C#.NETPower BI数据挖掘
Posted 擅长死循环
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了C#.NETPower BI数据挖掘相关的知识,希望对你有一定的参考价值。
阅读目录
第一次接触htmlAgilityPack是在5年前,一些意外,让我从技术部门临时调到销售部门,负责建立一些流程和寻找潜在客户,最后在阿里巴巴找到了很多客户信息,非常全面,刚开始是手动复制到Excel,是真尼玛的累,虽然那个时候C#还很菜,也想能不能通过程序来批量获取(所以平时想法要多才好)。几经周折,终于发现了HtmlAgilityPack神器,这几年也用HtmlAgilityPack采集了很多类型数据,特别是足球赛事资料库的数据采集以及天气数据采集,都是使用HtmlAgilityPack,所以把自己的使用过程总结下来,分享给大家,让更多人接触和学会使用,给自己的工作带来遍历。
今天的主要内容是HtmlAgilityPack的基本介绍、使用,实际代码。最后我们以采集天气数据为例子,来介绍实际的采集分析过程和简单的代码。我们将在下一篇文章中开源该天气数据库和C#操作代码。采集核心就只是在这里介绍,其实核心代码都有了,自己加工下就可以了,同时也免费对有需要的人开放。至于具体详情,请关注下一篇文章。
.NET开源目录:【目录】本博客其他.NET开源项目文章目录
本文原文地址:C#+HtmlAgilityPack+XPath带你采集数据(以采集天气数据为例子)
1.HtmlAgilityPack简介
HtmlAgilityPack是一个开源的解析HTML元素的类库,最大的特点是可以通过XPath来解析HMTL,如果您以前用C#操作过XML,那么使用起HtmlAgilityPack也会得心应手。目前最新版本为1.4.6,下载地址如下:http://htmlagilitypack.codeplex.com/ 目前稳定的版本是1.4.6,上一次更新还是2012年,所以很稳定,基本功能全面,也没必要更新了。
提到HtmlAgilityPack,就必须要介绍一个辅助工具,不知道其他人在使用的时候,是如何分析页面结构的。反正我是使用官方提供的一个叫做HAPExplorer的工具。非常有用。下面我们在使用的时候会介绍如何使用。
2.XPath技术介绍与使用
2.1 XPath介绍
XPath即为XML路径语言,它是一种用来确定XML(标准通用标记语言的子集)文档中某部分位置的语言。XPath基于XML的树状结构,提供在数据结构树中找寻节点的能力。起初 XPath 的提出的初衷是将其作为一个通用的、介于XPointer与XSL间的语法模型。但是 XPath 很快的被开发者采用来当作小型查询语言。
XPath是W3C的一个标准。它最主要的目的是为了在XML1.0或XML1.1文档节点树中定位节点所设计。目前有XPath1.0和XPath2.0两个版本。其中Xpath1.0是1999年成为W3C标准,而XPath2.0标准的确立是在2007年。W3C关于XPath的英文详细文档请见:http://www.w3.org/TR/xpath20/ 。
2.2 XPath的路径表达
XPath是XML的查询语言,和SQL的角色很类似。以下面XML为例,介绍XPath的语法。下面的一些资料是几年前学习这个的时候,从网络以及博客园获取的一些资料,暂时找不到出处,例子和文字基本都是借鉴,再次谢过。如果大家发现类似的一起文章,告诉我链接,我加上引用。下面的Xpath的相关表达也很基础,基本足够用了。

<?xml version="1.0"encoding="ISO-8859-1"?> <catalog> <cd country="USA"> <title>Empire Burlesque</title> <artist>Bob Dylan</artist> <price>10.90</price> </cd> </catalog>
定位节点:XML是树状结构,类似档案系统内数据夹的结构,XPath也类似档案系统的路径命名方式。不过XPath是一种模式(Pattern),可以选出XML档案中,路径符合某个模式的所有节点出来。例如要选catalog底下的cd中所有price元素可以用:
/catalog/cd/price
如果XPath的开头是一个斜线(/)代表这是绝对路径。如果开头是两个斜线(//)表示文件中所有符合模式的元素都会被选出来,即使是处于树中不同的层级也会被选出来。以下的语法会选出文件中所有叫做cd的元素(在树中的任何层级都会被选出来)://cd
选择未知的元素:使用星号(*)可以选择未知的元素。下面这个语法会选出/catalog/cd的所有子元素:
/catalog/cd/*
以下的语法会选出所有catalog的子元素中,包含有price作为子元素的元素。
/catalog/*/price
以下的语法会选出有两层父节点,叫做price的所有元素。
/*/*/price
要注意的是,想要存取不分层级的元素,XPath语法必须以两个斜线开头(//),想要存取未知元素才用星号(*),星号只能代表未知名称的元素,不能代表未知层级的元素。
选择分支:使用中括号可以选择分支。以下的语法从catalog的子元素中取出第一个叫做cd的元素。XPath的定义中没有第0元素这种东西。
/catalog/cd[1]
以下语法选择catalog中的最后一个cd元素:(XPathj并没有定义first()这种函式喔,用上例的[1]就可以取出第一个元素。
/catalog/cd[last()]
以下语法选出price元素的值等于10.90的所有/catalog/cd元素
/catalog/cd[price=10.90]
选择属性:在XPath中,除了选择元素以外,也可以选择属性。属性都是以@开头。例如选择文件中所有叫做country的属性:
//@country
以下语法选择出country属性值为UK的cd元素
//cd[@country='UK']
3.采集天气网站案例
3.1 需求分析
我们要采集的是全国各地城市的天气信息,网站为:http://www.tianqihoubao.com/,该网站数据分为2种类型,1个是历史数据,覆盖范围为2011年至今,1个是天气预报的数据,历史数据是天气后报,也就是实际的天气数据。采集的范围必须覆盖全国主要城市,最好是所有的城市。通过分析该网站的页面,的确是满足要求。天气信息,包括实际的天气状况,风力状况以及气温状况情况,包括最低和最高区间。
结合基本要求,我们进入网站,分析一些大概特点,以及主要页面的结构。
3.2 网站页面结构分析
要采集大量的信息,必须对网站页面进行详细的分析和总结。因为机器采集不是人工,需要动态构造URL,请求或者页面html,然后进行解析。所以分析网站页面结构是第一步,也是很关键的一步。我们首先进入到总的历史页面:http://www.tianqihoubao.com/lishi/,如下图:
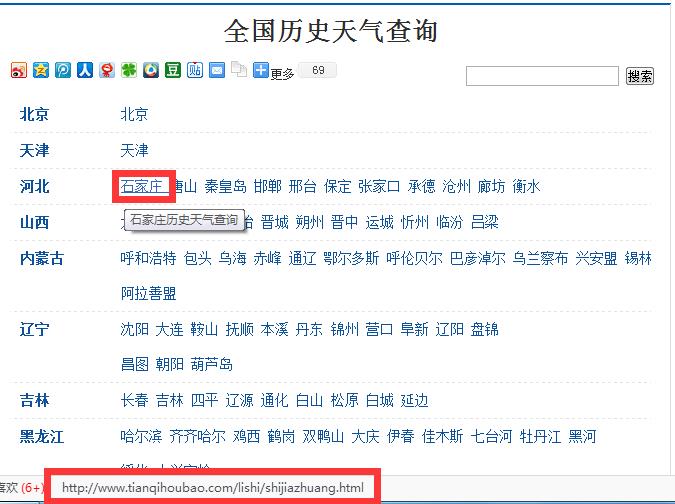
很明显,这个总的页面按省份进行了分开,可以看到每个省份、地级市名称的链接中,都是固定格式,只不过拼音缩写不同而已。而且每个省份的第一个城市为省会城市。这一点要注意,程序中要区分省会城市和其他地级城市。当然省会城市也可以省略,毕竟只有30多个,手动标记也很快的事情。这个页面我们将主要采集省份的缩写信息,然后我们选择一个省份,点击进去,看每个省份具体的城市信息,如我们选择辽宁省:http://www.tianqihoubao.com/lishi/ln.htm如下图:

同样,每个省份下面的地区也有单独的链接,格式和上面的类似,按照城市拼音。我们看到每个省份下面,有大的地级行政区,每个地级市区后面细分了小的县市区。我们随意点击大连市的链接,进去看看具体的天气历史信息:

该页面包括了城市2011年1月到2015年至今的历史数据,按月分开。链接的特点也很固定,包括了城市名称的拼音和年份月份信息。所以构造这个链接就很容易了。下面看看每个月份的情况:
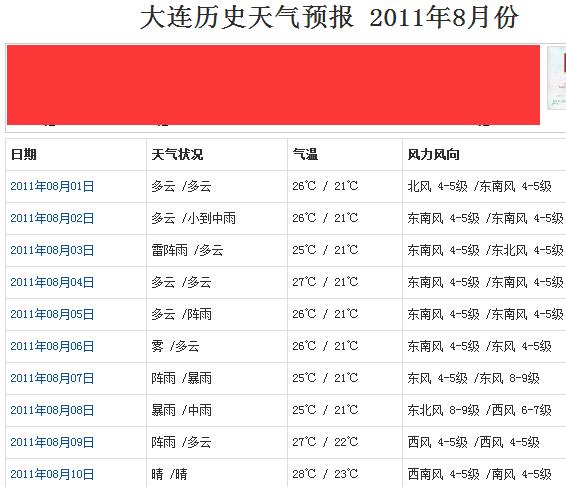
广告我屏蔽了一些,手动给抹掉吧。每个城市的每个月的天气信息比较简单,直接表格填充了数据,日期,天气状况,气温和风力。这几步都是按照页面的链接一步一步引导过来的,所以上述流程清楚了,要采集的信息也清楚了,有了大概的思路:
先采集整个省份的拼音代码,然后依次获取每个省份每个地级市,以及对应县级市的名称和拼音代码,最后循环每个县级市,按照月份获取所有历史数据。下面将重点分析几个页面的节点情况,就是如何用HtmlAgilityPack和Xpath来获取你要的数据信息,至于保存到数据库,八仙过海各显神通吧,我用的是XCode组件。
3.3 分析省-县市结构页面
还是以辽宁省为例:http://www.tianqihoubao.com/lishi/ln.htm ,打开页面,右键获取网页源代码后,粘贴到 HAPExplorer 中,也可以直接在HAPExplorer 中打开链接,如下面的动画演示:

我们可以看到,右侧的XPath地址,div结束后,下面都是dl标签,就是我们要采集的行了。下面我们用代码来获取上述结构。先看看获取页面源代码的代码:
| 1 2 3 4 5 6 7 8 9 10 |
|
下面是分析每个省份下属县市区的程序,限于篇幅我们省掉了数据库部分,只采集城市和拼音代码,并输出:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
|
我们以辽宁为例,调用代码:ParsePageByArea("ln");结果如下:

3.4 分析城市单月的历史天气页面
这也是最重要核心的一个要分析的页面。我们以大连市2011年8月份为例:http://www.tianqihoubao.com/lishi/dalian/month/201108.html,我们要找到我们需要采集的信息节点,如下图所示的动画演示,其实这个过程习惯几次就好了,每一次点击节点后,要观察右边的内容是不是我们想要的,还可以通过滚动条的长度判断大概的长度。

这里不是直接从URL加载,由于编码原因,URL加载会有乱码,所以我是手动辅助源代码到HAPExplorer中的,效果一样,所以直接在获取页面源代码的时候,要注意编码问题。总的过程比较简单,还是查找到Table标签的位置,因为那里保存了所需要的数据,每一行每一列都非常标准。过程类似,我们直接更加XPath找到Table,然后一次获取每行,每列,进行对应即可,看代码,都进行了详细的注释:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
|
我们调用大连市2011年8月的记录:ParsePageByCityMonth("dalian",2011,8); 结果如下:
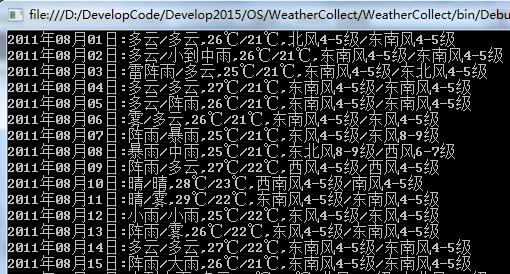
至于其他页面都是这个思路,先分析xpath,再获取对应的信息。熟悉几次后应该会快很多的。HtmlAgilityPack里面的方法用多了,自己用对象浏览器查看一些,会一些基本的就可以解决很多问题。
另外,很多网页都是直接输出json数据,对json数据的处理我写过一篇文章,可以参考下,纯手工打造的解析json:用原始方法解析复杂字符串,json一定要用JsonMapper么?
4.资源
网易新闻页面信息抓取 -- htmlagilitypack搭配scrapysharp
C#类似Jquery的html解析类HtmlAgilityPack基础类介绍及运用
我把分析HAPExplorer 工具共享一些吧,这里下载:HtmlAgilityPack分析工具.rar
我将在下一篇文章中开放这个天气数据库,目前正在采集,很大,很慢。敬请关注。
以上是关于C#.NETPower BI数据挖掘的主要内容,如果未能解决你的问题,请参考以下文章