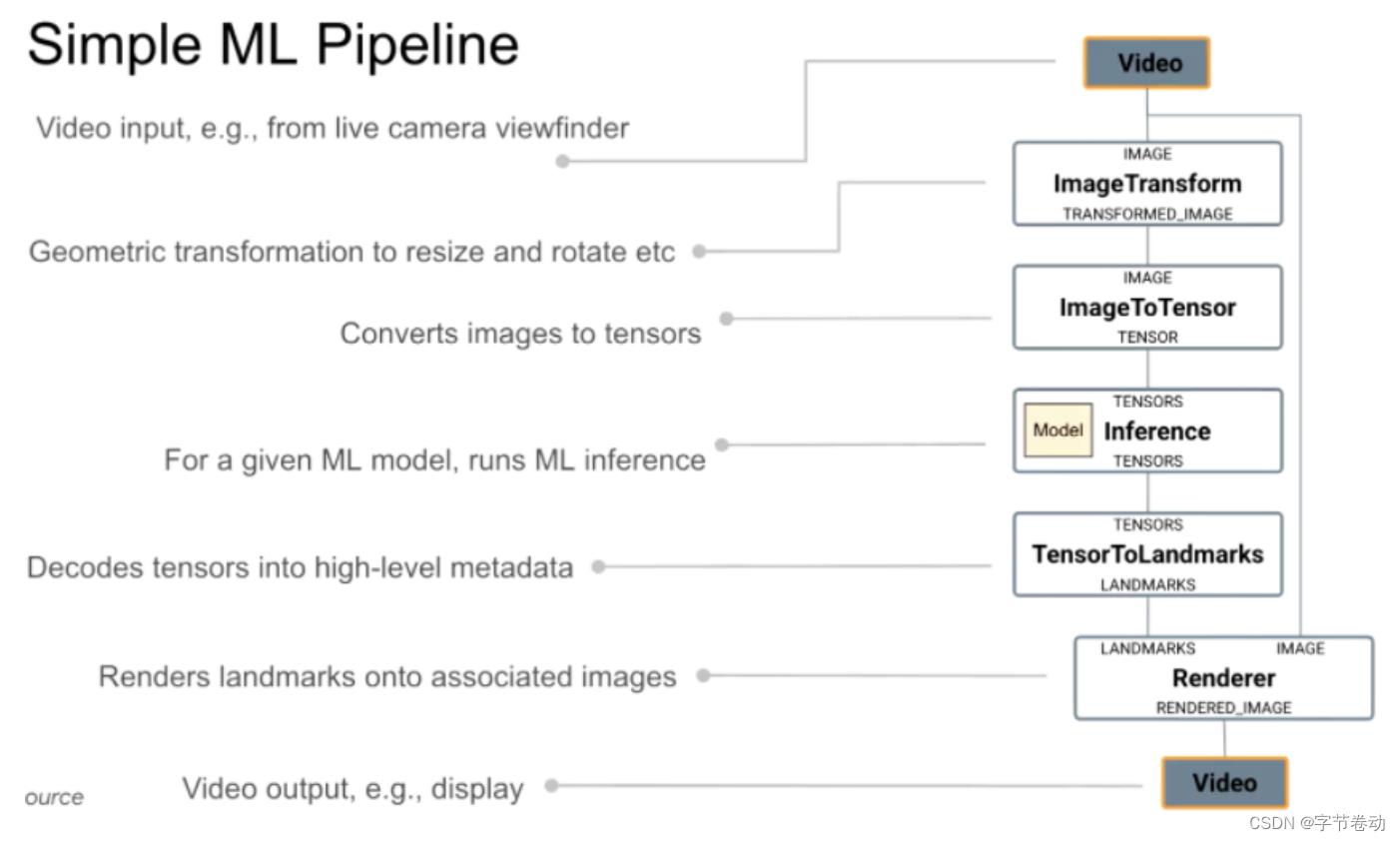
图6 常见的机器学习流水线:从数据流入、数据预处理、引擎推理计算、渲染结果、数据流出
- Image Transform:视频或图像接入需要做图像变换如Resize或者裁剪到模型接受的大小,以及对图片进行旋转等;
- Image To Tenso****r:处理好的图片转换到模型认识的类型,如TensorType,但如果是GPU做推理,则还需要把CPU Tensor转换为GPU Tensor,会涉及OpenGL等操作,但若是GL,则前面一步可能在Image Transform过程可能也需要考虑是在GPU上来做;
- Inference:这部分是推理的核心,模型和输入Tensor给到,输出output tensor;
- Tensor To Landmarks:在得到推理的output tensor后,需要将其翻译为标注点、检测点的信息如x、y轴的信息等等、也需要做很多工作;
- Renderer:在得到Landmark坐标信息后,还需要与原图做渲染,将最终渲染后的图片放进手机屏幕或者视频中。
3.1 MediaPipe的流水线
MediaPipe将上述整个过程表达为MediaPipe graph,一个个步骤,称为Node,Node在MediaPipe表达为Calculator,两个calculator之间通过stream链接,这个stream即数据如video stream或单帧图片,MediaPipe就是将上述过程表达为graph,进来video stream数据后如第一帧,即时间戳为0,比方视频是30fps,第二帧时间戳可能是3300的位置,即第33毫秒的位置,stream是携带数据包升序排列时间戳的数据流。
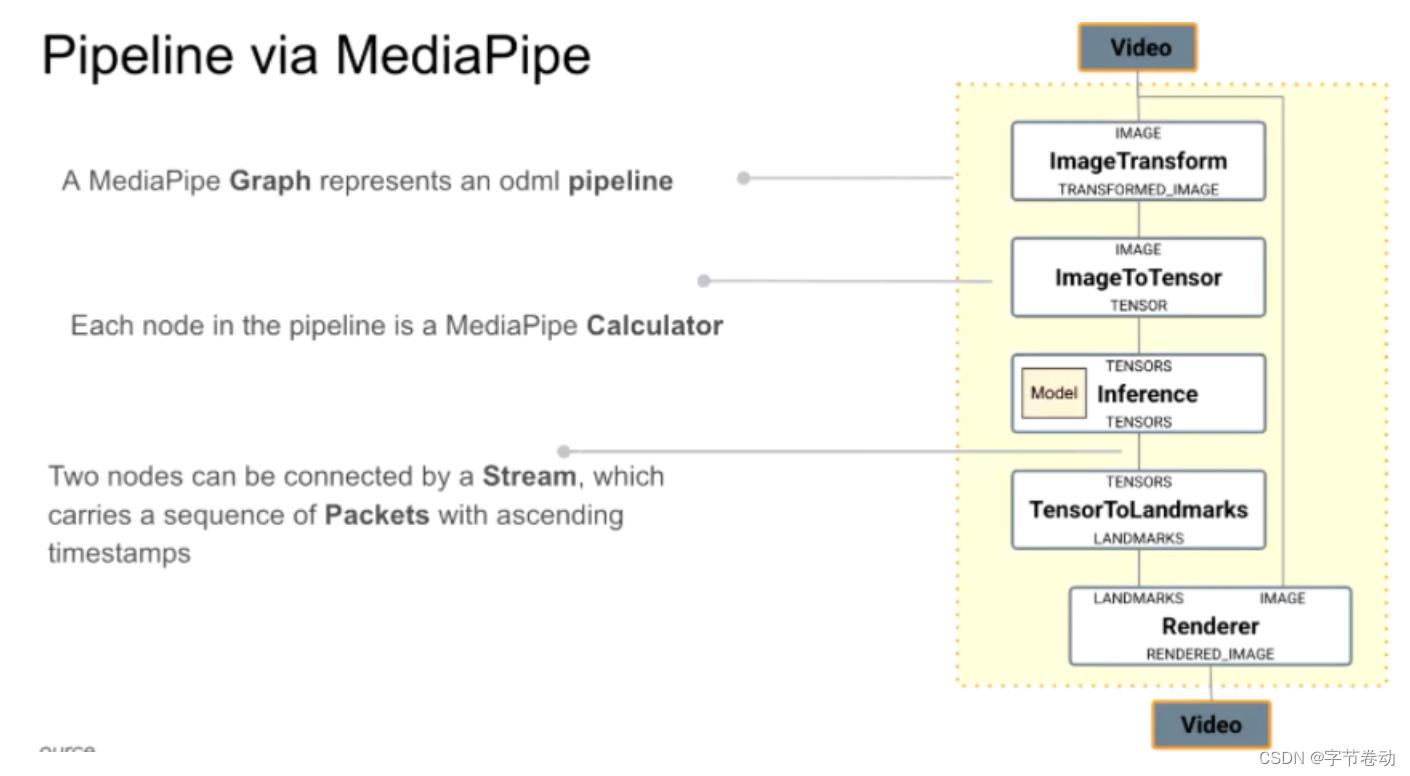
图7 MediaPipe的流水线组成,Node也称为Calculator,两个Node间以携带Packets(数据包)的数据流链接
3.2 Calculator介绍以及预设
可以看到calculator是组成Graph的核心,其实现目前都是C++,当你要用时,需要定义其输入、输出的类型,如ImageToTensor的输入是ImageType,输出是TensorType。当定义完这些接口后,需要再定义3个method:
- Open:graph初始化完后,Run前需要做的一次性工作。如tflite runtime的初始化,gpu的delegate初始化,均是在Open方法里完成;
- Process:数据的重复性操作,数据进来时,会不停调用这个方法;
- Close:最后graph全部跑完,一次性的清理工作,如释放TFLite runtime、文件IO的通道等。

图8 MediaPipe Calculator的构成
MediaPipe已经提供了很多预设的Calculator,主要分以下四类:
- 对图像等媒体数据处理的calculator,如ImageTransformation,当然还有对语音处理的calculator,里面有傅里叶变换操作等;
- TensorFlow与TFLite相关用于推理的Calculator:包含TF、TFLite runtime。注意:这里也是可以用TF Runtime;
- 后处理Calculator:将前面模型输出转为目标检测结果、图像分割的位图,如手势识别的landmarks等;
- 辅助性的Calculator:如对整个flow控制的calculaor,还有渲染的calculator。
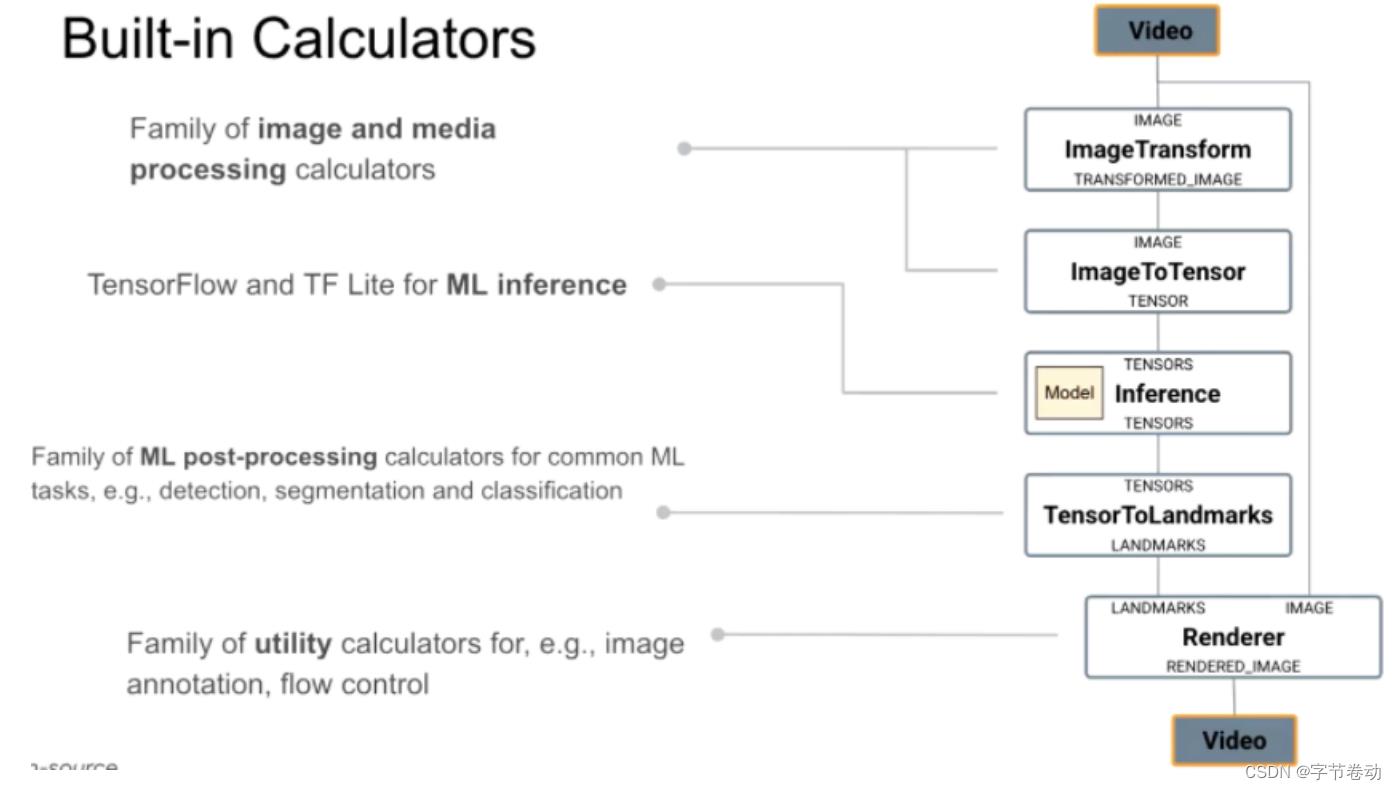
图9 内部预设的Calculator,已经可以满足大部分场景的使用
从生态的推广来说,MediaPipe当前还是希望大家能尽可能用built-in calculator,目前也是在想大家如何能更快速用自己的方式来写Calculator,甚至不需要完全编译MediaPipe就能使用自定义的Calculator,可能是明后年的一个开发计划。
对于非TFLite的模型格式的支持,如PyTorch格式,需要单独实现PyTorch的Calculator,模仿TFLite的方式来实现。
3.3 Calculator内的同步
MediaPipe也支持calculator的同步操作,如果一个calculator有多个数据流进入,calculator需要查询同一个时间戳下,所有inputs的stream,下游会根据刚讲的调用Process方法,来对同一个时间戳的data packet处理,如对于多张image跑出的landmark,渲染到原图,则需要做同步。
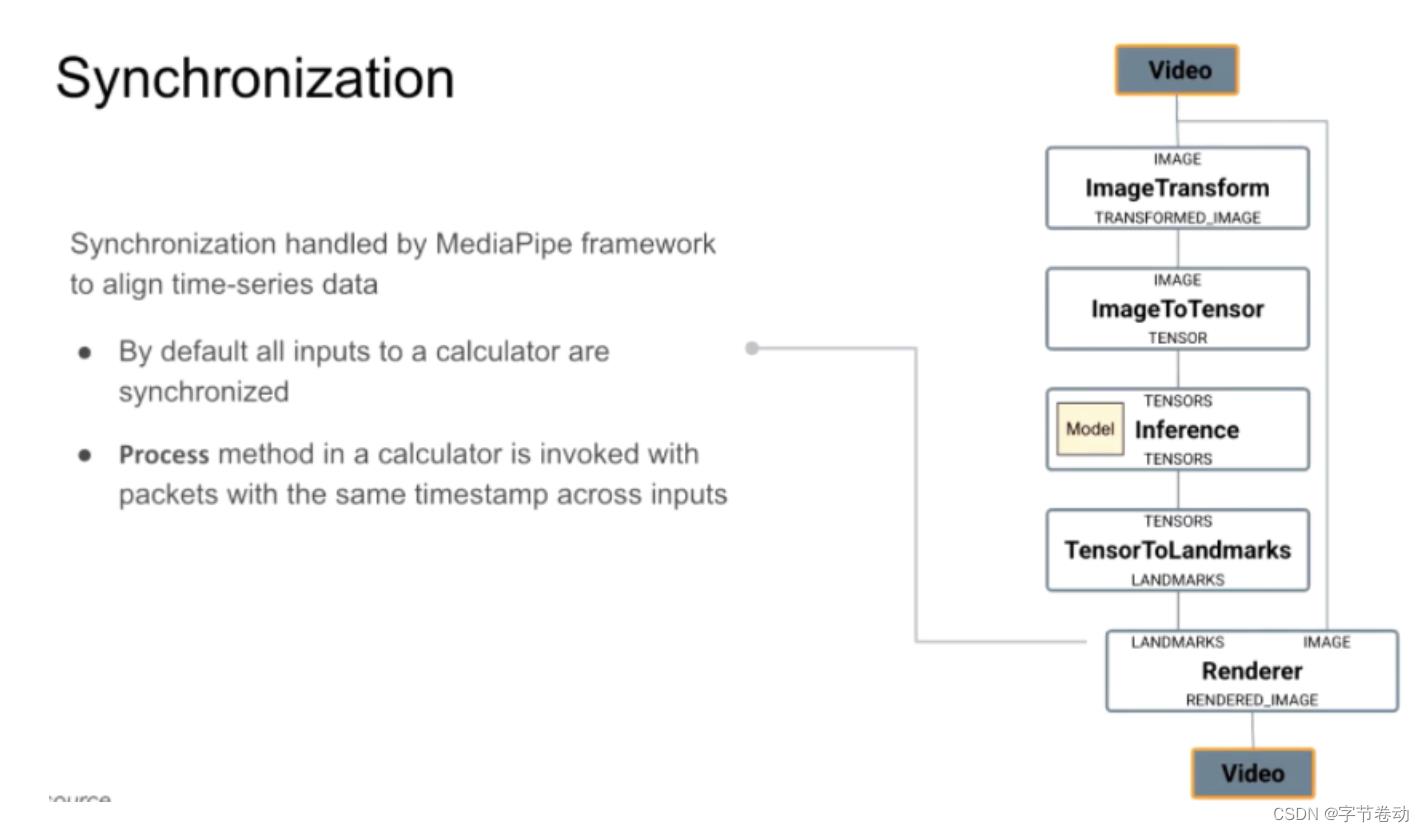
图10:Calculator的同步
Each graph has at least one scheduler queue. Each scheduler queue has exactly one executor. Nodes are statically assigned to a queue (and therefore to an executor). By default there is one queue, whose executor is a thread pool with a number of threads based on the system’s capabilities.
Each node has a scheduling state, which can be not ready, ready, or running. A readiness function determines whether a node is ready to run. This function is invoked at graph initialization, whenever a node finishes running, and whenever the state of a node’s inputs changes.
https://google.github.io/mediapipe/framework_concepts/synchronization.html
3.4 子图:Graph复用
子图的概念,是想提高复用性,如将前面的Handlandmark的超大子图声明为一个子图,可以在其他流水线中复用。需要注意这里与模型优化中的区别,当有多个calculator中不会有fusion操作。
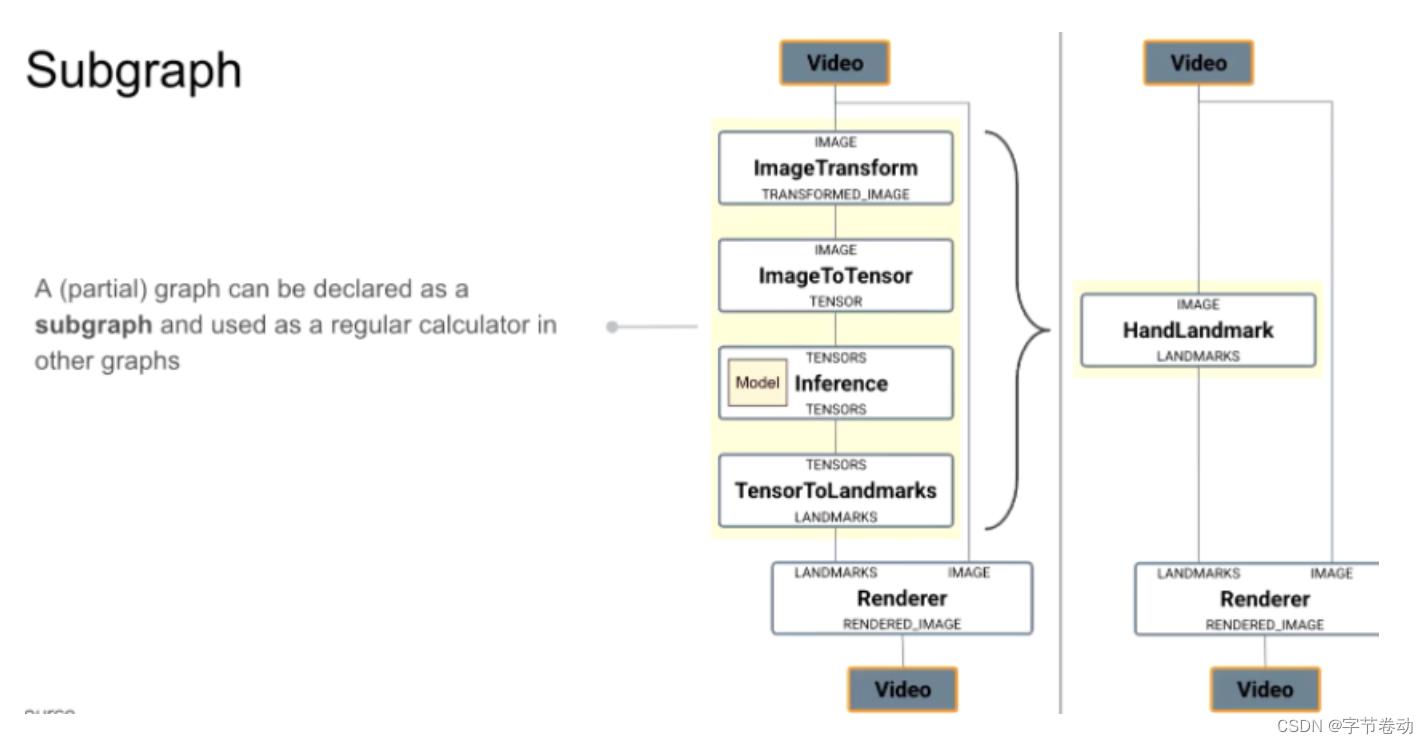
图11 子图的复用
MediaPipe Graph在初始化后,是一个固定的状态。虽然想要动态调整Graph结构这件事儿,也被不少谷歌内部用户反馈过,即运行时候想要调整整个MediaPipe graph的结构,来动态修改calculator,目前MediaPipe团队也在尝试支持这个特性,还处于内部开发状态。
4. 更通用的机器学习流水线
下面这个例子从视频接入进来,经过landmark输出关键特征点,交给渲染calculator做渲染并输出,整个流程是否已经解决hand detection/landmark的所有事情呢?
**其实不然,对整个模型来说,手可以出现在图片的任意位置,手也可以是任意大小,距离镜头远近都要求模型要扫描全图,**以不同尺寸来跑图,导致对整个设备端机器学习,无法做到实时处理的。

图12 机器学习流水线的常见问题
其实有几个解决方法,先把流程切开,分为先对手做检测,然后再做handlandmark模型,看起来是一个比较合理的方案,真实使用中,也发现这个任务,并非需要检测手的完整图像,**最好是侦测手掌的位置,因为手会乱动,其检测是困难的,但手掌是一块相对来说比较整体,也更简单,手掌也是一块接近正方形的区域,无需关心其比例问题,**只需要检测正方形区域是否是手掌就行。
在MediaPipe对Handlanmark过程中,是先做手掌检测,然后再做Handlandmark特征点的流程。但这个整体还存在一个问题,虽然比之前的PPT展示的流程已经快了,但手掌检测是相当慢,整体还是无法达到实时。

图13 通过手掌检测的前置模型提高实时性
一个解决方法,我们先不管手掌检测,先在上一帧做handlandmark的矩形框给到下一帧,相当于给下一帧一个提示手的大概位置,这样置信度比较高,在大概什么位置做关键特征点检测,但这个解决方案也有一个问题:冷启动需要非常多帧来扫图片,只有当置信度比较高时,才会构建这样有反馈的环路,给到下一帧来做提示。但也不是一个很完美的解决方案。

图14 用上一次关键特征点结果来定位当前帧
最终,我们提出一个**混合解决方案:在刚开始跑手掌检测。手掌检测完后得到的手掌大致位置喂给接下来handlandmark的子图,该子图会跑关键特征点检测,并给下一帧喂相关数据的提示。**直到handlandmark的结果置信度不高的时候,在下图上会有1个Gate Calculator,会再次打开,即手掌检测模型再次打开,这样的整体方案,有很快的handlandmark模型会每一帧跑,同时有一个比较慢的手掌检测模型,手掌检测模型在有需要时候才会跑。
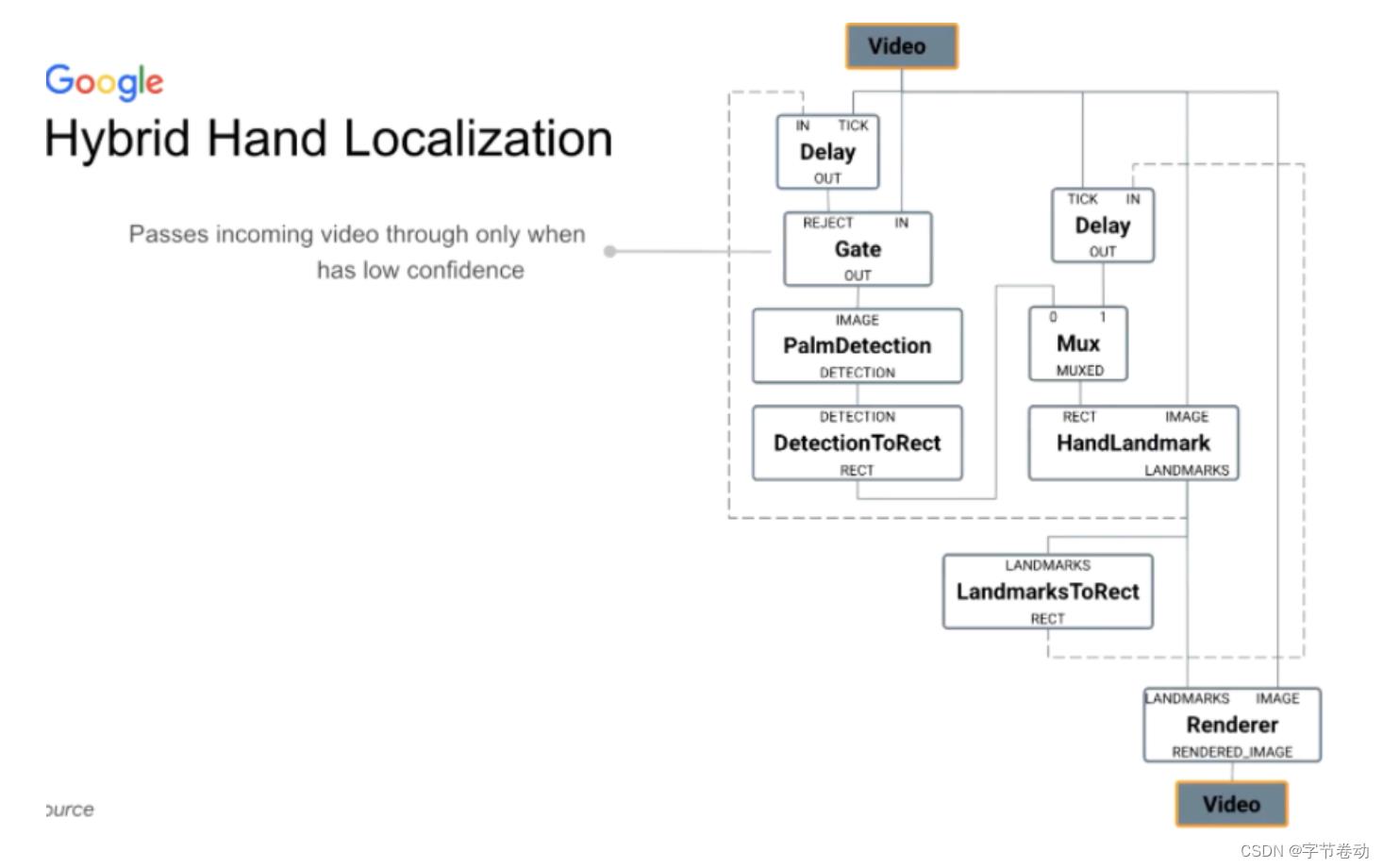
图15 最终提出的混合策略方案
在这样的组合下,实现了实时的要求,更多的技术细节可以在下面Google Blog里看到,其中实现了多个手的检测:
- https://arxiv.org/abs/2006.10214
- https://ai.googleblog.com/2019/08/on-device-real-time-hand-tracking-with.html
上述内容是MediaPipe搭建这个graph流程的细节,尤其是通过预置的calculator,但是MediaPipe不止步于此,它还提供性能上的优化,基本每个MediaPipe提供的Calculator计算都带有GPU的加速,对每个平台都有不同实现,如安卓平台是OpenCL/OpenGL/Vulkan三个都有、在Web上有WebGL/WebGPU的实现、ios上有Metal的实现。
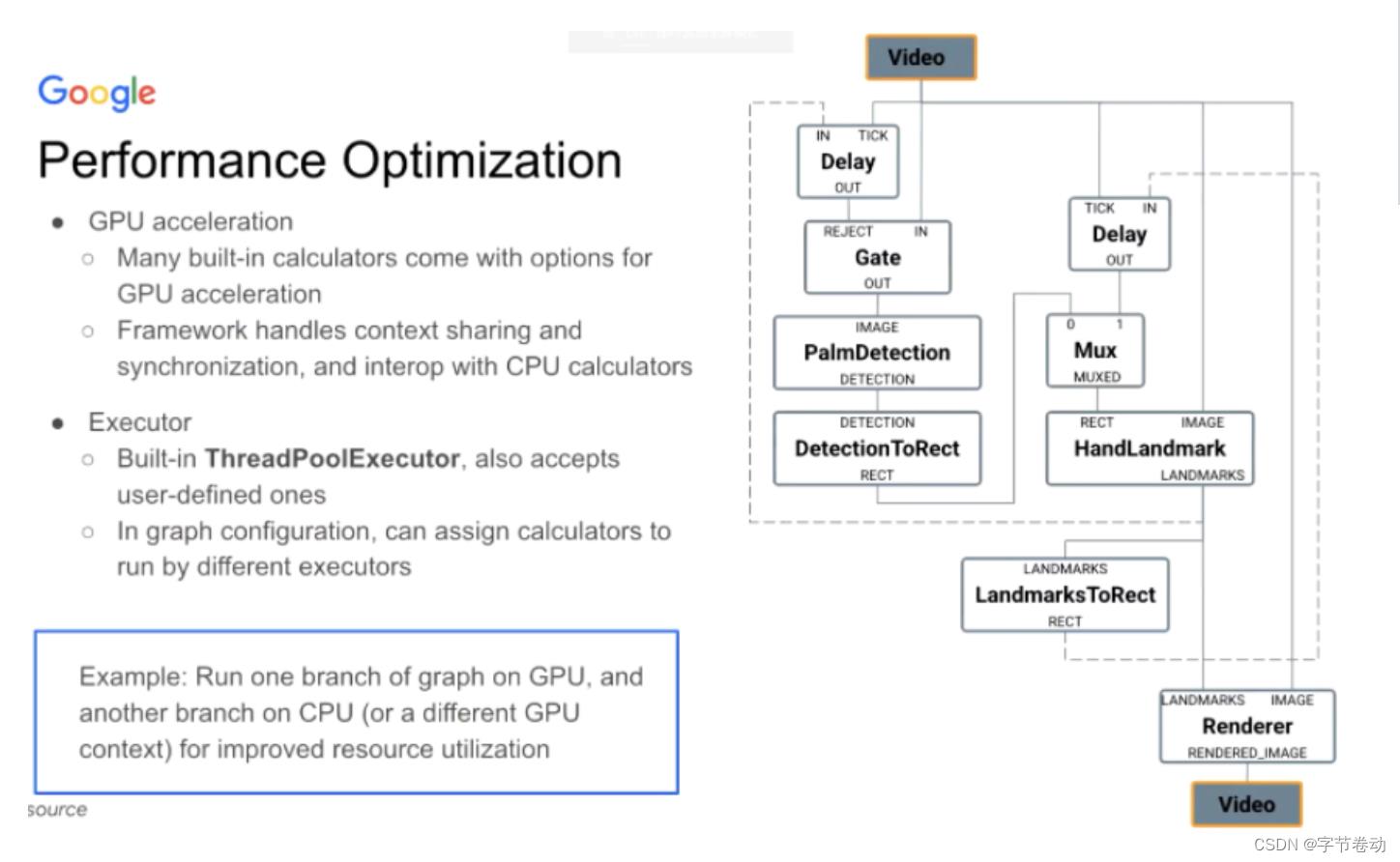
图16 MediaPipe Graph上的性能优化
而且性能优化过程中,MediaPipe也会处理GL资源的sharing和同步的问题,GPU与CPU数据有交互也是由MediaPipe来处理。
除此之外,还有一个称为Executor的东西,即你可以跑Graph的不同区域跑在不同的Executor上,如不同的TheadPool上,仍以刚刚的例子来说,将手掌检测跑在CPU上,手特征点检测跑在GPU上,甚至在这基础上加一个Render跑在一个新的Executor,并给予更高的优先级,具体的设置上,如安卓上可以指定跑大核还是小核。
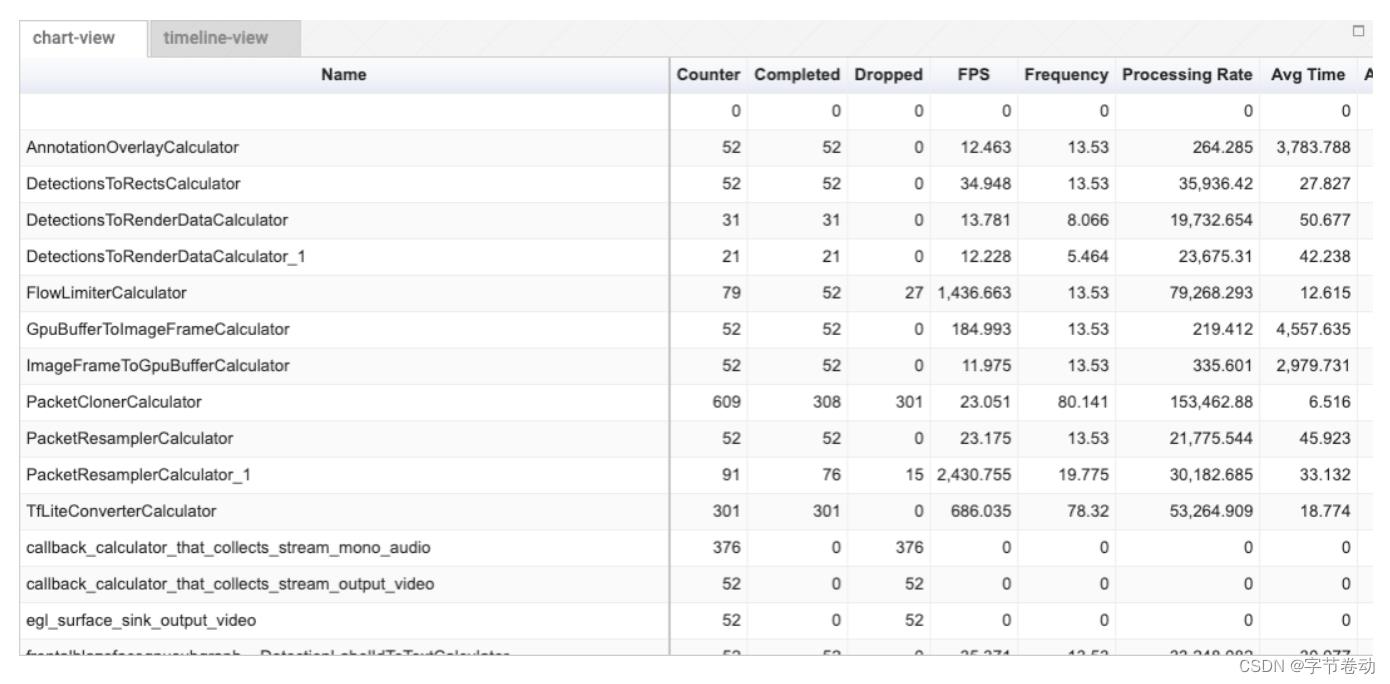
图17 viz.mediapipe.dev也提供了profiler工具查看每个calculator的耗时
总体而言,**MediaPipe不只是局限于TFLite delegate的某个设备如GPU的调用,还有跨平台的端到端的GPU加速,整个Pipeline可以完全在GPU上跑。**在MediaPipe Graph层级来说,你都是可以指定每个Calculator的粒度是跑在什么设备上。
但是一般而言,大家用MediaPipe API的话,都会指定整个Pipeline用什么设备,是CPU还是GPU,甚至为了用户友好,你不需要指定CPU亦或是GPU,只要在MediaPipe调用时候选择是否需要加速,MediaPipe会自动判断当前设备的硬件环境以及模型是否适合在GPU上跑,来选择最佳的环境。
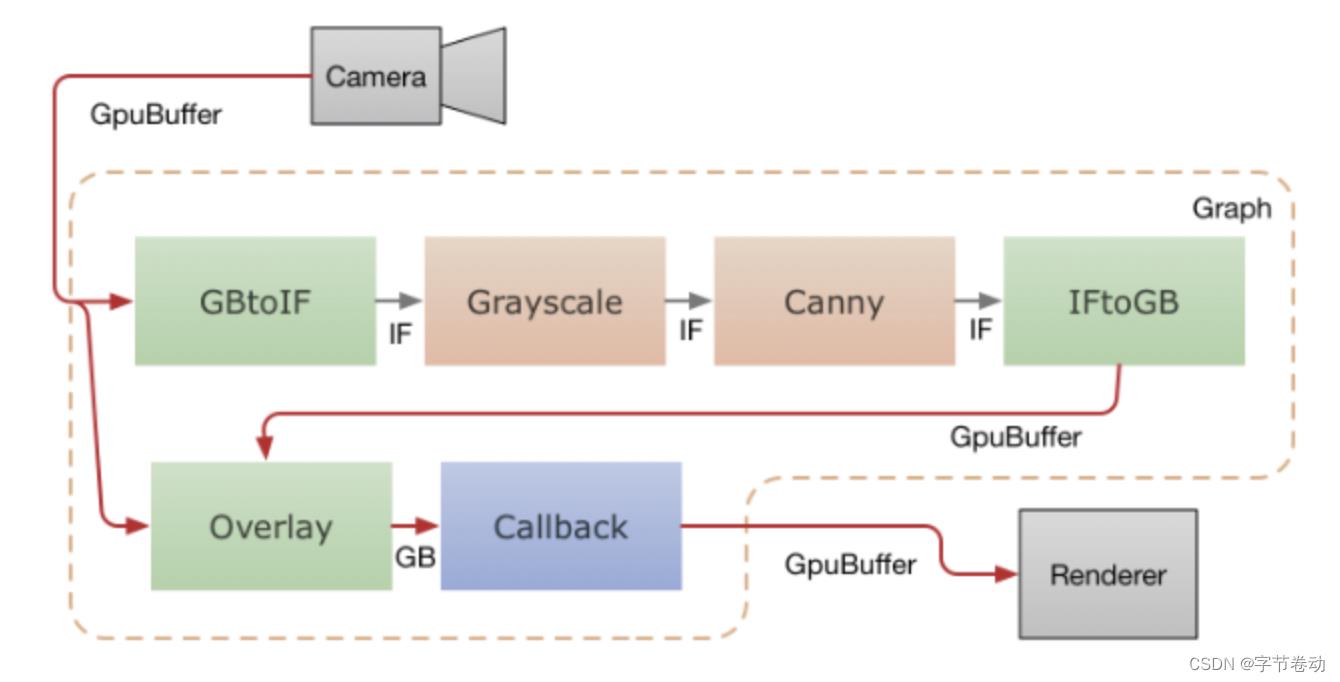
图18 视频帧从camera喂给GpuBuffer,再通过两个并行的Calculator入口进行处理,最终通过回调拿到结果以GL方式渲染
换句话说,调度这里,包括OpenGL Context以及相关的GPU资源管理,MediaPipe都已经做好了。目前MediaPipe Face、handlandmark的模型精度都是FP32,但是中间计算精度是设备支持的FP16,默认模型不是量化模型,但是MediaPipe也支持INT8模型,MediaPipe API也支持精度的设置。
目前Google内部产品使用MediaPipe的方式都是通过Native C++的方式使用,因为不少安卓应用并不想自己做JNI Layer,希望MediaPipe自己在Native这一层做完,然后自己在JNI这一层只是调用获取到结果。
需要注意的是,iOS这里MediaPipe支持的是Metal,但是Apple本身也有CoreML,那就意味着MediaPipe会和苹果走两套不同的生态开发,目前来看MediaPipe的图片预处理等和TFLite都是用Metal来提供加速。
5. MediaPipe定制化与扩展能力
5.1 模型的扩展
MediaPipe也实现了高度定制化与扩展能力,前文我们是一个手关键点的Graph:从第一步手掌检测、手的关键特征点检测。其实整个流水线对人脸也是通用的,即将前面手掌检测换成人脸检测,手特征点换成人脸特征点检测即FaceLandmark,就可以完成对人脸任务的处理流水线。
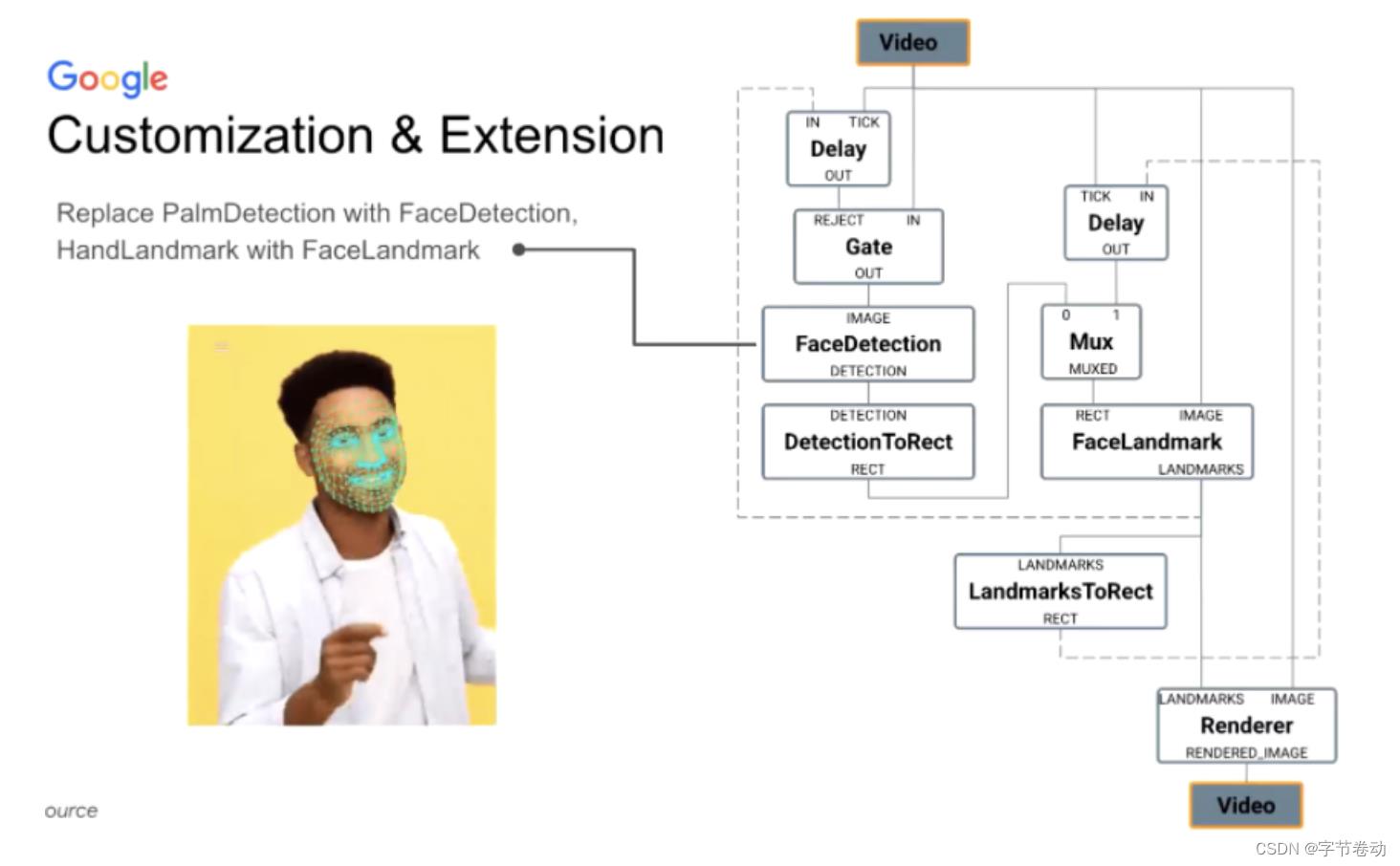
图19 MediaPipe定制化与扩展性
5.2 流水线的扩展:手势识别
比方我需要做一个手势识别,即在原本手的关键特征点检测计算完后,加入一个GestueRecognition这样的Calculator,其会跑手势识别模型,整体来说,扩展性是很容易实现。
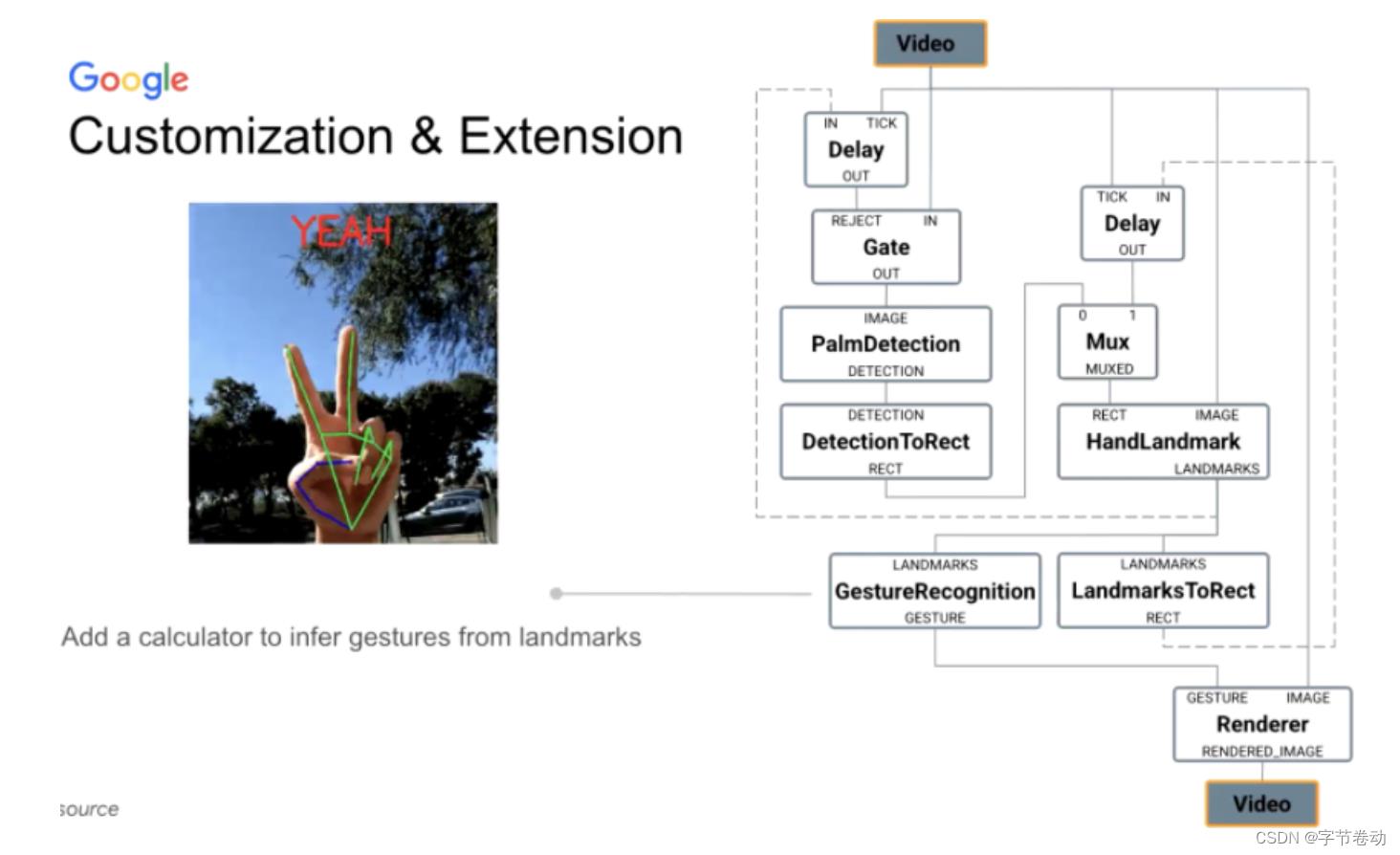
图20 新增自定义Calculator实现从手关键点到手势语义识别的功能支持
5.3 渲染特效的扩展
也是类似上面加入手势识别的Calculator一样,再加入一个计算机图形特效的渲染Calculator实现。
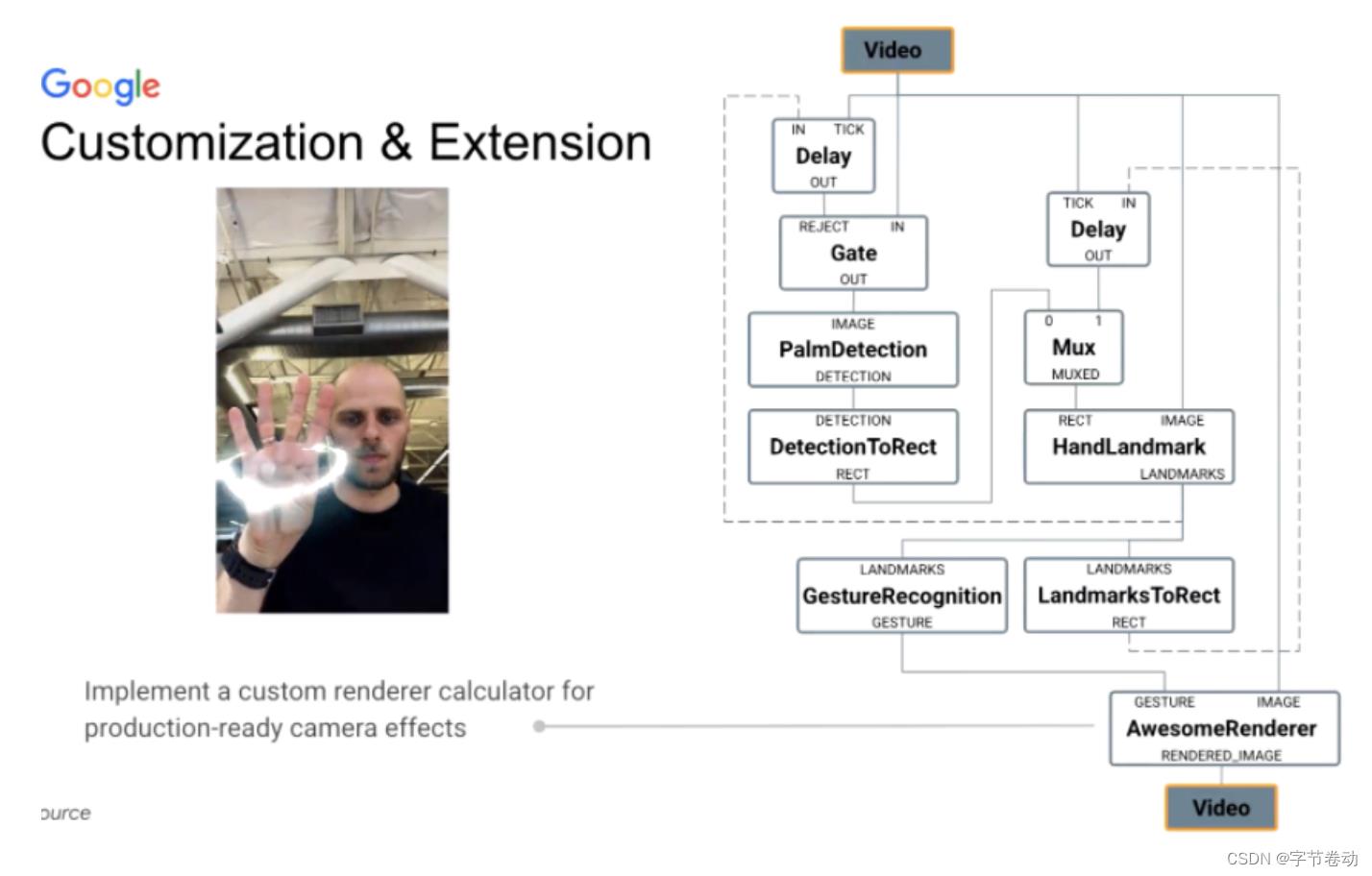
图21 实现生产环境下相机特效中的自定义渲染Calculator
在渲染这部分,你可以在MediaPipe中写OpenGL、Shader代码,表现在这个Calculator是Render,也可以导出。
目前有同学反馈,在上层依赖上,MediaPipe的渲染与Carmera有依赖关系,在版本上有不匹配的情况,MediaPipe团队也发现存在这个问题,在新版本上MediaPipe Task会尽量减少前后对Google Camera too,以及对渲染的依赖。
此外,如果TFLite本身不支持的某些算子,如某些高阶的GPU OPs、特定模型的奇怪OP,TFLite并不想merge,不通用或者对于TFLite来说用的很少,MediaPipe是需要单独写算子的。
6. MediaPipe工具包
MediaPipe是基于C++的,MediaPipe上面有搭建Graph的API,即Graph layer,再往上——应用层,即Application layer,对C++/Python/Java等都已经支持,目前还没有加在图上的如最近新加入的MediaPipe Task与Model Maker,接下来的内容会讲到。
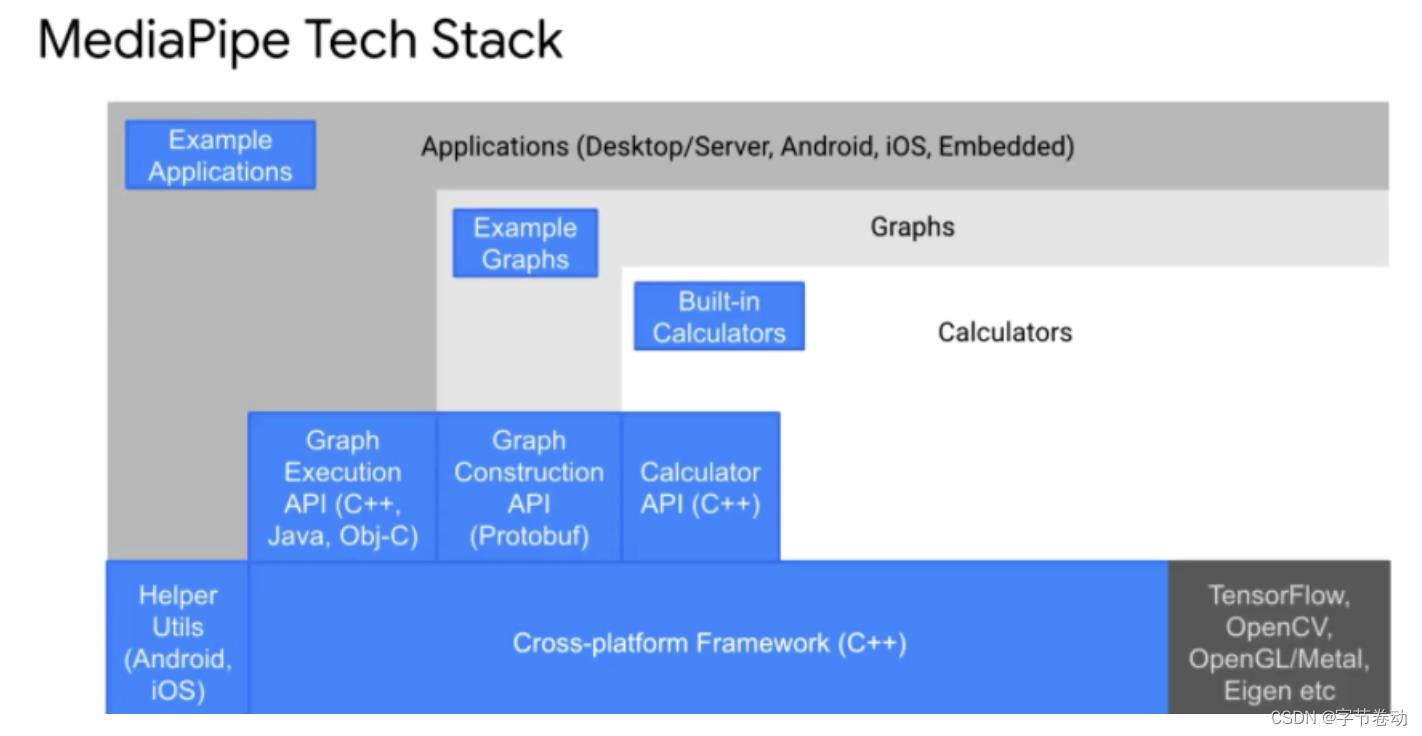
图22 MediaPipe背后的技术栈
目前MediaPipe已经是一个完整开源的项目,19年6月份在开源,最早发布是在CVPR上,现在已经有18k的Github star数,使用的开源协议是Apache 2.0。当前MediaPipe的构建工具是Bazel,后续是否会支持CMake构建因为人力的问题还不好说。目前MediaPipe直接放的Maven,可以在编译使用时,用Gradle将MediaPipe Solution Core这个Maven aar读取进来(https://google.github.io/mediapipe/gettingstarted/androidarchive_library.html),不需要对MediaPipe用Bazel从头编译。

图23 MediaPipe的开源里程
虽然MediaPipe是开源项目,但是对于第三方提交的PR还是比较谨慎,尤其是API的修改,因为内部产品团队也在用,如果有太大修改的话对内部产品团队会有很大影响,如导致YouTube APP的bug。但从开源社区来说,目前MediaPipe团队对于外部的PR上是欢迎的,如果有PR Merge需求,可以单独联系我们。
下图左边是MediaPipe当前的文档docs.mediapipe.dev,右边是对MediaPipe可视化的工具viz.mediapipe.dev,可以直接把建立好文本的MediaPipe graph贴到右边的编辑框中,就可以显示生成出Graph的样子。有时候,只看文本可能会少连接一条线,而且内部我们使用也很多,本质是一个类似Prototxt的可视化工具。

图24 MediaPipe详尽的文档与可视化功能
核心的Calculator都会在4MB的MediaPipe runtime里,如果需要定制则需要自己编译,这个4MB包含MediaPipe Graph结构以及其中用到的基本TFLite runtime等等。
目前Google内部不同产品组的使用方式不同,都是编译到自己产品中,比方最终形式是APP的一个动态链接库文件,MediaPipe就在其中,或者是多个动态库文件,如果某个产品组做的不是很好的话,可能MediaPipe会出现在一个产品APP的多个动态库里,但具体来说,MediaPipe并不关心业务方具体使用的方式。
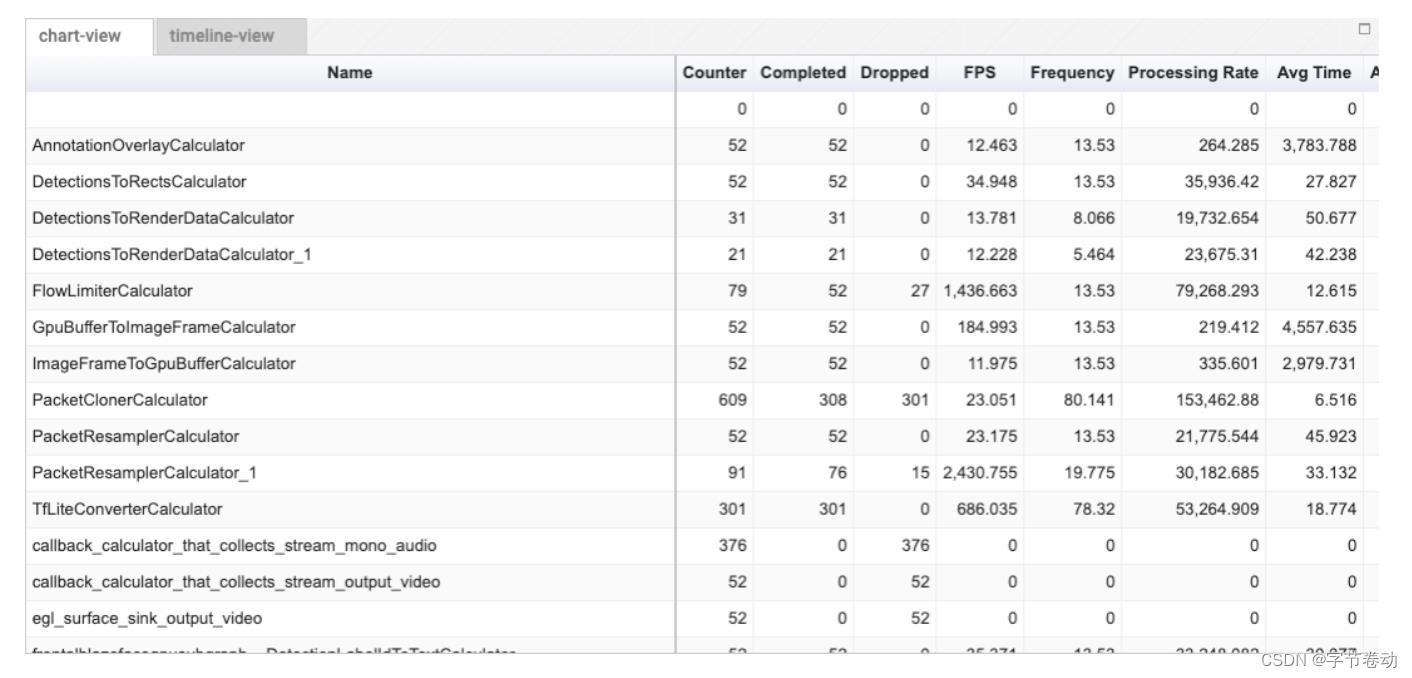
图25 viz.mediapipe.dev也提供了profiler工具查看每个calculator的耗时
7. MediaPipe Task & Model Maker
回顾前面Handlandmark这个流水线,其实整体还是较为复杂的,尤其是对于普通的开发者而言。MediaPipe想把设备端开发和部署的流程完全简化。
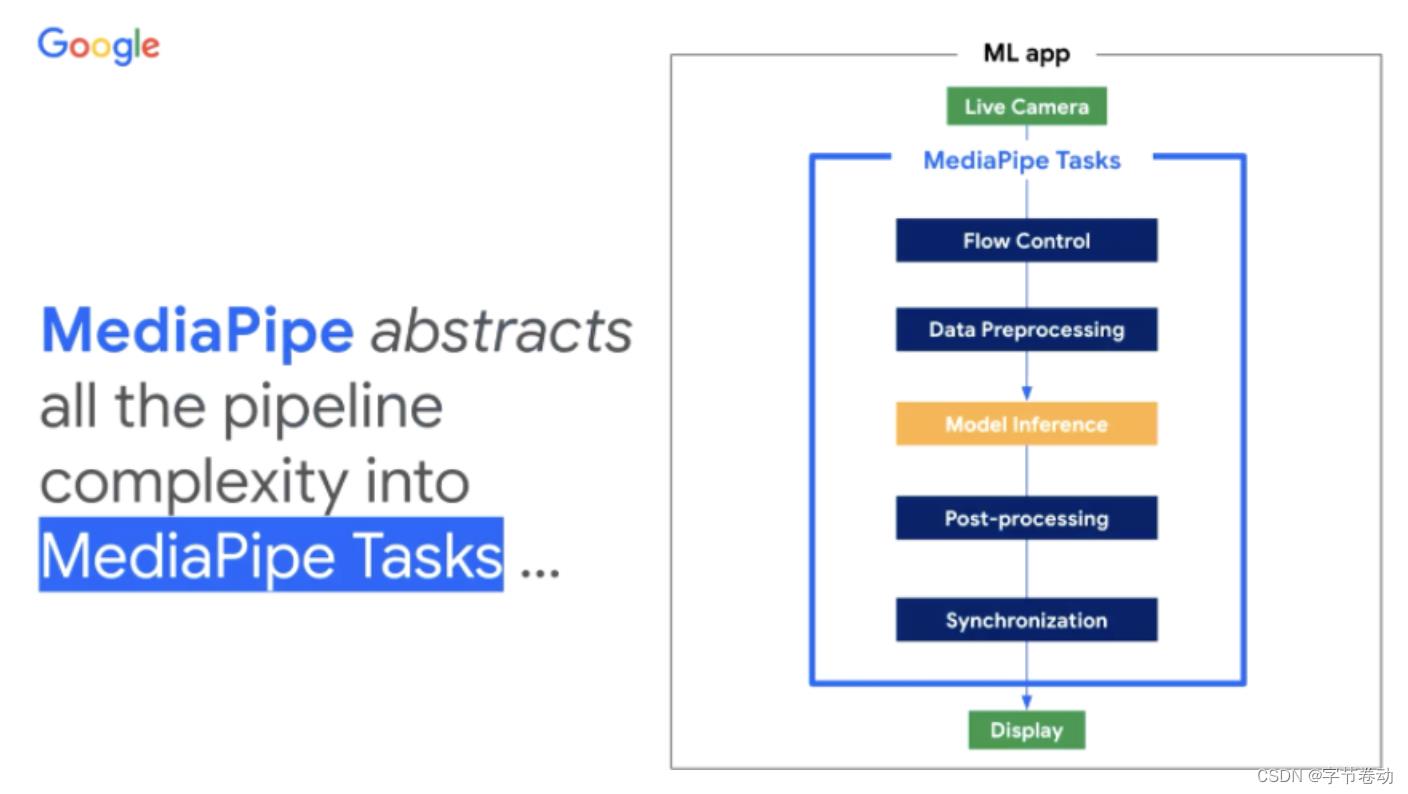
图26 MediaPipe将整个机器学习流水线的复杂性,简化抽象为Task API
MediaPipe首先将上述的流水线抽象为名为Task的概念,同时还提供了MediaPipe Model Maker的工具,帮助大家根据所需构建高度可定制化模型——的完整解决方案。整体上说,只需要几行代码就能构建如文本、视觉、语音应用相关的机器学习功能。

图27 端上机器学习解决方案的低代码API支持
后续也会有完全图形化的工具箱,甚至你完全不需要写代码,在浏览器里拖拖拽拽就可以实现完整机器学习流水线的构建。

图28 不久后将支持无代码纯GUI开发的机器学习流水线
下面我们会讲几个例子:通过预置的MediaPipe Task API来部署预训练模型。下面以猫狗目标检测模型为例:
- 先下载预训练模型:tfhub.dev/tensorflow/collections/lite/task-library。目前可以从tensorflow hub上下载到不同类别的目标检测模型;
- 比方下载的模型是EfficientDet-Lite模型,接下来我们用Task API来检测,检测结果包含了1000类的结果所属的类别ID,类别分数以及所在图上的检测框位置信息;
如果是使用MediaPipe Python API来做目标检测,则是下面的流程:

图29 MediaPipe Task Python API预测结果
该过程会在红框内的位置,将检测流水线,展开成前面我们所说的MediaPipe Graph,之后读取图片并得到结果。
MediaPipe也支持安卓和iOS上部署,类似Python,先在TFHub上下载模型给到ObjectDetector,然后读取位图拿到结果。
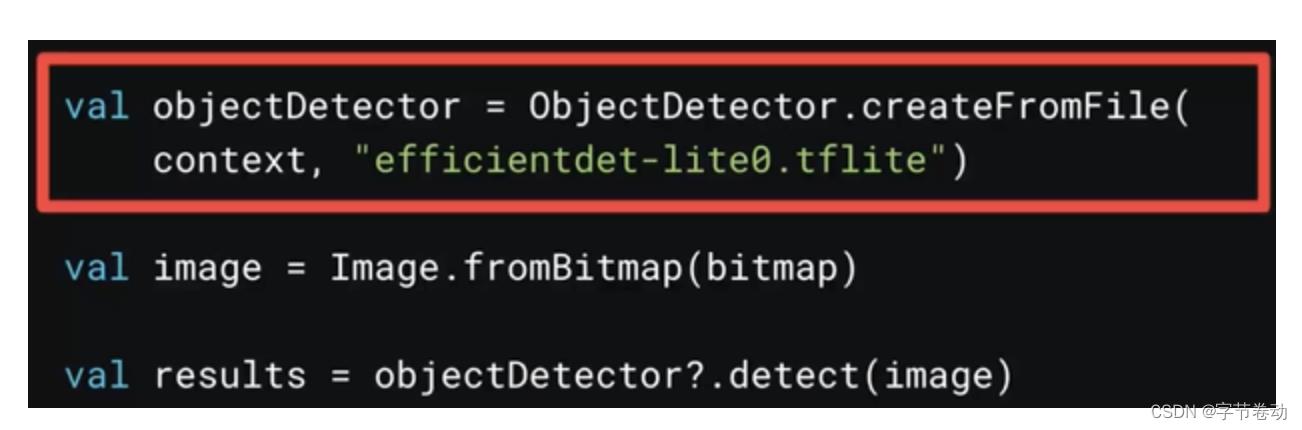
图30 MediaPipe Task Android API
7.1 自定义数据集与模型
前面说的都是直接拿来预训练使用,但通常我们需要定制化特定任务的模型,如下面这个例子我们来看看如何使用Model Maker来检测android Pig。

图31 自定义数据集识别安卓机器猪
这个需求可以通过使用MediaPipe Task+Model Maker API来实现,主要分为三步:

图32 Model Make与Task API基本使用流程
- 收集安卓玩偶与安卓猪玩偶数据并进行标注。足够高精度则需要每个类别拍100张以上的图片,接下来是使用LabelImg这样的标注工具对类别名称以及位置进行快速标注,并导出标注数据;
- 训练定制化模型。可以使用免费GPU资源在Colab上训练;
- 使用MediaPipe Task API来部署模型。

图33 收集数据:对所有安卓玩偶拍照
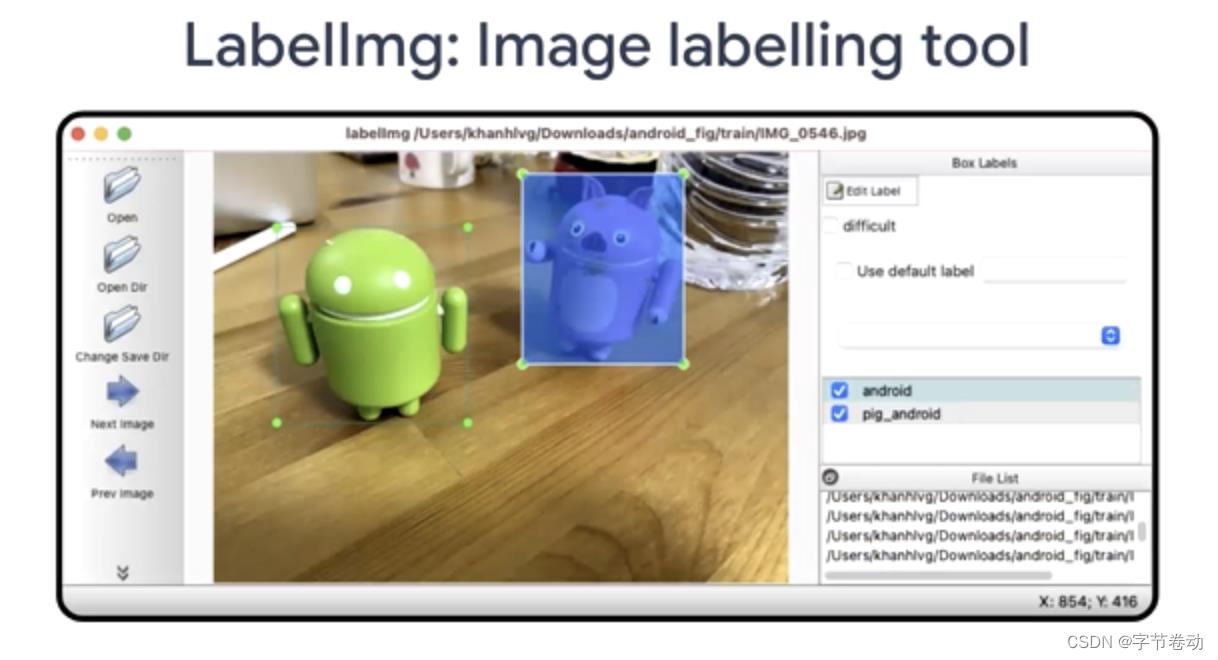
图34 用LabeImg做图像标注
在训练定制化模型这一步,可以通过 pip install tflite-model-maker来快速安装Model Maker包,使用如下命令使用预训练模型,相关API来开始训练。
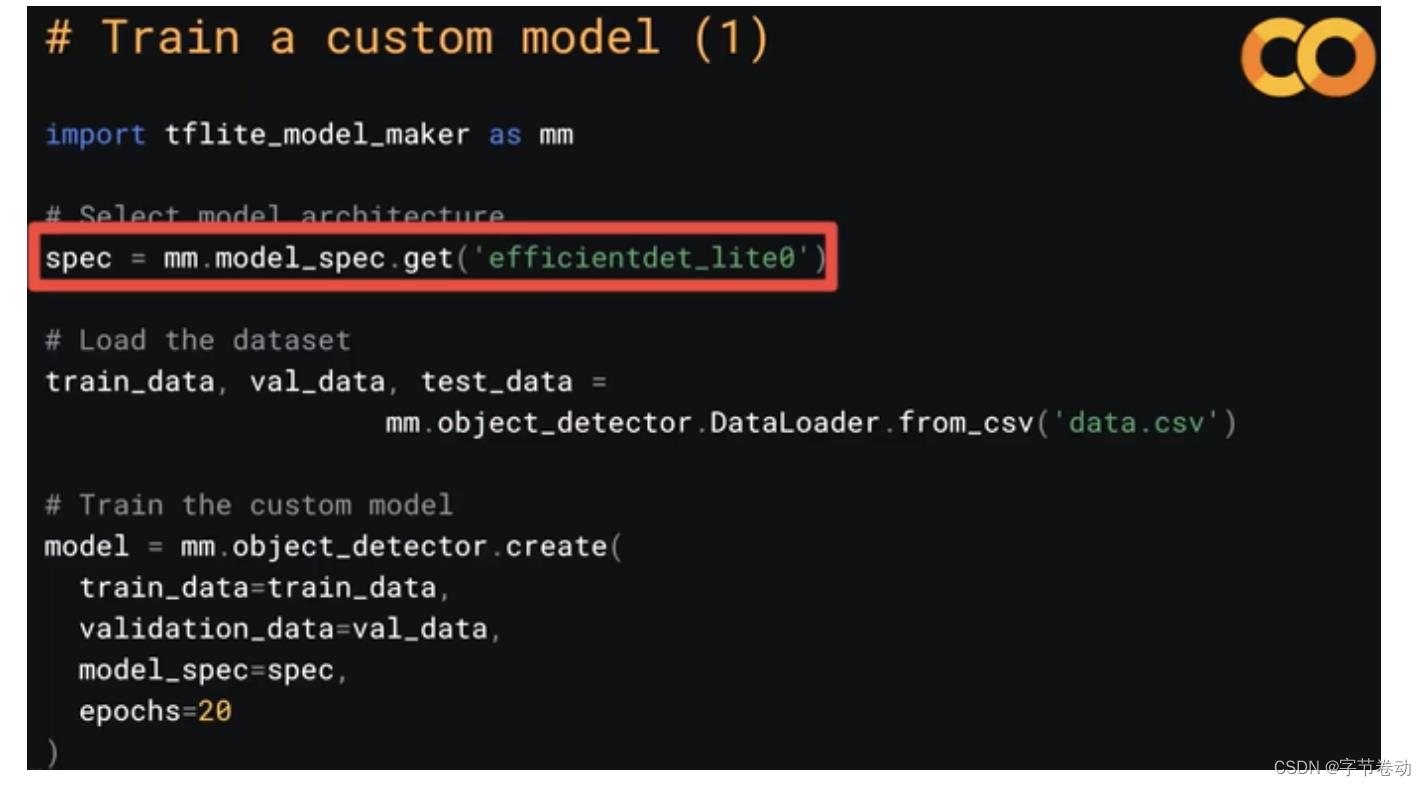
图35 训练自定义模型
训练完成后,则拿测试数据集来测试模型准确率,达到满足需求的高准确率时,便可以导出并准备部署

图36 评估模型精度并导出模型
鉴于先前已经在安卓上部署过模型,这里只需要将模型路径替换为这次定制的模型路径即可。
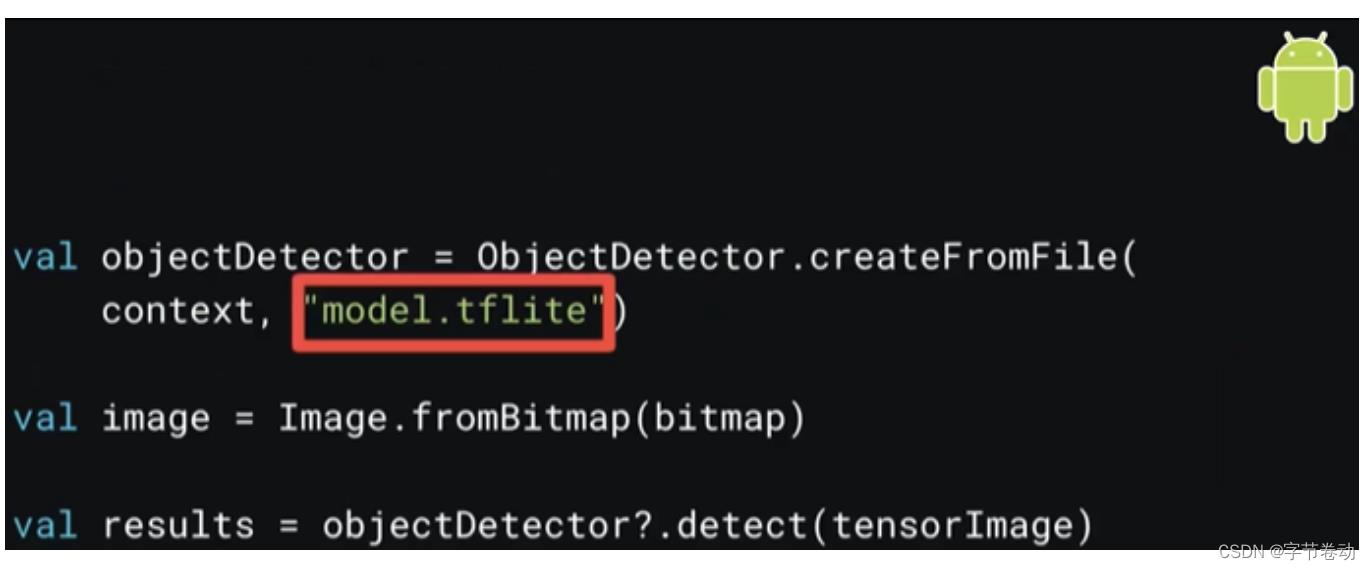
图37 在安卓上替换模型并实现预测
最终可以看到检测到了Android和Pig Android的效果,在安卓上目前runtime在4MB左右,其中包含了tflite runtime,也包含opencv的基本库。

图38 检测识别Demo APP的输出效果
回到前面所说的人手任务,在未来即将支持更多的任务,特别是定制化的手势识别模型,可以根据自己需要创建如将手势转换为表情符号,即先收集手势图片(这里标注图片不需要标注关键点,只需要标注手势是什么),然后再用Model Maker去训练定制化模型,第三步使用MediaPipe Task进行部署。

图39 手势识别案例效果
后续相关的能力都可以在mediapipe.dev上看到,或者是加入Google Group:mediapipe-solutions-announce来获取更多的最新动态。可能不少同学比较关注Benchmark,后续MediaPipe在发布一个Task后都会发布相关的Becnhmark,如安卓、iOS数据。
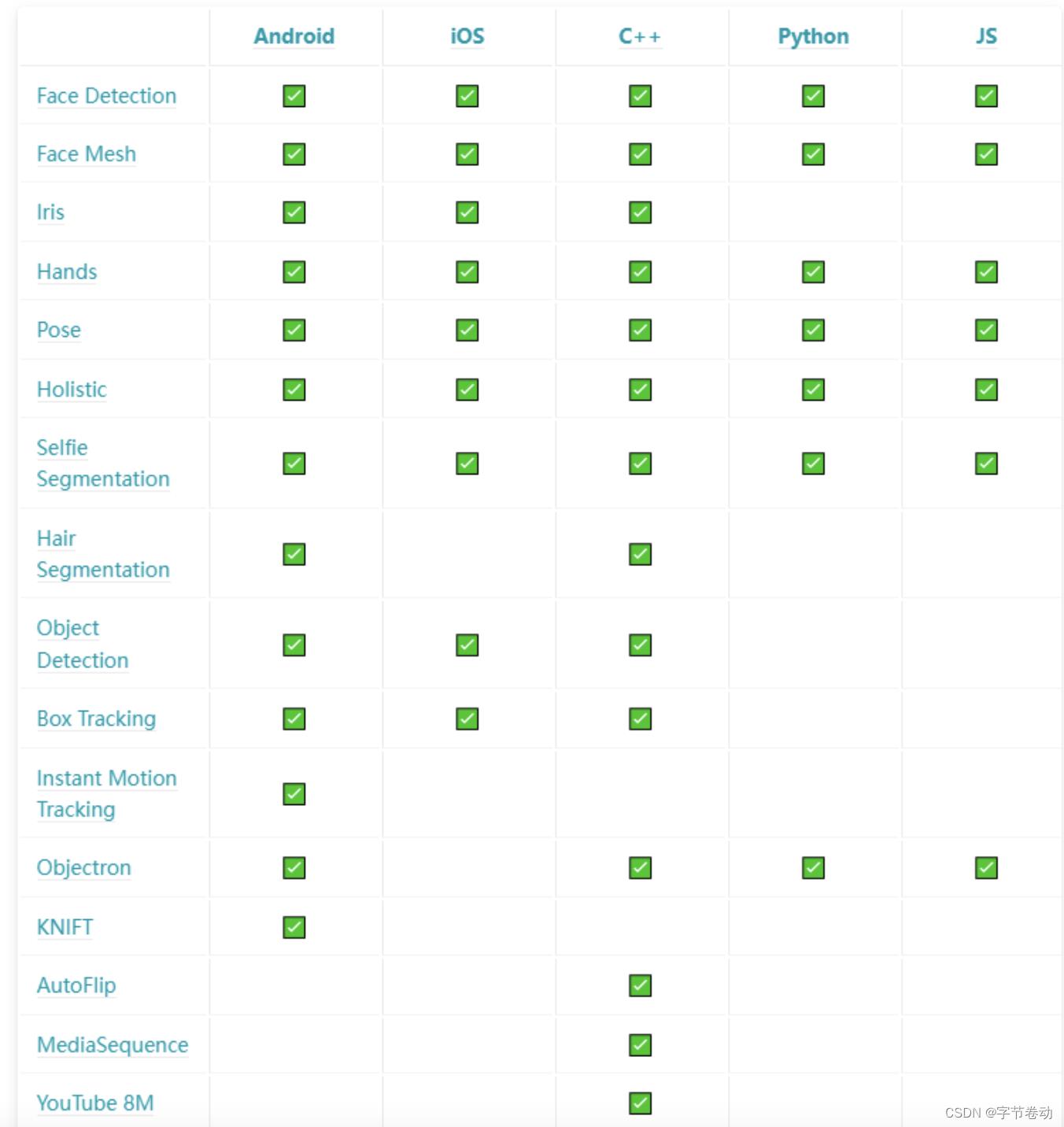
图40 MediaPipe当前支持的完整解决方案(右边还有一列是Coral,支持有限就不展示了)
目前MediaPipe支持的硬件设备还主要是CPU、GPU对图像、视频数据的处理,未来也会加入DSP对音频数据的处理,针对特别的硬件,目前还需要开发者自己去实现。
作者:开心的派大星
文章来源:NeuralTalk
推荐阅读
- 超轻目标检测 | 超越 NanoDet-Plus、YOLOv4-Tiny实时性、高精度都是你想要的!
- MediaPipe模型解读 | MoveNet-SinglePose:自底向上做单人姿态估计
- Pytorch编译机制的总结(来自吴芃老师)
更多嵌入式AI干货请关注 嵌入式AI 专栏。欢迎添加极术小姐姐微信(id:aijishu20)加入技术交流群,请备注研究方向。
以上是关于转载Google MediaPipe:设备端机器学习完整解决方案背后的技术实现的主要内容,如果未能解决你的问题,请参考以下文章