论文解读:From Pixels to Objects: Cubic Visual Attention for Visual Question Answering
Posted yealxxy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文解读:From Pixels to Objects: Cubic Visual Attention for Visual Question Answering相关的知识,希望对你有一定的参考价值。
这是关于VQA问题的第十一篇系列文章。本篇文章将介绍论文:主要思想;模型方法;主要贡献。有兴趣可以查看原文:From Pixels to Objects: Cubic Visual Attention for Visual Question Answering
1,主要思想
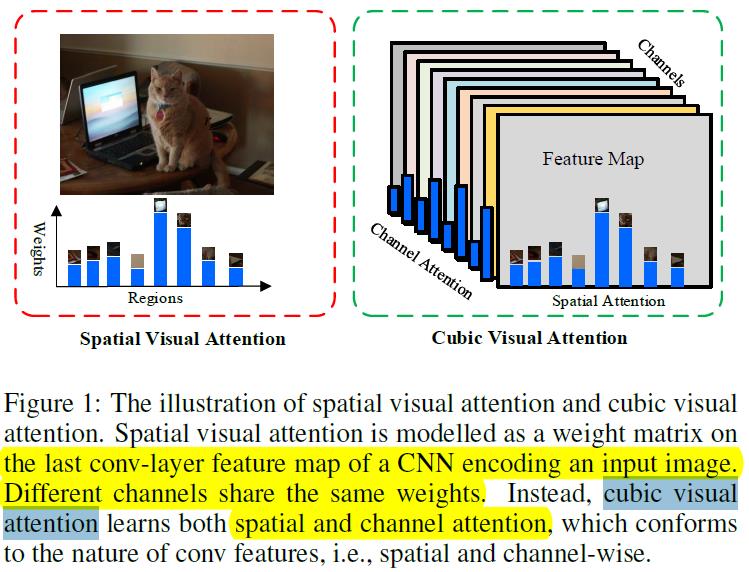
作者提出一般的Spatial visual attention只是选出了最关注的视觉对象,在通道上采用的相同的权重,这不符合attention的思路。基于此,作者提出cubic visual attention,在通道和空间上同时进行选择重要的。具体的区别见下图:
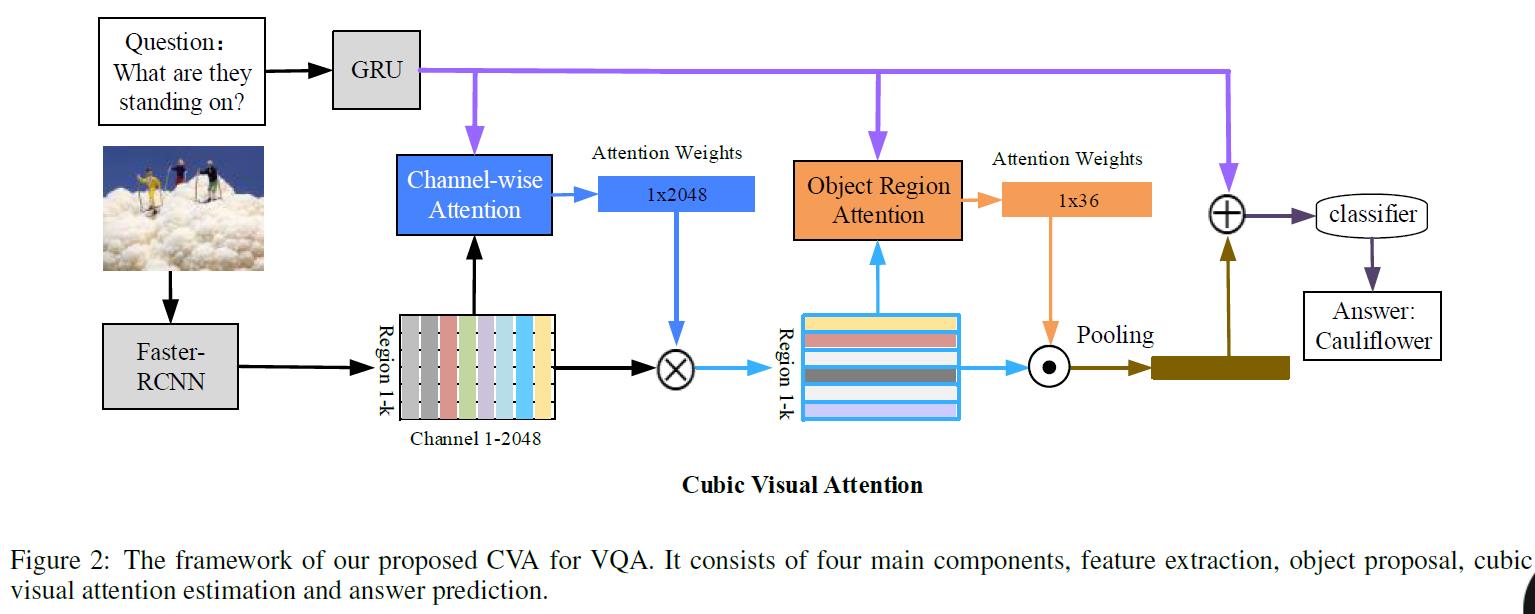
2,模型结构
- 首先对图像进行目标识别,提取视觉特征;同时对问题采用GRU编码
- 进行channel-wise attention
- 进行spatial attention
- 预测输出
a.Input Representations
- 对图像采用Faster R-CNN模型,提取k个主要的对象,并特权特征,每个对象特征维度D.
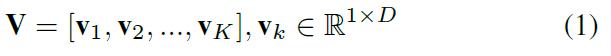
- Encoding Question Features:对词向量采用GRU进行编码。
b.Channel Attention(通道)
cnn的通道代表了不同粒度的特征,低维度的边缘特征和高粒度的语义特征。这篇论文对last conv feature map进行池化,这样每个通道代表着对象的属性特征。也就是说通道上的attention选择了视觉对象重要的语义属性。过程如下:
- 先对视觉特征V进行reshape:

- 对通道进行池化:

- attention权重计算部分:

可以简写成:

- attention结果:

c.Object Region-based Spatial Attention
就是对区域对象进行attention,选择重要的对象。
- 权重计算:
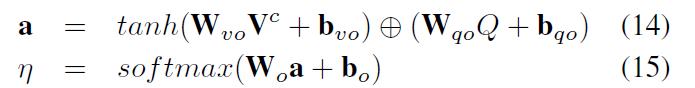
可以简写成:

- attention结果:

d.预测输出
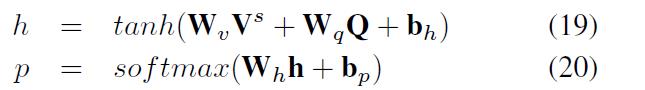
e.A Variant of CVA
- 上面的步骤可以总结为:
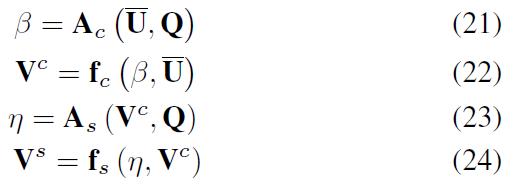
- 为了对比,可以变化为:

3, 主要贡献
- 提出了基于cubic visual attention,在通道和区域上进行关注。
以上是关于论文解读:From Pixels to Objects: Cubic Visual Attention for Visual Question Answering的主要内容,如果未能解决你的问题,请参考以下文章