热敏电阻高精度的读取方法是哪种啊?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了热敏电阻高精度的读取方法是哪种啊?相关的知识,希望对你有一定的参考价值。
作为支持模拟和数字温度传感器的高级应用/系统工程师,在工作中经常被问到有关温度传感器应用的问题。其中有很多是关于模数转换器(ADC)的,由于ADC在系统应用中的重要性,我花费很多时间在解释ADC对系统精度有何意义,以及如何理解并实现所选传感器的更大系统精度上。
温度传感器用于大功率开关电源设计中,需要监测功率晶体管和散热器。电池充电系统需要温度传感器监测电池温度,以便安全充电并优化电池寿命,家庭恒温器则需要温度传感器监测房间温度,以相应控制供暖,通风和空调系统。
这些应用中,常用的温度测量方法是使用负温度系数(NTC)热敏电阻。NTC是电阻器件,其电阻随着温度的改变而改变。为了满足当今温度传感器需求,一种更新、更高效、更准确的方法是使用硅基热敏电阻,它是一种正温度系数(PTC)器件。并且PTC不是电阻器件,而是电流模式器件;在电流模式下工作的硅提供基于温度的线性输出电压。
无论您使用NTC还是PTC,您的设计都需要一个ADC和一个MCU来测量热敏电阻的电压输出。本文的重点是将硅基热敏电阻与MCU结合使用带来的许多优势。我们将探讨NTC和PTC热敏电阻的优缺点。
选择微控制器
MCU选型具有诸多选择,但很可能在选择温度传感器时这个组件已经被确定。你可以关注温度传感的ADC外设的具体情况。
选择ADC
ADC有很多不同的类型。最受欢迎的两种为逐次逼近寄存器(SAR)和 Delta-Sigma模拟数字转换器。Delta-Sigma提供高分辨率(8-32位分辨率),但采样速度较慢。SAR类型最古老、最常见,分辨率为8-18位,采样速度更快。对于温度传感,任意一种ADC都是不错的选择。
ADC分辨率
ADC的位数将决定分辨率而非精度。分辨率是ADC用来测量施加到ADC管脚的模拟电压的步长。分辨率的位数以及参考电压(VREF)将设置ADC的步长值。
比如,一个10位ADC将具有2^10=1024位,而3.3VDC的VREF将为每个ADC位提供3.3/1024=0.003226VDC的分辨率。一个16位ADC将具有65536位的总分辨率,每位分辨率为0.000005035VDC。ADC位数越多将意味着更高的测量分辨率。
请勿将精度与分辨率混淆。分辨率是指能够看到被测电路值的变化。用于温度测量的典型ADC的分辨率为12-16位。您会发现8位或10位ADC不能提供足够的分辨率来查看热敏电阻的精度,且具有较大的温度步长,通常不可接受。
过采样以获得更高分辨率
过采样是一种平均测量值的方法,可提高分辨率和信噪比。过采样的工作原理是将多个带有噪声的温度测量值相加,然后进行平均,得到一个更精确的数值。每超过8个过采样,分辨率将增加2位。16次过采样会将10位ADC的总分辨率提高到14位。如果噪声高于Nyquist频率,则可在应用程序中使用任意数量的样本(N#份样本)来获得设计所需的分辨率。Nyquist速率是您期望获得实际温度读数的频率。样本总数必须比实际所需温度结果快至少N#倍。
在使用过采样方法时,在输入信号中添加一些抖动噪声可改善分辨率误差。许多实际应用中,噪声小幅增加可大幅提高测量分辨率。在实践中,将抖动噪声置于测量感兴趣的频率范围之外,随后可以在数字域中滤除这些噪声,从而在感兴趣的频率范围内进行最终的测量,同时具有更高的分辨率和更低的噪声。
提供抖动噪声的更佳方法是将热敏电阻分压器的Vcc和VREF.分开(将MCU的内部VREF用于ADC)。请勿在电阻分压器电压检测线上放置电容器。许多情况下,电路噪声将足以使电阻分压器的电压抖动,以求平均值。抖动噪声必须等于4位或更多位振幅。10位具有3.3VDC VREF的ADC将拥有0.0032VDC的电压步长。抖动噪声必须至少是预期温度测量值上下的4位分辨率。10位ADC的最小抖动噪声必须高于ADC的最低有效位(LSB)+/- 0.0128VDC(0.0256VDC p-p)或更高,以提供必要的电平,从而通过求平均值适当提高ADC的位分辨率。
在ADC读取一个位值并计算温度后,您可将该值存储在先进先出(FIFO)软件阵列中。当新值输入阵列时,最旧的样本将被丢弃,所有其他样本都将移至下一个对应的单元,从而创建一个FIFO。该求平均值方法可应用于温度转换过程中使用的任何值,例如温度、ADC位值、分压器电压,甚至计算得出的电阻。所有这些因素平均下来都将很好地发挥作用。
定点或浮点
微控制器可在内部具有浮点单元硬件,也可具有无需硬件即可进行浮点数学运算的固件库。32位非浮点器件的快速示例是Cortex “M4”器件,而带有浮点的版本将标记为“M4F”。与使用定点部件和使用浮点固件库相比,MCU内部具有浮点硬件使计算速度更快、功耗更低。
具有固定点意味着只能显示大于零的整数。例如:如果1 + 1,则得到2,然后取平均值1。如果2 + 1,则得到3,然后取平均值1.5。在定点计算中,结果将为“ 1”, 小数点以下的数字都不能用1。用固定点测量温度时,将只能看到和参考整数的温度,即22°C,23°C,24°C。浮点可显示更高分辨率的温度,即22.1°C或22.15°C。使用浮点数既可更轻松计算温度,也可使用带有插值的查找表。您可使用具有单位数分辨率的定点查找表,分辨率为一位数,这对于许多应用程序是可接受的。
选择热敏电阻
热敏电阻有两种类型,基本的NTC和PTC热敏电阻。通常会将它们混为一谈,被认为是同一类型的器件。这并不正确。NTC是一种随温度变化的电阻装置。如图1的分压器电路图中所示,在热敏电阻顶部放置一个电阻并施加稳定的电压。温度变化时,热敏电阻中的电阻也会发生变化,从而改变顶部电阻两端的压降。分压电阻器中心的输出为模拟电压,将由ADC测量。
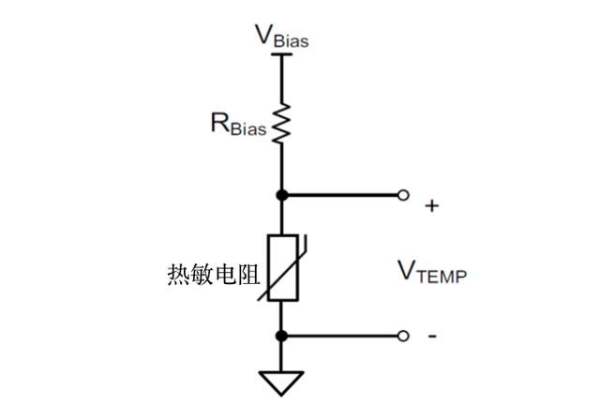
图1:分压电路实现
PTC是一种基于电流工作的硅器件。随着温度变化,传导电流也随之发生变化。大多数PTC的工作都使用恒流源进行,如图2所示。电流改变时,由电流源提供的电压改变。
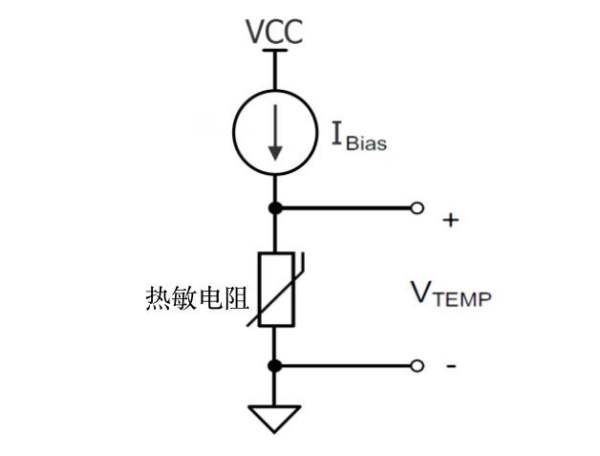
图2:恒流电路实现
ADC测量电压的变化,并将测量值转换为温度。
你也可以使用PTC,就像NTC热敏电阻与RBias电阻一样,见图1。顶部电阻将如同电流源一样工作。与相同条件下的NTC相比,PTC通常对温度变化具有更好的热敏性,且对较小的变化更敏感。PTC的另一个优点是:它们在Vtemp 连接处具有线性输出,如下图3所示,因此更易于校准。这也使零件在整个温度范围内都更加精确。
图3: PTC热敏电阻线性电阻斜率
NTC具有类似于下面图4所示的非线性输出,且可能需要在温度室内进行三点校准,以允许斜率补偿和偏移误差调整,从而在整个温度范围内保持精确。NTC的非线性斜率无法在未校准的情况下在整个温度范围内提供稳定的温度信息。

图4: NTC热敏电阻非线性电阻斜率
在正常条件下,NTC可以使用具有适当温度分辨率的12位ADC,尤其是在较冷温度下,但是PTC通常需要14位ADC才能获得足够的分辨率,以查看温度步长,从而显示出 PTC的实际精度。对于所有温度范围内的PTC都是如此,但NTC将需要一个14位ADC来测量60°C以上的较高温度。
在PTC顶部增加一个RBias电阻会减小PTC的动态范围。较低的动态范围使ADC的电压反馈降低,这就是PTC需要14位ADC分辨率的原因。但是,由于PTC的线性斜率,较低的动态范围将导致较大的温度误差测量。室温下的单点偏移将在整个温度范围内校准PTC。对于基于PTC的系统,在整个温度范围内,这将使温度测量比典型的(同等指定的)基于NTC的系统更加精确。
比率度
比率度是描述捕获的ADC值的术语。该值可与输入和/或电源电压的变化成比例地变化。当提供给温度感测电路的分压器的VCC电源也提供用于VREF的电压时(如下面图5所示),则称其为比率度。VCC的任何变化都将在分压器和VREF处同等同时变化,从而影响ADC的测量值,让这些源之间的潜在差分误差最小。
比率度方法可以增加系统中的总精度。在实现不使用平均或过采样的基于热敏电阻的温度传感器时,为分压器和ADC的VREF使用相同的电源非常重要。
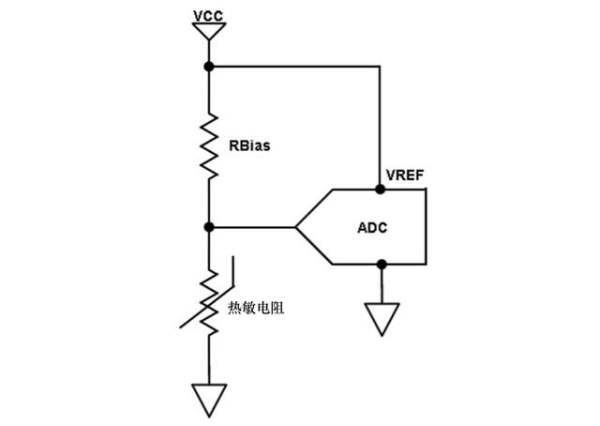
图5: 比率度,
由同一电源供电的电阻分压器和VREF供电
滤波
在大多数情况下,无需在分压器上使用电容器,在使用单端ADC的比率法时也不应使用。对于差分的VREF/ADC输入,您通常会在ADC输入和VREF输入之间放置一个电容。使用比率度方法时,对Vtemp 进行滤波将改变感测线上的电压响应,但不会改变ADC VREF 的电压响应。因此,增加一个滤波器会增加输入到电阻分压器的VREF 和VCC之间的差值,并增加误差。
不使用比率度方法时,可以使用在分压器处增加电容来滤除电压,以消除噪声和电压变化,否则会在测量中产生误差。添加一个电容器来滤除VREF也是一个不错的方法。有时,VREF 是内部的,无需额外滤波。如果在Vtemp线上添加电容器,则会增加对温度变化的响应时间。如果测得的温度响应缓慢且无需立即采取措施,则滤波器可能会有所帮助。另一种滤波器解决方案是在电阻分压器顶部的VCC处增加一个电容器,以滤除系统中的噪声以进行温度测量。如果使用比率度,则在VREF 上添加相同的电容器,以使两个电源的电压变化保持一致。
缓冲器和放大器
放大器可用于增加热敏电阻的动态范围。所有运算放大器都有潜在的失调误差和增益误差。选择对精度和失调影响最小的运算放大器需要付出更多努力。校正失调和增益误差所需的校准可能比升级到更高质量的ADC的成本更高。一些MCU具有内部运算放大器。许多DS ADC具有集成的PGA,正是为了这个目的(缓冲/增益)。一些SAR ADC也有这些功能。
有时会使用单位增益缓冲器来防止下垂或加载到电阻分压器电路。当ADC对热敏电阻分压器电路进行采样时,来自ADC的浪涌电容会导致测量时几毫伏的电压下降。如果在ADC中具有足够的分辨率,则会在温度测量中观察到这是一个错误。如果直接在ADC管脚上增加一个等于ADC电容10倍的电容器,则无需使用缓冲器就可以补偿ADC电容的浪涌电流。典型的ADC电容为3pF-20pF。最好在ADC管脚附近添加一个30pF – 200pF的电容,这是一个很好的解决方案。它将对热敏电阻的测量或热响应的影响降至最低。
漂移
由于PTC热敏电阻使用硅作为其基础材料且具有线性斜率,因此,流经PTC的电流随时间和温度变化具有非常低的漂移。另一方面,NTC通常对所用材料的电阻具有温度依赖性,且在高温下会随时间变化。NTC具有一个beta值,可定义整个温度范围内的TCR / PPM,且PPM随时间变化。
从ADC导出温度
NTC热敏电阻温度是基于器件的电阻。许多设计人员使用查找表寻找特定温度下的电阻。然后通过插值计算每个1°C温度步长之间的实际温度。为了更大程度地减少查找表的大小,您可使用5°C的查找表,但是内插误差会高一些。对于大多数设计人员而言,0.5°C的精度已足够,因此带有插值的5°C查找表就已足够。
PTC基于流经零件的实际电流,通常由公式定义。PTC基于三阶或四阶多项式。四阶多项式的精度曲线拟合(R2)为1.0000%至0.9999%,以提供温度信息。Steinhart Hart方程可由NTC和PTC使用,并采纳使用自然对数来计算温度的三阶多项式。Steinhart Hart方程式已为更多设计人员所认可,因为多年前其最初为NTC创建。如今,大多数高精度PTC都依赖于四阶多项式。
校准
所有NTC和PTC都需要校准才能精确。可购买一些具有更严格公差和Beta值的NTC。这似乎可以消除校准。但是,热敏电阻不是系统中唯一的组件。顶部电阻具有容差,且在整个温度范围内具有PPM,VCC在电压以及温度范围内存在电压误差。系统总精度可能超出预期范围,且精度可能并不能达到期望。
NTC通常需要进行三点校准以调整斜率误差,且需要进行偏移以校正总偏移误差。因此,这需要温度箱和时间来收集整个温度的误差。首先,由于硅的工艺偏差,PTC将具有较大的偏移误差,但是可通过单个偏移调整在整个温度范围内对其进行校正。大多数情况下,在组装的最终编程过程中,偏移调整可于室温下进行,且无需温度箱或时间来进行校准。
结论
NTC和PTC因零件数量少、成本低都易于实现。但是,NTC可能将需要更昂贵的校准方法,且随时间推移具有更高的漂移。
PTC是进行温度测量的新方法。一个简易的失调校正是整个温度范围内所需的整个校准。PTC的精度非常精确,且温度测量值随时间和温度变化具有很小的漂移。
需要明确的是,NTC和PTC不是同一类型的组件,且很难仅通过阅读数据表进行直接比较。PTC不是电阻组件,大多数供应商建议仅使用恒流源来驱动它们。德州仪器(TI)创建了一个设计工具,以向设计人员展示如何在电阻分压器电路中使用其TMP61 系列 PTC。该工具包括一个计算阻力表,供那些习惯使用查找表的人使用。使用新的设计考虑因素和正确的计算方法,使得PTC比NTC具有更高的精度和稳定性。
参考技术A热敏电阻高精度读取方法,现在电子工程师大部分都是采用惠斯顿电桥,利用惠斯顿电桥可精确测量热敏电阻的阻值的方法来读取数据!
原理:将一个合适的NTC热敏电阻Rt代替R4,串接在桥电路中,将恒压源加在电路的两端,从桥路的另两端就可以获得温差信号△V;当电桥平衡时:
Rt=R4=R3*R1/R2,电流表读数为零,△V=0;当Rt随温度变化其阻值发生变化,△V会剧烈的发生跟随变化。
本回答被提问者采纳各语言使用的是哪种线程模型?
问题
(1)线程类型有哪些?
(2)线程模型有哪些?
(3)各语言使用的是哪种线程模型?
简介
在Java中,我们平时所说的并发编程、多线程、共享资源等概念都是与线程相关的,这里所说的线程实际上应该叫作“用户线程”,而对应到操作系统,还有另外一种线程叫作“内核线程”。
用户线程位于内核之上,它的管理无需内核支持;而内核线程由操作系统来直接支持与管理。几乎所有的现代操作系统,包括 Windows、Linux、Mac OS X 和 Solaris,都支持内核线程。
最终,用户线程和内核线程之间必然存在某种关系,本章我们一起来学习下建立这种关系常见的三种方法:多对一模型、一对一模型和多对多模型。
多对一模型
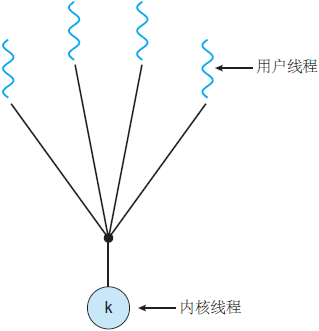
多对一线程模型,又叫作用户级线程模型,即多个用户线程对应到同一个内核线程上,线程的创建、调度、同步的所有细节全部由进程的用户空间线程库来处理。
优点:
- 用户线程的很多操作对内核来说都是透明的,不需要用户态和内核态的频繁切换,使线程的创建、调度、同步等非常快;
缺点:
-
由于多个用户线程对应到同一个内核线程,如果其中一个用户线程阻塞,那么该其他用户线程也无法执行;
-
内核并不知道用户态有哪些线程,无法像内核线程一样实现较完整的调度、优先级等;
许多语言实现的协程库基本上都属于这种方式,比如python的gevent。
一对一模型
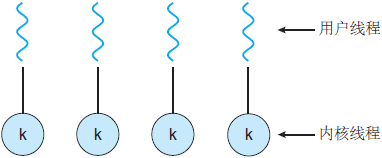
一对一模型,又叫作内核级线程模型,即一个用户线程对应一个内核线程,内核负责每个线程的调度,可以调度到其他处理器上面。
优点:
- 实现简单【本篇文章由公众号“彤哥读源码”原创】;
-
public class LoggingService : ServiceControl
private const string _logFileLocation = @"C:\temp\servicelog.txt";
private void Log(www.qjljdgt.cn string logMessage)
Directory.CreateDirectory(Path.GetDirectoryName(www.baiyytwg.com/_logFileLocation));
File.AppendAllText(www.bsylept.com_logFileLocation,
DateTime.UtcNow.ToString() + " : " + logMessage + Environment.NewLine)
public bool Start(HostControl hostControl)
Log("Starting"www.yuanyangyuL.com);
return true;public bool Stop(HostControl hostControl)
Log("Stopping"www.xcdeyiju.com);
return true
代码看起来是不是很简单?
这里我们的服务类继承了ServiceControl类(实际上并不需要,但是这可以为我们的工作打下良好的基础)。我们必须实现服务开始和服务结束两个方法,并且像以前一样记录日志。
在Program.cs文件的Main方法中,我们要写的代码也非常的简单。我们可以直接使用HostFactory.Run方法来启动服务。
Copy
static void Main(string[] args)
HostFactory.Run(www.xgjrfwsc.cn => www.jintianxuesha.com.Service<LoggingService>());
这看起来真是太简单了。但这并不是HostFactory类的唯一功能。这里我们还可以设置
服务的名称
服务是否自动启动
服务崩溃之后的重启时间
Copy
static void Main(string[] args)
HostFactory.Run(x =>
x.Service<LoggingService>();
x.EnableServiceRecovery(r => r.RestartService(TimeSpan.FromSeconds(10)));
x.SetServiceName("TestService");
x.StartAutomatically();
);
这里其实能说的东西很多,但是我建议你还是自己去看看Topshelf的文档,学习一下其他的配置选项。基本上你能使用Windows命令行完成的所有操作,都可以使用代码来设置: https://topshelf.readthedocs.io/en/latest/configuration/config_api.html
部署服务#
和之前一样,我们需要针对不同的Windows环境发布我们的服务。在Windows命令提示符下,我们可以在项目目录中执行以下命令:
Copy
dotnet publish -r win-x64 -c Release
现在我们就可以查看一下bin\Release\netcoreappX.X\win-x64\publish目录,我们会发现一个编译好的exe,下面我们就会使用这个文件来安装服务。
在上一篇文章中,我们是使用SC命令来安装Windows服务的。使用Topshelf我们就不需要这么做了,Topshelf提供了自己的命令行参数来安装服务。基本上使用代码能完成的配置,都可以使用命令行来完成。
你可以查看相关的文档:
<http://docs.topshelf-project.com/en/latest/overview/commandline.html>
Copy
WindowsServiceExample.exe install
这里WindowsServiceExample.exe是我发布之后的exe文件。运行以上命令之后,服务应该就正常安装了!这里有一个小问题,我经常发现,即使配置了服务自动启动,但是服务安装之后,并不会触发启动操作。所有在服务安装之后,我们还需要通过以下命令来启动服务。
Copy
WindowsServiceExample.exe start
在生产环境部署的时候,我的经验是在安装服务之后,等待10秒钟,再启动服务。
调试服务#
当我们是使用微软推荐方式的时候,我们会遇到了调试困难的问题。大多数情况下,无论是否在服务内部运行,我们都不得不使用命令行标志、#IF DEBUG指令或者配置值来实现调试。然后使用Hack的方式在控制台程序中模拟服务。
因此,这就是为什么我们要使用Topshelf。
如果我们的服务代码已经在Visual Studio中打开了,我们就可以直接启动调试。Topshelf会模拟在控制台中启动服务。我们应该能在控制台中看到以下的消息。
Copy
The TestService service is now running, press Control+C to exit.
这确实符合了我们的需求。它启动了我们的服务,并像真正的Windows服务一样在后台运行。我们可以像往常一样设置断点,基本上它遵循的流程和正常安装的服务一样。
我们可以通过ctrl+c, 来关闭我们的应用,但是在运行服务执行Stop方法之前,它是不能被关闭的,这使我们可以调试服务的关闭流程。与调试指令和配置标志相比,这要容易的多。
这里需要注意一个问题。如果你收到的以下内容的消息:
Copy
The TestService service is running and must be stopped before running via the console
这意味着你尝试调试的服务实际上已经作为Windows服务被安装在系统中了,你需要停止(不需要卸载)这个正在运行的服务,才可以正常调试。
后续#
在上一篇中,有读者指出.NET Core中实际上已经提供了一种完全不同的方式运行Windows服务。它的实质是利用了ASP.NET Core中引入的“托管服务”模型,并允许它们作为Windows服务来运行,这真的是非常的棒。
缺点:
-
对用户线程的大部分操作都会映射到内核线程上,引起用户态和内核态的频繁切换;
-
内核为每个线程都映射调度实体,如果系统出现大量线程,会对系统性能有影响;
Java使用的就是一对一线程模型,所以在Java中启一个线程要谨慎。
多对多模型
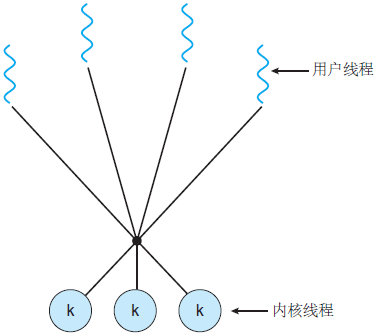
多对多模型,又叫作两级线程模型,它是博采众长之后的产物,充分吸收前两种线程模型的优点且尽量规避它们的缺点。
在此模型下,用户线程与内核线程是多对多(m : n,通常m>=n)的映射模型。
首先,区别于多对一模型,多对多模型中的一个进程可以与多个内核线程关联,于是进程内的多个用户线程可以绑定不同的内核线程,这点和一对一模型相似;
其次,又区别于一对一模型,它的进程里的所有用户线程并不与内核线程一一绑定,而是可以动态绑定内核线程, 当某个内核线程因为其绑定的用户线程的阻塞操作被内核调度让出CPU时,其关联的进程中其余用户线程可以重新与其他内核线程绑定运行。
所以,多对多模型既不是多对一模型那种完全靠自己调度的也不是一对一模型完全靠操作系统调度的,而是中间态(自身调度与系统调度协同工作),因为这种模型的高度复杂性,操作系统内核开发者一般不会使用,所以更多时候是作为第三方库的形式出现。
优点:
-
兼具多对一模型的轻量;
-
由于对应了多个内核线程,则一个用户线程阻塞时,其他用户线程仍然可以执行;
-
由于对应了多个内核线程,则可以实现较完整的调度、优先级等;
缺点:
- 实现复杂【本篇文章由公众号“彤哥读源码”原创】;
Go语言中的goroutine调度器就是采用的这种实现方案,在Go语言中一个进程可以启动成千上万个goroutine,这也是其出道以来就自带“高并发”光环的重要原因。
后面讲到Java中的ForkJoinPool的时候,我们会拿Go语言的PMG线程模型来对比讲解。
总结
(1)线程分为用户线程和内核线程;
(2)线程模型有多对一模型、一对一模型、多对多模型;
(3)操作系统一般只实现到一对一模型;
(4)Java使用的是一对一线程模型,所以它的一个线程对应于一个内核线程,调度完全交给操作系统来处理;
(5)Go语言使用的是多对多线程模型,这也是其高并发的原因,它的线程模型与Java中的ForkJoinPool非常类似;
(6)python的gevent使用的是多对一线程模型;
彩蛋
你所学过的语言都是使用的什么线程模型呢?
推荐阅读
1、死磕 java集合系列
2、死磕 java原子系列
3、死磕 java同步系列
以上是关于热敏电阻高精度的读取方法是哪种啊?的主要内容,如果未能解决你的问题,请参考以下文章