TIP 2018论文概述:基于深度学习的HEVC复杂度优化
Posted 机器之心V
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TIP 2018论文概述:基于深度学习的HEVC复杂度优化相关的知识,希望对你有一定的参考价值。
本文概述了 2018 年 6 月发表在 IEEE TIP 期刊的论文 Reducing Complexity of HEVC : A Deep Learning Approach。在此论文中,北京航空航天大学博士研究生李天一及其导师徐迈,提出了一种基于深度学习的视频编码复杂度优化方法,实现了在几乎不影响编码效率的前提下,显著降低高效率视频编码(High Efficiency Video Coding,HEVC)的复杂度。
■ 论文 | Reducing Complexity of HEVC: A Deep Learning Approach
■ 链接 | https://www.paperweekly.site/papers/2140
■ 源码 | https://github.com/HEVC-Projects/CPH
背景
与前一代 H.264/高级视频编码(Advanced Video Coding,AVC)标准相比,HEVC 标准能够在相同视频质量下,节省大约 50% 的比特率。这得益于一些先进的视频编码技术,例如基于四叉树结构的编码单元(coding unit,CU)分割结构。然而这些技术也带来了相当高的复杂度。与 H.264/AVC 相比,HEVC 的编码时间平均增加约 253%,较高的复杂度就限制了该标准的实际应用。因此,有必要在率失真(rate-distortion,RD)性能几乎不受影响的前提下,显著降低 HEVC 编码复杂度。
从 2013 年 HEVC 正式发布开始,学界已经在降低编码复杂度方向进行了广泛的研究。目前已经存在多种降低 HEVC 编码复杂度的方法。就编码过程而言,基于四叉树的递归 CU 分割搜索,占据绝大部分编码时间(在标准参考软件 HM 中用时超过80%),因此很多方法都通过简化 CU 分割来降低 HEVC 编码复杂度。
HEVC 中的 CU 分割结构如图 1 所示。在标准编码器中,CU 分割是一种递归的搜索,从最基本的 64×64 编码树单元(Coding Tree Unit,CTU)开始,一个 CTU 可以只包含一个 CU,也可以被分成四个子 CU;每个子 CU 又可以选择是否被分成四个更细的子 CU,以此类推,直到 CU 被分成最小尺寸 8×8 为止。
可见,从最大 64×64 到最小 8×8,多种可能的 CU 尺寸为 HEVC 标准提供了十分灵活的块分割方式,使编码器可以从中选出一种率失真代价最小的 CU 分割方案,作为实际编码结果。
与 H.264 相比,可选择的分割方案数增多,就更有希望找出率失真代价尽可能小的方案,这就是 HEVC 编码效率较高的一个重要原因。然而,有利往往也有弊,更多种 CU 分割方案,就意味着编码器需要花费更多时间,检查每种方案的率失真代价。
这是一个分层递归的过程,编码器需要对总共 85 个 CU(包括 64 个 8×8 的 CU,16 个 16×16 的 CU,4 个 32×32 的 CU 和 1 个 64×64 CU)编码,以检查每个 CU 的率失真代价。相比之下,在最终编码结果中,只会存在最少 1 个、最多 64 个 CU,因此如果能提前预测出合理的 CU 分割结果,即可直接对所选的 CU 进行编码,跳过不必要的率失真代价检查过程。
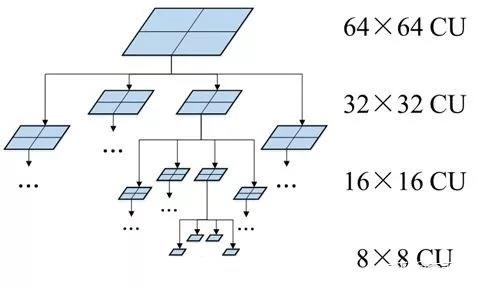
▲ 图1. HEVC中CU分割结构
早期的 CU 分割预测方法大多为启发式的,根据编码中的一些特征(如图像内容复杂度、率失真代价、运动矢量信息等)和人为制定的决策规则,在进行递归搜索之前,提前决定 CU 分割。2015 年以后,利用机器学习预测 CU 分割的一些方法被陆续提出,例如用支持向量机的自动学习,弥补了先前方法中需要人为制定决策规则的缺点。
然而,上述方法中的特征都需要手动提取,这在一定程度上依赖于研究者的先验知识,难以确定选取的特征是否为最优,并且容易忽略一些隐含但有用的特征。为实现特征自动提取,另有文献通过搭建简易的卷积神经网络(convolutional neural network,CNN)结构决定 CU 分割,初步实现了利用深度学习思想降低 HEVC 复杂度。
尽管相关研究已经取得诸多成果,在本文方法提出之前,已有文献中的网络结构还比较浅,难以充分发挥深度学习的优势,并且,先前基于 CNN 的方法都只适用于帧内模式,对于实际应用更广泛的帧间模式则无能为力。
在设计算法之前,作者首先直观地分析 CU 分割结果,如图 2 所示,帧内模式的 CU 结果主要由 CTU 中的图像内容决定,一般纹理越密集之处,CU 分割也越密集,反之亦反。当然 CU 分割不仅仅取决于纹理的细密程度,若一个 CU 中纹理比较密集,但恰好可以通过相邻 CU 信息来准确预测,那么此 CU 也有可能不被分割。
无论如何,CU 分割结果和图像内容紧密相关,因此在帧内模式中,本文首先提出一种与 CU 分割相适应的 CNN 结构,通过图像内容自动提取特征,来学习 CU 分割结果。
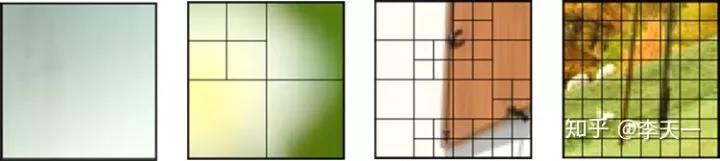
▲ 图2. 帧内模式CTU内容与CU分割结果示例
对于帧间模式,可以发现 CU 分割结果不仅与视频内容有关,还取决于相近帧内容的相似度。例如,在背景静止或只有缓慢运动的视频中,CTU 中的内容可能比较细密,但可以由参考帧准确预测得到,那么这个 CTU 很可能不被分割。
鉴于此,本文提出一种长-短期记忆(Long Short-Term Memory,LSTM)模型,以学习帧间模式 CU 分割的时序依赖关系。在帧间模式中,本文将 CNN 与 LSTM 结合使用,同时学习视频内容的空间和时间相关性。如图 3 所示,将连续若干帧的 CTU 图像信息输入到 CNN+LSTM 中,预测每一帧的 CU 分割结果。另外,与帧内模式不同,帧间模式中输入网络的是残差图像,这是考虑到残差图像本身就包含时间相关性信息,有利于准确预测。

▲ 图3. 帧间模式CTU内容与CU分割结果示例
思路
确定总体思路后,作者首先构建一个大规模的 CU 分割数据库,为训练神经网络提供数据支撑,并有望促进 HEVC 编码复杂度优化的后续研究。本数据库同时涵盖了帧内和帧间模式的全部四种配置(All Intra,Low Delay P,Low Delay B 和 Random Access,简称 AI,LDP,LDB 和 RA),其中帧内模式数据来自 2000 个无损图像,帧间的来自 111 个无损视频。所有数据均采用 4 个不同量化参数(Quantization Parameter,QP)压缩,以适应不同码率和编码质量。
在数据库中,每个样本由两部分组成:CU 中图像内容构成的亮度矩阵,以及一个二分类标签代表是否分割。表 1 显示了本数据库的样本组成,可见在每种模式中,都收集到超过 1 亿个样本,且正负样本分布大体均匀,保证能够有效训练。
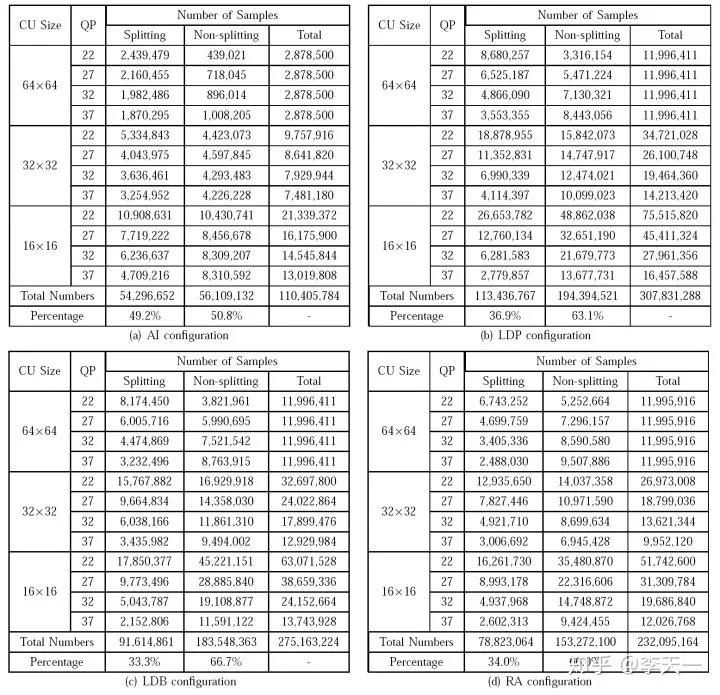
▲ 表1. CU分割数据库的样本组成
在取得足量数据后,本文又提出一种分层 CU 分割图(hierarchical CU partition map,HCPM),对整个 CTU 中的 CU 分割进行高效建模。传统的 CU 分割预测,一般是把 CU 分割过程视为各自独立的三级分类器,分别预测每个 64×64 的 CU、32×32 的 CU 和 16×16 的 CU 是否分割。然而,传统方法每次预测只能得到一个 CU 的分割结果,若要得到整个 CTU 的分割结果,需要最多 21 次预测,计算量较大,并且会增加算法本身的计算时间。
为解决这一问题,在本文的 HCPM 中,可直接将一个 CTU 输入到网络中,得到 1+4+16 个节点的结构化输出,来预测 CTU 中所有可能的 CU 是否分割。
如图 4 所示,对于一个 CTU,通过数据库可以得到正确的 CU 分割结果,每个存在的 CU 都用 1 代表分割,0 代表不分割,即 HCPM 真值;将此 CTU 通过深度网络处理,会得到相应的 HCPM 预测值。网络的训练就是使 HCPM 预测值尽可能接近真值。如此,通过构建高效的 HCPM,可以大幅节省算法本身的调用时间,有利于最终降低编码复杂度的目标。
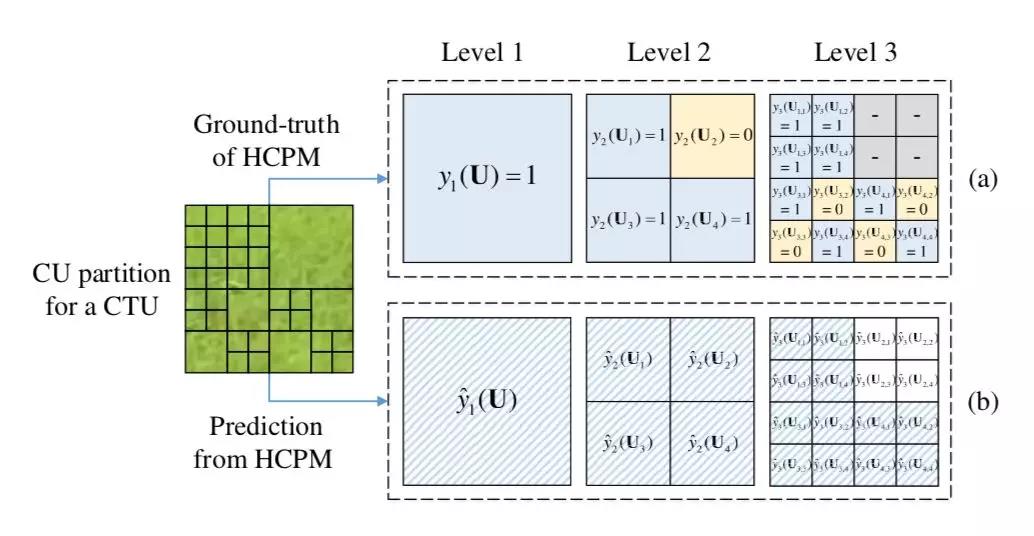
▲ 图4. 分层CU分割图示例(HCPM)
帧内模式
下面分别介绍帧内和帧间模式中的深度神经网络结构。
在帧内模式中,作者设计了一种可以提前终止的分层 CNN(early-terminated hierarchical CNN,ETH-CNN)。该网络输入一个 64×64 CTU 的亮度信息,输出所有不同尺寸 CU 的分割概率,即前文所述的 HCPM。其中的提前终止机制,可以减少网络本身的时间复杂度。
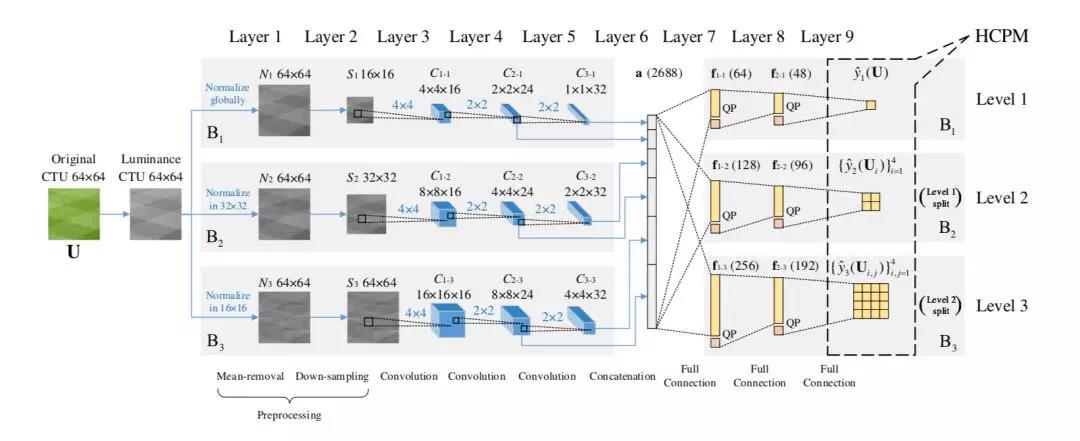
▲ 图5. ETH-CNN结构
ETH-CNN 包含两个预处理层,三个卷积层,一个归并层和三个全连接层,结构如图 5 所示。各部分的具体配置与功能,阐述如下。
预处理层
对 CTU 原始亮度矩阵进行去均值和降采样等预处理操作。为了适应最终的 HCPM 三级输出,从预处理层开始,输入信息就在三条并列的分支 B1、B2 和 B3 中操作。
首先,在去均值操作中,CTU 的亮度矩阵减去图像整体或某一局部的平均亮度,以减小图像间的亮度差异。之后,考虑到分割深度较浅的 CTU 一般对应平滑的图像内容,没有过多细节信息,因此在 B1 和 B2 中,对去均值的亮度矩阵进一步降采样,将矩阵尺寸转化为 16×16 和 32×32,进一步降低后续的计算复杂度。
并且,通过这种选择性的降采样,能保证后续卷积层的输出尺寸(1×1、2×2 和 4×4)与 HCPM 的三级输出标签数相一致,使卷积层输出结果具有比较清晰、明确的意义。
卷积层
在每条分支中,对预处理后的数据进行三层卷积操作。在同一层里,所有三条分支的卷积核大小相同。首先,在第 1 卷积层中,预处理后数据与 16 个 4×4 的核进行卷积,获得 16 种不同的特征图,以提取图像信息中的低级特征。在第 2、第 3 卷积层中,将上述特征图依次通过 24 个和 32 个 2×2 的核进行卷积,以提取较高级的特征,最终在每条分支中均得到 32 种特征图。
所有卷积层中,卷积操作的步长等于核的边长,恰好能实现无重叠的卷积运算,且大多数卷积核作用域为 8×8,16×16,32×32 或 64×64 等(边长均为 2 的整数次幂),在位置和尺寸上都恰好对应各个互不重叠的 CU。因此,ETH-CNN 中的卷积与 HEVC 的 CU 分割过程相适应。
归并层
将三条分支中第 2、第 3 卷积层的所有特征归并在一起,组合成一个向量。如图 5 中间的蓝色箭头所示,归并后的特征由 6 种不同来源的特征图组合而成,这有助于获得多种全局与局部特征。
全连接层
将归并后的特征再次分为三条支路进行处理,同样对应于 HCPM 中的三级输出。由于经历了特征归并,此处的任何一条支路都可以利用完整 CTU 中的特征,来预测 HCPM 中某一级 CU 的分割结果。在每条支路中,特征向量依次通过三个全连接层,包括两个隐含层和一个输出层,最终的输出即为 HCPM 预测值。
此外,需要考虑量化参数 QP 对 CU 分割的影响。一般随着 QP 减小,有更多的 CU 会被分割,反之,当 QP 增大时,则倾向于不分割。因此,在 ETH-CNN 的第一、第二全连接层中,将 QP 作为一个外部特征,添加到特征向量中,使网络能够对 QP 与 CU 分割的关系进行建模,在不同 QP 下准确预测分割结果,提高算法对不同编码质量和码率的适应性。
另外,通过 ETH-CNN 的提前终止机制,可以跳过第二、三级全连接层,以节省计算时间,即:如果第一级最大尺寸的 CU 不分割,则不需要计算第二级是否分割;如果第二级的 4 个 CU 都不分割,则不需要计算第三级是否分割。
其他层
在 CNN 训练阶段,将第一、第二全连接层的特征分别以 50% 和 20% 的概率随机丢弃(dropout),防止过拟合,提高网络的泛化能力。在训练和测试阶段,所有卷积层和第一、二个全连接层均用修正线性单元(rectified linear units, ReLU)激活。所有分支的第三个全连接层,即输出层,采用 S 形(sigmoid)函数进行激活,使输出值都位于 (0,1) 内,与 HCPM 中的二值化标签相适应。
帧间模式
在帧间模式中,需要同时考虑 CTU 内容中的空间相关性,以及不同帧 CTU 内容的时间相关性。在 ETH-CNN 的基础上,作者进一步提出可以提前终止的分层 LSTM(early-terminated hierarchical LSTM,ETH-LSTM),来学习帧间 CU 分割的长、短时依赖关系。
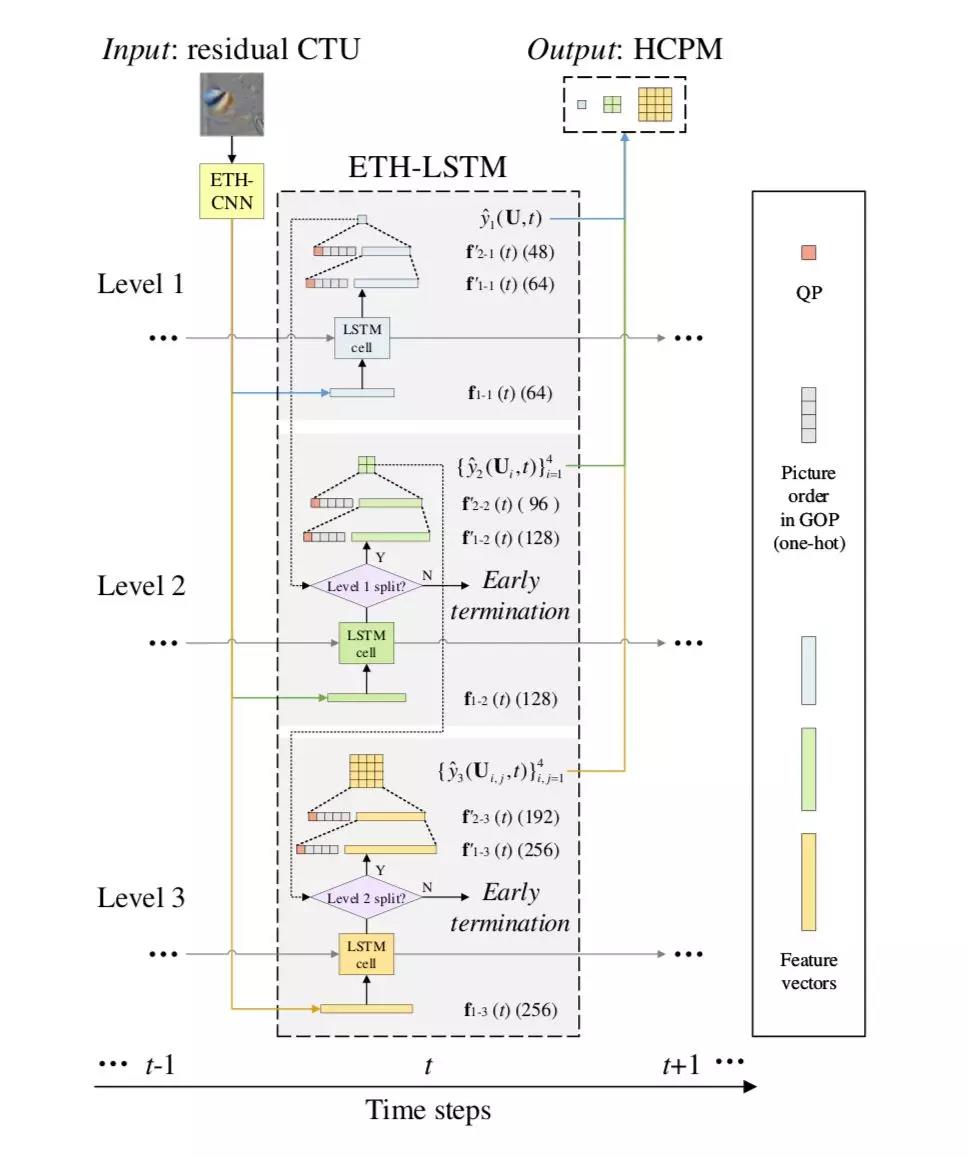
▲ 图6. ETH-LSTM结构
ETH-LSTM 的结构如图 6 所示。由于帧间模式同样需要提取 CTU 中的空间特征,首先,仍然将 CTU 输入到 ETH-CNN 中。但与帧内模式不同,帧间模式的网络输入是残差 CTU 的亮度信息,而不是原始 CTU 的亮度信息。这里的残差,是通过对当前帧进行快速预编码获得的,此过程与标准编码过程相似,唯一区别是将 CU 和 PU 强制设为最大尺寸 64×64,以节省编码时间。
尽管额外的预编码过程带来了时间冗余,但这种冗余只占标准编码时间的 3%,不会显著影响算法的最终性能。将残差 CTU 通过 ETH-CNN 进行处理后,把第 7 层(即第 1 个全连接层)三个支路输出的特征向量,送入到 ETH-LSTM 的三级,以备后续处理。
在 ETH-LSTM 中,第 1、2、3 级各有一个 LSTM 单元。每个 LSTM 单元接受当前时刻的输入向量(即 CNN 处理后的特征),以及上一时刻 LSTM 产生的状态向量,由此来更新当前时刻 LSTM 的状态向量和输出向量。LSTM 单元的输出向量,再依次通过两个全连接层做进一步处理,最终得到 HCPM 所需的二值化 CU 分割概率。
与帧内模式类似,此处的每个全连接层也考虑了外部特征:QP 值和当前帧在 GOP 中的帧顺序,以适应不同编码质量和帧位置对 CU 分割的影响。与 ETH-CNN 类似,ETH-LSTM 中同样引入提前终止机制,以减少 ETH-LSTM 中的计算冗余。最终,将 ETH-LSTM 中三个级别的输出联合起来,即可得到 HCPM 预测结果。
实验
在测试本方法性能时,选用 18 个 HEVC 标准视频以及本文图像数据库中的 200 幅测试图像,保证测试数据的多样性和代表性,在 QP 22,27,32,37 和全部四种标准配置(AI,LDP,LDB 和 RA)下,用标准 HEVC 编码器和作者改进后的编码器分别进行编码,比较编码时间的减少率和率失真性能。帧内和帧间模式的测试结果如表 2 和表 3 所示。
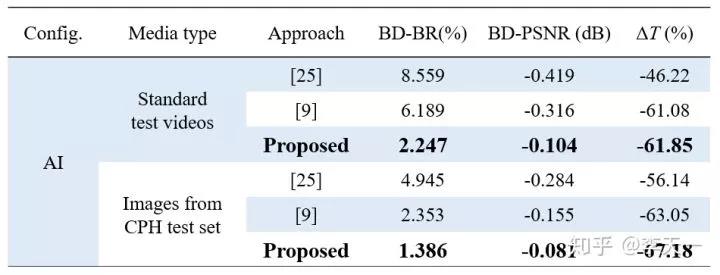
▲ 表2. 帧内模式复杂度和率失真性能对比
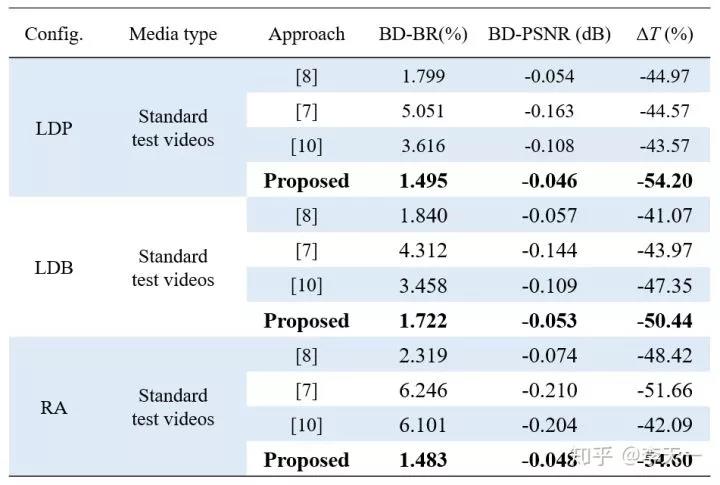
▲ 表3. 帧间模式复杂度和率失真性能对比
两表中的 BD-BR 和 BD-PSNR 是衡量率失真性能的关键指标,代表相同质量下的码率变化和相同码率下的质量变化。在编码复杂度优化中,对块分割的快速判决并不是绝对准确,因此所有算法都会不同程度地带来率失真损失,即 BD-BR>0,BD-PSNR<0。这两项指标的绝对值越小,说明对率失真性能的不利影响越小,算法越优。表中的 ΔT 为编码时间节省率,绝对值越大说明算法越优。可见,本文方法在率失真性能优于先前方法的前提下,能够更有效地降低编码复杂度。
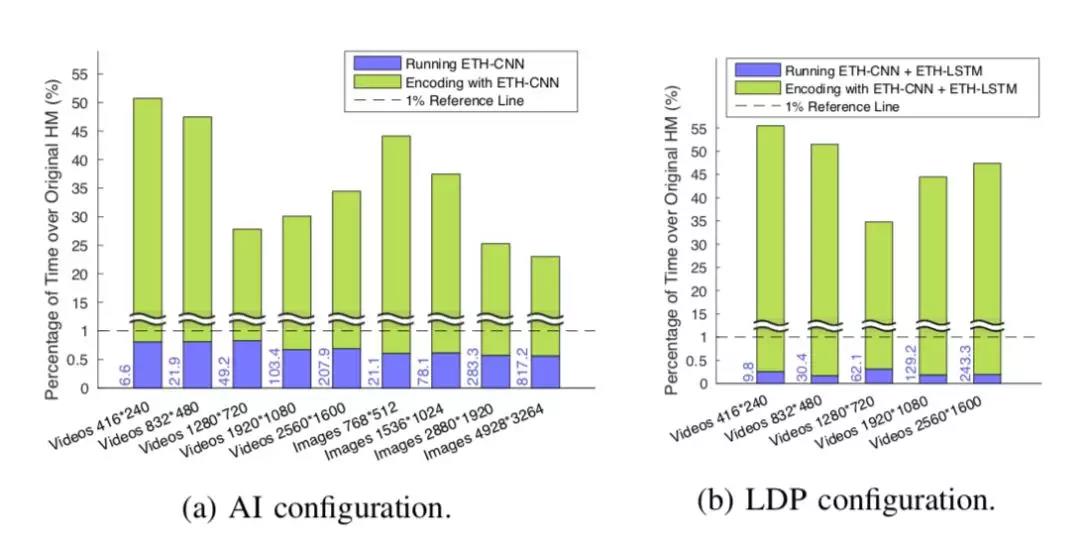
▲ 图7. 编码时间构成。蓝柱和绿柱代表网络运行时间和本方法中HM编码时间占原编码时间的百分比,柱左侧的蓝色数字代表网络运行的绝对时间(单位毫秒)
总结
至此,已经说明了本文方法的有效性。兼顾良好的复杂度和率失真性能,是因为深度神经网络能够准确预测 CU 分割。另一个自然而然的问题是:既然网络层数和参数都比较多,网络本身的运行是否比较费时,影响总的编码时间?
实际上,如图 7 所示,无论在帧内或帧间模式,网络本身的运行时间都不超过原编码时间的 1%,因此几乎不会影响最终的编码复杂度。这得益于独特的、适用于 CU 分割的网络结构,包括三个主要原因:
1. 首先,CU 分割结果采用高效的 HCPM 表示,调用一次 CNN(或 CNN+LSTM),即可预测整个 CTU 中所有 CU 的分割结果,使网络运行次数远少于传统方法中分别预测每个 CU;
2. 其次,ETH-CNN 中的卷积层跨度等于核的宽度,即卷积核间无重叠,这与传统的有重叠卷积相比,复杂度能降低到几分之一到几十分之一;
3. 另外,ETH-CNN 和 ETH-LSTM 都提供了提前终止机制,能够根据上一级 CU 分割结果跳过下一级的一部分运算。
以上几个原因,使得深度网络本身运行时间远小于 HM 编码时间,保证了本文方法降低编码复杂度的可行性和有效性。
入门 TIP 2018 深度学习 HEVC以上是关于TIP 2018论文概述:基于深度学习的HEVC复杂度优化的主要内容,如果未能解决你的问题,请参考以下文章