CPU Cache 一致性:Cache 结构同步方式Cache 一致性总线嗅探MESI 协议
Posted 凌桓丶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CPU Cache 一致性:Cache 结构同步方式Cache 一致性总线嗅探MESI 协议相关的知识,希望对你有一定的参考价值。
文章目录
CPU Cache 一致性
CPU Cache 结构
随着时间的推移,CPU 和内存的访问性能相差越来越大,为了弥补 CPU 与内存两者之间的性能差异,就在 CPU 内部引入了 CPU Cache,也称高速缓存。
CPU Cache 通常分为大小不等的三级缓存,分别是 L1 Cache、L2 Cache 和 L3 Cache。
- L1 Cache:
L1 Cache的访问速度几乎和寄存器一样快,通常在2~4 个时钟周期,而大小在几十 KB 到几百 KB 不等。每个 CPU 核心都有一块属于自己的L1 Cache,并且指令和数据在 L1 是分开存放的,所以L1 Cache通常分成指令缓存和数据缓存。 - L2 Cache:
L2 Cache同样每个 CPU 核心都有,但是L2 Cache的大小比L1 Cache更大,通常在几百KB到几MB不等,访问速度则更慢,速度在 10~20 个时钟周期 - L3 Cache:
L3 Cache通常是多个 CPU 核心共用的,大小比起L2 Cache也会更大些,通常在几 MB 到几十 MB不等,访问速度相对也比较慢一些,通常在 20~60 个时钟周期。
它们之间的层级关系如下图:
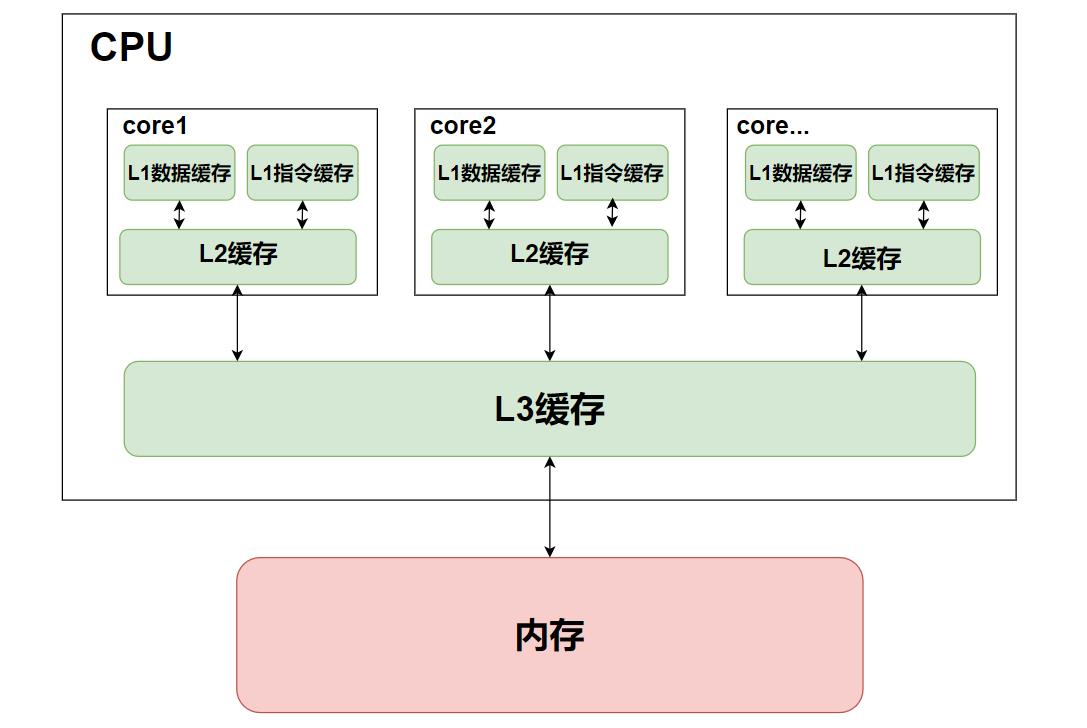
介绍完了 CPU Cache 的层级关系后,再来聊聊它的构成。CPU Cache 其实是由多个 Cache Line 组成的,而 Cache Line 其实就是 CPU 从内存读取数据的基本单位,由 Tag(标志)和 Data Block(数据块)组成。
Cache 同步方式
当我们把数据写入 Cache 之后,必然会引起内存与 Cache 的数据不一致,此时我们就需要将数据同步回内存来确保数据的一致性。
通常我们会采用 Write Through(直写) 和 Write Back(写回) 两种方法。
Write Through(直写)
保证一致性最简单的一种方式,就是直写——把数据同时写入Cache和内存中。
具体流程如下图:

这个方法虽然简单,但是在我们每次写数据时都需要将数据写入到内存中,由于内存 io 的性能比起 Cache 差了很多,因此性能非常不理想。
Write Back(写回)
从上面可以看出,直写最大的缺点就在于其每次都要将数据写入内存,导致性能不佳。为了减少写入内存的次数,此时又引入了写回——当CPU执行写操作时,数据不会立即写入内存,而是写入到Cache Block里,只有当Cache Block被替换出Cache时才会将其写入内存。其执行流程如下图:
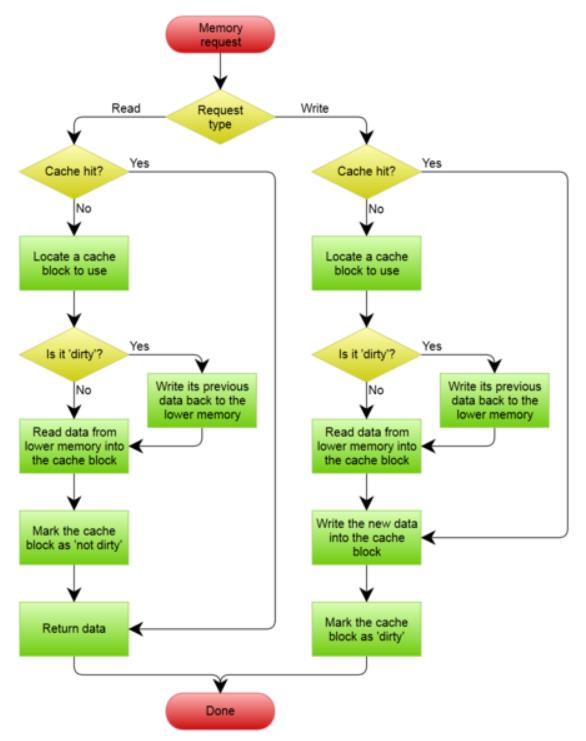
写回的流程比起直写要复杂许多,下面就简要说明几个地方。
- 当命中缓存时,只需要将数据更新到
cache block中,并将其标记为脏,此时不需要写入内存。 - 当未命中缓存时,分配一个合适的
cache block,如果当前cache block为脏,则说明此时其之前的数据与内存不一致,将之前的数据写入内存中。如果不为脏,并将新数据写入到该cache block中,之后再将该cache block标记为脏。
Cache一致性问题
一致性问题
由于L1/L2 Cache都是每个core独有的,当我们在多核机器上运行程序时,就必须要考虑Cache一致性的问题。
下面以一个2核的机器举例子,假设两个core同时运行着两个不同的线程,此时它们都在操作变量i:
- 线程1执行
i++,此时考虑到性能其使用的是写回的策略,在修改后仅将Cache标记为脏而没有写回内存中。 - 此时线程2读取内存,其读取到的则是
i++执行之前的旧数据,此时就出现了Cache数据不一致的问题。
如果要想确保多个core中的cache的数据能够一致,就必须要实现以下两点
- 写传播:某个core里的cache数据更新时,必须要传播到其他core的cache中,确保数据一致。
- 事务串行化:某个core里对数据执行的操作,在其他core看起来必须是顺序一样的。
写传播即同步修改的数据,这个很容易就可以理解,但是为什么要保证事务串行化呢?下面我举一个例子:
-
假设当前的机器为四核,它们同时操作变量i,此时core1将变量的值修改为5,core2同时将变量的值修改为10。
-
此时这两个修改都会同步到core3和core4中,如果不保证传播的顺序性,此时就会出现问题
-
如果core3先执行core1在执行core2的同步,此时它最终的结果是10
-
如果core4先执行core2的同步在执行core1,此时它的结果是5。这时候就出现cache不一致的情况了。
因此,为了确保数据一致性,我们就必须要让core3和core4看到相同的顺序变化,执行相同的同步逻辑,这也就是事务串行化的主要工作。
如果要想实现事务的串行化,就必须要实现以下内容
- CPU core对于Cache中数据的写操作,需要传播给其他CPU core;
- 如果两个 CPU 核心里有相同数据的 Cache,那么对于这个 Cache 数据的更新,只有拿到了「锁」,才能进行对应的数据更新(确保顺序执行)。
而总线嗅探和MESI协议,刚好满足我们的需求。
总线嗅探
要想实现写传播,最常见的方法就是总线嗅探——所有core时刻监听总线上的一切活动,一旦有某个core执行了写操作,此时其就会通过总线将该事件广播给所有core,每个core接收到后就会检查自己的L1 Cache中是否有数据,如果有则将数据更新过来,确保数据同步。
不难看出,总线嗅探只保证了某个core中cache的数据更新能被其他core感知到,但并没有办法保证事务的串行化。于是为了实现事务的串行化,降低总线的带宽压力,大佬们基于状态机和总线嗅探实现了MESI协议。
MESI协议
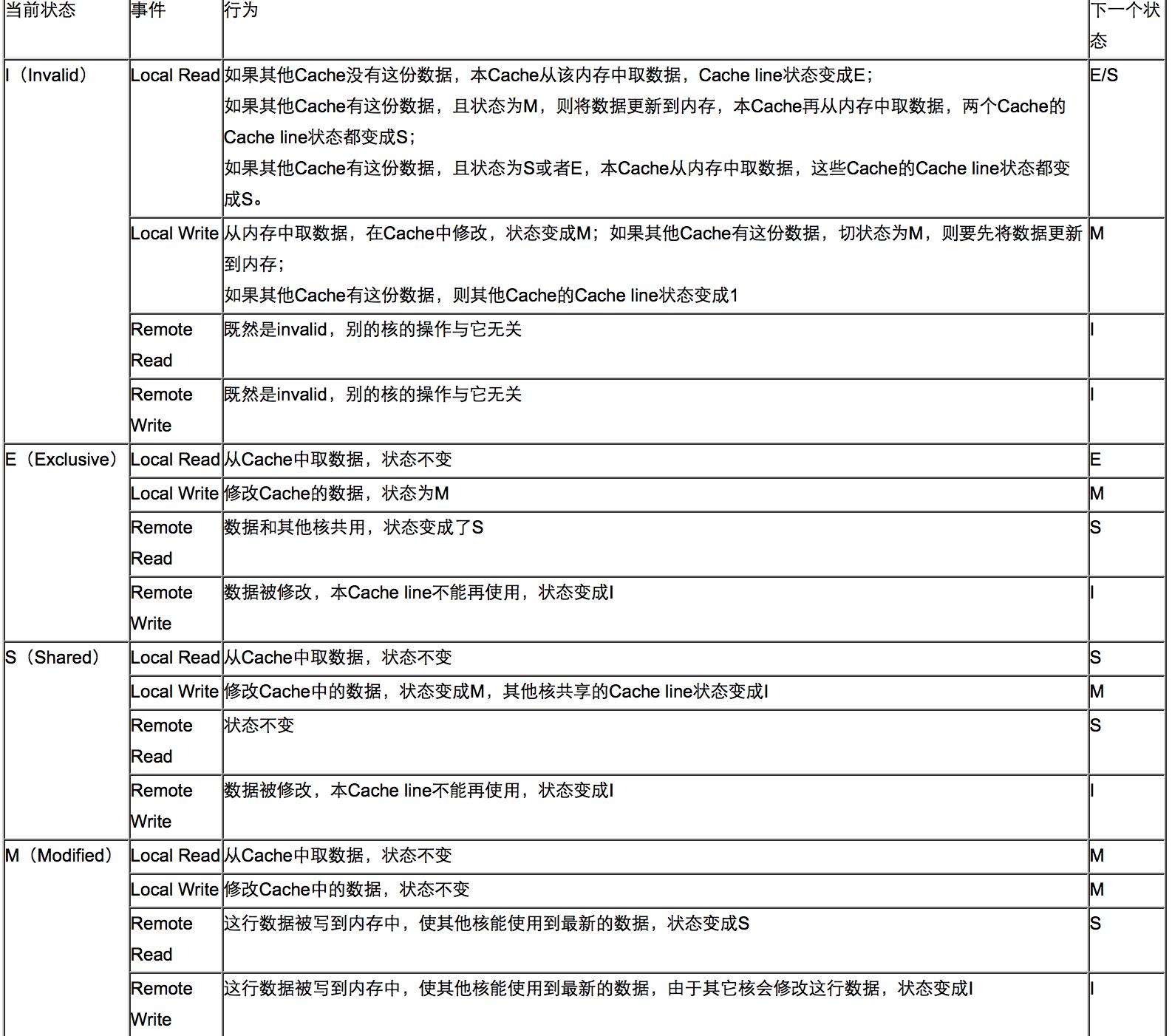
MESI协议是基于Invalidate的高速缓存一致性协议,并且是支持回写高速缓存的最常用协议之一。其主要包含以下四种状态:
- Modified(已修改):该数据只存在当前core的Cache中,但是数据已经被修改,此时
Cache Block的数据有效但与内存中不一致。 - Exclusive(独占):该数据只存在当前core的Cache中,且
Cache Block的数据有效且与内存中保持一致。 - Shared(共享):该数据存在多个core的Cache中,且
Cache Block的数据有效且与内存中保持一致。 - Invalidated(已失效):该数据无效。
为了方便理解,下面举一个例子来说明状态之间转移的过程,假设我们的CPU有2个core
- 1号core从内存中读取数据,此时数据缓存到1号core的cache中,此时其为独占状态。
- 2号core从内存中读取数据,缓存到自己的cache中,由于已经有其他core也缓存了该数据,此时其为共享状态。
- 当1号core对数据进行修改时,此时由于状态是共享,它首先会向所有core广播一个请求,让其他缓存该数据的cache将状态修改为已失效,之后再进行数据修改,修改后将状态置为已修改。
- 由于修改后的数据只有当前一个core独占,因此我们对已修改状态的数据再次修改,不会影响其他core,直接修改数据即可。
- 当我们cache满了之后,需要替换新的数据进来,此时就会将被替换的已修改状态的数据写入内存中,确保修改生效。
具体的状态转移过程可以参考下面的图表

以上是关于CPU Cache 一致性:Cache 结构同步方式Cache 一致性总线嗅探MESI 协议的主要内容,如果未能解决你的问题,请参考以下文章