卷积神经网络(Convolutional Neural Network) 简介
Posted Babyface Killer
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了卷积神经网络(Convolutional Neural Network) 简介相关的知识,希望对你有一定的参考价值。
卷积神经网络与普通神经网络有哪些不同
对于图像类的数据来说,使用全连接的普通神经网络其需要的权重数量会显著受输入的图像大小影响。举例说明,一个128x128的彩色图片其输入值的维度为128x128x3,假设隐藏层有十个神经元,其需要的变量数就为128x128x3x10+10=491530个,如果使用更多神经元和更多隐藏层,变量的维度很快就会爆炸。而使用过多的自由度(Degree of freedom)会导致过拟合,但这还只是全连接神经网络处理图像数据的其中一个问题。试想如果使用全连接神经网络,每个像素对应为一个数值,即使我们使用全连接神经网络克服了过拟合的问题,但如果我们需要识别的图片中的目标物出现在了图片的不同位置,而该位置不曾在训练集中出现过,那么这个神经网络模型是无法识别这个目标物的。而使用目标物出现在所有位置的图片做为训练集又不现实,那么就只好使用别的办法来处理输入的图片数据使其拥有位移不变性(shift invariance),而这个办法就是卷积层(convolutional layer)。
卷积层(Convolutional Layer)
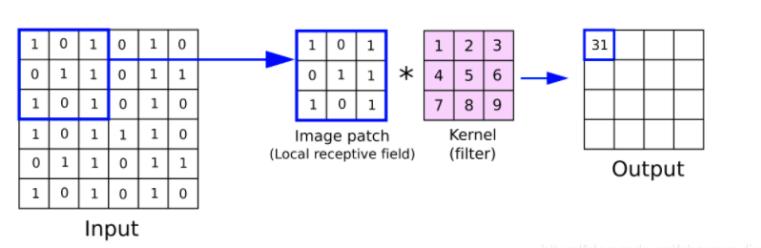
如前面所提到的,卷积层主要的工作就是降低模型需要的变量数,以及为输入的数据提供位移不变性。卷积层的工作原理就是找到P个不同的Filter,拿着每个Filter在原始的输入数据上平移,计算对应矩阵元素之间乘积的和就是对应位置的输出数据。每次平移一个单位Stride就为1,平移两个单位Stride就为2,以此类推。每个不同的Filter都对应会找到原始输入数据中不同的特征。仔细观察上图可以发现当Filter移动到输入矩阵最右边时似乎再往右移动就会缺少一列用来计算的数据,如果因此就放弃这些角落的数据,那么每一次使用卷积层都会导致输出数据比输入数据的维度小一些从而可能丢失一些重要信息。为了解决这个问题,我们可以在输入数据周围补上一圈0值,这样Filter在移动的时候就可以掠过每一个输入数据而输出数据又不会受到补值的影响。那么卷积层是如何解决我之前提到的两个问题的呢?首先,对于卷积层我们通常可以使用参数共享假设(parameter sharing)即对于同一个输入数据使用Filter来进行卷积操作时我们可以使用同一个Filter而不需要每平移一次就变化一次Filter。直观来说就是我们假设一个Filter在图片的局部有识别特征的能力那么这个能力就可以泛化到其他部分。这样一来,对于每一个nxn的Filter来说,我们需要的变量就降为nxn,而使用P个Filter,整个卷积层需要的变量数就为(nxnxp+p),相比于全连接神经网络,需要的变量数显著下降。同时变量数也不再与输入数据的大小挂钩,而是与需要识别的特征数相关,这同时也更符合我们的常识。但是需要注意的是并不是所有输入数据都满足参数共享的假设条件,如对于人脸识别任务,目标物多集中在图像中央,而人脸五官也具有不同特征,在这种情况下使用相同的Filter就不是一个好的选择。除了显著降低需要的参数量外,可以观察到使用卷积操作时输出值与输入值存在着同时平移的性质,也就是说输出值不再与输入值的绝对位置相关,而是根据输入值的移动而移动,这就满足了我们之前提到的位移不变性(shift invariance)。
池化层(Pooling Layer)
池化层的目的是进一步缩小最后用来做预测的数据的维度,其主要的工作原理为找到每个局部区域的最大值(max pooling)并只保留该最大值,经过池化层后数据维度进一步缩小,需要的变量数也随之而缩小,从而更加有效的防止过拟合。和卷积层类似,池化层也需要使用一个Filter,使用这个Filter在输入数据上平移找到每个区域的最大值。与之前不同的是,池化层需要的Filter数量一定和卷积层的Filter数量是相同的,也就是对于每一个经过卷积层制造出来的数据会再经过池化层来降低维度。池化层的使用方法不止有max pooling,还有average pooling和l2 norm pooling等不同的方法,但在实践中max pooling是最为常用的方法。
卷积神经网络结构
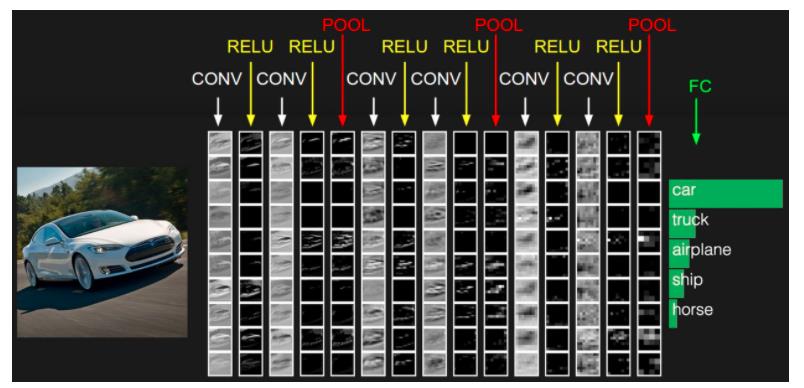
通过这张图片我们可以从整体上观察到卷积神经网络的基本结构,输入数据每经过一次卷积层后会经过一个激活层,这个激活层和普通的神经网络的激活层作用是相似的,也就是使神经网络拥有更强的表达能力,而在卷积层之间会穿插一些池化层来降低数据的维度。最后最关键的一步就是输出层的全连接层。通过之前对输入数据的处理,在最后一层池化层我们可以得到一个类似于向量的数据。可以试想一下,若输入数据为一张128x128x3的图片,在卷积层我们使用100个Filter来对输入数据进行卷积操作,而在池化层我们每次把输入数据在横向和纵向上缩小一倍,经过四次重复操作之后,我们就得到了一个4x4x100的数据,这也就是我之前提到的类似于向量的数据。而对于分类问题,这样的数据的处理方法就和普通的全连接神经网络相似了,如果是多分类问题,直接把数据输入到激活函数为softmax的输出层就可以得到模型的预测结果。完成了这一步之后,整个卷积神经网络的工作也就完成了。总结一下,卷积神经网络的基本结构为:INPUT–>[[CONV–>RELU]xN–>POOL?]xM–>[FC–>ACTIVATION]xK–>OUTPUT
参考文章
https://cs231n.github.io/convolutional-networks/
Other Resources
斯坦福大学卷积神经网络可视化网站,对于理解卷积神经网络非常有帮助
https://cs.stanford.edu/people/karpathy/convnetjs/demo/cifar10.html
以上是关于卷积神经网络(Convolutional Neural Network) 简介的主要内容,如果未能解决你的问题,请参考以下文章