(DDIA)数据存储与检索——B-tree
Posted 雨钓Moowei
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了(DDIA)数据存储与检索——B-tree相关的知识,希望对你有一定的参考价值。
翻译《Designing Data-Intensive Applications》
作者:Martin Kleppmann
译者:雨钓(有增改)
一、B-Tree
目前我们所讨论的日志结构的索引已经被广泛认可,但是他们却不是最普遍的索引类型。被用于构建索引的最普遍的数据结构于此有很大的不同,我们称之为:B-Tree
在1970年引入,不到10年之后,已经发展到“无所不在”,B-trees经受住了时间的考验。 它们仍然是几乎所有关系数据库中的标准索引实现,而且许多非关系数据库也使用它们。
与SSTables类似,B-Tree将键值对按键排序,以便允许高效的键值查找和范围查询,但二者仅有这一点相似之处,因为B-Tree有非常不同的设计理念。
我们之前看到的日志结构索引将数据库分解为可变大小的 segments,通常是几兆字节或更大的大小,并且总是按顺序写。 与此相反,B-Tree将数据库分解成固定大小的块或页面,传统上是4 KB大小(有时更大),并同时读取或写一页。 这个设计更接近符合(corresponds )底层硬件,因为磁盘存储也是采用类似的设计,数据被安排在固定大小的块中。
B-Tree中每个页面都可以使用一个地址或位置来标识,这允许一个页面转到另一个页面(类似于一个指针),注意这是在磁盘上而不是在内存中。 我们可以使用这些页面引用来构建页面树,如所示。
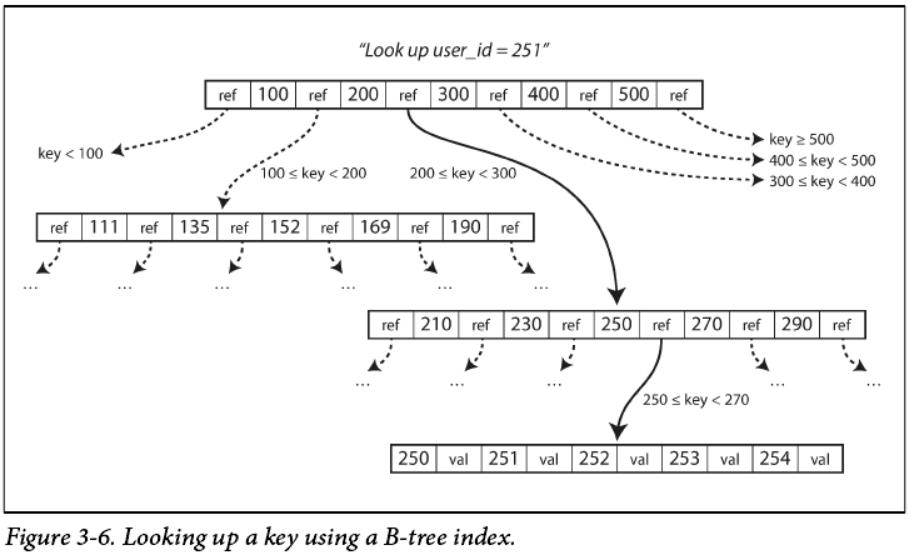
一页被指定为B-Tree的Root;每当你想要查找索引中的key时,就从这里开始。这个也包含几个key和一些指向其子节点页的指针。 每个子元素负责一个连续的键范围,引用之间的键表示这些范围之间的界限在哪里。
在图3-6的示例中,我们正在寻找key=251,因此我们知道我们需要遵循在边界200和300之间的页面引用。 这就把我们进一步引入200-300范围分解的子范围。
最终,我们会找到一个包含单个key(叶子页)的页面,其中包含每个key的值,或者包含指向该值的页面的引用。
在B-Tree的一页中对子页面的引用数量称为分支因子(branching factor)。例如,在图3-6中,分支因子为6。在实践中,分支因素取决于存储页面所需的空间数量和范围边界,但通常是几百个
如果您想要更新B-tree中的现有key的值,则需要搜索包含该key的页,更改该页面中的值,并将该页面写回磁盘(任何对该页面的引用仍然有效), 如果您想添加一个新key,您需要找到其范围包含新key的页面并将其添加到该页面中。 如果页面中没有足够的空闲空间来容纳新key,那么它切分成两个完整的页面,而父页面将被更新,如图3-7( 将一个新key插入到B-Tree中是相当直观的,但是删除一个key(同时保持树的平衡)会更复杂一些[2])。
[图片上传失败…(image-bd0a82-1550122280516)]
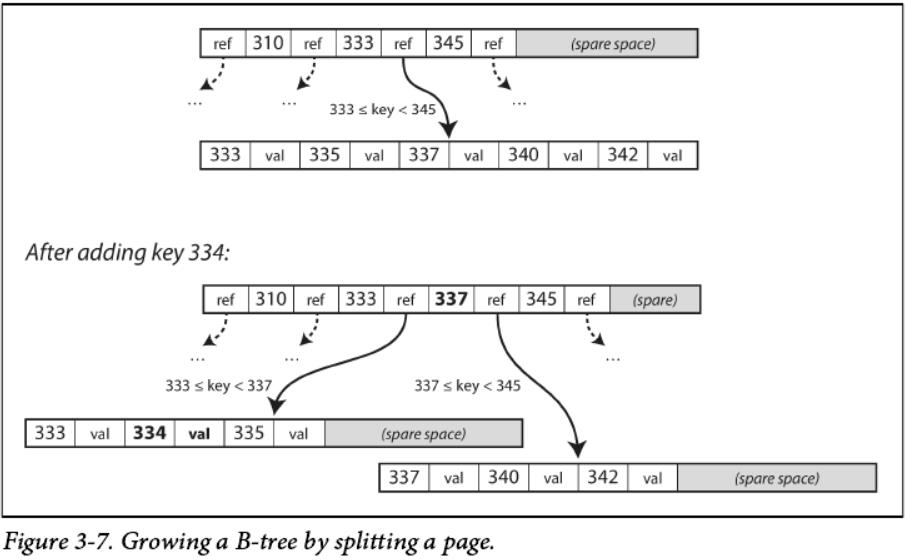
这个算法保证了树的平衡:一个b -树,n个键,alwayshas a depth of O(log n),大多数数据库都能适应B-tree,它有3到4个级别,所以你不需要遵循很多页面引用来找到你要查找的页面。(4kb页的四层树,其分支系数为500,可存储到256 TB(即500^4*4k)。)
二、Making B-trees reliable
B-Tree底层基本的写操作是用新的页面数据覆盖磁盘上的一个页面,我们先假定覆盖写操作不会改变页面的位置,例如; 当页面被覆盖时,所有对该页面的引用都保持不变。 这与lsm -tree这样的日志结构索引形成了鲜明的对比:这些索引只会附加到文件(最终会删除过时的文件),但永远不会修改文件。
您可以考虑将磁盘上的页面重写看做为实际的硬件操作。 在磁盘上,这意味着把磁盘头移到正确的位置,然后用新的数据覆盖适当的扇区。 在SSD上,由于SSD必须在一段时间内清除和重写相当大的一段晶体管芯片[19],所以会发生一些更复杂的情况。
此外,有些操作需要覆盖多个不同的页面。 例如,因为插入它的内容过多导致需要分割一个页面 ,那么您需要将两个页面分开,并覆盖它们的父页面,同时更新两个子页面的内容。 这是一个危险的操作,因为如果数据在仅仅一些页面被写入后崩溃了,那么您最终会得到一个cor - rupted索引(例如,可能会有一个孤儿页面,而不属于任何父页面)。
为了使数据库恢复到崩溃的状态,B-tree的实现通常包括在磁盘上添加一个额外的数据结构:write-ahead log(WAL, also known as a redo log)。 这是一个附加(append-only)的文件,在更改被应用到树本身的页面之前,每一个B-tree修改都必须被写入到该文件。 当数据库在崩溃恢复时,这个日志被用来恢复B-tree,并将数据返回到一个一致的状态[5,20]。
更新页面的另一个复杂之处是,如果多个线程在同一时间访问B-tree,则需要进行严密的并发控制,否则线程可能会在不一致的状态下看到B-tree中的数据。 这通常是通过使用锁 (轻量级锁)来保护树的数据结构的。 在这方面,日志结构的方法比较简单,因为它们在后台进行所有合并,而不会干扰正常的查询,并且不时地将新segments与老的segments进行原子操作的交换。
三、B-tree optimizations
由于B-tree已经存在了很长时间,所以许多优化技术在过去的几年里发展起来也就不足为奇了。仅举几个例子:
- 有些数据库(如LMDB)使用了一个复制-写的方案[21],而不是覆盖页面并维护一个用于崩溃恢复的WAL。 一个修改后的页面被写入到一个不同的位置,并且在树中创建了一个新版本的父页面,指向新的位置。这种方式对并发也是有用的
- 我们可以通过不存储整个key来节省页面空间,但可以缩写它。 特别是在树的内部页面,key只需要提供足够的信息作为key范围之间的边界。将更多的key放入一个页面中,可以使树具有更高的分支系数,从而使级别更低( 这种变体有时被称为B+树,尽管这种优化很常见,但它通常与其他B-tree变体没有区别。)。
- 一般来说,页面可以放置在磁盘的任何位置;key值的范围相近,并不要求page在磁盘上的位置也要相邻。 如果一个查询需要扫描按顺序排列的key范围内的部分,那么页面逐页布局就可能是不高效的,因为每个读到的页面都可能需要一个磁盘查找。 因此,许多B-tree实现都试图对树进行布局优化,以便页面在磁盘上按顺序存储。 然而,当树生长时,很难维持这种顺序。 相比之下,由于lsm -树在一个合并过程中重写了大量segments存储,因此它们更容易在磁盘上保持数据按key连续。
- 额外的指针被添加到树中。例如,每个leaf页面都可以引用其位于左和右的同级页面(sibling pages),这样可以在不跳转回父页面的情况下按顺序对其进行扫描。
- 像分形树这样的B-tree变体[22]借用了一些逻辑结构的想法来帮助磁盘寻找(它们与分形无关)。
四、Comparing B-Trees and LSM-Trees
尽管B-Tree实现通常比LSM-Tree实现更成熟,但LSM树的特性也很有用。根据经验LSM-Tree通常对写操作支持更友好,写操作更快,而B-Trees被认为读起来更快[23],在LSM-Trees上读取通常要慢一些,因为它们必须检查不同的压缩阶段的数据结构和SSTables。
但是,基准测试通常对工作负载的细节并不十分不确定。你需要使用你的特定工作负载来测试系统,以便获得更为准确的测试结论。 在本节中,我们将简要讨论一些在度量存储引擎性能时值得考虑的事情。
五、Advantages of LSM-trees
B-Tree索引至少需要写两次数据:一次是写日志(write-ahead log),一次是树页面本身(可能是页面分割后)。 同时即使页面中只有几个字节发生了变化也需要对整个页面进行重写。 有些存储引擎甚至会在相同的页面上重写两次,以避免在出现电源故障时出现部分更新的页面[24,25].。
由于重复的压缩和SSTables的合并,日志结构的索引也需要多次重写数据。 这个中多次写入数据库,导致在数据库的生命周期中对磁盘进行多写操作—称为write amplification。 当使用ssd时就需要特别注意,SSD是有写入次数的,所以在使用SSD时只能覆写固定的块,即这些块的写入次数还没有被耗尽。
在哪些需要对数据库进行大量写操作的应用程序中,性能瓶颈可能是数据库写入磁盘的速率。 在这种情况下,write amplification有一个直接的效率成本:在可用的磁盘带宽内,一个存储引擎写入磁盘的次数越多,每分钟内处理写入的将越少 。
此外,LSM-Tree通常能够比B-Tree保持更高的写吞吐量,一部分原因是它们有时具有更低的写扩增(尽管这取决于存储引擎的配置和工作负载),另一部分原因是它们可以顺序地写SSTable文件,而不是在树中重写几个页面[26]。 这种差异在磁盘上尤其重要,因为在磁盘上,顺序写入比随机写入要快得多。
LSM-Tree可以被更好地压缩,因此他们在磁盘上生成的文件通常要比B-Tree生成的文件更小。B-tree存储引擎会存在磁盘碎片化的问题;当一个页面被分割,或者当一个行不能存储在现有的页面时,页面中的一些空间就无法被使用,一致处于空余状态。 由于LSM-Tree不是面向页的,并且周期性地重写SSTables以清除碎片,所以在使用分层压缩[27]时,它们的存储开销更低。
在许多SSD中,固件内部使用一种日志结构算法来将随机写转化为顺序写,因此存储引擎写入模式对此影响不那么显著[19] 。但是,较低的write amplification和较少存储碎片对SSD仍然是有利:数据的存储更加紧凑,在可用的I/O 带宽中可以满足更多的读写请求。
六、Downsides Of LSM-trees
日志结构存储的缺点是压缩过程有时会影响(interfere with)正在进行的读和写的性能。 即使存储引擎试图逐步执行压缩操作以便尽量不影响并发访问。但是,毕竟磁盘资源有限,仍然很容易发生这样的情况:当磁盘完成一个昂贵的压缩操作时,请求(读请求和写请求)操作需要等待。在进行延迟监控时,这种情况虽然对吞吐量和平均响应时间的影响通常很小,但在较高的占位百分比数值中,日志结构存储引擎的查询响应时间有时相当高,而B-Tree相对而言则可以更容易预测和监测[28]
压缩的另一个问题是高写吞吐量:有限的磁盘写入带宽需要在初始写入(日志数据写入数据库和刷新memtable到磁盘)和后台运行的压缩线程之间共享。 当写入一个空数据库时,可以使用整个磁盘带宽来进行初始写入,但是数据库中数据量越大,压缩所需的磁盘带宽就越多。如果写吞吐量高,而压缩进程没有经过优化配置,则会发生压缩无法跟上写入速度的情况。 在这种情况下,磁盘上未合并的segment的数量一直在增长,直到耗尽磁盘空间,并且读取速度也会减慢,因为它们需要检查更多的segment文件。 通常,即使后台运行的压缩进程不能保持较高的压缩效率,基于SSTable的存储引擎也不会限制数据写入的速度,因此需要提供额外的监视来检测这种情况[29,30]。
B-Tree的一个优点是,每个key在索引中只存储在一个位置,而一个日志结构的存储引擎可能有多个相同的key且这些key在不同的segment中。B-Tree数据库希望提供强大的事务语义,这就使得它很具有吸引力:在许多关系数据库中,事务隔离是在key的范围内使用锁实现的,在B-Tree索引中,这些锁扫描直接连接到树[5]。在第七章,我们将更详细地讨论这一点。
B-Tree在数据库体系结构中是根深蒂固的,并且在许多工作负载中提供良好的一致性,所以它们不可能短时间内消失掉。 在新的数据存储中,日志结构的索引变得越来越流行。并没有任何快速简单的规则来确定哪种类型的存储引擎对您的用例更好,这需要凭借自身经验和对自身业务的认知进行测试。
未完待续。。。。

以上是关于(DDIA)数据存储与检索——B-tree的主要内容,如果未能解决你的问题,请参考以下文章