K2 编译器是什么?世界第二高峰又是哪座?
Posted bug樱樱
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了K2 编译器是什么?世界第二高峰又是哪座?相关的知识,希望对你有一定的参考价值。
作者:程序员江同学
链接:https://juejin.cn/post/7143207967775522823
前言
众所周知,Kotlin团队正在开发新版Kotlin编译器,并命名为K2。那么K2又是什么意思呢?难道是Kotlin第二版编译器的意思?
其实K2指的是乔戈里峰,海拔8611米,仅次于珠穆朗玛峰,为世界第二高峰。登山者通常称乔戈里峰为K2,它虽然海拔排名第二,但因位置偏远及山势陡峭,乔戈里峰通常被认为是最难攀登的8000米以上高峰之一。Kotlin团队通过K2这个名字表示编译器重构工作的难度。
好了,没用的冷知识又增加了,在了解了世界第二高峰是哪座之后,我们一起来看下K2编译器是什么?与老版本编译器有什么区别?
本文主要是学习《K2编译器之路》视频的输出,感兴趣的同学可以直接查看视频,链接在文末
Kotlin编译器总体介绍
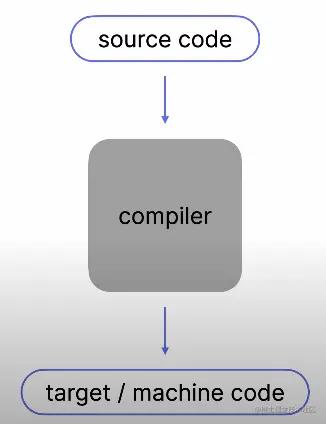
如上图所示,我们可以认为编译器是一个黑箱,它的输入就是源代码,输出则是机器码或者目标代码。
源代码是人类编写的,通常使用高级语言编写,比如java或者kotlin,对于人类来说,易于阅读,理解和修改
机器码则是一系列供机器执行的指令,通常是自动生成的,对于人类来说难以理解,但是对于机器来说却易于理解
当然机器码也是可以手写的,远古时代的程序员就是这样工作的。但是就算是远古程序员,使用机器码开发也不是那么简单,因此程序也难以扩展到复杂的级别。正是因为这个原因,出现了一系列的高级语言与编译器,显著简化了编程体验
编译器的作用就是将源代码输出为机器码或者目标代码
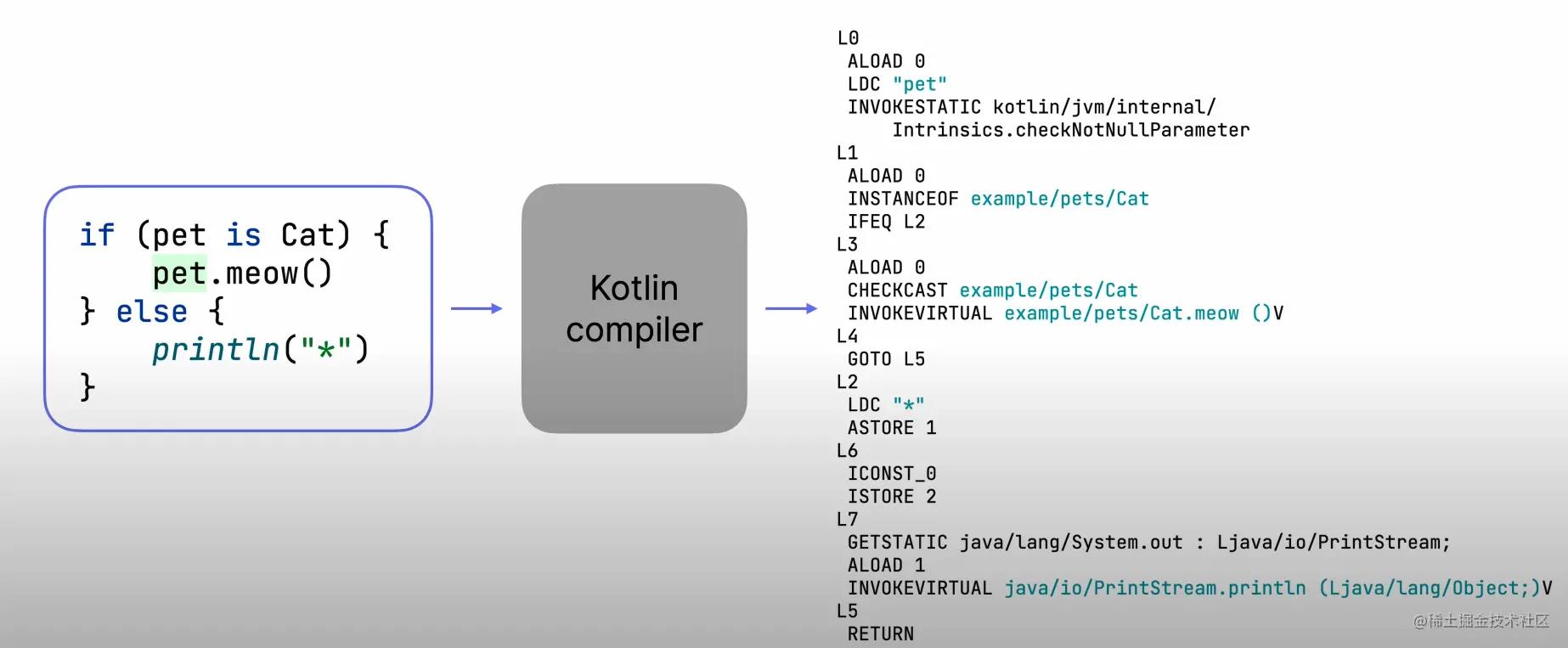
如上所示,Kotin编译器可以将Kotlin代码编译成jvm字节码,除此之外,Kotlin编译器也可以将Kotlin代码编译成javascript或者llvm bitcode

总得来说,Kotlin编译器目前有3个目标平台,jvm,javascript,native,它们都有着不同的格式,因此需要将源代码编译成三种目标产物
Kotlin编译器的具体结构
前端与后端
编译器通常可以划分为前端和后端两部分,如下图所示:
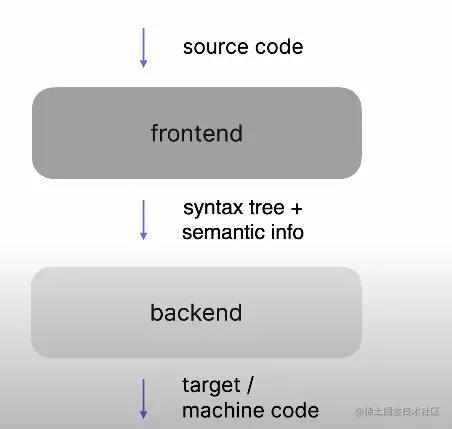
当然看到前端与后端你可能会跟业务开发上的前后端产生一定的混淆,但编译器前后端是与之完全不同的概念
- 编译器前端:作用是构建抽象语法树和语义信息
- 编译器后端:作用是生成机器码或者目标代码
在著名的编译原理龙书中,对编译器前端与后端做了进一步的划分
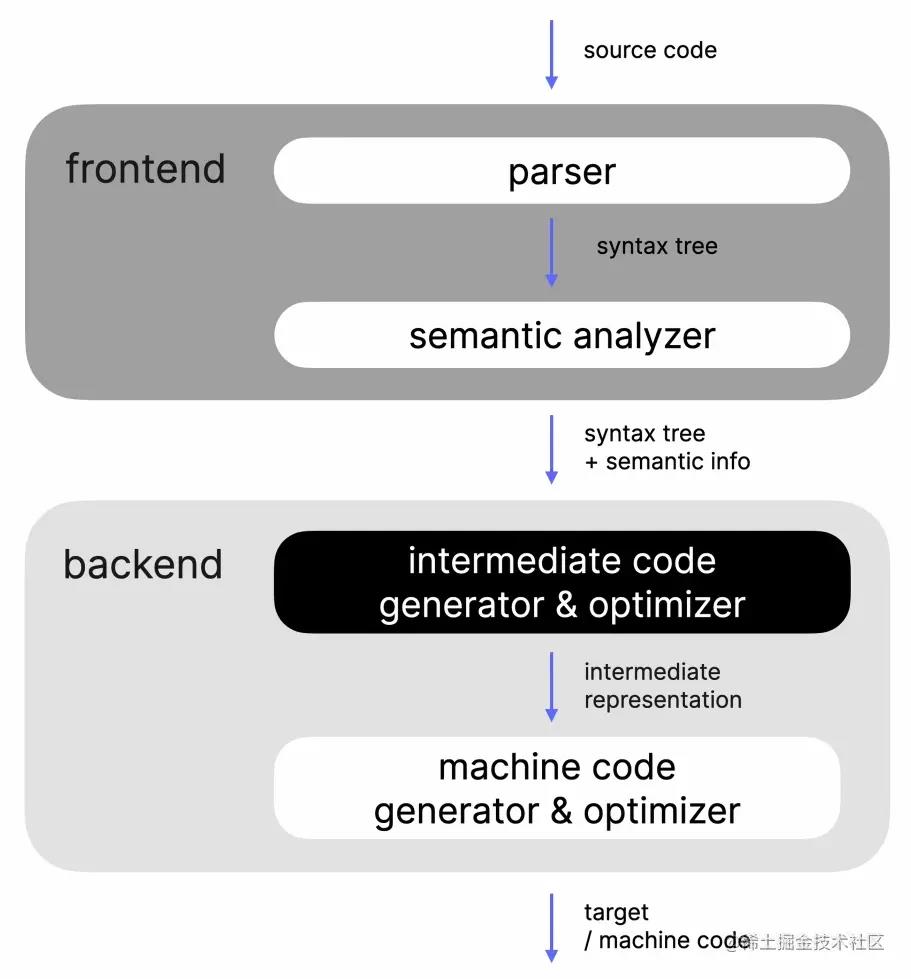
- 编译器前端被划分为语法解析器(
parser)和语义分析器 - 编译器后端被划分为中间代码生成器和机器代码生成器,其中中间代码生成器是可选的,没有这个阶段也可以实现编译器,中间代码生成器的产物就是
IR
语法解析器

语法解析器以源代码作为输入,输出抽象语法树,比如下面一段代码

这段代码对我们来说很简单,就是个if else的判断,如果条件满足则调用meow方法,否则打印一段内容。
但是对于编译器来说,这段代码目前还只是一段没有语义的文本,目前对编译器毫无意义。
要让编译器认识这段代码,第一步就是给这段文本添加结构,而这些结构就是通过Kotlin语言的语法定义的。Kotlin开发者根据定义的语法编写代码,编译器根据语法解析这些文本,得到有结构的数据,这就是语法解析器的作用
比如如上图所示,if表达式要求必须以if开头,并且左右各有一个括号,如果我们编译的代码不符合这个规范的话,编译就会报错。Kotlin的更多语法定义可查看相关网站:kotlinlang.org/docs/refere…
如果输入的源代码根据语法解析正确,语法解析器将会构建出一个抽象语法树
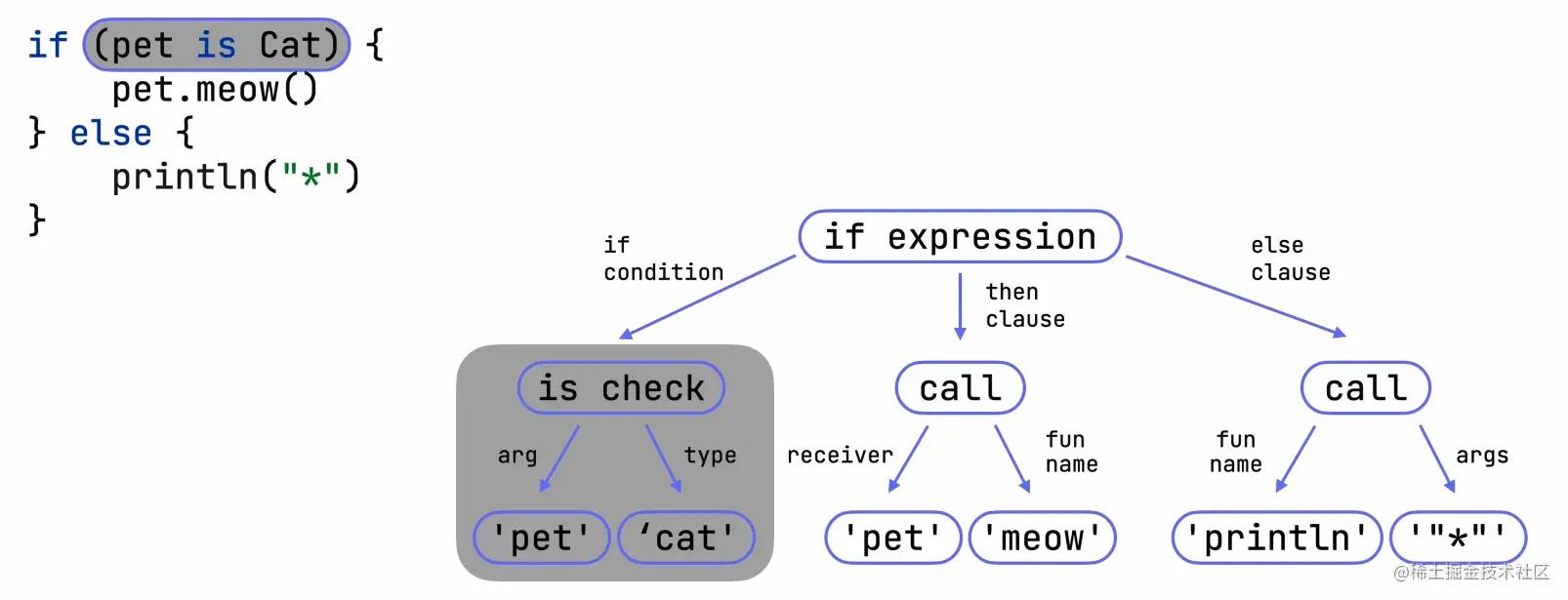
如上图,在解析成功后,解析器了解了代码的结构,它知道if表达式有三个部分,if表达式,then子句与else子句,并将结果存储在抽象语法树中
需要注意的是,在这一阶段,编译器还没有理解语义,解析器的目标是遵循语法理解代码结构,但在目前,它还不能分辨出节点内到底存储了什么,它只是将cat,pet这些存储为字符串,这些字符串还没有语义,这个时候就需要语义分析器开始发挥作用了
语义分析器

下一阶段,就是语义分析器以抽象语法树为输入,并向其中的节点添加语义信息,那么问题来了,什么是语义信息?
语义信息就是代码中用到的函数,变量和类型的所有详细信息,它能回答“这个函数从哪里来?”,“这两个字符串是否引用同一变量?”,“这是什么类型?”等问题

- 这段代码中
pet出现了3次,都指向同一个形参,在语法树中,这些pet是没有关联彼此独立的,语义信息的作用是让编译器让解这3个字符串引用的是同一个变量 - 语义信息同样包含类型信息,比如
pet参数是Pet类型的,语义信息需要解析所有使用的类型,并找到他们引用的类或者接口,然后以相同的方式进行解析 - 如图调用了
meow函数,语义信息的目标是理解在这种情况下该使用哪个函数,比如可以是类中的成员函数,也可以是同名的扩展函数,函数类型的属性,语义分析器需要选择出最合适的那个 - 语义分析器还有一个重要作用是类型推断,有时我们在声明属性时不需要指定类型,编译器可以推断出属性的类型,这也是由语义分析器来完成的
- 当语法不正确时,语法解析器会抛出错误,当语义发生错误,比如调用了不存在的函数,或者调用函数传递的参数个数不对时,语义分析器也会抛出错误

- 语义分析器分析出语义信息,并将这些信息存储在一个表里,这张表是包含语法树所有节点的额外信息的一个
map - 比如语法树中存储的第一个
pet字符串,表中存储了它是example.pets.Pet类型的函数参数,Cat字符串在表中也记录了它的类型 - 这也适用于第二个
pet字符串,这时编译器了解了两个pet字符串其实是引用了同一个参数,并且被智能转换成了Cat类型 - 对于方法也是一样的,在表中存储了
meow与println方法的位置
到了这个阶段,这张表存储了各个节点的信息,每个字符串都有了语义,编译器前端的工作也就完成了。
编译器前端的目标是给源代码转化为有结构和语义的数据结构,有了这些信息,编译器后端生成目标代码也就容易多了,比如Kotlin jvm后端将语法树和语义信息作为输入,生成Jvm字节码
编译器后端

我们知道,Kotlin可以将源代码编译成3个平台的目标代码,因此也有着3个不同的编译器后端,为不同的目标平台转换语法树和信息
上文提到,编译器后端包括一个可选的中间代码生成器,在Kotlin刚开始开发时,为了加快开发速度,以及在早期阶段的快速发展,没有使用任何的IR
因此老版的Jvm后端与JavaScript后端是不包括IR的,但是由于Kotlin编译器有着3个后端,显然所有后端可以共享一些代码表示的一些逻辑,简化和转换。因此Kotlin团队在开发Native后端时引入了IR
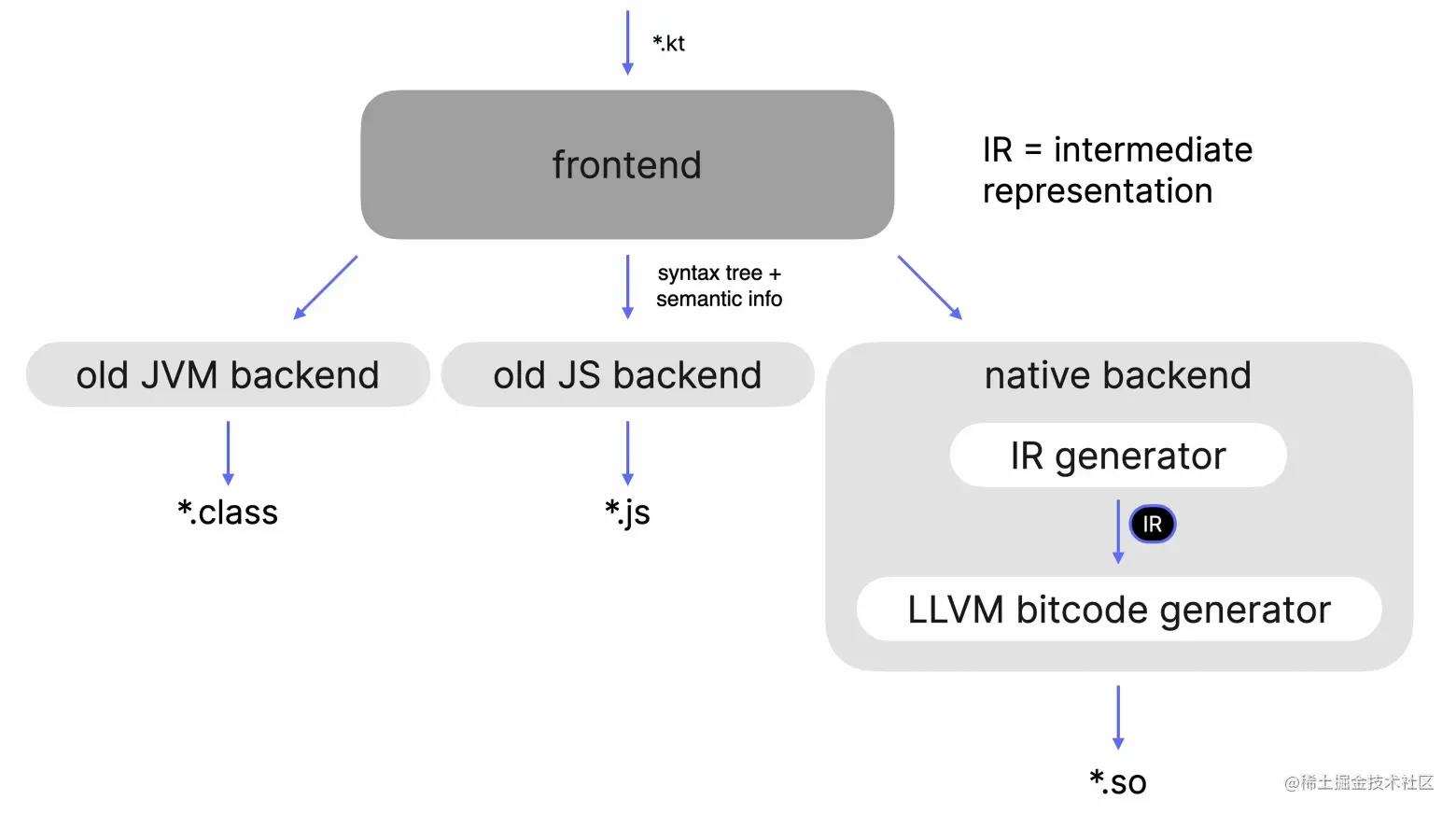
可以看到Native后端遵循了龙书的经典方法,将生成中间代码的阶段和基于IR生成目标代码的阶段分离,这一设计的目的是考虑到IR将来可能可以在不同的后端之间复用
K2编译器是什么?

如上图所示,K2编译器主要包括两个部分,新后端与新前端,其中新的Jvm后端与Js后端已经正式发布了(Native后端一开始就引入了IR),而新的编译器前端还在开发中
新的编译器后端
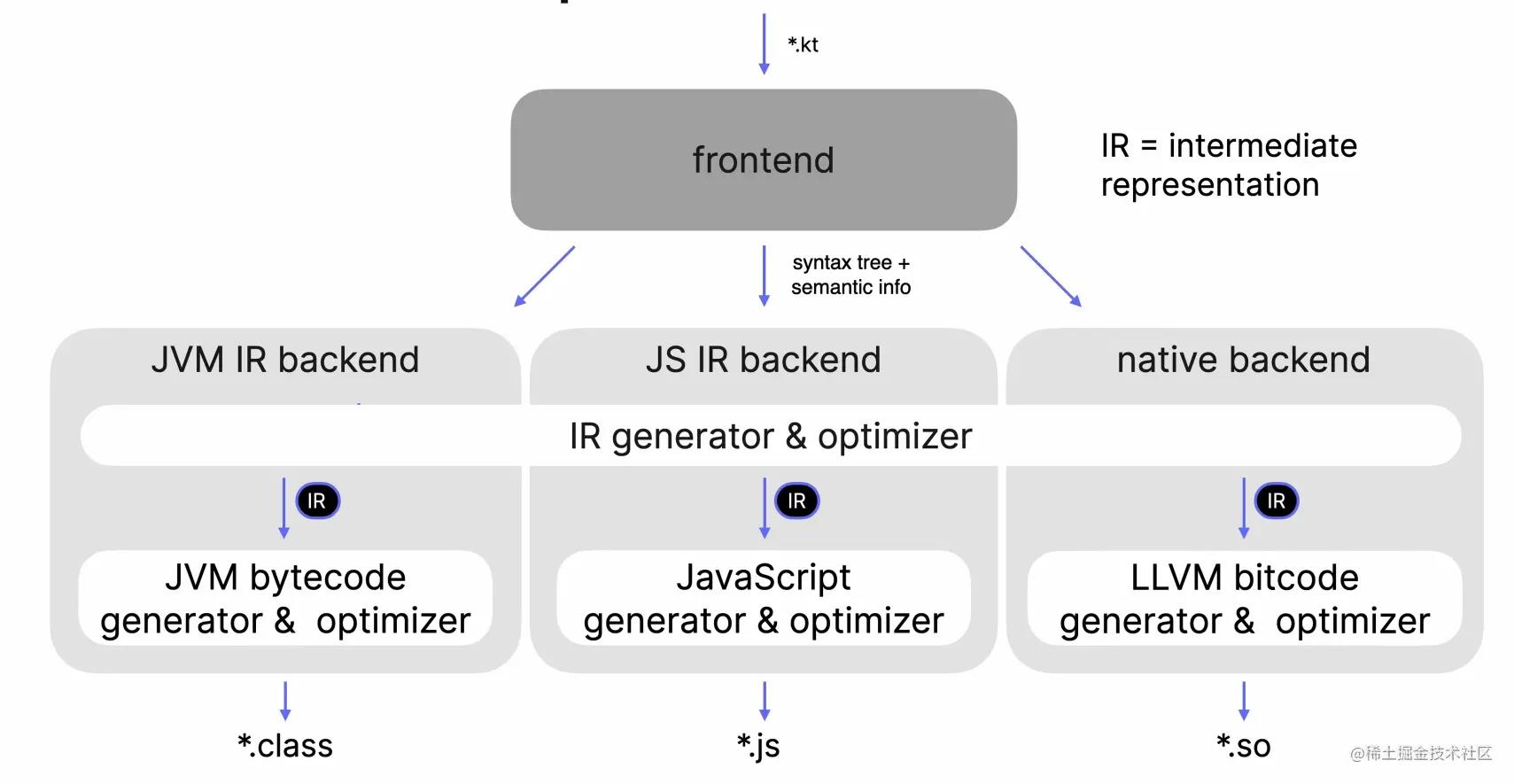
- 可以看出,新的编译器后端都使用了
IR,并共享构建和操作它的逻辑 - 引入
IR的主要目的就是在不同的后端之间共享逻辑 - 引入
IR同时简化了支持新的语言特性所需的工作 - 需要指出的是,性能改进不是新的后端的目标(性能改进主要通过一个新的前端来完成)
新的编译器前端

可以看出,新的编译器前端还是做了一样的工作,通过语法分析与语义分析,获得语法树与语意信息,但是会得到不同的数据结构,也就是FIR(前端中间表示)
在老版前端中,最后的输出是语法树和一个包含语义信息的表,其中语法树通过PSI(程序结构接口)表示,PSI的代码最早来源于IDEA。而带有语义信息的表称作BindingContext,它是一个特殊的map,存储了PSI元素的所有语义信息
而新版前端与之不同,如下图所示:
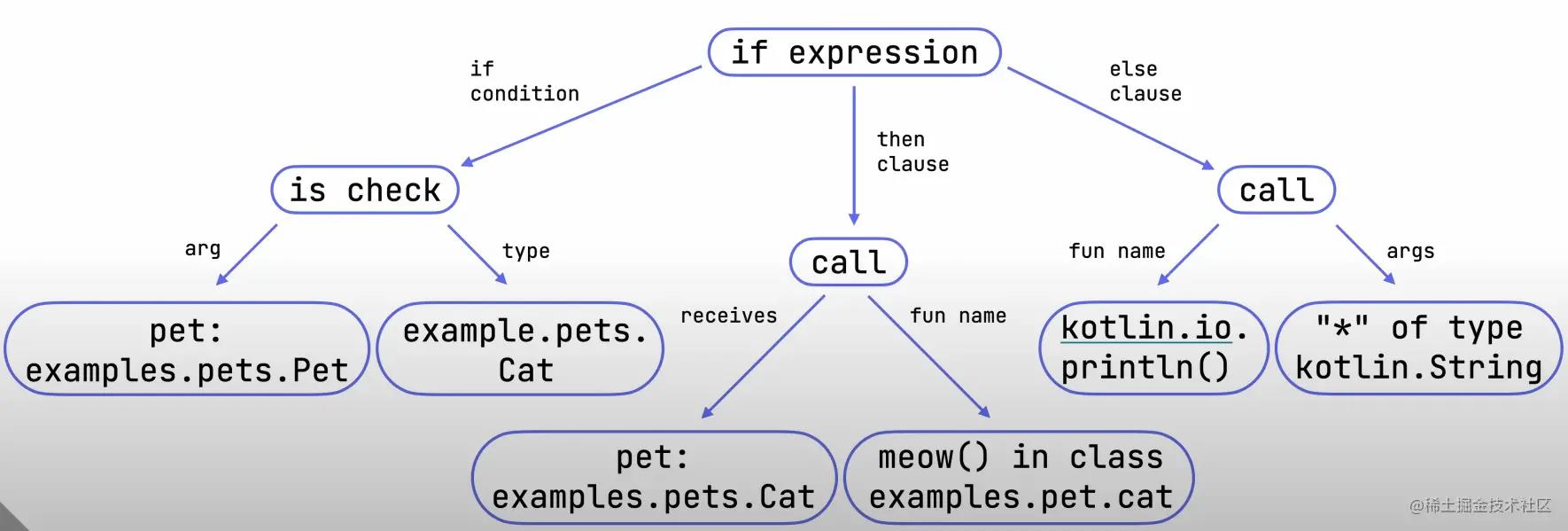
FIR = 前端中间表示 = 带有语义信息的树
新前端使用FIR表示输出,它本质上也是一棵语法树,但是带有语义信息。树包含其节点中的所有语义信息,不再使用单独的数据来表示
所以新前端的想法其实很简单,旧前端产生两个数据结构,而新前端只产生一个数据结构
同时,新的编译器前端将给编译器和IDE都带来更好的性能,也将为Kotlin编译器插件提供公开api
FIR与IR的区别
FIR即前端中间表示,位于编译器前端,而IR即中间表示,位于编译器后端FIR为调用解析而设计和优化,而IR则为代码生成而设计和优化,IR使用FIR构建而成- 得益于
FIR单一的数据结构,它的生成和更新过程可以并行执行,因此它可以带来更好的性能,FIR也会做一些脱糖的工作,将复杂的语言结构替换为更简单的结构 - 而
IR的设计目标则不包括性能上的改进,它的主要目标是在不同的后端之间共享逻辑,并降低支持新的语言特性的成本
总结
Kotlin编译器可以分为前端与后端两部分,前端负责将源代码转化成语法树与语义信息,后端负责根据这些信息生成目标代码- 新的编译器后端引入了
IR,所有的后端共享IR以简化生成目标代码的过程 - 新的编译器前端引入了
FIR,将语法树与语义信息存储在一个数据结构中,同时带来一定的性能提升
目前K2编译器已经发布了alpha包,或许明年底就可以正式发布,应该也是时候了解一下K2编译器了,同时如果你需要开发Kotlin编译器插件,也有必要了解一下Kotlin编译器,希望本文对你有所帮助~
参考资料
最后
如果想要成为架构师或想突破20~30K薪资范畴,那就不要局限在编码,业务,要会选型、扩展,提升编程思维。此外,良好的职业规划也很重要,学习的习惯很重要,但是最重要的还是要能持之以恒,任何不能坚持落实的计划都是空谈。
如果你没有方向,这里给大家分享一套由阿里高级架构师编写的《android八大模块进阶笔记》,帮大家将杂乱、零散、碎片化的知识进行体系化的整理,让大家系统而高效地掌握Android开发的各个知识点。

相对于我们平时看的碎片化内容,这份笔记的知识点更系统化,更容易理解和记忆,是严格按照知识体系编排的。
全套视频资料:
一、面试合集
二、源码解析合集
三、开源框架合集

欢迎大家一键三连支持,若需要文中资料,直接点击文末CSDN官方认证微信卡片免费领取↓↓↓
以上是关于K2 编译器是什么?世界第二高峰又是哪座?的主要内容,如果未能解决你的问题,请参考以下文章