一个优秀的大数据开发工程师的日常是怎么样的?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一个优秀的大数据开发工程师的日常是怎么样的?相关的知识,希望对你有一定的参考价值。
参考技术A【导读】大数据相关工作岗位很多,有大数据分析师、大数据挖掘算法工程师、大数据研发工程师、数据产品经理、大数据可视化工程师、大数据爬虫工程师、大数据运营专员、大数据架构师、大数据专家、大数据总监、大数据研究员、大数据科学家等等。下面先主要总结归纳最常见、需求量最大、最普遍的4个岗位,其他的岗位以后逐步补充,也欢迎大家一起来补充和优化

数据分析师:
工作内容:
a.临时取数分析,比如双11大促活动分析;产品的流量转化情况、产品流程优化分析,等等;
b.报表需求分析--比如企业常见的日报、周报、月报、季报、年报、产品报表、流量转化报表、经营分析报表、KPI报表等等;
c.业务专题分析:
精准营销分析(用户画像分析、营销对象分析、营销策略分析、营销效果分析);
风控分析(策略分析,反欺诈分析,信用状况分析);
市场研究分析(行业分析、竞品分析、市场分析、价格分析、渠道分析、决策分析等等);
工具和技能:
工具: R、Python、SAS、SPSS、Spark、X-Mind、Excel、PPT
技能:需掌握SQL数据库、概率统计、常用的算法模型(分类、聚类、关联、预测等,每一类模型的一两种最典型的算法)、分析报告的撰写、商业的敏感性等等;

数据挖掘工程师:
工作内容:
a.用户基础研究:用户生命周期刻画(进入、成长、成熟、衰退、流失)、用户细分模型、用户价值模型、用户活跃度模型、用户意愿度识别模型、用户偏好识别模型、用户流失预警模型、用户激活模型等
b.个性化推荐算法:基于协同过滤(USERBASE/ITEMBASE)的推荐,基于内容推荐,基于关联规则Apriot算法推荐,基于热门地区、季节、商品、人群的推荐等
c.风控模型:恶意注册模型、异地识别模型、欺诈识别模型、高危会员模型、
电商领域(炒信模型、刷单模型、职业差评师模型、虚假发货模型、反欺诈模型)
金融领域(欺诈评分模型、征信评分模型、催收模型、虚假账单识别模型等)
d.产品知识库:产品聚类分类模型、产品质量评分模型、违禁品识别模型、假货识别模型等
e.文本挖掘、语义识别、图像识别,等等
工具和技能:
工具: R、Python、SAS、SPSS、Spark、Mlib等等
技能:需掌握SQL数据库、概率统计、机器学习算法原理(分类、聚类、关联、预测、神经网络等)、模型评估、模型部署、模型监控;

数据产品经理:
工作内容:
a.大数据平台建设,让获取数据、用数据变得轻而易举;构建完善的指标体系,实现对业务的全流程监控、提高决策效率、降低运营成本、提升营收水平;
b.数据需求分析,形成数据产品,对内提升效率、控制成本,对外增加创收,最终实现数据价值变现;
c.典型的大数据产品:大数据分析平台、个性化推荐系统、精准营销系统、广告系统、征信评分系统(如芝麻评分)、会员数据服务系统(如数据纵横),等等;
工具和技能:
工具: 除了掌握数据分析工具,还需要掌握 像 原型设计工具Auxe、画结构流程的X-Mind、visio、Excel、PPT等
技能:需掌握SQL数据库、产品设计,同时,熟悉常用的数据产品框架
数据研发工程师:
工作内容:
a.大数据采集、日志爬虫、数据上报等数据获取工作
b.大数据清洗、转换、计算、存储、展现等工作
c.大数据应用开发、可视化开发、报表开发等
工具和技能:
工具:hadoop、hbase、hive、kafaka、sqoop、java、python等
技能:需掌握数据库、日志采集方法、分布式计算、实时计算等技术
综上所述,就是小编总结归纳最常见、需求量最大、最普遍的4个岗位,从工作内容,工具和技能入手来分析大数据开发工程师的日常工作是怎么样的,希望那可以帮助到大家。


23年二级建造师-新考季备考指导课
精编干货 高效通关
¥1元/科

23年一级建造师-备考资料大礼包
备考提速 精华知识点
¥1元/科

2021一级造价师-密训抢分
密训抢分冲刺
¥0元

2021一消名师100节精品课
超值体验,轻松取证
¥0元

2021年中级经济师-强化进阶体验课
知己知彼,三步破局
¥1元

2022年高级经济师-基础重塑课
基础重塑 高效备考
¥0元

2021健康管理师超值教程大礼包
教程课题一站式配齐
¥39元

四级人力资源管理师-备考指导
轻松入门人力资源师
¥0元
查
看
更
多
- 在线客服官方服务
- 官方网站精华资料免费直播课免费领课领优惠券考试日历
打怪升级之小白的大数据之旅(六十)<Hive旅程中的始发站>
打怪升级之小白的大数据之旅(六十)
Hive旅程中的始发站
引言
- 经过了前面Hadoop、MR、Java、MySQL以及Linux的洗礼,接下来我们就要进入到大数据中特别重要的一个知识点学习–Hive,Hive是我们大数据日常工作中必不可少的一个技能,基本上许多有大数据部门的公司他们雇佣的大数据工程师就是利用Hive来完成他们的日常工作…
- 既然Hive这么重要,那么我们应该怎么学好它呢?别急,跟着我一起进入Hive的旅程吧
Hive始发站—Hive的地图
- 博客已经写到了第六十期了,看过我前面博客的小伙伴应该知道我的习惯,每次介绍一个新知识之前,我总会列出一个大的框架,然后再对框架中的内容进行讲解
- 因为Hive比较重要,所以我专门在开篇梳理一下Hive的整体学习地图,带着这个地图就可以从容地在Hive中旅行啦~
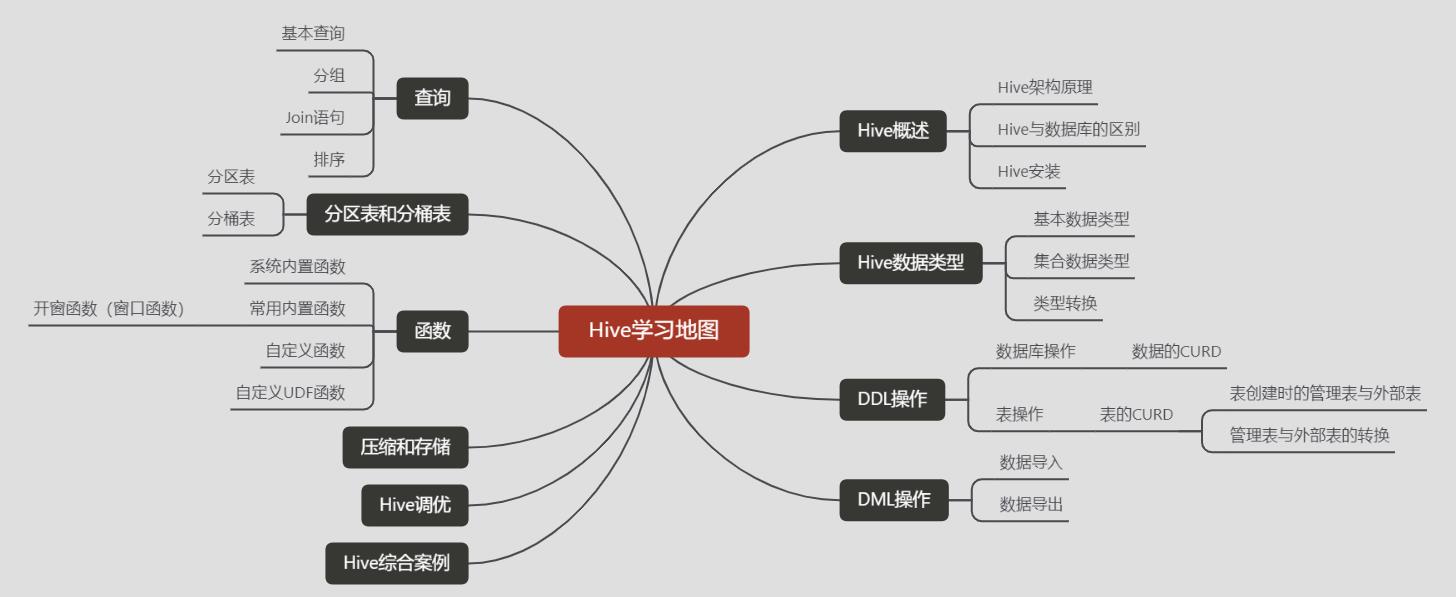
地图解释:
- Hive概述:
- 首先我们要了解Hive的基本概念,了解Hive架构原理,知道这些知识,我们就可以清晰地了解它的工作流程
- Hive安装:
- 接下来当然就是安装Hive了,因为它需要我们自己配置一些东西,所以我将它也纳入了地图之中
- Hive数据类型:
- 了解了Hive的原理以及安装好Hive,我们就要开始使用Hive了,当然,要想使用Hive,就需要了解它的数据类型
- DDL操作:
- Hive的操作就像我们操作Mysql一样,它也是通过sql来操作数据的,所以我们在操作数据前就需要知道怎么操作数据库与数据表
- DML操作:
- 学会了数据库与数据表的操作,我们就需要了解数据是如何导入、导出到Hive中的,所以我们DML操作主要就是学习数据的导入与导出
- 查询:
- Hive最重要的工作就是查询,前面的工作最终就是为了辅助我们进行这一段的旅程,查询这一块大家一定好好学习
- 分区表、分桶表:
- 因为是大数据,所以我们不可能对整个数据全部查询一遍,我们就要有分治的思想、所以我们要学习分区表和分桶表,有了它们可以更好地辅助我们进行查询
- 函数:
- 我们简单的查询当然不能满足需求,于是就需要学习高端操作–函数,让函数来解决一些查询中的疑难杂症
- 压缩和存储:
- 学习完前面的知识点,我们已经可以掌握Hive的使用了,但是为了提高工作效率,我们就需要学习一下数据的压缩和存储
- Hive调优:
- 调优就是锦上添花、画龙点睛必不可少的一部分,正如Hadoop最后的调优一样,合理的调优可以让我们飞起来~~~~
- Hive综合案例:
- 学习的最高效率就是实战、所以为了刚好的让大家吸收前面旅程中的种种风景,我为大家带来一个旅程相册集(Hive综合案例),通过综合案例可以更好的让我们查漏补缺
Hive概述
- 官方的解释是:Hive是基于Hadoop的一个数据仓库工具,可以将结构化数据文件映射为一张表,并提供类SQL的查询功能
- 一句话来形容Hive:将HQL转化为MapReduce程序
Hive架构原理
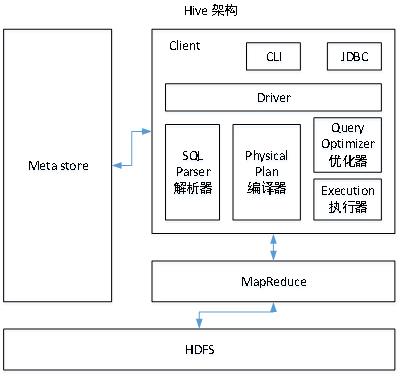
- 用户接口:Client
CLI(command-line interface)、JDBC/ODBC(jdbc访问hive)、WEBUI(浏览器访问hive) - 元数据:Metastore
- 元数据包括:表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等;
- 默认存储在自带的derby数据库中,推荐使用MySQL存储Metastore
- 因为derby同时只允许一个客户端进行访问,所以使用Mysql可以进行多客户端进行访问
- Hadoop
- 使用HDFS进行存储,使用MapReduce进行计算。
- 驱动器:Driver
(1)解析器(SQL Parser):将SQL字符串转换成抽象语法树AST,这一步一般都用第三方工具库完成,比如antlr;对AST进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误。
(2)编译器(Physical Plan):将AST编译生成逻辑执行计划。
(3)优化器(Query Optimizer):对逻辑执行计划进行优化。
(4)执行器(Execution):把逻辑执行计划转换成可以运行的物理计划。对于Hive来说,就是MR/Spark
Hive运行机制
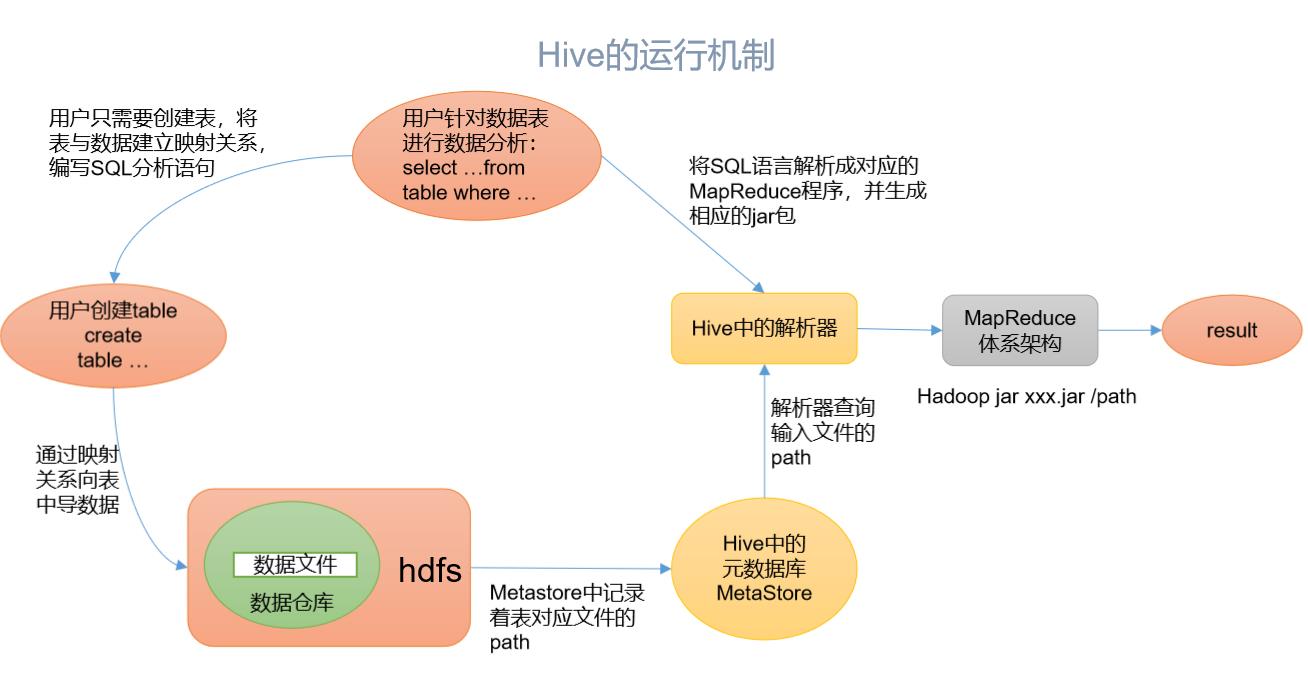
一句话总结:Hive通过给用户提供的一系列交互接口,接收到用户的指令(SQL),使用自己的Driver,结合元数据(MetaStore),将这些指令翻译成MapReduce,提交到Hadoop中执行,最后,将执行返回的结果输出到用户交互接口
Hive执行流程
上面介绍了Hive运行机制,接下来我来介绍一下客户端是如何操作Hive获取所需数据的
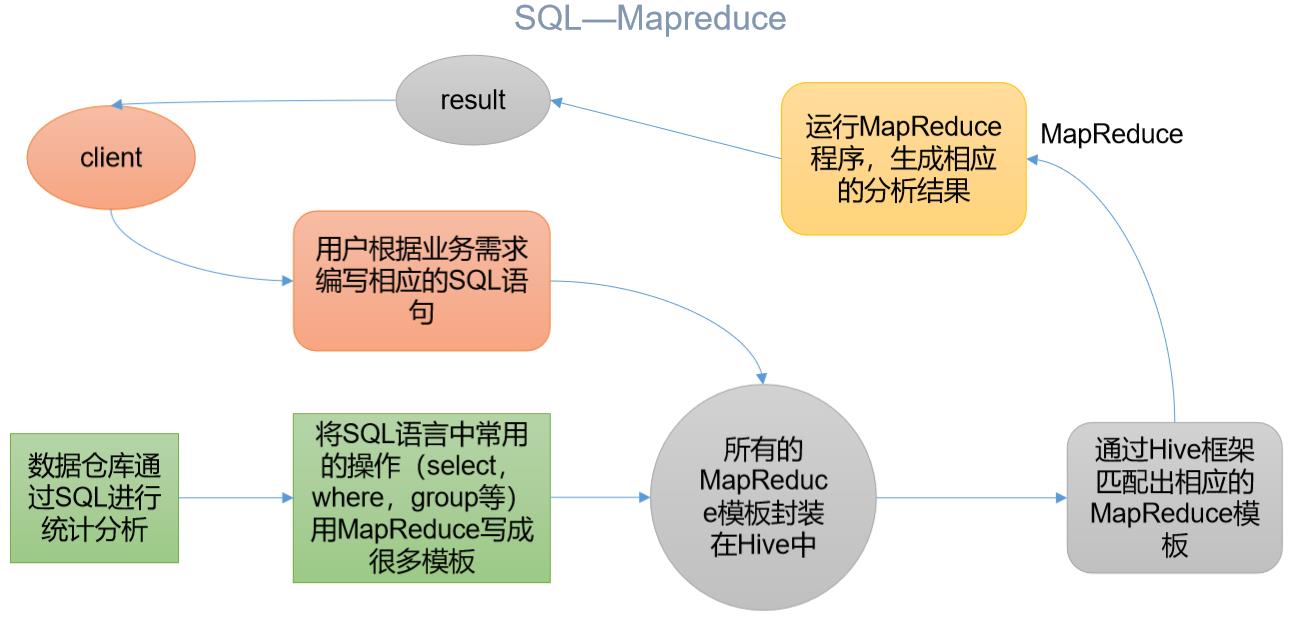
- 客户端通过CLI或者JDBC连接Hive后,根据业务来编写HQL语句
- 在Hive内部,封装了许多的MapReduce模板,这些模板用来实现SQL语言中的操作
- 当Hive接收到HQL语句后,会通过MetaStore和内部匹配相对应的MapReduce模板来执行对应的MapReduce程序
- 运行完成后,将结果返回给客户端
Hive优缺点
Hive的优点
- 操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手)。
- 避免了去写MapReduce,减少开发人员的学习成本。
- Hive优势在于处理大数据,支持海量数据的分析与计算。
- Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
Hive的缺点
- Hive的HQL表达能力有限
- Hive自动生成的MapReduce作业,通常情况下不够智能化
- 数据挖掘方面不擅长,由于MapReduce数据处理流程的限制,效率更高的算法却无法实现。
- Hive的效率比较低
- Hive的执行延迟比较高,因此Hive常用于数据分析,对实时性要求不高的场合。
- Hive调优比较困难,粒度较粗
- Hive不支持实时查询和行级别更新
- hive分析的数据是存储在hdfs上,hdfs不支持随机写,只支持追加写,所以在hive中不能delete和update,只能select和insert
Hive和数据库比较
- 首先我们要知道数据仓库和数据的区别:
- 数据库仓库指的是一堆的数据库,它用于存储海量的数据,而数据库我们将它理解为一个用于存放数据的柜子
- 知道了数据仓库与数据库的区别,Hive和数据的区别就显而易见了,它们最大的区别就是数据规模,数据库支持的数据规模相对较小,而Hive建立在Hadoop集群上,所以Hive可以支持很大的数据规模
- 既然数据规模不同,那么它们的执行效率必然有所区别
- 因为Hive是通过Hadoop集群,并且它实际是执行MapReduce程序,所以它在执行执行规模小的数据时,会比较慢,而数据库因为有索引,索引它的速度会很快
- 因为执行慢,并且数据规模大,所以当我们将数据存储到HDFS中后一般就不再进行修改更新了,因此Hive的数据更新一般来说不建议使用,如果非要进行数据改写,可以从HDFS上下载数据,修改后再上传,而数据库因为数据规模小并且数据更新频率高,所以它会经常进行数据更新的操作
Hive的升级之路
为了更好的熟练学习掌握Hive,我将LeetCode中的HQL的练习题放到了github中,大家有需要的可以自行下载:https://github.com/GaryLea/BigDataTools
还有下面这两个网址中:
- 牛客sql实战 https://www.nowcoder.com/ta/sql
- Hive SQL50道练习题 https://mp.weixin.qq.com/s/k2VORfLxiu8wwQyHMaw_NA
- 注意一下:微信里这个它有一个BUG,它里面的原数据和表的定义是错误的,数据是空格分开,而表的定义是
/t,大家自己改一下哈(这个知识点我会在DDL操作里讲)
总结
本章是Hive旅程的始发站,我们学习一个知识点之前就需要了解整个框架才可以了然于胸的进行学习,因此本章节主要是对Hive的一些介绍,Hive是大数据中我认为很重要的一个技能,大家要尽量多练习Hive中的HQL习题
以上是关于一个优秀的大数据开发工程师的日常是怎么样的?的主要内容,如果未能解决你的问题,请参考以下文章
打怪升级之小白的大数据之旅(六十)<Hive旅程中的始发站>